This topic describes the Clustered Columnar Index (CCI) feature.
The Online Transaction Processing (OLTP) and Online Analytical Processing (OLAP) solutions are developed based on the read/write splitting or extract, transform, load (ETL) model. These solutions extract data from online databases and load the data into a data warehouse for analysis by means of T+1. However, these solutions have several drawbacks, such as high storage cost, poor real-time capabilities, and high maintenance and connectivity costs.
To cope with explosive data growth, PolarDB-X provides the CCI feature based on Object Storage Service (OSS). This feature allows you to synchronize row-oriented data to column-oriented data in real time and supports the following capabilities:
The CCI feature supports integrated OLTP and real-time data analysis to meet the requirements in scenarios where OLTP and OLAP are involved.
The CCI feature of PolarDB-X supports intelligent routing and massively parallel processing (MPP). The compute layer accurately identifies transactional processing (TP) traffic and analytical processing (AP) traffic and routes the traffic to different storage media. By default, the compute layer also ensures that MPP is enabled on AP traces to scan CCIs. This significantly improves query analysis capabilities.
The CCI feature uses the Delta+Main model to implement real-time update within seconds. The feature integrates with Multi-Version Concurrency Control (MVCC) to ensure that consistent snapshot data can be read at any time.
Usage notes
The CCI feature is supported only by Enterprise Edition instances whose version is 5.4.19-16989811 or later.
Only databases in AUTO mode support creating CCIs.
NoteFor information about instance versioning, see Release notes.
For information about how to view the version of a PolarDB-X instance, see View and update the version of an instance.
Architecture
Hybrid row-column storage

Key components
Compute nodes (CNs) are the entrance of the system. These nodes use the stateless design, and include models such as the SQL parser, optimizer, and executor. CNs are responsible for distributed data routing, computation, dynamic scheduling, distributed transaction coordination based on the Two-Phase Commit (2PC) protocol, and global secondary index maintenance. CNs provide enterprise-level features such as SQL throttling and the three-role mode.
Data nodes (DNs) are responsible for persistent row-oriented data. DNs ensure data durability and provide strong consistency guarantees based on the multi-majority Paxos protocol. DNs use MVCC to maintain the visibility of distributed transactions. DNs can also meet the requirements of operations that need to push down computing tasks in distributed architectures, such as Project, Filter, Join, and Aggregation.
Global Meta Service (GMS) is responsible for maintaining globally consistent system metadata such as table metadata, schema metadata, and statistics metadata. GMS manages security-related information such as user accounts and permissions. GMS provides the Timestamp Oracle (TSO) service.
Change Data Capture (CDC) provides incremental subscription capabilities fully compatibility with the formats and protocols of MySQL binary logs. CDC also provides primary/secondary replication capabilities compatible with MySQL replication protocols.
Columnar provides persistent CCIs, consumes the binary logs of distributed transactions in real time, and builds CCIs based on OSS to meet the requirements of real-time updates. When combined with CNs, columnar can provide snapshot-consistent query capabilities for CCIs.
Column-oriented storage

Architecture concept
With the increasing popularity of cloud-native technologies, new-generation cloud-native data warehouses such as Snowflake and the HTAP architecture are continuously driving innovation. It is evident that in the near future, hybrid row-column storage with HTAP capabilities will become a standard requirement for databases. Therefore, it is important to focus on future-oriented aspects such as cost-effectiveness, ease of use, and high performance in current column-oriented storage designs.
PolarDB-X provides the CCI feature. By default, a row-oriented table in PolarDB-X has primary key indexes and secondary indexes. A CCI is a secondary index that is built on top of a column-oriented structure and is valid for all columns in a row-oriented table. A table can contain row-oriented data and column-oriented data.
Architecture features
Cloud-native architecture (decoupled storage and computing and cost-effectiveness)
The CCI feature of PolarDB-X uses OSS as primary data storage, which generates the costs of one sixth to one tenth of local disk-based storage costs. The feature also implements the high compression ratio of column-oriented data that is from three to five times that of other data types. This provides the CCI feature with a competitive advantage in lower costs. In HTAP scenarios where hybrid row-column storage is involved, the addition column-oriented storage costs can be controlled within 5% to 10% of the row-oriented storage costs.
