This topic explains how to perform aggregation operations for data analysis. Aggregation operations can calculate the minimum, maximum, sum, average, count, distinct count, and percentiles. Results can be grouped by field value, range, location, filters, histograms, or dates, with the option to run nested queries to analyze the rows from each group. Multiple aggregation operations can also be combined for more complex queries.
Procedure
The following figure shows the complete aggregation procedure.
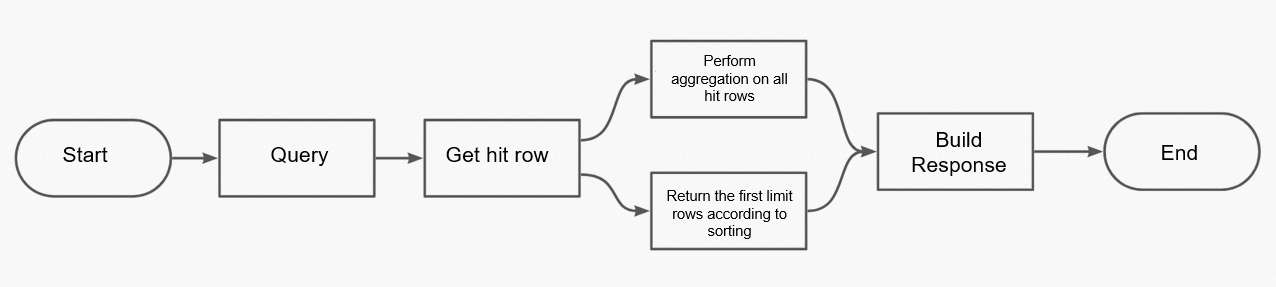
The server queries the data that meets the query conditions and performs aggregation on the data based on the request. Therefore, a request that requires aggregation is more complex to process than a request that does not require aggregation.
Background information
The following table describes the aggregation methods.
Method | Description |
Minimum value | The aggregation method that can be used to return the minimum value of a field. This method can be used in a similar manner as the MIN operator in SQL. |
Maximum value | The aggregation method that can be used to return the maximum value of a field. This method can be used in a similar manner as the MAX operator in SQL. |
And | The aggregation method that can be used to return the sum of all values for a numeric field. This method can be used in a similar manner as the SUM operator in SQL. |
Average value | The aggregation method that can be used to return the average of all values for a numeric field. This method can be used in a similar manner as the AVG operator in SQL. |
Count | The aggregation method that can be used to return the total number of values for a field or the total number of rows in a search index. This method can be used in a similar manner as the COUNT operator in SQL. |
Distinct count | The aggregation method that can be used to return the number of distinct values for a field. This method can be used in a similar manner as the COUNT(DISTINCT) operator in SQL. |
Percentile statistics | A percentile value indicates the relative position of a value in a dataset. For example, when you collect statistics for the response time of each request during the routine O&M of your system, you must analyze the response time distribution by using percentiles such as p25, p50, p90, and p99. |
Group by field value | The aggregation method that can be used to group query results based on field values. The values that are the same are grouped together. The value of each group and the number of members in each group are returned. Note Group by field value uses parallel computing and is not an exact calculation. There may be slight errors. |
Group by multiple fields | The aggregation method that can be used to group query results based on multiple fields. Use tokens to perform paging. |
Nested grouping | GroupBy supports nesting. Perform sub-aggregation operations by using GroupBy. |
Group by range | The aggregation method that can be used to group query results based on the value ranges of a field. Field values that are within a specific range are grouped together. The number of values in each range is returned. |
Group by geographical location | The aggregation method that can be used to group query results based on distances from geographical locations to a central point. Query results in distances that are within a specific range are grouped together. The number of values in each range is returned. |
Group by filter | The aggregation method that can be used to filter the query results and group them based on each filter to obtain the number of matching results. Results are returned in the order in which the filters are specified. |
Query by histogram | The aggregation method can be used to group query results based on specific data intervals. Field values that are within the same range are grouped together. The value range of each group and the number of values in each group are returned. |
Query by date histogram | The aggregation method that can be used to group query results based on specific date intervals. Field values that are within the same range are grouped together. The value range of each group and the number of values in each group are returned. |
Query the rows that are obtained from the results of an aggregation operation in each group | After you group query results, query the rows in each group. This method can be used in a similar manner as ANY_VALUE(field) in MySQL. |
Multiple aggregations | Perform multiple aggregation operations. Note If you perform multiple complex aggregation operations at the same time, a long period of time may be required. |
Prerequisites
An OTSClient instance is initialized. For more information, see Initialize a Tablestore client.
A data table is created, and data is written to the data table. For more information, see Create a data table and Write data.
A search index is created for the data table. For more information, see Create a search index.
ImportantThe field types supported by the aggregation feature are the field types supported by search indexes. For information about the field types supported by search indexes and the mappings between the field types supported by search indexes and the field types supported by data tables, see Data types.
Minimum value
The aggregation method that can be used to return the minimum value of a field. This method can be used in a similar manner as the MIN operator in SQL.
Parameters
Parameter
Description
aggregationName
The unique name of the aggregation operation. Query the results of a specific aggregation operation based on this name.
fieldName
The name of the field that is used to perform the aggregation operation. Only the Long, Double, and Date types are supported.
missing
The default value for the field on which the aggregation operation is performed, which is applied to rows in which the field value is empty.
If you do not specify a value for the missing parameter, the row is ignored.
If you specify a value for the missing parameter, the value of this parameter is used as the field value of the row.
Examples
/** * The price of each product is listed in the product table. Query the minimum price of the products that are produced in Zhejiang. * SQL statement: SELECT min(column_price) FROM product where place_of_production="Zhejiang". */ public void min(SyncClient client) { //Use builder to create a query statement. { SearchRequest searchRequest = SearchRequest.newBuilder() .tableName("<TABLE_NAME>") .indexName("<SEARCH_INDEX_NAME>") .searchQuery( SearchQuery.newBuilder() .query(QueryBuilders.term("place_of_production", "Zhejiang")) .limit(0) //If you want to obtain only the aggregation results instead of specific data, set limit to 0 to improve query performance. .addAggregation(AggregationBuilders.min("min_agg_1", "column_price").missing(100)) .build()) .build(); //Execute the query statement. SearchResponse resp = client.search(searchRequest); //Obtain the aggregation results. System.out.println(resp.getAggregationResults().getAsMinAggregationResult("min_agg_1").getValue()); } //Create a query statement without using builder. { SearchRequest searchRequest = new SearchRequest(); searchRequest.setTableName("<TABLE_NAME>"); searchRequest.setIndexName("<SEARCH_INDEX_NAME>"); SearchQuery searchQuery = new SearchQuery(); TermQuery query = new TermQuery(); query.setTerm(ColumnValue.fromString("Zhejiang")); query.setFieldName("place_of_production"); //In the following comment, builder is used to create a query statement. The method that uses builder to create a query statement has the same effect as the method that uses TermQuery to create a query statement. // Query query2 = QueryBuilders.term("place_of_production", "Zhejiang").build(); searchQuery.setQuery(query); searchQuery.setLimit(0); MinAggregation aggregation = new MinAggregation(); aggregation.setAggName("min_agg_1"); aggregation.setFieldName("column_price"); aggregation.setMissing(ColumnValue.fromLong(100)); //In the following comment, builder is used to create a query statement. The method that uses builder to create a query statement has the same effect as the method that uses aggregation to create a query statement. // MinAggregation aggregation2 = AggregationBuilders.min("min_agg_1", "column_price").missing(100).build(); List<Aggregation> aggregationList = new ArrayList<Aggregation>(); aggregationList.add(aggregation); searchQuery.setAggregationList(aggregationList); //Execute the query statement. SearchResponse resp = client.search(searchRequest); //Obtain the aggregation results. System.out.println(resp.getAggregationResults().getAsMinAggregationResult("min_agg_1").getValue()); } }
Maximum value
The aggregation method that can be used to return the maximum value of a field. This method can be used in a similar manner as the MAX operator in SQL.
