Application Load Balancer (ALB) performs health checks to test whether the backend servers work as expected. After health checks are enabled, if a backend server fails to pass health checks, ALB automatically routes requests to healthy backend servers. Health checks prevent failed backend servers from affecting the entire service and ensure high service availability. This topic describes how to troubleshoot health check issues.
Issue
The Health Check Status column of a listener of an ALB instance displays Unhealthy.
Causes
If the error occurs after the first health check probe is sent, the issue may be caused by improper health check configurations. You need to check the following possible causes:
Improper parameter settings
Improper health check ports
If health checks are properly configured, the error may be caused by backend servers. In this case, check the following causes:
Improper security service configurations
Improper route configurations
Heavy loads on backend servers
Solutions
Errors that occur after the first health check probe is sent
Cause 1: improper parameter settings
- Log on to the ALB console.
In the top navigation bar, select the region where the ALB instance that you want to manage is deployed.
In the left-side navigation pane, choose .
On the Server Groups page, find the server group associated with the ALB instance and click the server group ID.
On the server group details page, click Modify Health Check in the Health Check section.
In the Modify Health Check dialog box, check the parameter settings. We recommend that you use the default settings.
For more information, see Health checks.
Cause 2: improper health check ports
- Log on to the ALB console.
In the top navigation bar, select the region where the ALB instance that you want to manage is deployed.
In the left-side navigation pane, choose .
On the Server Groups page, find the server group associated with the ALB instance and click the server group ID.
On the server group details page, click the Backend Servers tab and record the backend server port.
On the server group details page, click the Details tab. Then, click Modify Health Check in the Health Check section. In the Modify Health Check dialog box, record the health check configurations.
Log on to a backend server and run the nc or curl command to probe the backend server.
For more information about how to log on to an Elastic Compute Service (ECS) instance, see Guidelines on instance connection.
# The nc command: echo -e "[$Method] [$PATH] [$VERSION]\r\nHost: [$Domain]\r\n\r\n" | nc -t [$IP] [$Port] #Format echo -e "HEAD /index.html HTTP/1.0\r\nHost: wwww.example.org\r\n\r\n" | nc -t 127.0.0.1 80 #Example # The curl command: curl -X [$Method] -H "Host: [$Domain]" -I http://[$IP]:[$Port][$PATH] #Format curl -X HEAD --http1.0 -H "Host: www.example.org" -I http://127.0.0.1:80/index.html # ExampleNoteSet [$Method] to the health check method of the server group.
Set [$PATH] to the health check path of the server group.
Set [$VERSION] to the version of the HTTP protocol of the server group, such as HTTP/1.0.
Set [$Domain] to the health check domain name of the server group. If the domain name is -----, the private IP address of the ECS instance is used as the health check domain name. In this case, you can replace [$Domain] with [$IP].
Set [$IP] to the private IP address of the ECS instance.
Set [$Port] to the health check port of the server group. If no port is specified, the port of the ECS instance is used by default. If a port is specified, enter the specified port.
After you run the command, view the returned HTTP status code and determine whether the returned HTTP status code indicates a healthy state:
If the returned HTTP status code indicates a healthy state but is not included in health check settings, modify the health check settings to include the HTTP status code.
If the returned HTTP status code indicates an unhealthy state, see the following table for troubleshooting. The following table describes the HTTP status codes that may be returned and how to troubleshoot.
Status code
Description
Troubleshooting
400
The format of the HTTP request is invalid.
Check whether the format of the HTTP request is valid. For example, check for empty Content-Length headers and configurations forwarding HTTP requests to the HTTPS port of the backend server.
404
The requested resource is not found.
Check whether the requested URL is valid.
405
The health check request method is not supported.
Check whether the backend service supports the health check request method.
500
The request cannot be processed because the server has an internal error.
Check the business logic of the backend service.
503
The server is temporarily unavailable.
Check the business logic of the backend service or whether the backend server is overloaded.
Errors that occur during subsequent health check probes
Cause 1: improper security service configurations
By default, an upgraded ALB instance uses private IP addresses in the CIDR block of the vSwitch specified for the instance to communicate with backend ECS instances. Ensure the backend ECS instances do not block these IP addresses in any way, including using iptables rules or third-party security policy software. You can log on to the ALB console to check the private IP addresses, which are displayed as Local IP.
Non-upgraded ALB instances use IP addresses in the 100.64.0.0/10 CIDR block to communicate with backend ECS instances. Ensure the backend ECS instances do not block these IP addresses in any way, including using iptables rules or third-party security policy software.
For information about the ALB instance upgrade, see ALB instance upgrade.
ALB instances use reserved IP addresses in the CIDR block to communicate with the backend ECS instances. If the CIDR block used by the ALB instance is blocked, health check errors arise and the ALB instance cannot work as expected. In the following example, 100.64.0.0/10 is blocked by iptables rules.
Log on to the ECS instance and run the following command to query all rules in the filter table:
iptables -nLThe following output indicates that the ECS instance blocks requests from the private CIDR block of the ALB instance.
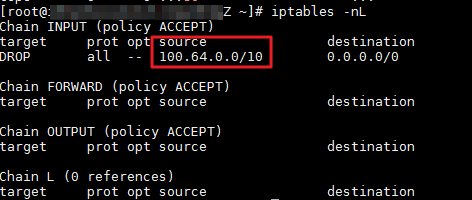
Run the following command to delete the rule:
iptables -t filter -D INPUT -s 100.64.0.0/10 -j DROPRun the following command to verify that the ECS instance no longer blocks requests from the private CIDR block of the ALB instance:
iptables -nL
Cause 2: Improper route configurations
This cause applies only to non-upgraded ALB instances. An upgraded instance uses private IP addresses (Local IP in the console) in the CIDR block of the vSwitch specified for it to communicate with backend ECS instances. Therefore, it does not require allow policies for the 100.64.0.0/10 CIDR block.
For information about the ALB instance upgrade, see ALB instance upgrade.
Check the corresponding route on the backend ECS instance. The route points to 100.64.0.0/10, which is the private CIDR block of the ALB instance. If the route is improperly configured, the ALB cannot receive health check probe packets returned by the backend ECS instance. This results in health check errors. In this example, the route command in Linux is used to check the route configuration.
Log on to the backend ECS instance that has issues and run the following command to check the route configuration:
route -nIf the Destination value of the route is 100.64.0.0, the Genmask value of the route is 255.192.0.0, and the Gateway value is not set to the default gateway of the corresponding elastic network interface (ENI), the route is improperly configured. The default gateway refers to the Gateway value when the Destination value is 0.0.0.0.

Run the following command to delete the route that points to 100.64.0.0/10:
route del -net 100.64.0.0/10
Cause 3: The backend ECS instance is overloaded
Refer to Query and analysis of system loads on Linux instances and check whether the ECS instance is overloaded.