With the development of ChatGPT, large language models (LLMs) and generative artificial intelligence (AI) start to play important roles in various fields, such as writing, image generation, code optimization, and information retrieval. LLMs are helpful to individual users and enterprises. LLMs accelerate ecosystem innovation and lead the way in building super applications. This topic describes how to build a dedicated chatbot on top of PolarDB for PostgreSQL.
Background information
An increasing number of enterprises and individual users want to use LLMs and generative AI to build AI-powered applications that are dedicated for specific business scenarios. LLMs deliver excellent performance in resolving common issues. However, LLMs cannot better meet requirements for timeliness and professional knowledge in industry verticals due to the limits of corpus training and large model generation. In the information age, enterprises frequently update their knowledge bases. The knowledge bases in industry verticals, including documents, images, audio files, and videos, may be confidential or cannot be disclosed to the public. If an enterprise wants to use LLMs to build AI-powered applications for industry verticals, the enterprise must constantly import its knowledge base into LLMs for training.
The following list describes the common training approaches:
Fine-tuning: New datasets are provided to fine-tune the weight of an existing model, and the datasets are constantly updated to obtain the required effect. This approach is suitable for training models based on small datasets or models that are task-specific. However, the approach is costly and requires intensive training.
Prompt-tuning: Prompts instead of model weights are adjusted to obtain the required effect. Prompt-tuning generates less computing costs, requires fewer resources and training time, and is more flexible than fine-tuning.
In summary, the fine-tuning approach is featured by high investment and low update frequency and therefore is not suitable for all enterprises. The prompt-tuning approach builds knowledge assets in vector libraries and can use LLMs and vector libraries to construct in-depth services of industry verticals. Databases are used in prompt engineering. Feature vectors are extracted from enterprise knowledge base documents and real-time information and then stored in vector databases. When combined with LLMs, prompt-tuning assists chatbots providing more professional and timely answers and helps small and medium-sized enterprises build dedicated chatbots.
In the machine learning area, artificial intelligence technology is usually used to extract features of unstructured data, and convert them into feature vectors, and then analyze and retrieve these feature vectors for processing of unstructured data. The databases that can store, analyze and retrieve feature vectors are called vector databases.
The following list describes the advantages of building a chatbot on top of PolarDB for PostgreSQL:
PolarDB for PostgreSQL provides the pgvector extension that can be used to translate real-time data or expertise of industry verticals into vector embeddings. PolarDB for PostgreSQL stores the embeddings to accelerate vector-based searches and improve the accuracy of Q&A about a specific private domain.
PolarDB for PostgreSQL combines the following advantages: cost-effectiveness of the distributed architecture and ease of use of the centralized architecture. The separation of compute nodes and storage nodes enables instant scalability and O&M capabilities. PolarDB for PostgreSQL is an internationally leading database product.
The pgvector extension has been widely used in the developer community and open source PostgreSQL databases. In addition, tools such as ChatGPT Retrieval Plugin are supported by PostgreSQL databases at the earliest opportunity. PolarDB for PostgreSQL has been extensively applied and is fully supported to perform vector-based searches. It also provides abundant tools and resources.
LLMs in this topic are from third parties and collectively called third-party models. Alibaba Cloud does not guarantee the compliance and accuracy of third-party models, and disclaims all liability in connection with third-party models or the actions and results of your use of third-party models. You must evaluate the risks before you access or use third-party models. In addition, third-party models come with agreements such as open source licenses and licenses. You must carefully read and strictly abide by these agreements.
Prerequisites
A PolarDB for PostgreSQL cluster is created and meets the following requirements:
PostgreSQL 14 (revision version 14.7.9.0 or later)
NoteFor more information about how to upgrade the revision version, see Version management.
You are familiar with the usage and basic terms of the pgvector extension because the dedicated chatbot in this topic is based on the pgvector extension for PolarDB for PostgreSQL.
A
Secret API keyis obtained, and OpenAI is available in your network environment. The sample code used in this topic is deployed on an Elastic Compute Service (ECS) instance in the Singapore region.A Python development environment is deployed. In this topic,
Python 3.11.4andPyCharm 2023.1.2are used.
Terms
Embedding
Embedding is a method that translates high-dimensional data into a low-dimensional space. In machine learning and natural language processing (NLP), embedding is a common method that is used to represent sparse symbols or objects as continuous vectors.
