This topic describes the write-ahead log (WAL) parallel replay feature for PolarDB for PostgreSQL and .
Applicability
This feature is available for the following versions of PolarDB for PostgreSQL:
PostgreSQL 18 with minor engine version 2.0.18.0.1.0 or later.
PostgreSQL 17 with minor engine version 2.0.17.2.1.0 or later.
PostgreSQL 16 with minor engine version 2.0.16.3.1.1 or later.
PostgreSQL 15 with minor engine version 2.0.15.7.1.1 or later.
PostgreSQL 14 with minor engine version 2.0.14.5.1.0 or later.
PostgreSQL 11 with minor engine version 2.0.11.9.17.0 or later.
You can view the minor engine version in the PolarDB console or by running the SHOW polardb_version; statement. If your cluster's minor engine version does not meet the requirements, you must upgrade the minor engine version.
Background information
A PolarDB for PostgreSQL or cluster uses a one-writer, multiple-reader architecture. On a running read-only node (replica node), the LogIndex background worker process and a backend process use LogIndex data to replay WAL records in separate buffers. This method achieves the parallel replay of WAL records.
WAL replay is critical for the high availability (HA) of PolarDB clusters. Applying the parallel replay method to the standard log replay path is an effective optimization.
Parallel WAL replay offers advantages in at least three scenarios:
The crash recovery process for the primary database, read-only nodes, and secondary databases.
The continuous replay of WAL records by the LogIndex BGW process on a read-only node.
The continuous replay of WAL records by the Startup process on a secondary database.
Terms
Block: A data block.
WAL: Write-Ahead Logging.
Task Node: A subtask execution node in the parallel execution framework that can receive and execute one subtask.
Task Tag: A classification identifier for a subtask. Subtasks with the same tag must be executed in sequence.
Hold List: A linked list that each child process in the parallel execution framework uses to schedule and execute replay subtasks.
How it works
Overview
A single WAL record may modify multiple data blocks. The WAL replay process can be defined as follows:
Assume that the
i-th WAL record has an LSN ofLSN<sub>i</sub>and modifiesmdata blocks. The list of data blocks modified by thei-th WAL record is represented asBlock<sub>i</sub>=[Block<sub>i,0</sub>,Block<sub>i,1</sub>,...,Block<sub>i,m</sub>].The smallest replay subtask is defined as
Task<sub>i,j</sub>=LSN<sub>i</sub>−>Block<sub>i,j</sub>. This subtask represents replaying thei-th WAL record on the data blockBlock<sub>i,j</sub>.Therefore, a WAL record that modifies
mblocks can be represented as a collection ofmreplay subtasks:TASK<sub>i,∗</sub>=[Task<sub>i,0</sub>,Task<sub>i,1</sub>,...,Task<sub>i,m</sub>].Furthermore, multiple WAL records can be represented as a series of replay subtask collections:
TASK<sub>∗,∗</sub>=[Task<sub>0,∗</sub>,Task<sub>1,∗</sub>,...,Task<sub>N,∗</sub>].
In the collection of replay subtasks
Task<sub>∗,∗</sub>, the execution of a subtask does not always depend on the result of the preceding subtask.Assume the collection of replay subtasks is
TASK<sub>∗,∗</sub>=[Task<sub>0,∗</sub>,Task<sub>1,∗</sub>,Task<sub>2,∗</sub>], where:Task<sub>0,∗</sub>=[Task<sub>0,0</sub>,Task<sub>0,1</sub>,Task<sub>0,2</sub>]Task<sub>1,∗</sub>=[Task<sub>1,0</sub>,Task<sub>1,1</sub>]Task<sub>2,∗</sub>=[Task<sub>2,0</sub>]
Assume that Block0,0=Block1,0, Block0,1=Block1,1, and Block0,2=Block2,0.
Then, there are three collections of subtasks that can be replayed in parallel: [Task0,0,Task1,0], [Task0,1,Task1,1], and [Task0,2,Task2,0].
In summary, many subtask sequences within the set of replay subtasks can be executed in parallel without affecting the consistency of the final result. PolarDB leverages this concept in its parallel task execution framework, which is applied to the WAL replay process.
