You can query collected logs in real time in the Simple Log Service console and ship the logs to MaxCompute for business intelligence (BI) analysis and data mining. This topic describes how to ship logs to MaxCompute in the Simple Log Service console.
The old version of shipping logs to MaxCompute is discontinued. Refer to the new version.
Prerequisites
MaxCompute is activated and a MaxCompute table is created. For more information, see Create tables.
Limits
You can create data shipping jobs only by using an Alibaba Cloud account. You cannot create data shipping jobs by using a RAM user.
Do not ship logs from multiple Logstores to a MaxCompute table. If you ship logs from multiple Logstores to a MaxCompute table, the existing data in the MaxCompute table may be overwritten.
Logs that are generated 14 days before the current day are automatically discarded in data shipping jobs. The _time_ field specifies the point in time when logs are generated.
You cannot ship logs whose data type is DECIMAL, DATETIME, DATE, or TIMESTAMP to MaxCompute. For more information, see MaxCompute V2.0 data type edition.
The following table describes the regions that support data shipping to MaxCompute. If Simple Log Service is deployed in other regions, use DataWorks to synchronize data. For more information, see Use Data Integration to synchronize data from a LogHub data source to a destination.
Region where your Simple Log Service project resides
Region where a MaxCompute project resides
China (Qingdao)
China (Shanghai)
China (Beijing)
China (Beijing) and China (Shanghai)
China (Zhangjiakou)
China (Shanghai)
China (Hohhot)
China (Shanghai)
China (Hangzhou)
China (Shanghai)
China (Shanghai)
China (Shanghai)
China (Shenzhen)
China (Shenzhen) and China (Shanghai)
China (Hong Kong)
China (Shanghai)
Step 1: Create a data shipping job
Log on to the Simple Log Service console.
In the Projects section, click the one you want to manage.

Choose . On the Logstores tab, find the Logstore that you want to manage, click > and choose .
On the MaxCompute (Formerly ODPS) LogShipper page, click Enable.
In the Shipping Notes dialog box, click Ship.
In the Ship Data to MaxCompute panel, configure the shipping rule and click OK.
The following table describes the parameters.
Parameter
Description
Select Region
The regions where MaxCompute is supported vary with the region where your Simple Log Service project resides. For more information, see Limits.
Shipping Job Name
The name of the data shipping job.
MaxCompute Project Name
The name of the MaxCompute project.
Table Name
The name of the MaxCompute table.
MaxCompute Common Column
The mappings between log fields and data columns in the MaxCompute table. In the left field, enter the name of a log field that you want to map to a data column in the MaxCompute table. In the right field, enter the name of the column. For more information, see Data model mapping.
ImportantSimple Log Service ships logs to MaxCompute based on the sequence of the specified log fields and MaxCompute table columns. Changing the names of these columns do not affect the data shipping process. If you modify the schema of a MaxCompute table, you must reconfigure the mappings between log fields and MaxCompute table columns.
The name of the log field that you specify in the left field cannot contain double quotation marks ("") or single quotation marks (''). The name cannot be a string that contains spaces.
- If a log contains two fields that have the same name, such as request_time, Log Service displays one of the fields as request_time_0. The two fields are still stored as request_time in Log Service. When you configure a shipping rule, you can use only the original field name request_time.
If a log contains fields that have the same name, Log Service randomly ships the value of one of the fields. We recommend that you do not include fields that have the same name in your logs.
MaxCompute Partition Column
The mappings between log fields and partition key columns in the MaxCompute table. In the left field, enter the name of a log field that you want to map to a partition key column in the MaxCompute table. In the right field, enter the name of the column. For more information, see Data model mapping.
NoteYou can specify up to three partition key columns. If you specify custom fields as partition key columns, make sure that the number of partitions that can be generated in a data shipping job is less than 512. If the number of partitions is greater than or equal to 512, the data shipping job fails to write data to the specified MaxCompute table, and no data can be shipped.
Partition Format
For information about the configuration examples and parameters of the partition format, see Examples and Java SimpleDateFormat.
NoteThe partition format takes effect only if a partition field in the MaxCompute Partition Column parameter is set to __partition_time__.
We recommend that you do not specify a time partition format that is accurate to seconds. If you specify a time partition format that is accurate to seconds, the number of partitions in the MaxCompute table may exceed the limit of 60,000.
