This topic provides answers to some frequently asked questions (FAQ) about job management in SchedulerX.
What do I do if the Spring application cannot find the beans?
On the Application Management page in the SchedulerX console, find the Spring application and click the number displayed in the Total number of instances column. Make sure that the boot mode is Spring or Spring Boot.
Make sure that a
beanis injected into theJobProcessorin the code of the Spring application. For example, you can add the@Componentannotation.If the pom.xml file contains the
spring-boot-devtoolsdependency, delete the dependency.If the JobProcessor or the process method contains any aspect-oriented programming (AOP) annotation, upgrade your SchedulerX agent to the latest version. A SchedulerX agent of an earlier version does not support AOP annotations.
Check whether the beans are proxied by other aspects. Add breakpoints to the
DefaultListableBeanFactoryclass. The member variables ofbeanDefinitionNamesare the beans that are registered in Spring. Check whether these beans are proxied by other aspects. For example, the beans may be proxied by other aspects because some invalid second-party libraries are indirectly imported by users. If the beans are proxied by other aspects, delete the aspects.

If the issue persists, debug ThreadContainer.start. If the class.forName error occurs but the class exists, the cause of the issue may be that the framework of the Spring application uses a class loader that is different from the class loader of the SchedulerXWorker agent. In this case, you can modify SchedulerxWorker.setClassLoader to resolve this issue.
What do I do if a job fails and the error message "Unable to make field private" is returned?
MapReduce adopts serialization and deserialization frameworks. For Java 9 and later versions, you must manually enable the reflection feature to access private variables. Add the following configuration to Java virtual machine (JVM) parameters:
--add-opens java.base/java.lang=ALL-UNNAMEDWhat do I do if a job fails and the error message "submit jobInstanceId to worker timeout" is returned?
If this issue occurs during application release or occurs occasionally, you can ignore it.
If this issue persists and the workAddr parameter in the reported errors is the same, the persistent connection between the server and the agent is disconnected. You need to restart the worker node or upgrade the SchedulerX agent to the latest version. Then, the persistent connection automatically recovers.
What do I do if a job fails and the error message "used space beyond 90.0%!" is returned?
The disk is full. You need to clear the disk space of the Elastic Compute Service (ECS) instance or container.
What do I do if a job fails and the error message "ClassNotFoundException" is returned?
This error message indicates that the worker that runs the job does not have this class. Make sure that the value of the Processor class name parameter configured for the Java job is the full path of the class.
If the JobProcessor class name is correct, the class does not exist on the worker. In this case, the common cause is that the used package is incorrect, or the application is connected to another worker. You can log on to the worker and use Java decompilation to view the details.
What do I do if a job fails and the error message "jobInstance=xxx don't update progress more than 60s" is returned?
If a worker that is running a job fails to function normally and does not update the progress for 60s, the worker is forcibly terminated by the server. If the issue is caused by the worker or the worker does not exist, you can ignore the issue.
What do I do if a job fails and no error message is returned?
Issue
A job fails to run, and no error message is returned.
Possible cause
The possible causes include worker or business logic failures.
Solution
On the Execution List page, click the Task instance List tab. Find the job that you want to manage and click Details in the Operation column to go to the Task instance details page.
If no task details are available, the job is a simple job. The value of the WorkAddr parameter on the Basic information tab indicates the worker that runs the job.
Log on to the worker that runs the job and open the ~/logs/schedulerx/worker.log log.
Run the
grep <Instance ID> worker.logcommand to view logs related to the instance. If an error occurs, view the stack cause of the error.If the error description is empty, this issue is caused by a business logic failure, and no error message is returned. In this case, troubleshoot the business logic.
If the error description indicates a framework exception, join the DingTalk group 23103656 for technical support.
How do I identify the cause of a job failure?
If an exception is reported for a standalone job, open the Execution List page and click the Task instance List tab. Then, find the job and click Details in the Operation column to view the error message.
If no exception is reported or the job is a distributed job, use Log Service for troubleshooting if you use SchedulerX Professional Edition.
In Basic Edition, you can log on to the worker node and view the logs of SchedulerX and business logs for troubleshooting.
What do I do if a job is stuck during running?
Issue
The job remains in the running state and cannot be completed.
Possible cause
A business issue may occur.
A SchedulerX issue may occur.
Solution
If a business issue occurs, perform the following operations. If another type of issue occurs, join the DingTalk group 23103656 for technical support.
SchedulerX Professional Edition: Use the ThreadDump feature in the console to query the stack and resolve the issue. This feature is available in agents of 1.4.2 or later versions.