Parallel task execution framework
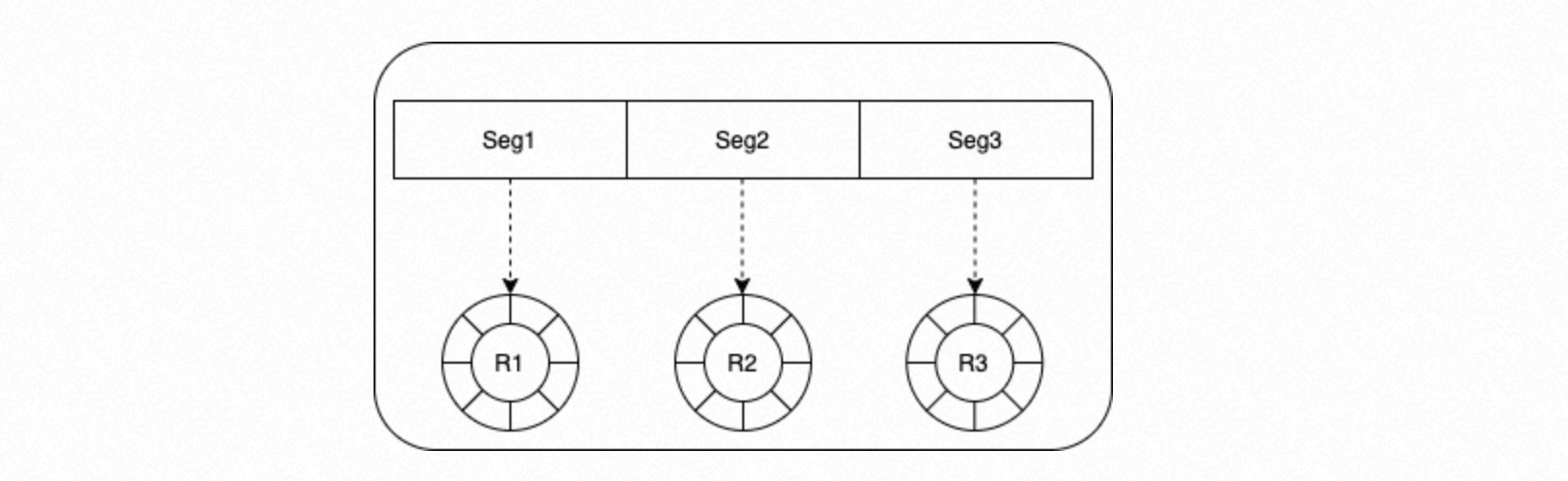
A segment of shared memory is divided equally based on the number of concurrent processes. Each segment acts as a circular queue and is allocated to one process. You can configure the depth of each circular queue by setting a parameter.
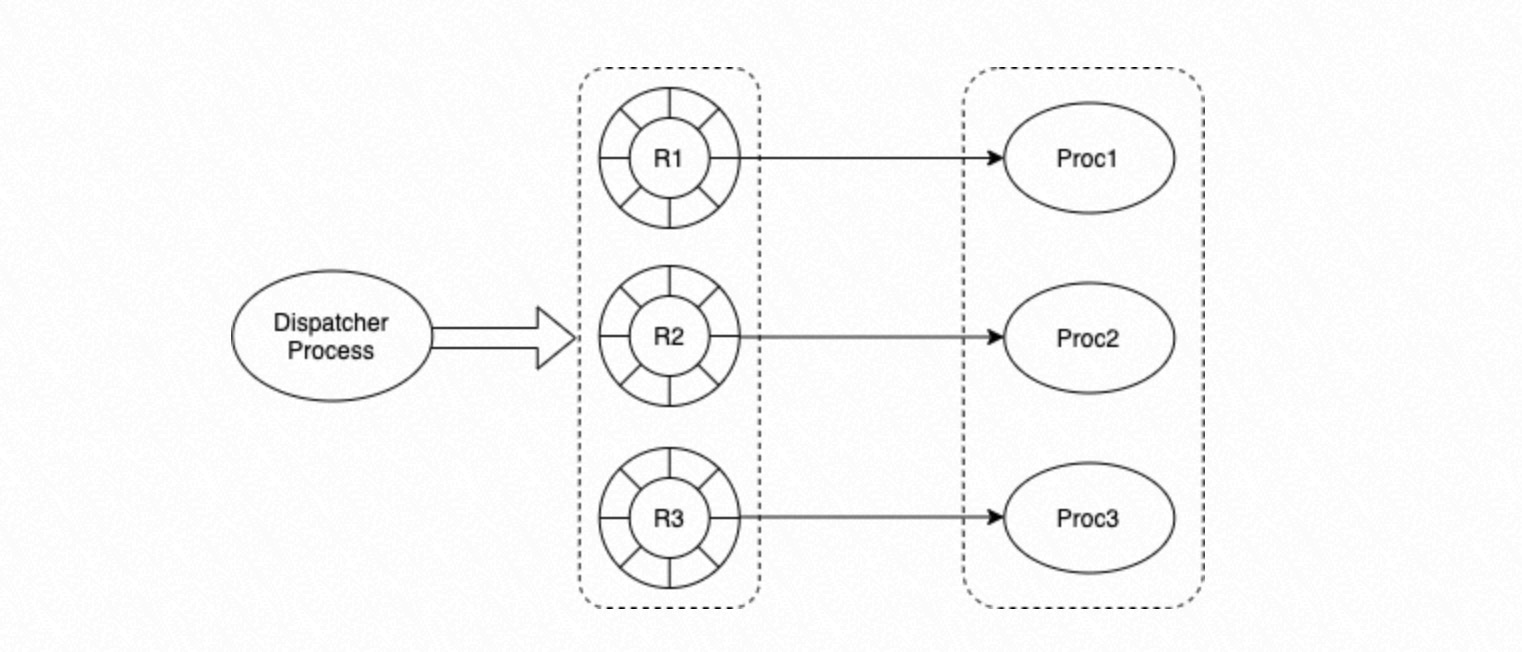
Dispatcher process.