Make sure that the number of partitions processed by each data shipping job is less than 512.
Shipping Interval
The duration of the data shipping job. Default value: 1800. Unit: seconds.
When the specified duration elapses, another data shipping job is created.
After data shipping is enabled, log data is shipped to MaxCompute in 1 hour after the data is written to the Logstore. After the log data is shipped, you can view the log data in MaxCompute. For more information, see How do I check the completeness of data that is shipped from Simple Log Service to MaxCompute?
Step 2: View data in MaxCompute
After data is shipped to MaxCompute, you can view the data in MaxCompute. The following code shows sample data. You can use the big data development tool Data IDE that is integrated with MaxCompute to consume data and perform BI analysis and data mining in a visualized manner.
| log_source | log_time | log_topic | time | ip | thread | log_extract_others | log_partition_time | status |
+------------+------------+-----------+-----------+-----------+-----------+------------------+--------------------+-----------+
| 10.10.*.* | 1453899013 | | 27/Jan/2016:20:50:13 +0800 | 10.10.*.* | 414579208 | {"url":"POST /PutData?Category=YunOsAccountOpLog&AccessKeyId=****************&Date=Fri%2C%2028%20Jun%202013%2006%3A53%3A30%20GMT&Topic=raw&Signature=******************************** HTTP/1.1","user-agent":"aliyun-sdk-java"} | 2016_01_27_20_50 | 200 |
+------------+------------+-----------+-----------+-----------+-----------+------------------+--------------------+-----------+Grant the account for Simple Log Service the permissions to ship data
If you delete a MaxCompute table and create a new MaxCompute table in the DataWorks console, the default authorization that is performed for the previous table becomes invalid. You must grant Simple Log Service the permissions to ship data.
Log on to the DataWorks console.
In the top navigation bar, select the required region.
In the left-side navigation pane, click Workspaces.
On the Workspaces page, find the workspace that you want to manage, move the pointer over Shortcuts, and then click Data Development.
Create a workflow.
On the Scheduled Workflow page, choose .
In the Create Workflow dialog box, configure the Workflow Name parameter and click Create.
Create a node.
On the Scheduled Workflow page, choose .
In the Create Node dialog box, configure the Name and Path parameters, and then click Commit.
You must set Path to the workflow that you created in Step 5.
In the editor of the node, run the required commands to complete the authorization. The following table describes the commands.
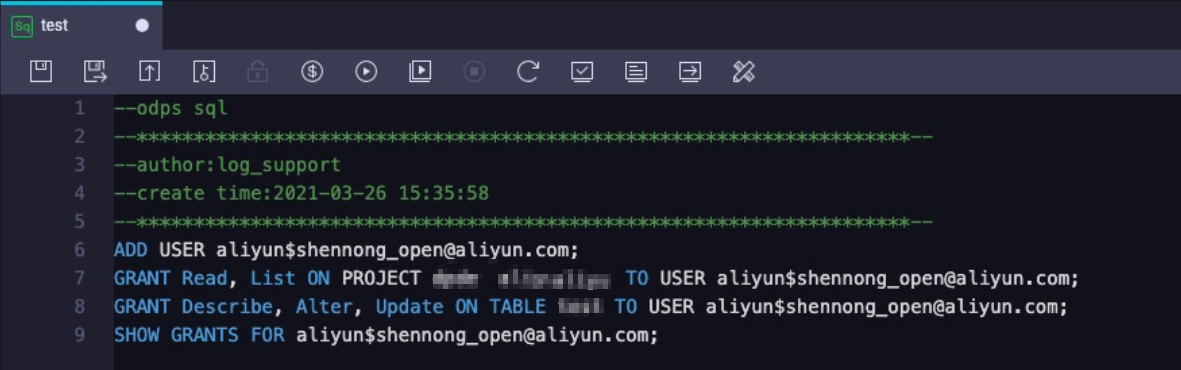
Command
Description
ADD USER aliyun$shennong_open@aliyun.com;Adds a user to the MaxCompute project.
shennong_open@aliyun.com indicates the account for Simple Log Service. You cannot change this value.
GRANT Read, List ON PROJECT {ODPS_PROJECT_NAME} TO USER aliyun$shennong_open@aliyun.com;Grants the user the permissions to read and query MaxCompute projects.