Parameters
Parameter
Description
aggregationName
The unique name of the aggregation operation. Query the results of a specific aggregation operation based on this name.
fieldName
The name of the field that is used to perform the aggregation operation. Only the Long, Double, and Date types are supported.
missing
The default value for the field on which the aggregation operation is performed, which is applied to rows in which the field value is empty.
If you do not specify a value for the missing parameter, the row is ignored.
If you specify a value for the missing parameter, the value of this parameter is used as the field value of the row.
Examples
/** * The price of each product is listed in the product table. Query the maximum price of the products that are produced in Zhejiang. * SQL statement: SELECT max(column_price) FROM product where place_of_production="Zhejiang". */ public void max(SyncClient client) { //Use builder to create a query statement. { SearchRequest searchRequest = SearchRequest.newBuilder() .tableName("<TABLE_NAME>") .indexName("<SEARCH_INDEX_NAME>") .searchQuery( SearchQuery.newBuilder() .query(QueryBuilders.term("place_of_production", "Zhejiang")) .limit(0) //If you want to obtain only the aggregation results instead of specific data, set limit to 0 to improve query performance. .addAggregation(AggregationBuilders.max("max_agg_1", "column_price").missing(0)) .build()) .build(); //Execute the query statement. SearchResponse resp = client.search(searchRequest); //Obtain the aggregation results. System.out.println(resp.getAggregationResults().getAsMaxAggregationResult("max_agg_1").getValue()); } //Create a query statement without using builder. { SearchRequest searchRequest = new SearchRequest(); searchRequest.setTableName("<TABLE_NAME>"); searchRequest.setIndexName("<SEARCH_INDEX_NAME>"); SearchQuery searchQuery = new SearchQuery(); TermQuery query = new TermQuery(); query.setTerm(ColumnValue.fromString("Zhejiang")); query.setFieldName("place_of_production"); //In the following comment, builder is used to create a query statement. The method that uses builder to create a query statement has the same effect as the method that uses TermQuery to create a query statement. // Query query2 = QueryBuilders.term("place_of_production", "Zhejiang").build(); searchQuery.setQuery(query); searchQuery.setLimit(0); MaxAggregation aggregation = new MaxAggregation(); aggregation.setAggName("max_agg_1"); aggregation.setFieldName("column_price"); aggregation.setMissing(ColumnValue.fromLong(100)); //In the following comment, builder is used to create a query statement. The method that uses builder to create a query statement has the same effect as the method that uses aggregation to create a query statement. // MaxAggregation aggregation2 = AggregationBuilders.max("max_agg_1", "column_price").missing(100).build(); List<Aggregation> aggregationList = new ArrayList<Aggregation>(); aggregationList.add(aggregation); searchQuery.setAggregationList(aggregationList); //Execute the query statement. SearchResponse resp = client.search(searchRequest); //Obtain the aggregation results. System.out.println(resp.getAggregationResults().getAsMaxAggregationResult("max_agg_1").getValue()); } }
And
The aggregation method that can be used to return the sum of all values for a numeric field. This method can be used in a similar manner as the SUM operator in SQL.
Parameters
Parameter
Description
aggregationName
The unique name of the aggregation operation. Query the results of a specific aggregation operation based on this name.
fieldName
The name of the field that is used to perform the aggregation operation. Only the Long and Double types are supported.
missing
The default value for the field on which the aggregation operation is performed, which is applied to rows in which the field value is empty.
If you do not specify a value for the missing parameter, the row is ignored.
If you specify a value for the missing parameter, the value of this parameter is used as the field value of the row.
Examples
/** * The price of each product is listed in the product table. Query the maximum price of the products that are produced in Zhejiang. * SQL statement: SELECT sum(column_price) FROM product where place_of_production="Zhejiang". */ public void sum(SyncClient client) { //Use builder to create a query statement. { SearchRequest searchRequest = SearchRequest.newBuilder() .tableName("<TABLE_NAME>") .indexName("<SEARCH_INDEX_NAME>") .searchQuery( SearchQuery.newBuilder() .query(QueryBuilders.term("place_of_production", "Zhejiang")) .limit(0) //If you want to obtain only the aggregation results instead of specific data, set limit to 0 to improve query performance. .addAggregation(AggregationBuilders.sum("sum_agg_1", "column_number").missing(10)) .build()) .build(); //Execute the query statement. SearchResponse resp = client.search(searchRequest); //Obtain the aggregation results. System.out.println(resp.getAggregationResults().getAsSumAggregationResult("sum_agg_1").getValue()); } // Create a query statement without using builder. { SearchRequest searchRequest = new SearchRequest(); searchRequest.setTableName("<TABLE_NAME>"); searchRequest.setIndexName("<SEARCH_INDEX_NAME>"); SearchQuery searchQuery = new SearchQuery(); TermQuery query = new TermQuery(); query.setTerm(ColumnValue.fromString("Zhejiang")); query.setFieldName("place_of_production"); //In the following comment, builder is used to create a query statement. The method that uses builder to create a query statement has the same effect as the method that uses TermQuery to create a query statement. // Query query2 = QueryBuilders.term("place_of_production", "Zhejiang").build(); searchQuery.setQuery(query); searchQuery.setLimit(0); SumAggregation aggregation = new SumAggregation(); aggregation.setAggName("sum_agg_1"); aggregation.setFieldName("column_number"); aggregation.setMissing(ColumnValue.fromLong(100)); //In the following comment, builder is used to create a query statement. The method that uses builder to create a query statement has the same effect as the method that uses aggregation to create a query statement. // SumAggregation aggregation2 = AggregationBuilders.sum("sum_agg_1", "column_number").missing(10).build(); List<Aggregation> aggregationList = new ArrayList<Aggregation>(); aggregationList.add(aggregation); searchQuery.setAggregationList(aggregationList); //Execute the query statement. SearchResponse resp = client.search(searchRequest); //Obtain the aggregation results. System.out.println(resp.getAggregationResults().getAsSumAggregationResult("sum_agg_1").getValue()); } }
Average value
The aggregation method that can be used to return the average of all values for a numeric field. This method can be used in a similar manner as the AVG operator in SQL.
Parameters
Parameter
Description
aggregationName
The unique name of the aggregation operation. Query the results of a specific aggregation operation based on this name.
fieldName
The name of the field that is used to perform the aggregation operation. Only the Long, Double, and Date types are supported.
missing
The default value for the field on which the aggregation operation is performed, which is applied to rows in which the field value is empty.
If you do not specify a value for the missing parameter, the row is ignored.
If you specify a value for the missing parameter, the value of this parameter is used as the field value of the row.
