Object Storage Service (OSS) ボリュームは複数のクライアントをサポートしており、異なるクライアントは書き込み操作に対して様々なレベルのサポートを提供します。完全な書き込みサポートは、読み取りパフォーマンスを低下させる可能性があります。したがって、読み書き分離は、書き込み操作が読み取りパフォーマンスに与える影響を最小限に抑え、読み取り集中型のシナリオでのデータアクセス パフォーマンスを大幅に向上させることができます。このトピックでは、読み取り集中型のシナリオで、異なる OSS ボリューム クライアント、または OSS SDK や ossutil などのツールを使用して読み書き分離を実装する方法について説明します。
前提条件
OSS バケットが作成されます。 このバケットは、お使いのクラスターと同じ Alibaba Cloud アカウントに属します。
OSS バケットが作成されている。バケットは、クラスタと同じ Alibaba Cloud アカウントに属しています。
重要アカウントをまたがる OSS バケットは使用しないことをお勧めします。
シナリオ
OSS は、読み取り専用と読み書きのシナリオでよく使用されます。読み取り集中型のシナリオでは、OSS データの読み取り操作と書き込み操作を分離することをお勧めします。
読み取り: 異なる OSS ボリューム クライアントを選択するか、構成パラメーターを変更して、データの読み取り速度を最適化します。
書き込み: ossfs 1.0 を使用して完全な書き込み機能を実装するか、OSS SDK などのツールを使用してデータを書き込みます。
読み取り専用シナリオ
ビッグデータの推論、分析、クエリ シナリオでは、OSS ボリュームのアクセス モードを ReadOnlyMany に設定して、データが誤って削除または変更されないようにすることをお勧めします。
OSS ボリュームは現在、ossfs 1.0、ossfs 2.0、strmvol の 3 つのタイプのクライアントをサポートしています。すべてが読み取り専用操作をサポートしています。
読み取り専用シナリオでのパフォーマンスを最適化するために、CSI プラグインをバージョン 1.33.1 以降にスペックアップし、ossfs 1.0 の代わりに ossfs 2.0 を使用することをお勧めします。 ossfs 2.0 ボリュームの使用方法については、「ossfs 2.0 ボリュームを使用する」をご参照ください。
データセットの読み取り、量子化バックテスト、時系列ログ分析など、ビジネスに大量の小さなファイルの読み取りが含まれる場合は、strmvol ボリュームを使用できます。 strmvol ボリュームの使用方法については、「strmvol ボリュームを使用する」をご参照ください。
クライアント シナリオと選択に関する推奨事項の詳細については、「クライアント選択リファレンス」をご参照ください。
読み取り専用シナリオで ossfs 1.0 クライアントを使用する必要がある場合は、次のパラメーター構成を参照して、データ読み取りパフォーマンスを向上させることができます。
パラメーター
説明
kernel_cache
カーネル キャッシュを使用して読み取り操作を高速化します。この機能は、最新のデータにリアルタイムでアクセスする必要がないシナリオに適しています。
ossfs がファイルを複数回読み取る必要があり、クエリがキャッシュにヒットした場合、カーネル キャッシュ内のアイドル メモリを使用してファイルがキャッシュされ、データ取得が高速化されます。
parallel_count
マルチパート ダウンロードまたはアップロード中に 同時 にダウンロードまたはアップロードできるパーツの最大数を指定します。デフォルト値: 20。
max_multireq
ファイル メタデータを 同時 に取得できるクエリの最大数を指定します。このパラメーターの値は、parallel_count パラメーターの値以上である必要があります。デフォルト値: 20。
max_stat_cache_size
メタデータ キャッシュにメタデータを保存できるファイルの最大数を指定します。デフォルト値: 1000。メタデータ キャッシュを無効にするには、このパラメーターを 0 に設定します。
最新のデータにリアルタイムでアクセスする必要がないシナリオでは、現在のディレクトリに多数のファイルが含まれている場合、キャッシュの数を増やして LIST 操作を高速化できます。
direct_read
ossfs 1.91 以降のバージョンでは、読み取り専用シナリオのダイレクト リード モードが追加されています。
ダイレクト リード モードの機能とパフォーマンステストの詳細については、「ossfs 1.0 の新機能と ossfs パフォーマンス ベンチマーク」をご参照ください。
ダイレクト リード モードの最適化方法については、「読み取り専用シナリオでのパフォーマンス最適化」をご参照ください。
読み書きシナリオ
読み書きシナリオでは、OSS ボリュームのアクセス モードを ReadWriteMany に設定する必要があります。