{ODPS_PROJECT_NAME} specifies the name of the MaxCompute project. Replace the variable with an actual project name.
GRANT Describe, Alter, Update ON TABLE {ODPS_TABLE_NAME} TO USER aliyun$shennong_open@aliyun.com;Grants the user the Describe permission, Alter permission, and Update permission.
{ODPS_TABLE_NAME} specifies the name of the MaxCompute table. Replace the variable with an actual table name.
SHOW GRANTS FOR aliyun$shennong_open@aliyun.com;Checks whether the authorization is successful.
If an output that is similar to the following example appears, the authorization is successful:
A projects/{ODPS_PROJECT_NAME}: List | Read A projects/{{ODPS_PROJECT_NAME}/tables/{ODPS_TABLE_NAME}: Describe | Alter | Update
Related operations
After you create a data shipping job, you can modify the job on the MaxCompute (Formerly ODPS) LogShipper page. You can also disable the data shipping feature, view the status and error messages of jobs, and retry failed jobs.
Modify a data shipping job.
Click Settings to modify the data shipping job. For information about the parameters, see Step 1: Create a data shipping job. If you want to add a column, you can modify the schema of the corresponding table in MaxCompute.
Disable the data shipping feature.
Click Disable. The data in the Logstore is no longer shipped to MaxCompute.
View the status and error messages of data shipping jobs.
You can view the data shipping jobs that are performed on the previous two days and the status of the jobs.
Job status
Status
Description
Success
The data shipping job succeeded.
Running
The data shipping job is running. Check whether the job succeeds later.
Failed
The data shipping job failed. If the job cannot be restarted due to external reasons, troubleshoot the failure based on the error message and retry the job. For example, the MaxCompute schema does not comply with the Simple Log Service specifications or Simple Log Service is not authorized to access MaxCompute.
Simple Log Service allows you to retry all failed jobs of the last two days.
Error messages
If a data shipping job fails, an error message is returned for the job.
Error message
Solution
The MaxCompute project does not exist.
Check whether the specified MaxCompute project exists in the MaxCompute console. If the MaxCompute project does not exist, you must create a MaxCompute project. Simple Log Service does not automatically retry the job that fails due to this error. You must manually retry the job after you fix the issue.
The MaxCompute table does not exist.
Check whether the MaxCompute table that is specified exists in the MaxCompute console. If the MaxCompute table does not exist, you must create a MaxCompute table. Simple Log Service does not automatically retry the job that fails due to this error. You must manually retry the job after you fix the issue.
Simple Log Service is not authorized to access the MaxCompute project or table.
Check whether the required permissions are granted to the account that is used to log on to Simple Log Service in the MaxCompute console. If not, grant permissions to the account. For more information, see Grant the account for Simple Log Service the permissions to ship data. Simple Log Service does not automatically retry the job that fails due to this error. You must manually retry the job after you fix the issue.
A MaxCompute error has occurred.
A MaxCompute error is returned for the data shipping job. For more information, see the MaxCompute documentation or contact MaxCompute technical support. Simple Log Service automatically retries all failed jobs of the last two days.
The MaxCompute schema does not comply with the Simple Log Service specifications.
Reconfigure the mappings between the columns of the MaxCompute table and the log fields in Simple Log Service. Simple Log Service does not automatically retry the job that fails due to this error. You must manually retry the job after you fix the issue.
Retry a data shipping job
SIMPLE Log Service automatically retries the jobs that fail due to internal errors. In other cases, you must manually retry failed jobs. The minimum interval between two consecutive automatic retries is 30 minutes. If a job fails, wait for 30 minutes before you retry the job. Simple Log Service allows you to retry all failed jobs of the last two days.
To immediately retry a failed job, you can click Retry All Failed Tasks. You can also call an API operation or use an SDK to retry a job.
References
__partition_time__
In most cases, MaxCompute filters data by time or uses the timestamp of a log as a partition field.
Format
The value of the __partition_time__ field is calculated based on the value of the __time__ field in Simple Log Service and is rounded down to the nearest integer based on the partition time format. The value of the date partition key column is specified based on the shipping interval. This prevents the number of partitions in a single MaxCompute table from exceeding the limit.