Examples
/** * The sales of each product are listed in the product table. Query the average price of the products that are produced in Zhejiang. * SQL statement: SELECT avg(column_price) FROM product where place_of_production="Zhejiang". */ public void avg(SyncClient client) { //Use builder to create a query statement. { SearchRequest searchRequest = SearchRequest.newBuilder() .tableName("<TABLE_NAME>") .indexName("<SEARCH_INDEX_NAME>") .searchQuery( SearchQuery.newBuilder() .query(QueryBuilders.term("place_of_production", "Zhejiang")) .limit(0) //If you want to obtain only the aggregation results instead of specific data, set limit to 0 to improve query performance. .addAggregation(AggregationBuilders.avg("avg_agg_1", "column_price")) .build()) .build(); //Execute the query statement. SearchResponse resp = client.search(searchRequest); //Obtain the aggregation results. System.out.println(resp.getAggregationResults().getAsAvgAggregationResult("avg_agg_1").getValue()); } //Create a query statement without using builder. { SearchRequest searchRequest = new SearchRequest(); searchRequest.setTableName("<TABLE_NAME>"); searchRequest.setIndexName("<SEARCH_INDEX_NAME>"); SearchQuery searchQuery = new SearchQuery(); TermQuery query = new TermQuery(); query.setTerm(ColumnValue.fromString("Zhejiang")); query.setFieldName("place_of_production"); //In the following comment, builder is used to create a query statement. The method that uses builder to create a query statement has the same effect as the method that uses TermQuery to create a query statement. // Query query2 = QueryBuilders.term("place_of_production", "Zhejiang").build(); searchQuery.setQuery(query); searchQuery.setLimit(0); AvgAggregation aggregation = new AvgAggregation(); aggregation.setAggName("avg_agg_1"); aggregation.setFieldName("column_price"); //In the following comment, builder is used to create a query statement. The method that uses builder to create a query statement has the same effect as the method that uses aggregation to create a query statement. // AvgAggregation aggregation2 = AggregationBuilders.avg("avg_agg_1", "column_price").build(); List<Aggregation> aggregationList = new ArrayList<Aggregation>(); aggregationList.add(aggregation); searchQuery.setAggregationList(aggregationList); //Execute the query statement. SearchResponse resp = client.search(searchRequest); //Obtain the aggregation results. System.out.println(resp.getAggregationResults().getAsAvgAggregationResult("avg_agg_1").getValue()); } }
Count
The aggregation method that can be used to return the total number of values for a field or the total number of rows in a search index. This method can be used in a similar manner as the COUNT operator in SQL.
Use the following methods to query the total number of rows in a search index or the total number of rows that meet the query conditions:
Use the count feature of aggregation. Set the count parameter to * in the request.
Use the query feature to obtain the number of rows that meet the query conditions. Set the setGetTotalCount parameter to true in the query. Use MatchAllQuery to obtain the total number of rows in a search index.
Use the name of a column as the value of the count expression to query the number of rows that contain the column in a search index. This method is suitable for scenarios that involve sparse columns.
Parameters
Parameter
Description
aggregationName
The unique name of the aggregation operation. Query the results of a specific aggregation operation based on this name.
fieldName
The name of the field that is used to perform the aggregation operation. Only the following types are supported: Long, Double, Boolean, Keyword, Geo_point, and Date.
Examples
/** * Penalty records of merchants are recorded in the merchant table. You can query the number of merchants who are located in Zhejiang and for whom penalty records exist. If no penalty record exists for a merchant, the field that corresponds to penalty records also does not exist for the merchant. * SQL statement: SELECT count(column_history) FROM product where place_of_production="Zhejiang". */ public void count(SyncClient client) { //Use builder to create a query statement. { SearchRequest searchRequest = SearchRequest.newBuilder() .tableName("<TABLE_NAME>") .indexName("<SEARCH_INDEX_NAME>") .searchQuery( SearchQuery.newBuilder() .query(QueryBuilders.term("place_of_production", "Zhejiang")) .limit(0) //If you want to obtain only the aggregation results instead of specific data, set limit to 0 to improve query performance. .addAggregation(AggregationBuilders.count("count_agg_1", "column_history")) .build()) .build(); //Execute the query statement. SearchResponse resp = client.search(searchRequest); //Obtain the aggregation results. System.out.println(resp.getAggregationResults().getAsCountAggregationResult("count_agg_1").getValue()); } //Create a query statement without using builder. { SearchRequest searchRequest = new SearchRequest(); searchRequest.setTableName("<TABLE_NAME>"); searchRequest.setIndexName("<SEARCH_INDEX_NAME>"); SearchQuery searchQuery = new SearchQuery(); TermQuery query = new TermQuery(); query.setTerm(ColumnValue.fromString("Zhejiang")); query.setFieldName("place_of_production"); //In the following comment, builder is used to create a query statement. The method that uses builder to create a query statement has the same effect as the method that uses TermQuery to create a query statement. // Query query2 = QueryBuilders.term("place_of_production", "Zhejiang").build(); searchQuery.setQuery(query); searchQuery.setLimit(0); CountAggregation aggregation = new CountAggregation(); aggregation.setAggName("count_agg_1"); aggregation.setFieldName("column_history"); //In the following comment, builder is used to create a query statement. The method that uses builder to create a query statement has the same effect as the method that uses aggregation to create a query statement. // CountAggregation aggregation2 = AggregationBuilders.count("count_agg_1", "column_history").build(); List<Aggregation> aggregationList = new ArrayList<Aggregation>(); aggregationList.add(aggregation); searchQuery.setAggregationList(aggregationList); //Execute the query statement. SearchResponse resp = client.search(searchRequest); //Obtain the aggregation results. System.out.println(resp.getAggregationResults().getAsCountAggregationResult("count_agg_1").getValue()); } }
Distinct count
The aggregation method that can be used to return the number of distinct values for a field. This method can be used in a similar manner as the COUNT(DISTINCT) operator in SQL.
The number of distinct values is an approximate number.
If the total number of rows before the distinct count feature is used is less than 10,000, the calculated result is close to the exact value.
If the total number of rows before the distinct count feature is used is greater than or equal to 100 million, the error rate is approximately 2%.
Parameters
Parameter
Description
aggregationName
The unique name of the aggregation operation. Query the results of a specific aggregation operation based on this name.
fieldName
The name of the field that is used to perform the aggregation operation. Only the following types are supported: Long, Double, Boolean, Keyword, Geo_point, and Date.
missing
The default value for the field on which the aggregation operation is performed, which is applied to rows in which the field value is empty.
If you do not specify a value for the missing parameter, the row is ignored.
If you specify a value for the missing parameter, the value of this parameter is used as the field value of the row.
Examples
/** * Query the number of distinct provinces from which the products are produced. * SQL statement: SELECT count(distinct column_place) FROM product. */ public void distinctCount(SyncClient client) { //Use builder to create a query statement. { SearchRequest searchRequest = SearchRequest.newBuilder() .tableName("<TABLE_NAME>") .indexName("<SEARCH_INDEX_NAME>") .searchQuery( SearchQuery.newBuilder() .query(QueryBuilders.matchAll()) .limit(0) //If you want to obtain only the aggregation results instead of specific data, set limit to 0 to improve query performance. .addAggregation(AggregationBuilders.distinctCount("dis_count_agg_1", "column_place")) .build()) .build(); //Execute the query statement. SearchResponse resp = client.search(searchRequest); //Obtain the aggregation results. System.out.println(resp.getAggregationResults().getAsDistinctCountAggregationResult("dis_count_agg_1").getValue()); } //Create a query statement without using builder. { SearchRequest searchRequest = new SearchRequest(); searchRequest.setTableName("<TABLE_NAME>"); searchRequest.setIndexName("<SEARCH_INDEX_NAME>"); SearchQuery searchQuery = new SearchQuery(); MatchAllQuery query = new MatchAllQuery(); //In the following comment, builder is used to create a query statement. The method that uses builder to create a query statement has the same effect as the method that uses TermQuery to create a query statement. // Query query2 = QueryBuilders.matchAll().build(); searchQuery.setQuery(query); searchQuery.setLimit(0); DistinctCountAggregation aggregation = new DistinctCountAggregation(); aggregation.setAggName("dis_count_agg_1"); aggregation.setFieldName("column_place"); //In the following comment, builder is used to create a query statement. The method that uses builder to create a query statement has the same effect as the method that uses aggregation to create a query statement. // DistinctCountAggregation aggregation2 = AggregationBuilders.distinctCount("dis_count_agg_1", "column_place").build(); List<Aggregation> aggregationList = new ArrayList<Aggregation>(); aggregationList.add(aggregation); searchQuery.setAggregationList(aggregationList); //Execute the query statement. SearchResponse resp = client.search(searchRequest); //Obtain the aggregation results. System.out.println(resp.getAggregationResults().getAsDistinctCountAggregationResult("dis_count_agg_1").getValue()); } }
Percentile statistics
A percentile value indicates the relative position of a value in a dataset. For example, when you collect statistics for the response time of each request during the routine O&M of your system, you must analyze the response time distribution by using percentiles such as p25, p50, p90, and p99.