現在、ossfs 1.0 は完全な書き込み操作をサポートしていますが、ossfs 2.0 はシーケンシャル 追加 書き込みのみをサポートしています。 ossfs を介して書き込み操作を実行する場合は、次の点に注意してください。
ossfs は、同時書き込み操作によって書き込まれたデータの整合性を保証しません。
OSS ボリュームがポッドにマウントされている場合、ポッドまたはポッドのホストにログインして、マウント パス内のファイルを削除または変更すると、OSS バケット内のソース ファイルも削除または変更されます。重要なデータが誤って削除されないように、OSS バケットのバージョン管理を有効にすることができます。詳細については、「バージョニング」をご参照ください。
読み取り集中型のシナリオ、特にビッグデータ ビジネスのトレーニング プロセスのように読み取りパスと書き込みパスが分離されている場合は、OSS データの読み取り操作と書き込み操作を分離することをお勧めします。 OSS ボリュームのアクセス モードを
ReadOnlyManyに設定し、キャッシュ パラメーターを構成することでデータ読み取り速度を最適化し、SDK などのツールを使用してデータを書き込みます。詳細については、「例」をご参照ください。
例
この例では、手書きの画像認識トレーニング アプリケーションを使用して、OSS 読み書き分離を構成する方法を説明します。この例は、単純なディープ ラーニング モデル トレーニングです。アプリケーションは、読み取り専用 OSS ボリュームを介して OSS バケットの /data-dir ディレクトリからトレーニング データセットを読み取り、読み書き OSS ボリュームまたは OSS SDK を介して OSS バケットの /log-dir ディレクトリにチェックポイントを書き込みます。
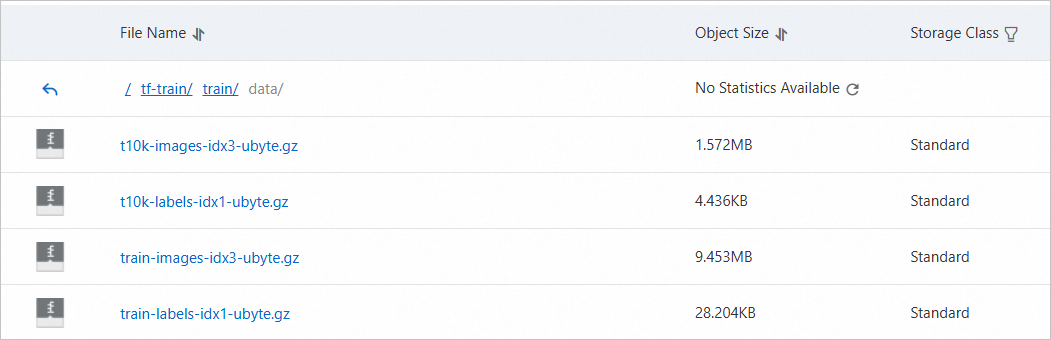
始める前に、MNIST 手書き画像トレーニング セットをダウンロードし、OSS バケットの /tf-train/train/data/ ディレクトリにアップロードします。これにより、アプリケーションはデータセットにアクセスできます。
MNIST 手書き画像トレーニング セット
OSS バケットにアップロードされたサンプル ファイル
ossfs を使用して読み取り/書き込み操作を実装する
チェックポイントの書き込みはシーケンシャル 追加 書き込み操作であるため、ossfs 1.0 または ossfs 2.0 のいずれかを選択して読み取り/書き込み操作を実装できます。
次のテンプレートに基づいて、手書きの画像認識トレーニング アプリケーションをデプロイします。
アプリケーションは Python で記述されており、静的にプロビジョニングされた OSS ボリュームがアプリケーションにマウントされています。 OSS ボリュームの構成方法については、「静的にプロビジョニングされた ossfs 1.0 ボリュームをマウントする」または「ossfs 2.0 ボリュームを使用する」をご参照ください。
次の例では、OSS バケットの
/tf-trainサブディレクトリがポッドの/mntディレクトリにマウントされています。次の内容に基づいて ossfs 1.0 ボリュームを作成します。
cat << EOF | kubectl apply -f - apiVersion: v1 kind: Secret metadata: name: oss-secret namespace: default stringData: akId: "<your-accesskey-id>" akSecret: "<your-accesskey-secret>" --- apiVersion: v1 kind: PersistentVolume metadata: name: tf-train-pv labels: alicloud-pvname: tf-train-pv spec: capacity: storage: 10Gi accessModes: - ReadWriteMany persistentVolumeReclaimPolicy: Retain csi: driver: ossplugin.csi.alibabacloud.com volumeHandle: tf-train-pv nodePublishSecretRef: name: oss-secret namespace: default volumeAttributes: bucket: "<your-bucket-name>" url: "oss-<region>.aliyuncs.com" otherOpts: "-o max_stat_cache_size=0 -o allow_other" path: "/tf-train" --- apiVersion: v1 kind: PersistentVolumeClaim metadata: name: tf-train-pvc spec: accessModes: - ReadWriteMany resources: requests: storage: 10Gi selector: matchLabels: alicloud-pvname: tf-train-pv EOF次の内容に基づいてトレーニング コンテナーを作成します。