In NLP, word embedding is an method that is used to represent words in the form of real-valued vectors. This enables computers to better understand the text. Word embedding is used to translate the semantics and grammatical relations of words into a vector space.
OpenAI supports embedding.
How it works
This section describes the phases to build a dedicated chatbot:
Phase 1: Data preparation
Extract text from a domain-specific knowledge base and split the text into chunks. For example, you can split a large piece of text into paragraphs or sentences, and extract keywords or entities. This facilitates the arrangement and management of the data in the knowledge base.
Call an LLM operation such as an operation provided by OpenAI to import the text chunks to models and then generate text embeddings. The embeddings capture the semantic and contextual information of the text for subsequent search and matching.
Store the generated text embeddings, text chunks, and text metadata to your PolarDB for PostgreSQL cluster.
Phase 2: Q&A
Raise a question.
Call the embedding operation that is provided by OpenAI to create an embedding for the question.
Use the pgvector extension to search text chunks whose similarity is greater than a specified threshold in the PolarDB for PostgreSQL cluster and obtain the result.
The following figure shows the process.
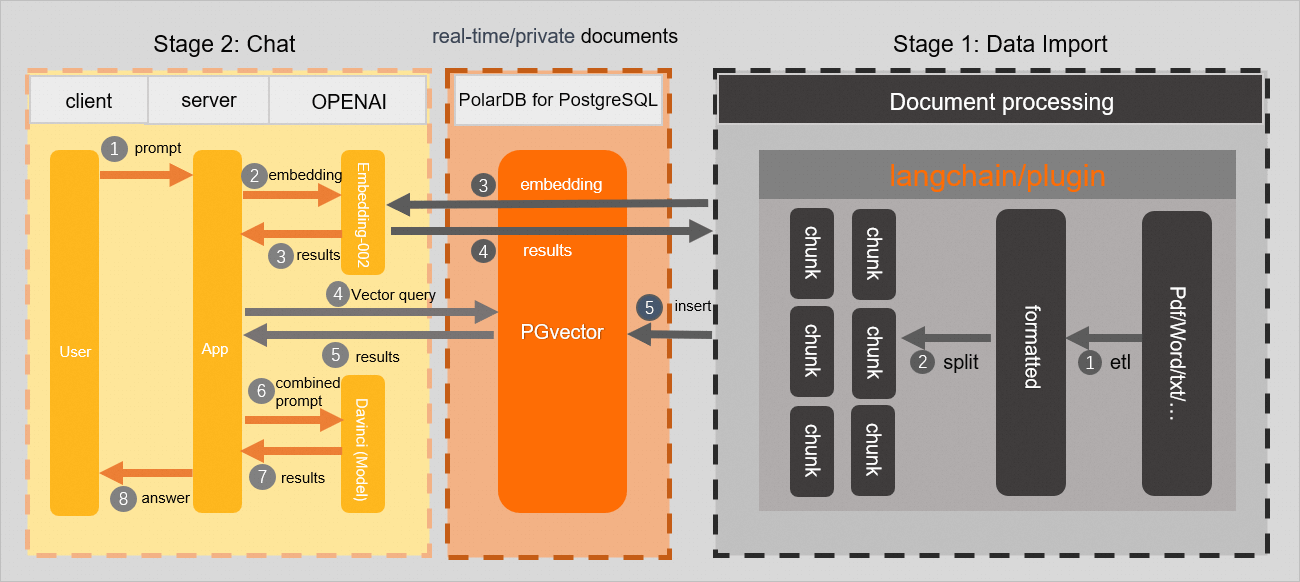
Procedure
Phase 1: Data preparation
In this example, the text data in 2023 of PolarDB for PostgreSQL release notes is split and stored in your PolarDB for PostgreSQL cluster. You must prepare a domain-specific knowledge base.