The CCI feature of PolarDB-X leverages the two-tier model of Delta+Main similar to the LSM structure and tag deletion technologies in its storage layer to ensure that the feature provides high-concurrency update capabilities when OSS is used. Multiple layers of local data cache and multi-level statistics mechanism are also employed on traces where the CCI feature reads data from OSS to minimize unnecessary remote access to OSS storage data.
Distributed database system (linear scaling)
In traditional distributed databases, CCIs are commonly built by using multi-replica mechanisms based on the Paxos or Raft protocol. However, OLTP and OLAP have different query requirements and various degrees of resource dependencies. The strong-consistency partitioning policies and scaling mechanisms between different replicas can limit the linear scaling capabilities of TP and AP, which degrades database performance.
The CCI feature of PolarDB-X implements heterogeneous transformation from row-oriented data to column-oriented data (M:N) based on the real-time synchronization of the binary logs of distributed transactions. The feature defines the distributed partition keys and sort keys for CCIs. PolarDB-X leverages distributed parallel processing techniques to provide linear scalability for CCI-based queries. The row-oriented and column-oriented storage mediums are isolated from each other. This way, storage and computing resources can be scaled with ease. In a distributed environment, CCI-based queries can benefit from extreme linear scalability.
Read/write splitting (serverless architecture with pay-as-you-go pricing for reads)
The CCI feature of PolarDB-X adopts a component-based read/write splitting architecture. This architecture consists of column store nodes and compute nodes. Column store nodes are stateless nodes that do not directly handle write requests from external clients. Instead, these nodes leverage the Group Commit technology to batch update CCI data. Compute nodes are stateless nodes that retrieve columnar metadata from GMS nodes and directly access the CCI data stored in OSS.
If you want to create a PolarDB-X instance, the system automatically provides column store nodes. These nodes continuously run and synchronize CCIs. You can easily create a CCI by executing a DDL statement. After the CCI is built, CCI data is automatically generated and updated in real time. You can use a primary instance or purchase an additional read-only instance to access row store indexes and CCIs. The serverless mode is also suitable for stateless CNs. You are charged only for the usage of CNs.
Combination of row-oriented and column-oriented storage (ease-of-use, integrated vectorized SQL engine)
PolarDB-X reuses the SQL engine of CNs to provide the complete capabilities of CNs. A cost optimizer is built for hybrid row-column scenarios. This cost optimizer intelligently identifies routes based on execution costs, and forwards OLTP queries to row store query traces and OLAP queries to CCI-based query traces. The cost optimizer allows you to access different row-oriented data and column-oriented data at the SQL operator level, which fully implements the hybrid row-column capabilities of HTAP. The cost optimizer also allows unified access to a set of SQL engines.
PolarDB-X is fully compatible with vectorization. The data structure of columnar chunk is used by the TableScan operator to read column-oriented data. Subsequent operator computations also fully inherit the in-memory columnar structure of chunks. This improves query performance based on end-to-end vectorization. The TableScan operator for row-oriented storage is also dynamically converted into columnar chunks to implement hybrid row-column queries based on a unified data structure.
One-stop warehouse (Zero-ETL)
Traditional data warehouses use ETL to synchronize data and leverage parallel computing architectures, such as MPP and Bulk Synchronous Parallel (BSP), to handle complex OLAP queries. However, in high-concurrency online queries (Serving scenarios), these warehouses have a bottleneck on resource concurrency. In this case, these warehouses return data to OLTP databases to provide online queries.
PolarDB-X integrates with AnalyticDB for MySQL to provide a one-stop warehouse. The warehouse leverages shared CCI data based on the zero-ETL concept. The warehouse also allows multiple parties to perform data aggregation and data correlation queries and provides the traditional warehouse and data lake analysis based on AnalyticDB for MySQL warehousing capabilities. The hybrid row-column architecture with HTAP capabilities of PolarDB-X can also be used for concurrent queries on online data to eliminate the need for traditional data ETL.