トレーニング プロセス中に、アプリケーションはポッド内の
/mnt/training_logsディレクトリに中間ファイルを書き込みます。このディレクトリは ossfs によって管理され、新しいファイルが OSS バケットの/tf-train/training_logs/ディレクトリに自動的にアップロードされます。cat << EOF | kubectl apply -f - apiVersion: v1 kind: Pod metadata: labels: app: tfjob name: tf-mnist namespace: default spec: containers: - command: - sh - -c - python /app/main.py env: - name: NVIDIA_VISIBLE_DEVICES value: void - name: gpus value: "0" - name: workers value: "1" - name: TEST_TMPDIR value: "/mnt" image: registry.cn-beijing.aliyuncs.com/tool-sys/tf-train-demo:rw imagePullPolicy: Always name: tensorflow ports: - containerPort: 20000 name: tfjob-port protocol: TCP volumeMounts: - name: train mountPath: "/mnt" workingDir: /root priority: 0 restartPolicy: Never securityContext: {} terminationGracePeriodSeconds: 30 volumes: - name: train persistentVolumeClaim: claimName: tf-train-pvc EOF
データが期待どおりに読み書きできることを確認します。
ポッドのステータスを確認します。
kubectl get pod tf-mnistポッドのステータスが Running から Completed に変わるまで数分待ちます。期待される出力:
NAME READY STATUS RESTARTS AGE tf-mnist 0/1 Completed 0 2m12sポッドの操作ログを確認します。
ポッドの操作ログでデータの読み込み時間を確認します。読み込み時間には、OSS からファイルをダウンロードし、TensorFlow にファイルを読み込むのに必要な時間が含まれます。
kubectl logs tf-mnist | grep dataloadシステムは、次の出力に類似した情報を表示します。実際のクエリ時間は、インスタンスのパフォーマンスとネットワーク ステータスによって異なります。
dataload cost time: 1.54191803932[OSS コンソール] にログインします。 関連ファイルが OSS バケットの
/tf-train/training_logsディレクトリにアップロードされていることがわかります。これは、データが期待どおりに OSS から読み書きできることを示しています。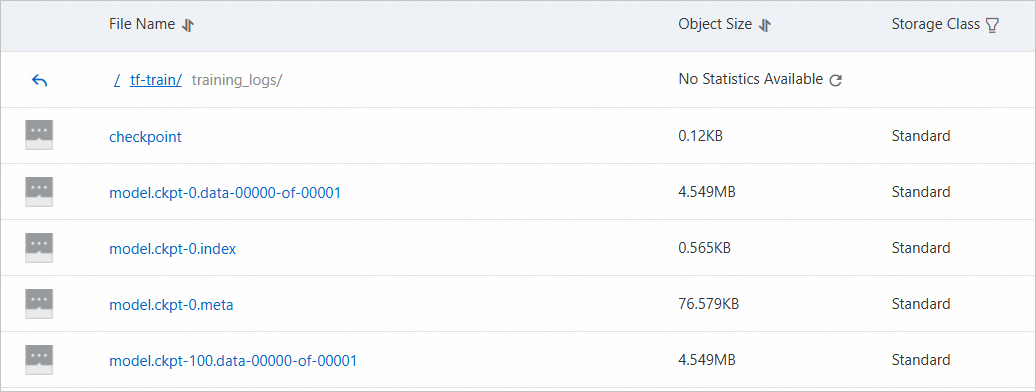
読み書き分離によって ossfs データ読み取り速度を最適化する
読み書き分離をサポートするようにアプリケーションを再構成します。
読み取り: 読み取り操作には、最適化された ossfs 1.0 読み取り専用ボリュームを使用します
書き込み: 書き込み操作には、ossfs 1.0 読み取り/書き込みボリュームまたは OSS SDK を使用します
書き込み操作に ossfs 1.0 読み取り/書き込みボリュームを使用する
手書きの画像認識トレーニング アプリケーションと ossfs 1.0 読み取り専用 + 読み取り/書き込みボリュームを例として使用して、読み取り/書き込み分離をサポートするようにアプリケーションを再構成する方法を説明します。
次の内容に基づいて ossfs 1.0 読み取り専用ボリュームを作成します。
読み取り専用シナリオ用に ossfs 1.0 ボリュームの構成パラメーターを最適化します。
PV と PVC の両方の