To improve the accuracy of the results, we recommend that you specify extreme percentile values such as p1 and p99. If you use extreme percentile values instead of other values such as p50, the returned results are more accurate.
Parameters
Parameter
Description
aggregationName
The unique name of the aggregation operation. Query the results of a specific aggregation operation based on this name.
fieldName
The name of the field that is used to perform the aggregation operation. Only the Long, Double, and Date types are supported.
percentiles
The percentiles such as p50, p90, and p99. You can specify one or more percentiles.
missing
The default value for the field on which the aggregation operation is performed, which is applied to rows in which the field value is empty.
If you do not specify a value for the missing parameter, the row is ignored.
If you specify a value for the missing parameter, the value of this parameter is used as the field value of the row.
Examples
/** * Analyze the distribution of the response time of each request that is sent to the system by using percentiles. */ public void percentilesAgg(SyncClient client) { //Use builder to create a query statement. { SearchRequest searchRequest = SearchRequest.newBuilder() .tableName("<TABLE_NAME>") .indexName("indexName") .searchQuery( SearchQuery.newBuilder() .query(QueryBuilders.matchAll()) .limit(0) //If you want to obtain only the aggregation results instead of specific data, set limit to 0 to improve query performance. .addAggregation(AggregationBuilders.percentiles("percentilesAgg", "latency") .percentiles(Arrays.asList(25.0d, 50.0d, 99.0d)) .missing(1.0)) .build()) .build(); //Execute the query statement. SearchResponse resp = client.search(searchRequest); //Obtain the results. PercentilesAggregationResult percentilesAggregationResult = resp.getAggregationResults().getAsPercentilesAggregationResult("percentilesAgg"); for (PercentilesAggregationItem item : percentilesAggregationResult.getPercentilesAggregationItems()) { System.out.println("key:" + item.getKey() + " value:" + item.getValue().asDouble()); } } //Create a query statement without using builder. { SearchRequest searchRequest = new SearchRequest(); searchRequest.setTableName("<TABLE_NAME>"); searchRequest.setIndexName("<SEARCH_INDEX_NAME>"); SearchQuery searchQuery = new SearchQuery(); MatchAllQuery query = new MatchAllQuery(); //In the following comment, builder is used to create a query statement. The method that uses builder to create a query statement has the same effect as the method that uses TermQuery to create a query statement. // Query query2 = QueryBuilders.matchAll().build(); searchQuery.setQuery(query); searchQuery.setLimit(0); PercentilesAggregation aggregation = new PercentilesAggregation(); aggregation.setAggName("percentilesAgg"); aggregation.setFieldName("latency"); aggregation.setPercentiles(Arrays.asList(25.0d, 50.0d, 99.0d)); //In the following comment, builder is used to create a query statement. The method that uses builder to create a query statement has the same effect as the method that uses aggregation to create a query statement. // AggregationBuilders.percentiles("percentilesAgg", "latency").percentiles(Arrays.asList(25.0d, 50.0d, 99.0d)).missing(1.0).build(); List<Aggregation> aggregationList = new ArrayList<Aggregation>(); aggregationList.add(aggregation); searchQuery.setAggregationList(aggregationList); //Execute the query statement. SearchResponse resp = client.search(searchRequest); //Obtain the results. PercentilesAggregationResult percentilesAggregationResult = resp.getAggregationResults().getAsPercentilesAggregationResult("percentilesAgg"); for (PercentilesAggregationItem item : percentilesAggregationResult.getPercentilesAggregationItems()) { System.out.println("key:" + item.getKey() + " value:" + item.getValue().asDouble()); } } }
Group by field value
The aggregation method that can be used to group query results based on field values. The values that are the same are grouped together. The value of each group and the number of members in each group are returned.
Group by field value uses parallel computing and is not an exact calculation. There may be slight errors.
If you want to group query results by multiple fields, use nested grouping or multi-field grouping. For information about the difference between these two methods, see Appendix: Different methods for multi-field grouping.
Parameters
Parameter
Description
groupByName
The unique name of the aggregation operation. Query the results of a specific aggregation operation based on this name.
fieldName
The name of the field that is used to perform the aggregation operation. Only the Long, Double, Boolean, Keyword, and Date types are supported.
groupBySorter
The sorting rules for groups. By default, groups are sorted based on the number of items in the groups in descending order. If you configure multiple sorting rules, the groups are sorted based on the order in which the rules are configured. The following sorting rules are supported:
groupKeySortInAsc: Sort by value in alphabetical order.
groupKeySortInDesc: Sort by value in reverse alphabetical order.
rowCountSortInAsc: Sort by row count in ascending order.
rowCountSortInDesc (default): Sort by row count in descending order.
subAggSortInAsc: Sort by the values that are obtained from sub-aggregation results in ascending order.
subAggSortInDesc: Sort by the values that are obtained from sub-aggregation results in descending order.
size
The number of groups that you want to return. Default value: 10. Maximum value: 2000.
subAggregations
The sub-aggregation operations that can be performed on the data in each group, such as calculating the maximum value, sum, or average value.
subGroupBys
The sub-grouping operations that can be performed on the data in each parent group to further group the data.