How CCIs work
Building of CCIs
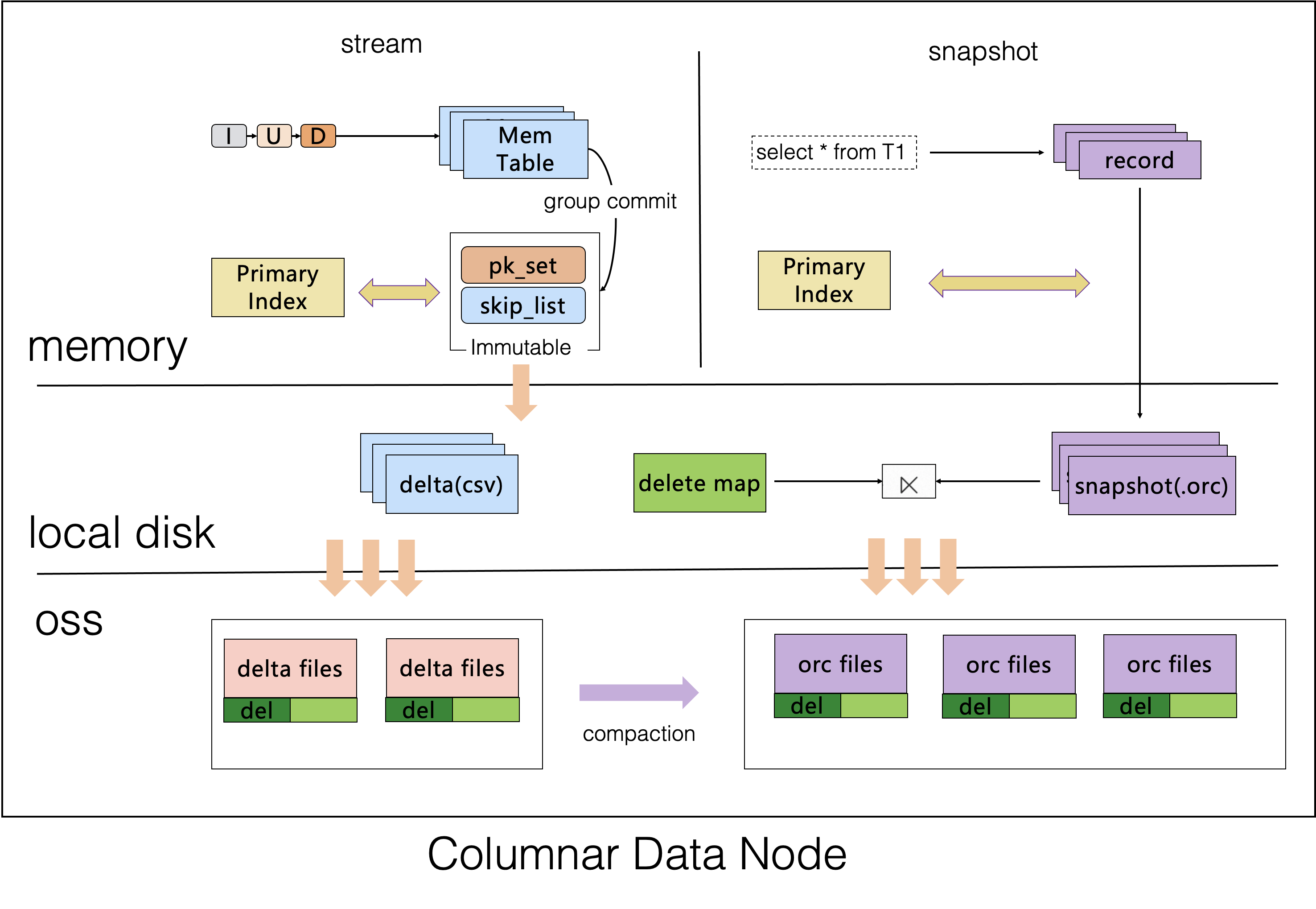
CCIs are built by column store nodes. Data related to built CCIs is stored in shard objects in the CSV and ORC formats. The CSV format is used to store real-time incremental data. Excessive incremental data is compacted in a timely manner and dumped into the ORC format. PolarDB-X has optimized the CSV and ORC formats. Optimized formats inherit the open source features of the native formats, and ensure that the two formats can fully express the data protocols of MySQL.