accessModesをReadOnlyManyに変更します。バケットのマウント パスは/tf-train/train/dataに短縮できます。otherOptsフィールドに、-o kernel_cache -o max_stat_cache_size=10000 -o umask=022オプションを追加します。kernel_cacheオプションは、システムのメモリ バッファーを使用して ossfs データの読み取りを高速化します。max_stat_cache_sizeオプションは、メタデータ キャッシュを増やします (値 10,000 は約 40 MB のメモリを消費します。インスタンス サイズに合わせて調整してください)。umask=022オプションは、コンテナー内のルート以外のプロセスに読み取り権限を付与します。
詳細については、「シナリオ」をご参照ください。
cat << EOF | kubectl apply -f - apiVersion: v1 kind: Secret metadata: name: oss-secret namespace: default stringData: akId: "<your-accesskey-id>" akSecret: "<your-accesskey-secret>" --- apiVersion: v1 kind: PersistentVolume metadata: name: tf-train-pv labels: alicloud-pvname: tf-train-pv spec: capacity: storage: 10Gi accessModes: - ReadOnlyMany persistentVolumeReclaimPolicy: Retain csi: driver: ossplugin.csi.alibabacloud.com volumeHandle: tf-train-pv nodePublishSecretRef: name: oss-secret namespace: default volumeAttributes: bucket: "<your-bucket-name>" url: "oss-<region>.aliyuncs.com" otherOpts: "-o kernel_cache -o max_stat_cache_size=10000 -o umask=022 -o allow_other" path: "/tf-train/train/data" --- apiVersion: v1 kind: PersistentVolumeClaim metadata: name: tf-train-pvc spec: accessModes: - ReadOnlyMany resources: requests: storage: 10Gi selector: matchLabels: alicloud-pvname: tf-train-pv EOF次の内容に基づいて ossfs 1.0 読み取り/書き込みボリュームを作成します。
cat << EOF | kubectl apply -f - apiVersion: v1 kind: PersistentVolume metadata: name: tf-logging-pv labels: alicloud-pvname: tf-logging-pv spec: capacity: storage: 10Gi accessModes: - ReadWriteMany persistentVolumeReclaimPolicy: Retain csi: driver: ossplugin.csi.alibabacloud.com volumeHandle: tf-logging-pv nodePublishSecretRef: name: oss-secret namespace: default volumeAttributes: bucket: "<your-bucket-name>" url: "oss-<region>.aliyuncs.com" otherOpts: "-o max_stat_cache_size=0 -o allow_other" path: "/tf-train/training_logs" --- apiVersion: v1 kind: PersistentVolumeClaim metadata: name: tf-logging-pvc spec: accessModes: - ReadWriteMany resources: requests: storage: 10Gi selector: matchLabels: alicloud-pvname: tf-logging-pv EOF次の内容に基づいてトレーニング コンテナーを作成します。
説明トレーニング ビジネス ロジックを変更する必要はありません。デプロイ時に読み取り専用ボリュームと読み取り/書き込みボリュームの両方をマウントするだけです。