Controls concurrent scheduling by dispatching tasks to specified processes.
Removes completed tasks from the queue.
Process group.
Each process in the group retrieves a task from its corresponding circular queue and executes it based on the task's state.
Tasks
A circular queue consists of Task Nodes. Each Task Node has one of five states: Idle, Running, Hold, Finished, or Removed.
Idle: The Task Node is not assigned a task.
Running: The Task Node is assigned a task and is either waiting for execution or is being executed.
Hold: The task in the Task Node has a dependency on a preceding task and must wait for that task to finish.
Finished: All processes in the process group have completed the task.
Removed: When the Dispatcher process determines that a task is in the Finished state, all its prerequisite tasks must also be Finished. The Dispatcher process then changes the task's state to Removed. This state indicates that the Dispatcher process has deleted the task and its prerequisites from the management struct. This ensures that the Dispatcher process handles the results of dependent tasks in the correct order.
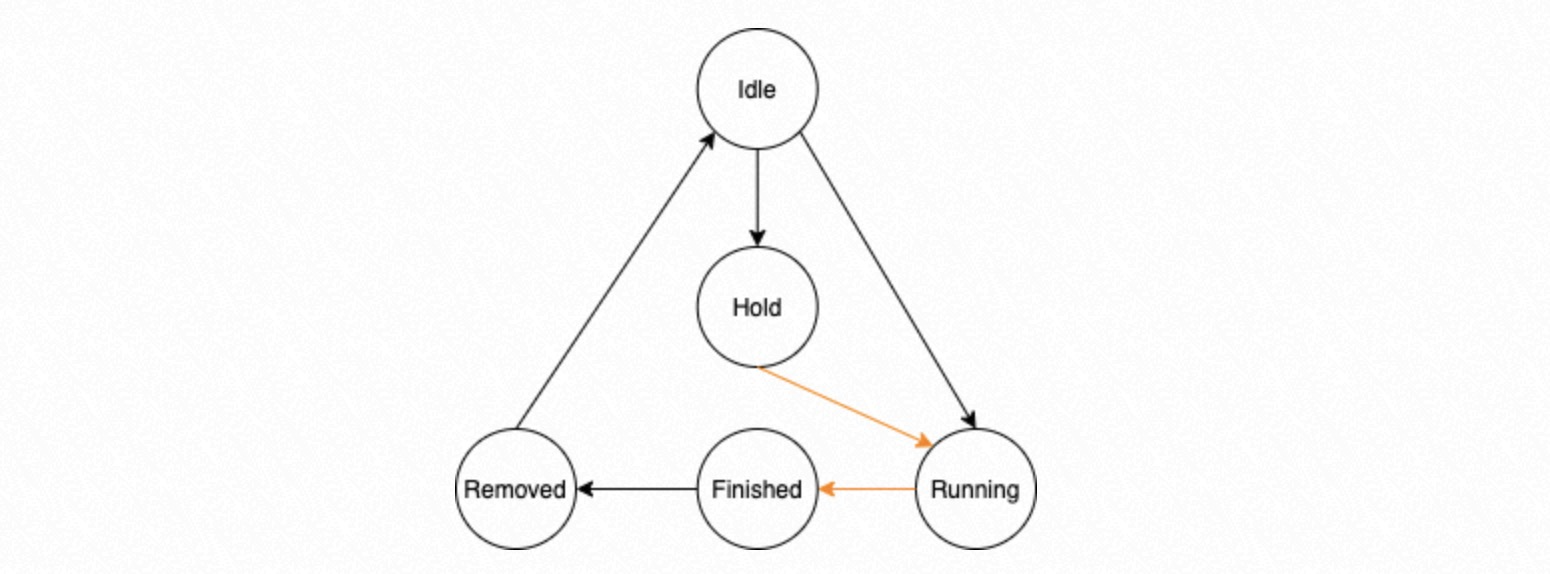 In the state machine transitions shown above, the transitions marked by black lines are performed by the Dispatcher process. The transitions marked by orange lines are performed by the parallel replay process group.