For example, if the timestamp of a log in Simple Log Service is 27/Jan/2016 20:50:13 +0800, Simple Log Service calculates the value of the __time__ field based on the timestamp. The value is a UNIX timestamp of 1453899013. The following table describes the values of the time partition column in different configurations.
Shipping Interval
Partition Format
__partition_time__
1800
yyyy_MM_dd_HH_mm_00
2016_01_27_20_30_00
1800
yyyy-MM-dd HH:mm
2016-01-27 20:30
1800
yyyyMMdd
20160127
3600
yyyyMMddHHmm
201601272000
3600
yyyy_MM_dd_HH
2016_01_27_20
Usage
You can use the __partition_time__ field to filter data to prevent a full-table scan. For example, you can execute the following query statement to query the log data of January 26, 2016:
select * from {ODPS_TABLE_NAME} where log_partition_time >= "2015_01_26" and log_partition_time < "2016_01_27";
__extract_others__
__extract_others__ indicates a JSON string. For example, you can execute the following query statement to obtain the user-agent content of this field:
select get_json_object(sls_extract_others, "$.user-agent") from {ODPS_TABLE_NAME} limit 10;Noteget_json_object indicates the standard user-defined function (UDF) provided by MaxCompute. Contact MaxCompute technical support to grant the permissions that are required to use the standard UDF. For more information, see Standard UDF provided by MaxCompute.
The preceding example is for reference only. The instructions provided in MaxCompute documentation prevail.
Data model mapping
If a data shipping job ships data from Simple Log Service to MaxCompute, the data model mapping between the two services is enabled. The following table describes the usage notes and provides examples.
A MaxCompute table contains at least one data column and one partition key column.
We recommend that you use the following reserved fields in Simple Log Service: __partition_time__, __source__, and __topic__.
Each MaxCompute table can have a maximum of 60,000 partitions. If the number of partitions exceeds the maximum value, data cannot be written to the table.
Data shipping jobs are executed in batches. When you specify custom fields as partition key columns and specify data types for a data shipping job, make sure that the number of partitions that each data shipping job needs to process does not exceed 512. Otherwise, no data can be written to MaxCompute.
The previous name of the system reserved field __extract_others__ is _extract_others_. Both names can be used together.
The value of the MaxCompute partition key column cannot be set to reserved words or keywords of MaxCompute. For more information, see Reserved words and keywords.
You cannot leave the fields of MaxCompute partition key columns empty. The fields that are mapped to partition key columns must be reserved fields or log fields. You can use the cast function to convert a field of the string type to the type of the corresponding partition key column. Logs that correspond to an empty partition key column are discarded during data shipping.
In Simple Log Service, a log field can be mapped to only one data column or partition key column of a MaxCompute table. Field redundancy is not supported. If the same field name is reused, the value that is shipped is null. If null appears in the partition key column, data cannot be shipped.
The following table describes the mapping relationships between MaxCompute data columns, partition key columns, and Simple Log Service fields. For more information about reserved fields in Simple Log Service, see Reserved fields.
MaxCompute column type
Column name in MaxCompute
Data type in MaxCompute
Log field name in Simple Log Service
Field type in Simple Log Service
Description
Data column
log_source
string
__source__
Reserved field
The source of the log.
log_time
bigint
__time__
Reserved field
The UNIX timestamp of the log. It is the number of seconds that have elapsed since 00:00:00 UTC, Thursday, January 1, 1970. This field corresponds to the Time field in the data model.
log_topic
string
__topic__
Reserved field
The topic of the log.
time
string
time
Log content field
This field is parsed from logs and corresponds to the key-value field in the data model. In most cases, the value of the __time__ field in the data that is collected by using Logtail is the same as the value of the time field.
ip
string
ip
Log content field
This field is parsed from logs.
thread
string
thread
Log content field
This field is parsed from logs.
log_extract_others
string
__extract_others__
Reserved field
Other log fields that are not mapped in the configuration are serialized into JSON data based on the key-value field. The JSON data has a single-layer structure and JSON nesting is not supported for the log fields.
Partition key column
log_partition_time
string
__partition_time__
Reserved field
This field is calculated based on the value of the __time__ field of the log. You can specify the partition granularity for the field.
status
string
status
Log content field
This field is parsed from logs. The value of this field supports enumeration to ensure that the number of partitions does not exceed the upper limit.