cat << EOF | kubectl apply -f - apiVersion: v1 kind: Pod metadata: labels: app: tfjob name: tf-mnist namespace: default spec: containers: - command: - sh - -c - python /app/main.py env: - name: NVIDIA_VISIBLE_DEVICES value: void - name: gpus value: "0" - name: workers value: "1" - name: TEST_TMPDIR value: "/mnt" image: registry.cn-beijing.aliyuncs.com/tool-sys/tf-train-demo:rw imagePullPolicy: Always name: tensorflow ports: - containerPort: 20000 name: tfjob-port protocol: TCP volumeMounts: - name: train mountPath: "/mnt/train/data" - name: logging mountPath: "/mnt/training_logs" workingDir: /root priority: 0 restartPolicy: Never securityContext: {} terminationGracePeriodSeconds: 30 volumes: - name: train persistentVolumeClaim: claimName: tf-train-pvc - name: logging persistentVolumeClaim: claimName: tf-logging-pvc EOF
書き込み操作に OSS SDK を使用する
この例では、手書きの画像認識トレーニング アプリケーションと OSS SDK を使用して、読み取り/書き込み分離をサポートするようにアプリケーションを再構成する方法を説明します。
Container Service for Kubernetes (ACK) 環境に OSS SDK をインストールします。イメージをビルドするときに次の内容を追加します。詳細については、「インストール」をご参照ください。
RUN pip install oss2Python SDK デモに基づいてソースコードを変更します。
次のコード ブロックは、前述の手書き画像認識トレーニング アプリケーションを使用する場合のベース イメージに関連するソースコードを示しています。
def train(): ... saver = tf.train.Saver(max_to_keep=0) for i in range(FLAGS.max_steps): if i % 10 == 0: # Record summaries and test-set accuracy summary, acc = sess.run([merged, accuracy], feed_dict=feed_dict(False)) print('Accuracy at step %s: %s' % (i, acc)) if i % 100 == 0: print('Save checkpoint at step %s: %s' % (i, acc)) saver.save(sess, FLAGS.log_dir + '/model.ckpt', global_step=i)上記のコードでは、100 反復ごとに、中間ファイル (チェックポイント) が指定された log_dir ディレクトリ (ポッドの
/mnt/training_logsディレクトリ) に保存されます。 Saver のmax_to_keepパラメーターは 0 であるため、すべての中間ファイルが保持されます。 1,000 回の反復後、10 セットのチェックポイントが OSS に保存されます。OSS SDK を使用してチェックポイントをアップロードするには、次の要件に基づいてコードを変更します。
環境変数から AccessKey ペアとバケット情報を読み取るようにクレデンシャルを構成します。詳細については、「アクセス クレデンシャルを構成する (Python SDK V1)」をご参照ください。
コンテナーのメモリ使用量を削減するために、
max_to_keepを 1 に設定できます。これは、最新のトレーニング中間ファイルのセットのみが常に保存されることを意味します。中間ファイルが保存されるたびに、put_object_from_file関数を使用して対応するバケット ディレクトリにアップロードされます。
説明読み書き分離シナリオで OSS SDK を使用する場合は、非同期読み取りと書き込みを使用してトレーニングを高速化できます。