In the state machine transitions shown above, the transitions marked by black lines are performed by the Dispatcher process. The transitions marked by orange lines are performed by the parallel replay process group.Dispatcher process
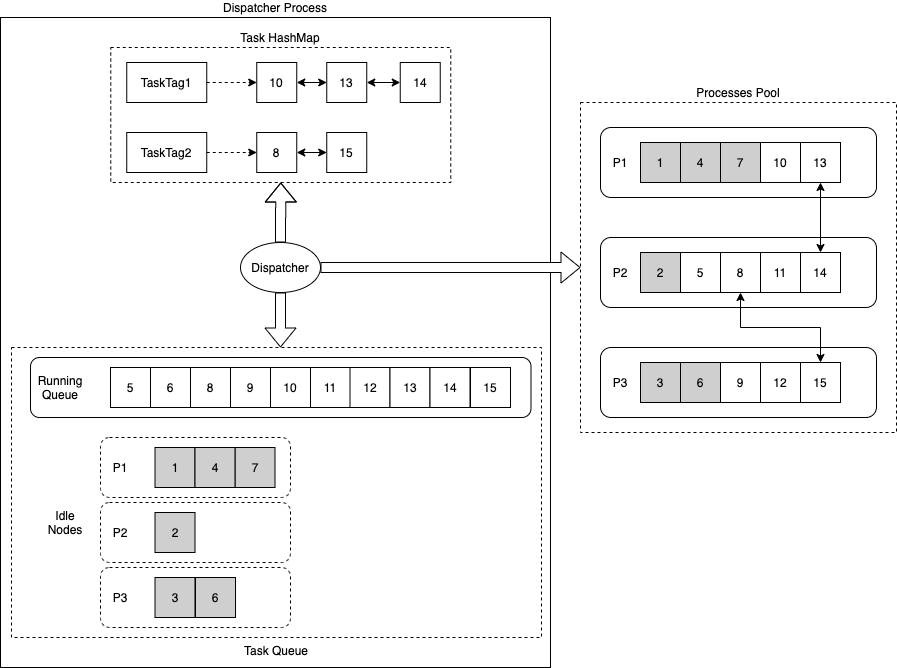
The Dispatcher process uses three key data structures: Task HashMap, Task Running Queue, and Task Idle Nodes.
Task HashMap: Records the hash mapping between Task Tags and their corresponding task execution lists.
Each task has a specific Task Tag. If two tasks have a dependency, they share the same Task Tag.
When a task is dispatched, if the task has a prerequisite, its state is marked as Hold. The task must wait for its prerequisite to be executed.
Task Running Queue: Records the tasks that are currently being executed.
Task Idle Nodes: Records the Task Nodes that are currently in the
Idlestate for different processes in the process group.
The Dispatcher uses the following scheduling policies:
If a task with the same Task Tag as the new task is already running, the new task is preferably assigned to the process that is handling the last task in that Task Tag's linked list. This policy executes dependent tasks on the same process to reduce the overhead of inter-process synchronization.
If the preferred process's queue is full, or if no task with the same Task Tag is running, a process is selected in sequence from the process group. An
IdleTask Node is then retrieved from that process's queue to schedule the task. This policy distributes tasks as evenly as possible across all processes.