Examples
Group by single field
/** * Query the number of products, and the maximum and minimum product prices in each category. * Example of returned results: Fruits: 5. The maximum price is CNY 15, and the minimum price is CNY 3. Toiletries: 10. The maximum price is CNY 98, and the minimum price is CNY 1. Electronic devices: 3. The maximum price is CNY 8,699, and the minimum price is CNY 2,300. Other products: 15. The maximum price is CNY 1,000, and the minimum price is CNY 80. */ public void groupByField(SyncClient client) { //Use builder to create a query statement. { SearchRequest searchRequest = SearchRequest.newBuilder() .tableName("<TABLE_NAME>") .indexName("<SEARCH_INDEX_NAME>") .searchQuery( SearchQuery.newBuilder() .query(QueryBuilders.matchAll()) .limit(0) //If you want to obtain only the aggregation results instead of specific data, set limit to 0 to improve query performance. .addGroupBy(GroupByBuilders .groupByField("name1", "column_type") .addSubAggregation(AggregationBuilders.min("subName1", "column_price")) .addSubAggregation(AggregationBuilders.max("subName2", "column_price")) ) .build()) .build(); //Execute the query statement. SearchResponse resp = client.search(searchRequest); //Obtain the aggregation results. for (GroupByFieldResultItem item : resp.getGroupByResults().getAsGroupByFieldResult("name1").getGroupByFieldResultItems()) { //Display values. System.out.println(item.getKey()); //Display the number of rows. System.out.println(item.getRowCount()); //Display the minimum prices. System.out.println(item.getSubAggregationResults().getAsMinAggregationResult("subName1").getValue()); //Display the maximum prices. System.out.println(item.getSubAggregationResults().getAsMaxAggregationResult("subName2").getValue()); } } //Create a query statement without using builder. { SearchRequest searchRequest = new SearchRequest(); searchRequest.setTableName("<TABLE_NAME>"); searchRequest.setIndexName("<SEARCH_INDEX_NAME>"); SearchQuery searchQuery = new SearchQuery(); MatchAllQuery query = new MatchAllQuery(); //In the following comment, builder is used to create a query statement. The method that uses builder to create a query statement has the same effect as the method that uses TermQuery to create a query statement. // Query query2 = QueryBuilders.matchAll().build(); searchQuery.setQuery(query); searchQuery.setLimit(0); GroupByField groupByField = new GroupByField(); groupByField.setGroupByName("name1"); groupByField.setFieldName("column_type"); //Configure sub-aggregation operations. MinAggregation minAggregation = AggregationBuilders.min("subName1", "column_price").build(); MaxAggregation maxAggregation = AggregationBuilders.max("subName2", "column_price").build(); groupByField.setSubAggregations(Arrays.asList(minAggregation, maxAggregation)); //In the following comment, builder is used to create a query statement. The method that uses builder to create a query statement has the same effect as the method that uses aggregation to create a query statement. // GroupByBuilders.groupByField("name1", "column_type") // .addSubAggregation(AggregationBuilders.min("subName1", "column_price")) // .addSubAggregation(AggregationBuilders.max("subName2", "column_price").build()); List<GroupBy> groupByList = new ArrayList<GroupBy>(); groupByList.add(groupByField); searchQuery.setGroupByList(groupByList); searchRequest.setSearchQuery(searchQuery); //Execute the query statement. SearchResponse resp = client.search(searchRequest); //Obtain the aggregation results. for (GroupByFieldResultItem item : resp.getGroupByResults().getAsGroupByFieldResult("name1").getGroupByFieldResultItems()) { //Display values. System.out.println(item.getKey()); //Display the number of rows. System.out.println(item.getRowCount()); //Display the minimum prices. System.out.println(item.getSubAggregationResults().getAsMinAggregationResult("subName1").getValue()); //Display the maximum prices. System.out.println(item.getSubAggregationResults().getAsMaxAggregationResult("subName2").getValue()); } } }Group by multiple fields in nested mode
/** * Example of grouping query results by multiple fields in nested mode. * In a search index, use two groupBy fields in nested mode to achieve the same effect as using multiple groupBy fields in an SQL statement. * SQL statement: select a,d, sum(b),sum(c) from user group by a,d. */ public void GroupByMultiField(SyncClient client) { SearchRequest searchRequest = SearchRequest.newBuilder() .tableName("<TABLE_NAME>") .indexName("<SEARCH_INDEX_NAME>") .returnAllColumns(true) //Set returnAllColumns to false and specify a value for addColumesToGet to obtain better query performance. //.addColumnsToGet("col_1","col_2") .searchQuery(SearchQuery.newBuilder() .query(QueryBuilders.matchAll()) //Specify query conditions. Query conditions can be used in the same manner as the WHERE clause in SQL. Use QueryBuilders.bool() to perform nested queries. .addGroupBy( GroupByBuilders .groupByField("unique name_1", "field_a") .size(20) .addSubGroupBy( GroupByBuilders .groupByField("unique name_2", "field_d") .size(20) .addSubAggregation(AggregationBuilders.sum("unique name_3", "field_b")) .addSubAggregation(AggregationBuilders.sum("unique name_4", "field_c")) ) ) .build()) .build(); SearchResponse response = client.search(searchRequest); //Query rows that meet the specified conditions. List<Row> rows = response.getRows(); //Obtain the aggregation results. GroupByFieldResult groupByFieldResult1 = response.getGroupByResults().getAsGroupByFieldResult("unique name_1"); for (GroupByFieldResultItem resultItem : groupByFieldResult1.getGroupByFieldResultItems()) { System.out.println("field_a key:" + resultItem.getKey() + " Count:" + resultItem.getRowCount()); //Obtain the sub-aggregation results. GroupByFieldResult subGroupByResult = resultItem.getSubGroupByResults().getAsGroupByFieldResult("unique name_2"); for (GroupByFieldResultItem item : subGroupByResult.getGroupByFieldResultItems()) { System.out.println("field_a " + resultItem.getKey() + " field_d key:" + item.getKey() + " Count: " + item.getRowCount()); double sumOf_field_b = item.getSubAggregationResults().getAsSumAggregationResult("unique name_3").getValue(); double sumOf_field_c = item.getSubAggregationResults().getAsSumAggregationResult("unique name_4").getValue(); System.out.println("sumOf_field_b:" + sumOf_field_b); System.out.println("sumOf_field_c:" + sumOf_field_c); } } }Sort groups for aggregation
/** * Example of configuring sorting rules for aggregation. * Method: Configure sorting rules by specifying GroupBySorter. If you configure multiple sorting rules, the groups are sorted based on the order in which the rules are configured. GroupBySorter supports sorting in ascending or descending order. * By default, the groups are sorted by row count in descending order (GroupBySorter.rowCountSortInDesc()). */ public void groupByFieldWithSort(SyncClient client) { //Create a query statement. SearchRequest searchRequest = SearchRequest.newBuilder() .tableName("<TABLE_NAME>") .indexName("<SEARCH_INDEX_NAME>") .searchQuery( SearchQuery.newBuilder() .query(QueryBuilders.matchAll()) .limit(0) .addGroupBy(GroupByBuilders .groupByField("name1", "column_type") //.addGroupBySorter(GroupBySorter.subAggSortInAsc("subName1")) //Sort the groups in ascending order based on the values that are obtained from sub-aggregation results. .addGroupBySorter(GroupBySorter.groupKeySortInAsc()) //Sort the groups in ascending order based on the values that are obtained from aggregation results. //.addGroupBySorter(GroupBySorter.rowCountSortInDesc()) //Sort the groups in descending order based on the number of rows that are obtained from the aggregation results in each group. .size(20) .addSubAggregation(AggregationBuilders.min("subName1", "column_price")) .addSubAggregation(AggregationBuilders.max("subName2", "column_price")) ) .build()) .build(); //Execute the query statement. SearchResponse resp = client.search(searchRequest); }
Nested grouping
GroupBy supports nesting operations, which allows you to add sub-level aggregations based on parent-level grouping results.
To ensure the high performance of complex GroupBy operations, specify only a small number of levels for nesting. For more information, see Search index limits.
Common scenarios
Multi-level grouping (GroupBy + SubGroupBy)
After you group data at the first level, perform second-level grouping. For example, first group data by province and then by city to obtain data for each city in each province.
Grouping followed by aggregation (GroupBy + SubAggregation)
After you group data at the first level, perform aggregation operations (such as calculating the maximum value or average value) on the data in each group. For example, after you group data by province, obtain the maximum value of a specific metric for each province group.
Examples
The following example shows how to perform nested grouping by province and city, and calculate the total number of orders for each province and the total number of orders and maximum order amount for each city.