import oss2 from oss2.credentials import EnvironmentVariableCredentialsProvider auth = oss2.ProviderAuth(EnvironmentVariableCredentialsProvider()) url = os.getenv('URL','<default-url>') bucketname = os.getenv('BUCKET','<default-bucket-name>') bucket = oss2.Bucket(auth, url, bucketname) ... def train(): ... saver = tf.train.Saver(max_to_keep=1) for i in range(FLAGS.max_steps): if i % 10 == 0: # Record summaries and test-set accuracy summary, acc = sess.run([merged, accuracy], feed_dict=feed_dict(False)) print('Accuracy at step %s: %s' % (i, acc)) if i % 100 == 0: print('Save checkpoint at step %s: %s' % (i, acc)) saver.save(sess, FLAGS.log_dir + '/model.ckpt', global_step=i) # FLAGS.log_dir = os.path.join(os.getenv('TEST_TMPDIR', '/mnt'),'training_logs') for path,_,file_list in os.walk(FLAGS.log_dir) : for file_name in file_list: bucket.put_object_from_file(os.path.join('tf-train/training_logs', file_name), os.path.join(path, file_name))変更されたコンテナー イメージは
registry.cn-beijing.aliyuncs.com/tool-sys/tf-train-demo:roです。アプリケーションが読み取り専用モードで OSS にアクセスするようにアプリケーション テンプレートを変更します。
PV と PVC の両方の
accessModesをReadOnlyManyに変更します。バケットのマウント パスは/tf-train/train/dataに短縮できます。otherOptsフィールドに、-o kernel_cache -o max_stat_cache_size=10000 -o umask=022オプションを追加します。kernel_cacheオプションは、システムのメモリ バッファーを使用して ossfs データの読み取りを高速化します。max_stat_cache_sizeオプションは、メタデータ キャッシュを増やします (値 10,000 は約 40 MB のメモリを消費します。インスタンス サイズに合わせて調整してください)。umask=022オプションは、コンテナー内のルート以外のプロセスに読み取り権限を付与します。
詳細については、「シナリオ」をご参照ください。
OSS_ACCESS_KEY_IDおよびOSS_ACCESS_KEY_SECRET環境変数をポッド テンプレートに追加します。環境変数の値は oss-secret から取得できます。情報は OSS ボリュームと同じであることを確認してください。
データが期待どおりに読み書きできることを確認します。
ポッドのステータスを確認します。
kubectl get pod tf-mnistポッドのステータスが
RunningからCompletedに変わるまで数分待ちます。期待される出力:NAME READY STATUS RESTARTS AGE tf-mnist 0/1 Completed 0 2m25sポッドの操作ログを確認します。
ポッドの操作ログでデータの読み込み時間を確認します。読み込み時間には、OSS からファイルをダウンロードし、TensorFlow にファイルを読み込むのに必要な時間が含まれます。
kubectl logs tf-mnist | grep dataload期待される出力:
dataload cost time: 0.843528985977出力は、読み取り専用モードでキャッシュを使用して読み取り操作が高速化されていることを示しています。この方法は、大規模なトレーニングや継続的なデータ読み込みシナリオに最適です。
[OSS コンソール] にログインします。 関連ファイルが OSS バケットの
/tf-train/training_logsディレクトリに表示されていることがわかります。これは、データが期待どおりに OSS から読み書きできることを示しています。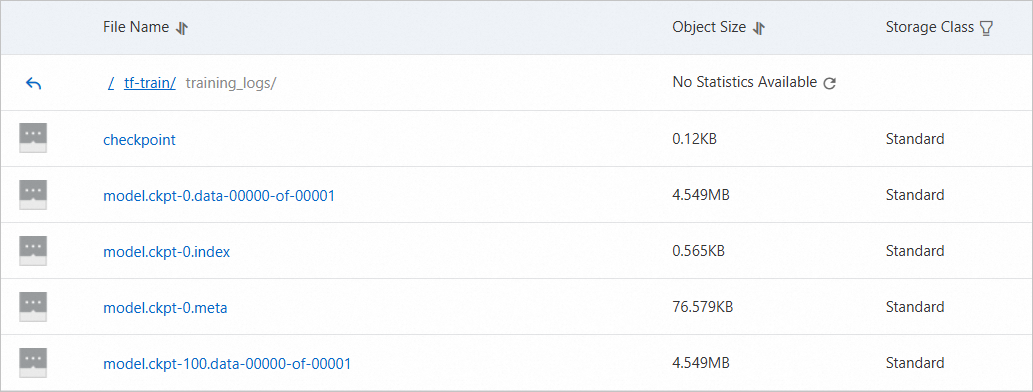
参考資料
OSS SDK リファレンス
以下は、Alibaba Cloud OSS SDK の公式リファレンス コードの一部です。
PHP、Node.js、Browser.js、.NET、Android、iOS、Ruby など、サポートされている言語の詳細については、「SDK リファレンス」をご参照ください。
OSS 読み書き分離を実装するためのその他のツール
ツール | 参考資料 |
OpenAPI | |
ossutil | |
ossbrowser |