Process Group
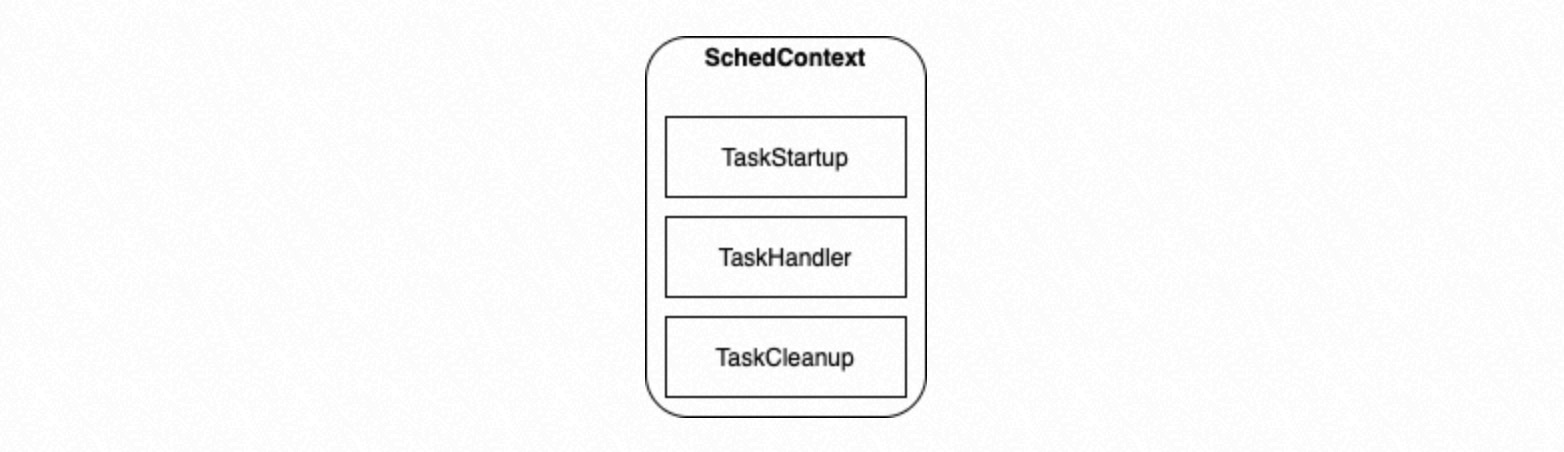
This parallel execution applies to tasks of the same type that share the same Task Node data structure. During process group initialization,
SchedContextis configured to specify the function pointers that execute specific tasks:TaskStartup: Performs initialization before a process executes tasks.
TaskHandler: Executes a specific task based on the incoming Task Node.
TaskCleanup: Performs cleanup before a process exits.
A process in the process group retrieves a Task Node from the circular queue. If the Task Node's state is
Hold, the process inserts it at the tail of theHold List. If the state isRunning, the process callsTaskHandlerto