SchedulerX Basic Edition: Log on to the worker node where the job is stuck and run the
jstackcommand to view the stack.jstack <pid> | grep <Instance ID> -A 20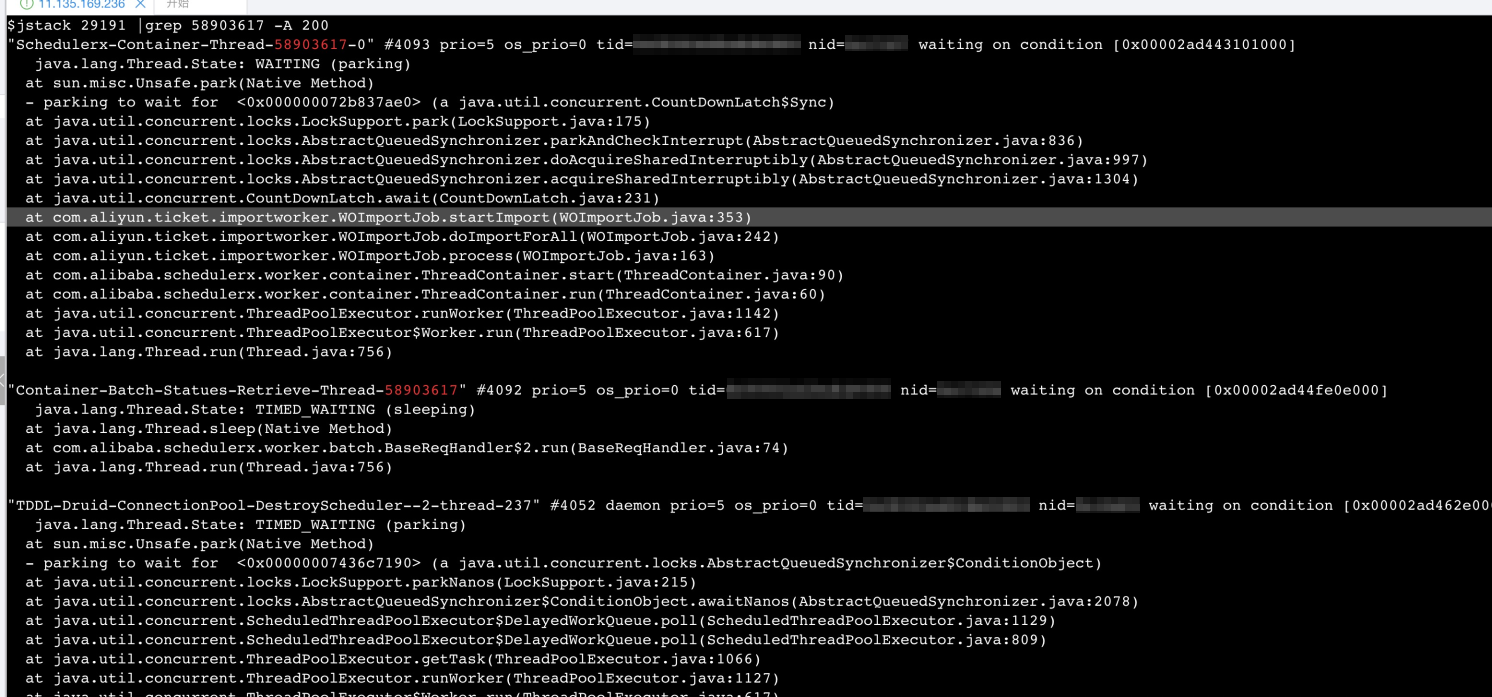
How do I troubleshoot slow job running?
Use Professional Edition and enable the Tracing Analysis feature. For more information, see Integrate tracing analysis.
What do I do if the number of instances that run a job reaches the upper limit?
Issue
The error message The number of concurrent job instances reaches the upper limit. Try again later. is returned after you click Run once on the Task Management page.
Possible cause
The job is already running on job instances.
The number of job instances that are running the job has reached the value of the Instance concurrency parameter configured for the job.
Solution
If the configured value of the Instance concurrency parameter is proper, you can ignore this issue. You can open the Task Management page, find the job that you want to manage and choose in the Operation column to view the job instances that are running.
If the configured value of the Instance concurrency parameter is improper, open the Task Management page, find the desired job, and click Edit in the Operation column. Then, specify the Instance concurrency parameter in Advanced Configuration.
If a job is not complete as scheduled, will the job be queued to run next time or not?
The default value of the Instance concurrency parameter is 1, which indicates that a job is run on only one instance at a time. If the running of a job takes a long time and is not complete as scheduled, the job will be directly discarded at the next scheduling time and will not be run or queued.
If the value of the Instance concurrency parameter is set to 2, the running of a job that is not complete as scheduled can continue next time. This indicates that up to two job instances can run the job.
How do I create a one-time job?
SchedulerX 2.0 allows you to create one-time jobs by setting the Time type parameter to one_time. No execution records are kept for one-time jobs.
How do I view the historical records of a one-time job after it is run?
After a one-time job is run, the job is automatically destroyed and no historical records are kept. This prevents data accumulation. If you want to save historical records, you can enable Log Service to retain the execution logs of all jobs in the last two weeks for troubleshooting. For more information, see Application management.
How do I perform second-delay scheduling?