public static void subGroupBy(SyncClient client) { //Create a query statement. SearchRequest searchRequest = SearchRequest.newBuilder() .tableName("<TABLE_NAME>") .indexName("<SEARCH_INDEX_NAME>") .returnAllColumns(true) .searchQuery(SearchQuery.newBuilder() .query(QueryBuilders.matchAll()).limit(20) //First-level grouping: Group by province and count the number of order IDs (total orders) for each province. //Second-level grouping: Group by city and count the number of order IDs (total orders) for each city, and calculate the maximum order amount for each city. .addGroupBy(GroupByBuilders.groupByField("provinceName", "province") .addSubAggregation(AggregationBuilders.count("provinceOrderCounts", "order_id")) .addGroupBySorter(GroupBySorter.rowCountSortInDesc()) .addSubGroupBy(GroupByBuilders.groupByField("cityName", "city") .addSubAggregation(AggregationBuilders.count("cityOrderCounts", "order_id")) .addSubAggregation(AggregationBuilders.max("cityMaxAmount", "order_amount")) .addGroupBySorter(GroupBySorter.subAggSortInDesc("cityMaxAmount")))) .build()) .build(); //Execute the query statement. SearchResponse resp = client.search(searchRequest); //Obtain the first-level grouping results (total orders for each province) GroupByFieldResult results = resp.getGroupByResults().getAsGroupByFieldResult("provinceName"); for (GroupByFieldResultItem item : results.getGroupByFieldResultItems()) { System.out.println("Province:" + item.getKey() + "\tTotal Orders:" + item.getSubAggregationResults().getAsCountAggregationResult("provinceOrderCounts").getValue()); //Obtain the second-level grouping results (total orders and maximum order amount for each city) GroupByFieldResult subResults = item.getSubGroupByResults().getAsGroupByFieldResult("cityName"); for (GroupByFieldResultItem subItem : subResults.getGroupByFieldResultItems()) { System.out.println("\t(City)" + subItem.getKey() + "\tTotal Orders:" + subItem.getSubAggregationResults().getAsCountAggregationResult("cityOrderCounts").getValue() + "\tMaximum Order Amount:" + subItem.getSubAggregationResults().getAsMaxAggregationResult("cityMaxAmount").getValue()); } } }
Group by multiple fields
The aggregation method that can be used to group query results based on multiple fields. Use tokens to perform paging.
Parameters
Parameter
Description
groupByName
The unique name of the aggregation operation. Query the results of a specific aggregation operation based on this name.
sources
The fields by which you want to group query results. Group query results by up to 32 fields and perform aggregation operations on the resulting groups. The following group types are supported:
GroupByField: Group by field value. Configure the groupByName, fieldName, and groupBySorter parameters.
GroupByHistogram: Query by histogram. Configure the groupByName, fieldName, interval, and groupBySorter parameters.
GroupByDateHistogram: Query by date histogram. Configure the groupByName, fieldName, interval, timeZone, and groupBySorter parameters.
ImportantFor group items in sources, only sorting by group value (groupKeySort) in dictionary order is supported. By default, groups are sorted in descending order.
If a field value does not exist for a specific column, the value in the returned results will be NULL.
nextToken
The pagination token that is used to retrieve the next page of data. By default, this parameter is empty.
For the first request, set nextToken to empty. If not all data that meets the query conditions is returned in a single request, the nextToken parameter in the response is not empty. Use this nextToken for pagination queries.
NoteIf you need to persist the nextToken or transmit it to a frontend page, we recommend that you use Base64 encoding to encode the nextToken as a string before saving or transmitting it. The nextToken itself is not a string. If you directly use new String(nextToken) for encoding, token information will be lost.
size
The number of groups per page. Default value: 10. Maximum value: 2000.
ImportantIf you want to limit the number of groups to return, in most cases, we recommend that you configure the size parameter.
You cannot configure the size and suggestedSize parameters at the same time.
suggestedSize
The number of groups to return. Specify a value greater than the maximum number of groups allowed at the server side or -1. The server side returns the number of groups based on its capacity.
If you set this parameter to a value that is greater than the maximum number of groups allowed at the server side, the system adjusts the value to the maximum number of groups allowed at the server side. The actual number of groups that are returned equals min(suggestedSize, maximum number of groups allowed at the server side, total number of groups).
ImportantThis parameter is suitable for scenarios in which you interconnect Tablestore with a high-throughput computing engine, such as Apache Spark or PrestoSQL.
subAggregations
The sub-aggregation operations that can be performed on the data in each group, such as calculating the maximum value, sum, or average value.
subGroupBys
The sub-grouping operations that can be performed on the data in each parent group to further group the data.
ImportantThe GroupByComposite parameter is not supported in subGroupBy.
Examples
/** * Group and aggregate query results: Group the query results and perform the aggregation operation on the resulting groups based on the parameters such as groupbyField, groupByHistogram, and groupByDataHistogram that are passed to the SourceGroupBy parameter. * Return the aggregated results of multiple fields in a flat structure. */ public static void groupByComposite(SyncClient client) { GroupByComposite.Builder compositeBuilder = GroupByBuilders .groupByComposite("groupByComposite") .size(2000) .addSources(GroupByBuilders.groupByField("groupByField", "Col_Keyword") .addGroupBySorter(GroupBySorter.groupKeySortInAsc()).build()) .addSources(GroupByBuilders.groupByHistogram("groupByHistogram", "Col_Long") .addGroupBySorter(GroupBySorter.groupKeySortInAsc()) .interval(5) .build()) .addSources(GroupByBuilders.groupByDateHistogram("groupByDateHistogram", "Col_Date") .addGroupBySorter(GroupBySorter.groupKeySortInAsc()) .interval(5, DateTimeUnit.DAY) .timeZone("+05:30").build()); SearchRequest searchRequest = SearchRequest.newBuilder() .indexName("<SEARCH_INDEX_NAME>") .tableName("<TABLE_NAME>") .returnAllColumnsFromIndex(true) .searchQuery(SearchQuery.newBuilder() .addGroupBy(compositeBuilder.build()) .build()) .build(); SearchResponse resp = client.search(searchRequest); while (true) { if (resp.getGroupByResults() == null || resp.getGroupByResults().getResultAsMap().size() == 0) { System.out.println("groupByComposite Result is null or empty"); return; } GroupByCompositeResult result = resp.getGroupByResults().getAsGroupByCompositeResult("groupByComposite"); if(!result.getSourceNames().isEmpty()) { for (String sourceGroupByNames: result.getSourceNames()) { System.out.printf("%s\t", sourceGroupByNames); } System.out.print("rowCount\t\n"); } for (GroupByCompositeResultItem item : result.getGroupByCompositeResultItems()) { for (String value : item.getKeys()) { String val = value == null ? "NULL" : value; System.out.printf("%s\t", val); } System.out.printf("%d\t\n", item.getRowCount()); } // Use the token to page through groups. if (result.getNextToken() != null) { searchRequest.setSearchQuery( SearchQuery.newBuilder() .addGroupBy(compositeBuilder.nextToken(result.getNextToken()).build()) .build() ); resp = client.search(searchRequest); } else { break; } } }
Group by range
The aggregation method that can be used to group query results based on the value ranges of a field. Field values that are within a specific range are grouped together. The number of values in each range is returned.
Parameters
Parameter
Description
groupByName
The unique name of the aggregation operation. Query the results of a specific aggregation operation based on this name.
fieldName
The name of the field that is used to perform the aggregation operation. Only the Long and Double types are supported.
range[double_from, double_to)
The value ranges for grouping.
Set double_from to Double.MIN_VALUE to specify the minimum value and set double_to to Double.MAX_VALUE to specify the maximum value.
subAggregation and subGroupBy
The sub-aggregation operation. Perform the sub-aggregation operation based on the grouping results.
For example, after you group query results by sales volume and by province, get the province that has the largest proportion of sales volume in a specified range. You need to specify GroupByField in GroupByRange to perform this query.
Examples
/** * Group sales volumes based on ranges [0, 1000), [1000, 5000), and [5000, Double.MAX_VALUE) to obtain the sales volume in each range. */ public void groupByRange(SyncClient client) { //Create a query statement. SearchRequest searchRequest = SearchRequest.newBuilder() .tableName("<TABLE_NAME>") .indexName("<SEARCH_INDEX_NAME>") .searchQuery( SearchQuery.newBuilder() .query(QueryBuilders.matchAll()) .limit(0) .addGroupBy(GroupByBuilders .groupByRange("name1", "column_number") .addRange(0, 1000) .addRange(1000, 5000) .addRange(5000, Double.MAX_VALUE) ) .build()) .build(); //Execute the query statement. SearchResponse resp = client.search(searchRequest); //Obtain the aggregation results. for (GroupByRangeResultItem item : resp.getGroupByResults().getAsGroupByRangeResult("name1").getGroupByRangeResultItems()) { //Display the number of rows. System.out.println(item.getRowCount()); } }
Group by geographical location
The aggregation method that can be used to group query results based on distances from geographical locations to a central point. Query results in distances that are within a specific range are grouped together. The number of values in each range is returned.