execute the task. IfTaskHandlerfails, the system sets a retry count for the Task Node (the default is 3) and inserts the Task Node at the head of theHold List.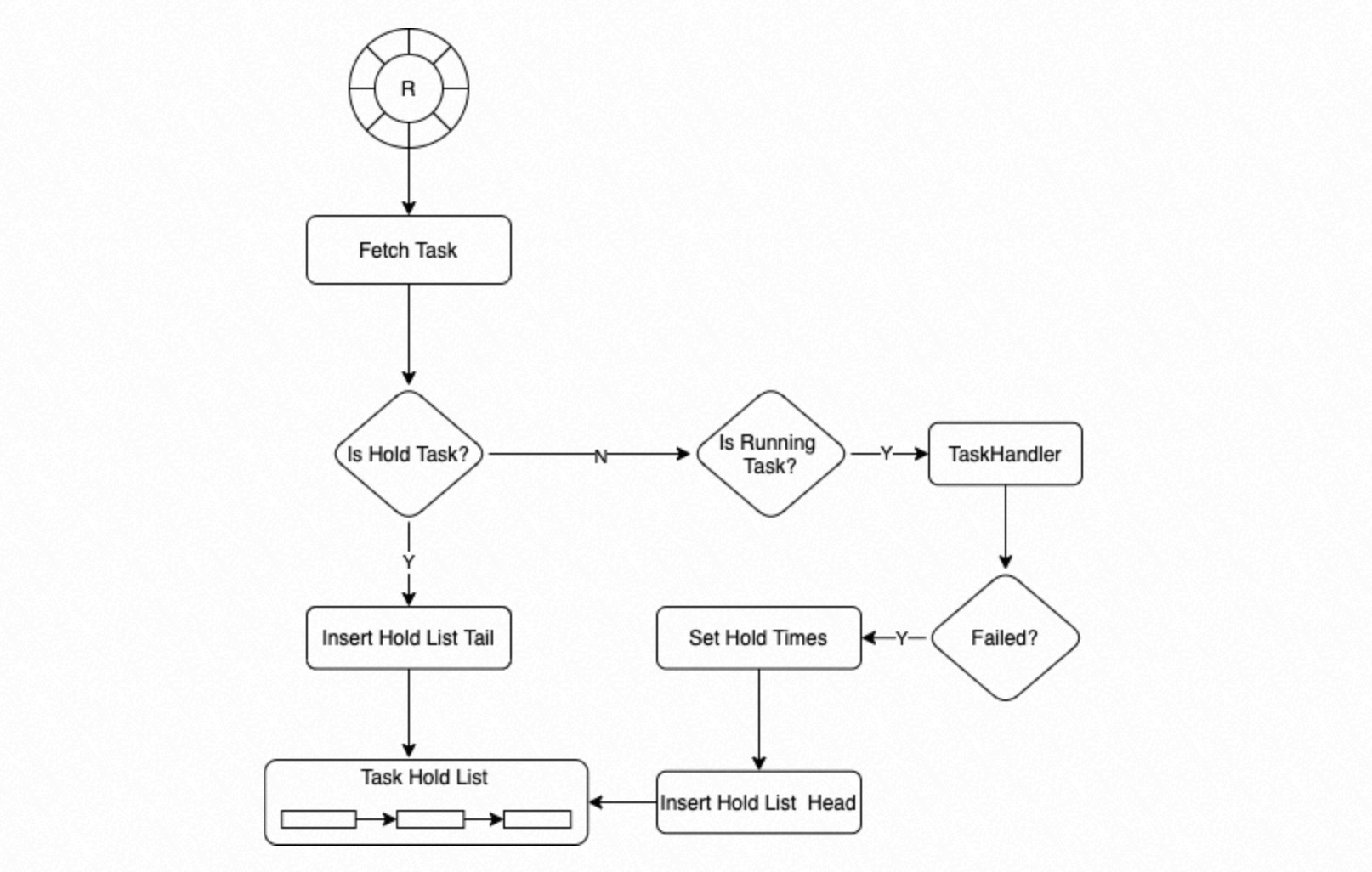
The process searches the
Hold Listfrom the beginning for an executable task. If a task's state isRunningand its wait count is 0, the process executes the task. If a task's state isRunningbut its wait count is greater than 0, the process decrements the wait count by 1.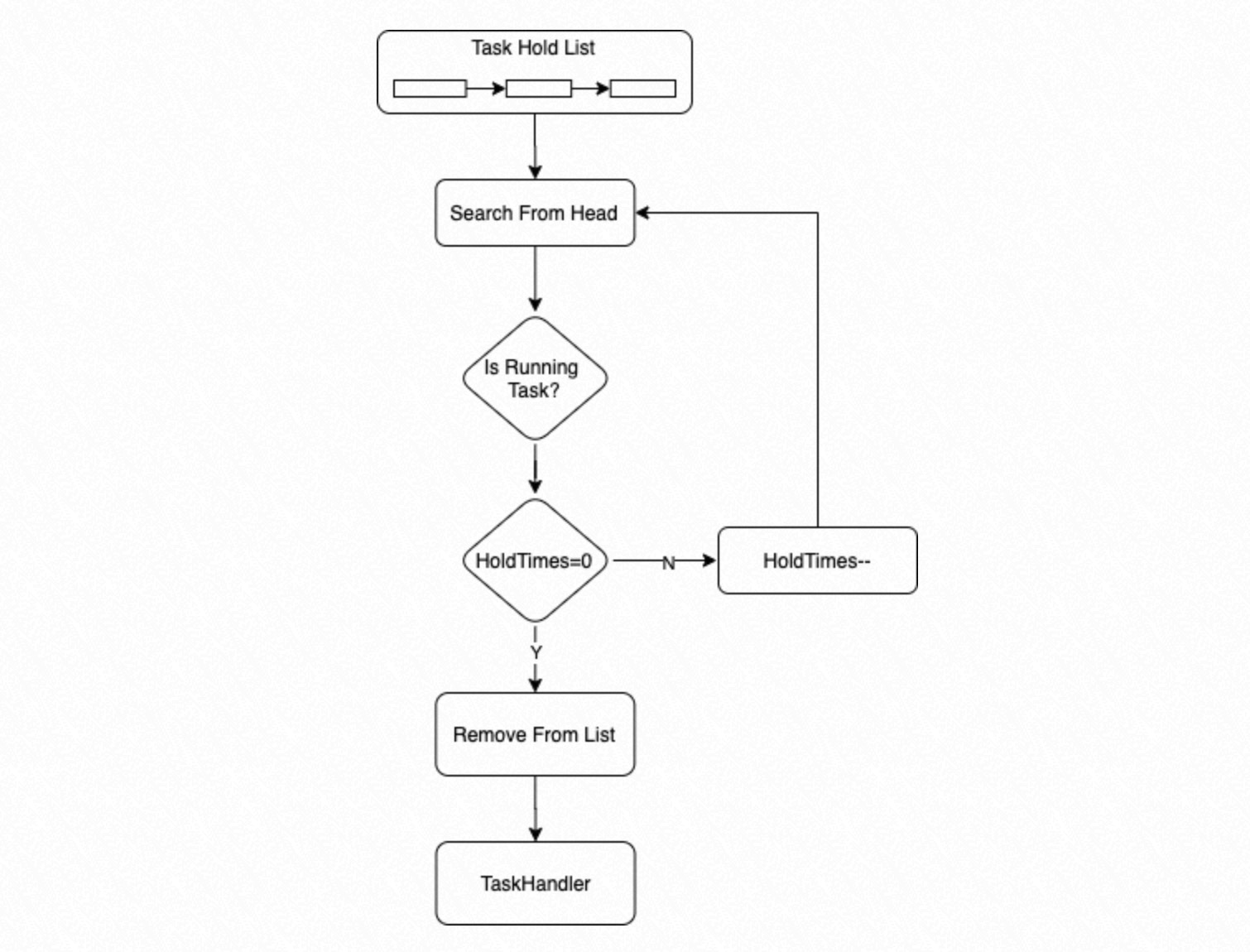
WAL parallel replay
LogIndex data records the mapping between Write-Ahead Logging (WAL) records and the data blocks they modify. It also supports retrieval by LSN. During the continuous replay