SchedulerX supports second-delay scheduling. If the Time type parameter of a job is set to cron or fix_rate, the job does not support second-delay scheduling. You can set Time type to second_delay for a job. Then, the job is run at an interval of the delay after the last run.
What do I do if a job is not scheduled at a point in time?
If a standalone job is not scheduled at a point in time, check whether workers exist in the worker list and whether all workers are busy. If no worker is available, check whether no worker exists or the existing workers are busy. For more information, see What do I do if the system displays the message "no workers available"? and What do I do if all workers are busy?
We recommend that you turn on the No machine alarm available switch. For more information, see Job management.
How do I set the timeout period in SchedulerX?
SchedulerX allows you to set the timeout period for jobs but not for tasks. You can change the timeout period in the console. For more information, see Job management.
Why is a job still run after the instance is stopped?
Issue
A job is still run after the instance is stopped.
Possible cause
After a job instance is stopped, SchedulerX sends a Kill message to the agent. After receiving the Kill message, the agent stops delivering and running tasks that are not executed, destroys the context of the instance, and destroys all thread pools of the instance. However, the tasks that are being executed are not stopped, and only the corresponding threads are interrupted. Therefore, the tasks will continue to run until they are complete.
Solution
In most cases, you can wait until the tasks are completed and do not need to handle the issue.
If you want to stop all running jobs immediately after you stop an instance, you need to modify the task processing logic and add the Interrupt state to the current thread.
How do I set advanced configurations for job management?
For more information, see Advanced parameters for job management.
What do I do if all workers are busy?
On the Application Management page, find the application that you want to manage and click View instances in the Operation column. Then, you can identify workers in the Busy state, and move the pointer over Busy to view the metrics that exceed the threshold.
To configure the threshold, go to the Application Management page, find the application, click Edit in the Operation column, and then specify related parameters in the Edit application grouping panel.
If a worker is busy because the load exceeds the specified threshold, check whether the application is deployed in a Kubernetes container. If you deploy the application in a Kubernetes container, configure the following parameters. Otherwise, the collected CPU utilization may be incorrect. For more information, see Connect a Spring Boot application to SchedulerX.
key | Description | Value | Initial version |
spring.schedulerx2.enableCgroupMetrics | Specifies whether to use control groups (cgroups) to collect the metrics of the agent. You must manually enable this feature in a Kubernetes environment. | Valid values: true and false. Default value: false. | 1.2.2.2 |
spring.schedulerx2.cgroupPathPrefix | Specifies the cgroup path in the container. | The default path is /sys/fs/cgroup/cpu/. If the path already exists, you do not need to configure this parameter. | 1.2.2.2 |
How do I integrate Tracing Analysis?
SchedulerX supports the end-to-end tracing analysis feature. For more information, see Integrate tracing analysis.
What do I do when the running of a job gets stuck or slows down during application release?
Issue
During application release, the running of a job is stuck or slows down.
Possible cause
For a distributed job, if a worker that processes a task goes offline, SchedulerX redistributes the task and performs polling to identify online workers. This slows down the entire process.
Solution
This issue can be optimized if you update the agent to version 1.7.9 or later.
What do I do when the system asks me to enter instance parameters after I click Run once?
When you click Run once in the Operation column of a scheduling job on the Task Management page, the job is run once. The Instance Parameters field in the displayed dialog box is optional and is used for testing.
Does the code obtain instance parameters or job parameters when I click Run Once and enter instance parameters?
Instance parameters are different from job parameters. The parameters that are obtained in the code are determined by your business code.
How do I obtain job parameters or instance parameters?
The following sample code provides an example on the configuration:
@Component
public class JavaDemoProcessor extends JavaProcessor {
private static final Logger LOGGER = LoggerFactory.getLogger("schedulerxLog");
@Override
public ProcessResult process(JobContext jobContext) throws InterruptedException {
LOGGER.info(JSON.toJSONString(jobContext));
// Obtain job parameters.
String jobParameters = jobContext.getJobParameters();
// Obtain instance parameters.
String instanceParameters = jobContext.getInstanceParameters();
LOGGER.info("Job parameters:" + jobParameters);
LOGGER.info("Instance parameters" + instanceParameters);
return new ProcessResult(InstanceStatus.SUCCESS);
}
}How do I allow the code to obtain instance parameters by default if I specify instance parameters and obtain job parameters if I do not specify instance parameters?
The following sample code provides an example on the configuration:
@Component
public class JavaDemoProcessor extends JavaProcessor {
private static final Logger LOGGER = LoggerFactory.getLogger("schedulerxLog");
@Override
public ProcessResult process(JobContext jobContext) throws InterruptedException {
String params = null;
if (StringUtils.isNotBlank(jobContext.getInstanceParameters())) {
params = jobContext.getInstanceParameters();
} else {
params = jobContext.getJobParameters();
}
LOGGER.info("JavaDemoProcessor params:{}", params);
return new ProcessResult(InstanceStatus.SUCCESS);
}
}