From the perspective of data synchronization, the process of building CCIs involves two parallel synchronization traces: full snapshot reading and incremental data synchronization. In scenarios where CCIs are built and then data is imported, only incremental data is synchronized, and column store nodes simultaneously consume binary logs to build the CCIs. In scenarios where data is partially imported, and then CCIs are built and remaining data is imported, incremental data is synchronized, and column store nodes simultaneously consume existing incremental and full data to improve the efficiency of creating CCIs.
From a hierarchical perspective, column store nodes use the two-tier model of Delta+Main similar to the LSM structure and tag deletion technologies to ensure low-latency data synchronization between row-oriented storage and column-oriented storage and real-time data updates within seconds. Data is written to the MemTable in real time. The data is stored in a local CSV file and appended to the corresponding CSV file on OSS within a group commit cycle. The local file is named the delta file. The CSV file on OSS is not permanently stored, but is converted into an ORC file by the compaction from time to time.
MPP

In PolarDB-X, CNs are used to handle traffic for queries and analysis. The preceding figure shows that the entire query acceleration chain consist of three levels: the optimizer, the executor, and the storage engine.
PolarDB-X provides the cost optimizer suitable for hybrid row-column scenarios. The cost optimizer intelligently identifies routes based on execution costs, and forwards TP queries to row store query traces and AP queries to CCI-based query traces.
PolarDB-X provides the integrated executor suitable for hybrid row-column scenarios. A set of executors are available in HTAP scenarios. The operator layer is also vectorized and supports MPP. In complex query scenarios, multi-node resources can be used for parallel computing to meet requirements for complex queries that have high throughput. To eliminate the network latency caused by the architecture with compute and storage resources decoupled, the executor layer also introduces local caching technology to load hot data to local disks in real time. This ensures that low-latency query requirements are met.
At the storage engine level, the building of CCIs enables the atomicity of committed transaction and ensures that transaction-level consistent data can be queried.
Service types

With the introduction of the columnar, PolarDB-X provides an additional service type apart from primary instances and read-only instances. This added service type is known as read-only column store instances.
Primary Instance: By default, the primary instance allows you to query only row-oriented data. However, when combined with read-only instances, the endpoint of the primary instance enables transparent and strongly consistent read-write splitting. The primary instance retains the ability to directly query column-oriented data. The intelligent routing and hybrid row-column query capabilities will be available in the future.
Read-only instance: Read-only instances allow you to query row-oriented read-only data and CCI data. Read-only instances have dedicated read-only endpoints. Applications can establish separate connections to these read-only endpoints to perform read operations. By connecting to these read-only endpoints, applications can independently manage read and write operations.
Read-only column store instance: Read-only column store instances allow you to query only CCI data. The instances have dedicated read-only endpoints. Applications can establish separate connections to these read-only endpoints to perform read operations. The instances consist only of CNs and are more cost-effective.
Scenario
The CCI feature of PolarDB-X provides a one-stop HTAP solution and can be used in various business scenarios.
Scenarios that require the real-time analysis of online data within seconds, such as real-time report business.
Data warehousing scenarios that depend on the large volume data storage capacity of PolarDB-X to aggregate multiple upstream data sources and use PolarDB-X as the dedicated data warehouse.
ETL-faced computing scenarios that depend on the powerful and flexible computing capabilities of CCIs of PolarDB-X.
The CCI feature of PolarDB-X meets the requirements of scenarios that involve TP and AP, and provides a transparent and cost-effective HTAP solution based on OSS and intelligent routing technology.
Performance tests
For information about PolarDB-X TPC Benchmark-H (TPC-H) test for PolarDB-X Clustered Columnar Indexes (CCIs), see TPC-H test for CCIs based on 100 GB of data.