Parameters
Parameter
Description
groupByName
The unique name of the aggregation operation. Query the results of a specific aggregation operation based on this name.
fieldName
The name of the field that is used to perform the aggregation operation. Only the Geo_point type is supported.
origin(double lat, double lon)
The longitude and latitude of the central point.
double lat specifies the latitude of the central point. double lon specifies the longitude of the central point.
range[double_from, double_to)
The distance ranges that are used for grouping. Unit: meters.
Set double_from to Double.MIN_VALUE to specify the minimum value and set double_to to Double.MAX_VALUE to specify the maximum value.
subAggregation and subGroupBy
The sub-aggregation operation. Perform the sub-aggregation operation based on the grouping results.
Examples
/** * Group users based on geographical locations to a Wanda Plaza to obtain the number of users in each distance range. The distance ranges are [0, 1000), [1000, 5000), and [5000, Double.MAX_VALUE). Unit: meters. */ public void groupByGeoDistance(SyncClient client) { //Create a query statement. SearchRequest searchRequest = SearchRequest.newBuilder() .tableName("<TABLE_NAME>") .indexName("<SEARCH_INDEX_NAME>") .searchQuery( SearchQuery.newBuilder() .query(QueryBuilders.matchAll()) .limit(0) .addGroupBy(GroupByBuilders .groupByGeoDistance("name1", "column_geo_point") .origin(3.1, 6.5) .addRange(0, 1000) .addRange(1000, 5000) .addRange(5000, Double.MAX_VALUE) ) .build()) .build(); //Execute the query statement. SearchResponse resp = client.search(searchRequest); //Obtain the aggregation results. for (GroupByGeoDistanceResultItem item : resp.getGroupByResults().getAsGroupByGeoDistanceResult("name1").getGroupByGeoDistanceResultItems()) { //Display the number of rows. System.out.println(item.getRowCount()); } }
Group by filter
The aggregation method that can be used to filter the query results and group them based on each filter to obtain the number of matching results. Results are returned in the order in which the filters are specified.
Parameters
Parameter
Description
groupByName
The unique name of the aggregation operation. Query the results of a specific aggregation operation based on this name.
filter
The filters that can be used for the query. Results are returned in the order in which the filters are specified.
subAggregation and subGroupBy
The sub-aggregation operation. Perform the sub-aggregation operation based on the grouping results.
Examples
/** * Specify the following filters to obtain the number of items that match each filter: The sales volume exceeds 100, the place of origin is Zhejiang, and the description contains Hangzhou. */ public void groupByFilter(SyncClient client) { //Create a query statement. SearchRequest searchRequest = SearchRequest.newBuilder() .tableName("<TABLE_NAME>") .indexName("<SEARCH_INDEX_NAME>") .searchQuery( SearchQuery.newBuilder() .query(QueryBuilders.matchAll()) .limit(0) .addGroupBy(GroupByBuilders .groupByFilter("name1") .addFilter(QueryBuilders.range("number").greaterThanOrEqual(100)) .addFilter(QueryBuilders.term("place","Zhejiang")) .addFilter(QueryBuilders.match("text","Hangzhou")) ) .build()) .build(); //Execute the query statement. SearchResponse resp = client.search(searchRequest); //Obtain the aggregation results based on the order of filters. for (GroupByFilterResultItem item : resp.getGroupByResults().getAsGroupByFilterResult("name1").getGroupByFilterResultItems()) { //Display the number of rows. System.out.println(item.getRowCount()); } }
Histogram statistics
The aggregation method can be used to group query results based on specific data intervals. Field values that are within the same range are grouped together. The value range of each group and the number of values in each group are returned.
Parameters
Parameter
Description
groupByName
The unique name of the aggregation operation. Query the results of a specific aggregation operation based on this name.
fieldName
The name of the field that is used to perform the aggregation operation. Only the Long and Double types are supported.
interval
The data interval that is used to obtain aggregation results.
fieldRange[min,max]
The range that is used together with the interval parameter to limit the number of groups. The number of groups that is determined by using the
(fieldRange.max-fieldRange.min)/intervalformula cannot exceed 2,000.minDocCount
The minimum number of rows. If the number of rows in a group is less than the minimum number of rows, the aggregation results for the group are not returned.
missing
The default value for the field on which the aggregation operation is performed, which is applied to rows in which the field value is empty.
If you do not specify a value for the missing parameter, the row is ignored.
If you specify a value for the missing parameter, the value of this parameter is used as the field value of the row.
Examples
/** * Collect statistics on the distribution of users by age group. */ public static void groupByHistogram(SyncClient client) { //Create a query statement. SearchRequest searchRequest = SearchRequest.newBuilder() .tableName("<TABLE_NAME>") .indexName("<SEARCH_INDEX_NAME>") .searchQuery( SearchQuery.newBuilder() .addGroupBy(GroupByBuilders .groupByHistogram("groupByHistogram", "age") .interval(10) .minDocCount(0L) .addFieldRange(0, 99)) .build()) .build(); //Execute the query statement. SearchResponse resp = ots.search(searchRequest); //Obtain the results that are returned when the aggregation operation is performed. GroupByHistogramResult results = resp.getGroupByResults().getAsGroupByHistogramResult("groupByHistogram"); for (GroupByHistogramItem item : results.getGroupByHistogramItems()) { System.out.println("key:" + item.getKey().asLong() + " value:" + item.getValue()); } }
Query by date histogram
The aggregation method that can be used to group query results based on specific date intervals. Field values that are within the same range are grouped together. The value range of each group and the number of values in each group are returned.
This feature is supported by Tablestore SDK for Java V5.16.1 and later. For information about the version history of Tablestore SDK for Java, see Version history of Tablestore SDK for Java.
Parameters
Parameter
Description
groupByName
The unique name of the aggregation operation. Query the results of a specific aggregation operation based on this name.
fieldName
The name of the field that is used to perform the aggregation operation. Only the Date type is supported.
ImportantThe Date type of search indexes is supported by Tablestore SDK for Java V5.13.9 and later.
interval
Statistical interval.
fieldRange[min,max]
The range that is used together with the interval parameter to limit the number of groups. The number of groups that is determined by using the
(fieldRange.max-fieldRange.min)/intervalformula cannot exceed 2,000.minDocCount
The minimum number of rows. If the number of rows in a group is less than the minimum number of rows, the aggregation results for the group are not returned.
missing
The default value for the field on which the aggregation operation is performed, which is applied to rows in which the field value is empty.
If you do not specify a value for the missing parameter, the row is ignored.
If you specify a value for the missing parameter, the value of this parameter is used as the field value of the row.
timeZone
The time zone in the
+hh:mmor-hh:mmformat, such as+08:00or-09:00. This parameter is required only when the field is of the Date type.If this parameter is not specified for the field of the Date type, the offset of N hours may occur in the aggregation results. Specify the timeZone parameter to prevent this issue.