of WAL records on a standby node, PolarDB uses a parallel execution framework. This framework uses LogIndex data to parallelize WAL replay tasks, which accelerates data synchronization on the standby node.
Workflow
Startup process: Parses WAL records and builds LogIndex data without replaying the WAL records.
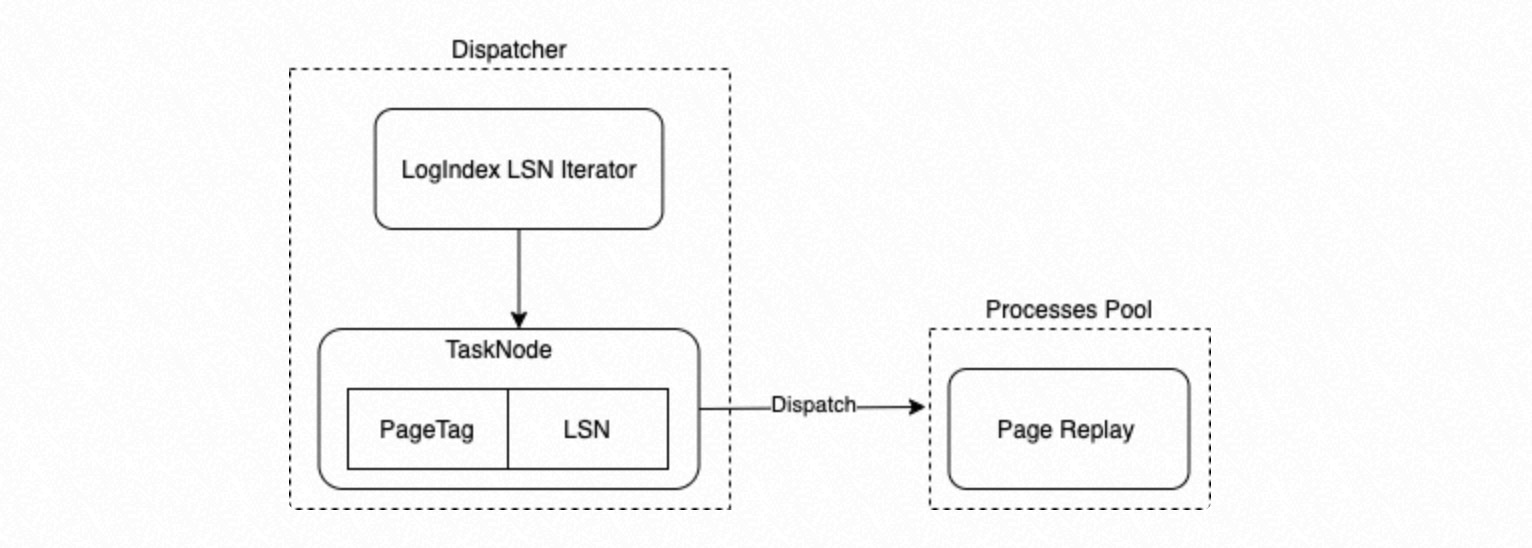
LogIndex BGW replay process: Acts as the Dispatcher process in the parallel execution framework. This process uses LSNs to retrieve LogIndex data, builds replay subtasks, and assigns them to the parallel replay process group.
Processes in the parallel replay process group: Execute replay subtasks and replay a single WAL record on a data block.