Examples
/** * Collect statistics on the daily distribution of data in the col_date field from 10:00:00 on May 1, 2017 to 13:00:00 May 21, 2017. */ public static void groupByDateHistogram(SyncClient client) { //Create a query statement. SearchRequest searchRequest = SearchRequest.newBuilder() .returnAllColumns(false) .indexName("<SEARCH_INDEX_NAME>") .tableName("<TABLE_NAME>") .searchQuery( SearchQuery.newBuilder() .query(QueryBuilders.matchAll()) .limit(0) .getTotalCount(false) .addGroupBy(GroupByBuilders .groupByDateHistogram("groupByDateHistogram", "col_date") .interval(1, DateTimeUnit.DAY) .minDocCount(1) .missing("2017-05-01 13:01:00") .fieldRange("2017-05-01 10:00", "2017-05-21 13:00:00")) .build()) .build(); //Execute the query statement. SearchResponse resp = ots.search(searchRequest); //Obtain the results that are returned when the aggregation operation is performed. List<GroupByDateHistogramItem> items = resp.getGroupByResults().getAsGroupByDateHistogramResult("groupByDateHistogram").getGroupByDateHistogramItems(); for (GroupByDateHistogramItem item : items) { System.out.printf("millisecondTimestamp:%d, count:%d \n", item.getTimestamp(), item.getRowCount()); } }
Query the rows that are obtained from the results of an aggregation operation in each group
After you group query results, query the rows in each group. This method can be used in a similar manner as ANY_VALUE(field) in MySQL.
When you query the rows that are obtained from the results of an aggregation operation in each group, the returned results contain only the primary key information if the search index contains the NESTED, GEOPOINT, or ARRAY field. To obtain the required field, you must query the data table.
Parameters
Parameter
Description
aggregationName
The unique name of the aggregation operation. Query the results of a specific aggregation operation based on this name.
limit
The maximum number of rows that can be returned for each group. By default, only one row of data is returned.
sort
The sorting method that is used to sort data in groups.
columnsToGet
The fields that you want to return. Only fields in search indexes are supported. Array, Date, Geopoint, and Nested fields are not supported.
The value of this parameter is the same as the value of the columnsToGet parameter in SearchRequest. You need to only specify a value for the columnsToGet parameter in SearchRequest.
Examples
/** * An activity application form of a school contains fields in which information such as the names of students, classes, head teachers, and class presidents can be specified. Group students by class to view the application statistics and the property information of each class. * SQL statement: select className, teacher, monitor, COUNT(*) as number from table GROUP BY className. */ public void testTopRows(SyncClient client) { SearchRequest searchRequest = SearchRequest.newBuilder() .indexName("<SEARCH_INDEX_NAME>") .tableName("<TABLE_NAME>") .searchQuery( SearchQuery.newBuilder() .query(QueryBuilders.matchAll()) .limit(0) .addGroupBy(GroupByBuilders.groupByField("groupName", "className") .size(5) //Specify the number of groups that you want to return. For information about the maximum value that you can specify for the number of groups to return, see the description of the number of groups returned by GroupByField in the "Search index limits" topic. .addSubAggregation(AggregationBuilders.topRows("topRowsName") .limit(1) .sort(new Sort(Arrays.asList(new FieldSort("teacher", SortOrder.DESC)))) //Sort rows by teacher in descending order. ) ) .build()) .addColumnsToGet(Arrays.asList("teacher", "monitor")) .build(); SearchResponse resp = client.search(searchRequest); List<GroupByFieldResultItem> items = resp.getGroupByResults().getAsGroupByFieldResult("groupName").getGroupByFieldResultItems(); for (GroupByFieldResultItem item : items) { String className = item.getKey(); long number = item.getRowCount(); List<Row> topRows = item.getSubAggregationResults().getAsTopRowsAggregationResult("topRowsName").getRows(); Row row = topRows.get(0); String teacher = row.getLatestColumn("teacher").getValue().asString(); String monitor = row.getLatestColumn("monitor").getValue().asString(); } }
Multiple aggregations
You can perform multiple aggregation operations.
If you perform multiple complex aggregation operations at the same time, a long period of time may be required.
Combine multiple aggregations
public void multipleAggregation(SyncClient client) {
//Create a query statement.
SearchRequest searchRequest = SearchRequest.newBuilder()
.tableName("<TABLE_NAME>")
.indexName("<SEARCH_INDEX_NAME>")
.searchQuery(
SearchQuery.newBuilder()
.query(QueryBuilders.matchAll())
.limit(0)
.addAggregation(AggregationBuilders.min("name1", "long"))
.addAggregation(AggregationBuilders.sum("name2", "long"))
.addAggregation(AggregationBuilders.distinctCount("name3", "long"))
.build())
.build();
//Execute the query statement.
SearchResponse resp = client.search(searchRequest);
//Obtain the minimum value from the results of the aggregation operation.
System.out.println(resp.getAggregationResults().getAsMinAggregationResult("name1").getValue());
//Obtain the sum from the results of the aggregation operation.
System.out.println(resp.getAggregationResults().getAsSumAggregationResult("name2").getValue());
//Obtain the number of distinct values from the results of the aggregation operation.
System.out.println(resp.getAggregationResults().getAsDistinctCountAggregationResult("name3").getValue());
}Combine Aggregation and GroupBy
public void multipleGroupBy(SyncClient client) {
//Create a query statement.
SearchRequest searchRequest = SearchRequest.newBuilder()
.tableName("<TABLE_NAME>")
.indexName("<SEARCH_INDEX_NAME>")
.searchQuery(
SearchQuery.newBuilder()
.query(QueryBuilders.matchAll())
.limit(0)
.addAggregation(AggregationBuilders.min("name1", "long"))
.addAggregation(AggregationBuilders.sum("name2", "long"))
.addAggregation(AggregationBuilders.distinctCount("name3", "long"))
.addGroupBy(GroupByBuilders.groupByField("name4", "type"))
.addGroupBy(GroupByBuilders.groupByRange("name5", "long").addRange(1, 15))
.build())
.build();
//Execute the query statement.
SearchResponse resp = client.search(searchRequest);
//Obtain the minimum value from the results of the aggregation operation.
System.out.println(resp.getAggregationResults().getAsMinAggregationResult("name1").getValue());
//Obtain the sum from the results of the aggregation operation.
System.out.println(resp.getAggregationResults().getAsSumAggregationResult("name2").getValue());
//Obtain the number of distinct values from the results of the aggregation operation.
System.out.println(resp.getAggregationResults().getAsDistinctCountAggregationResult("name3").getValue());
//Obtain the values of GroupByField from the results of the aggregation operation.
for (GroupByFieldResultItem item : resp.getGroupByResults().getAsGroupByFieldResult("name4").getGroupByFieldResultItems()) {
//Display the keys.
System.out.println(item.getKey());
//Display the number of rows.
System.out.println(item.getRowCount());
}
//Obtain the values of GroupByRange from the results of the aggregation operation.
for (GroupByRangeResultItem item : resp.getGroupByResults().getAsGroupByRangeResult("name5").getGroupByRangeResultItems()) {
//Display the number of rows.
System.out.println(item.getRowCount());
}
}Appendix: Different methods for multi-field grouping
If you want to group query results by multiple fields, use the groupBy parameter in nested mode or use the GroupByComposite parameter. The following table describes the difference between the groupBy parameter in nested mode and the GroupByComposite parameter.
Feature | groupBy (nested) | Multi-field grouping |
size | 2000 | 2000 |
Limits on fields | Up to 3 levels are supported. | Up to 32 levels are supported. |
Pagination | Not supported | Supported by using the nextToken parameter |
Sorting rules for rows in groups |
| In alphabetical order or reverse alphabetical order |
Supports aggregation | Yes | Yes |
Compatibility | For fields of the Date type, the query results are returned in the specified format. | For fields of the DATE type, the query results are returned as timestamp strings. |
References
You can also refer to the following topics to query and analyze data in data tables.
Use the SQL query feature of Tablestore. For more information, see SQL query.
Connect Tablestore to big data platforms, such as DataWorks to perform SQL queries and analyze data. For more information, see Connect Tablestore to big data platforms.
Connect Tablestore to computing engines, such as MaxCompute, Spark, Hive, HadoopMR, Function Compute, Flink, and PrestoDB to perform SQL queries and analyze data. For more information, see Overview.