Backend process: When reading a data block, the process uses the PageTag to retrieve LogIndex data. It obtains the linked list of LSNs for the WAL records that modified the block and then replays the entire WAL record chain on the data block.
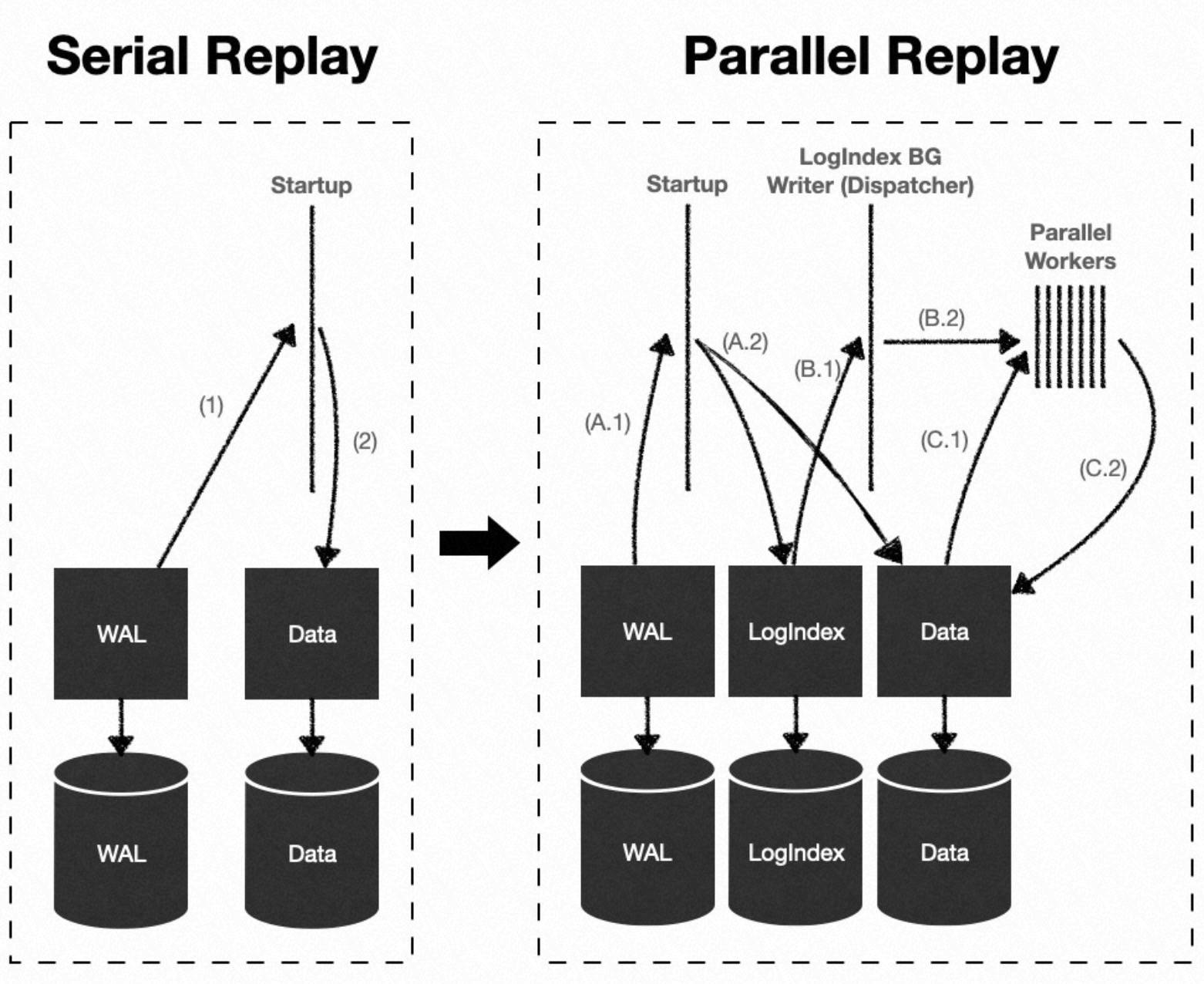
The Dispatcher process uses LSNs to retrieve LogIndex data. It enumerates PageTags and their corresponding LSNs in their LogIndex insertion order to build
{LSN -> PageTag}mappings, which serve as Task Nodes.The PageTag serves as the Task Tag for the Task Node.
The Dispatcher process dispatches the enumerated Task Nodes to the child processes in the parallel execution framework's process group for replay.
Usage guide
To enable the WAL parallel replay feature, add the following parameter to the postgresql.conf file on the standby node.
polar_enable_parallel_replay_standby_mode = ON