In this phase, the most important thing is to translate the domain-specific knowledge base into text embeddings and store and match the embeddings in an efficient manner. This way, you can obtain domain-specific high-quality answers and suggestions by leveraging the powerful semantic understanding capabilities of LLMs. Some existing open source frameworks allow you to upload and parse knowledge base files in formats such as URL, Markdown, PDF, and Word, in a convenient manner. For example, the LangChain and open source ChatGPT Retrieval Plugin frameworks of OpenAI are supported. LangChain and ChatGPT Retrieval Plugin can use PostgreSQL databases that supports the pgvector extension as backend vector databases. This facilitates the integration between LangChain and ChatGPT Retrieval Plugin and the PolarDB for PostgreSQL cluster. After the integration, you can prepare the domain-specific knowledge base in an efficient manner and make the most of the vector indexes and similarity searches that are provided by the pgvector extension to implement efficient text matching and query.
Create a test database named
testdb.CREATE DATABASE testdb;Connect to the test database and create the pgvector extension.
CREATE EXTENSION IF NOT EXISTS vector;Create a test table named
polardb_pg_help_docsto store the data of the knowledge base.CREATE TABLE polardb_pg_help_docs ( id bigserial PRIMARY KEY, title text, -- Title description text, -- Description doc_chunk text, -- Text chunk token_size int, -- Number of words in a text chunk embedding vector(1536)); -- Text embeddingCreate an index for the embedding column to optimize and accelerate queries.
CREATE INDEX ON polardb_pg_help_docs USING ivfflat (embedding vector_cosine_ops) WITH (lists = 100);Create a project in PyCharm, open the terminal, and then enter the following statement to install the following dependencies:
pip install openai psycopg2 tiktoken requests beautifulsoup4 numpyNoteIf an issue occurs when you install psycopg2, use the source code to install it.
Create a
.pyfile to split the data in the knowledge base and store the split data in the PolarDB cluster. In this example, theknowledge_chunk_storage.pyfile is created. Sample code:NoteIn the following sample code, the custom splitting method only split the data in the knowledge base into chunks with a fixed number of characters. You can use the splitting methods that are provided by LangChain and open source ChatGPT Retrieval Plugin of OpenAI. The quality of data in the knowledge base and the chunking result have a great impact on the final result.
import openai import psycopg2 import tiktoken import requests from bs4 import BeautifulSoup EMBEDDING_MODEL = "text-embedding-ada-002" tokenizer = tiktoken.get_encoding("cl100k_base") # Connect to a PolarDB for PostgreSQL database. conn=psycopg2.connect (database="<Database name>", host="<PolarDB for PostgreSQL cluster endpoint>", user="<Username>", password="<Password>", port="<Database port number>") conn.autocommit = True # API key of OpenAI openai.api_key = '<Secret API Key>' # Custom splitting method (The following method is an example.) def get_text_chunks(text, max_chunk_size): chunks_ = [] soup_ = BeautifulSoup(text, 'html.parser') content = ''.join(soup_.strings).strip() length = len(content) start = 0 while start < length: end = start + max_chunk_size if end >= length: end = length chunk_ = content[start:end] chunks_.append(chunk_) start = end return chunks_ # Specify the web page to be split. url = 'https://www.alibabacloud.com/help/document_detail/602217.html?spm=a2c4g.468881.0.0.5a2c72c2cnmjaL' response = requests.get(url) if response.status_code == 200: # Obtain the data on the web page. web_html_data = response.text soup = BeautifulSoup(web_html_data, 'html.parser') # Obtain the title with the H1 tag. title = soup.find('h1').text.strip() # Obtain the description (The description is enclosed in p tags and belongs to the shortdesc class.) description = soup.find('p', class_='shortdesc').text.strip() # Split and store the data. chunks = get_text_chunks(web_html_data, 500) for chunk in chunks: doc_item = { 'title': title, 'description': description, 'doc_chunk': chunk, 'token_size': len(tokenizer.encode(chunk)) } query_embedding_response = openai.Embedding.create( model=EMBEDDING_MODEL, input=chunk, ) doc_item['embedding'] = query_embedding_response['data'][0]['embedding'] cur = conn.cursor() insert_query = ''' INSERT INTO polardb_pg_help_docs (title, description, doc_chunk, token_size, embedding) VALUES (%s, %s, %s, %s, %s); ''' cur.execute(insert_query, ( doc_item['title'], doc_item['description'], doc_item['doc_chunk'], doc_item['token_size'], doc_item['embedding'])) conn.commit() else: print('Failed to fetch web page')Start a Python program.
Log on to the database and execute the following statement to check whether the data in the knowledge base is split and stored as vectors:
SELECT * FROM polardb_pg_help_docs;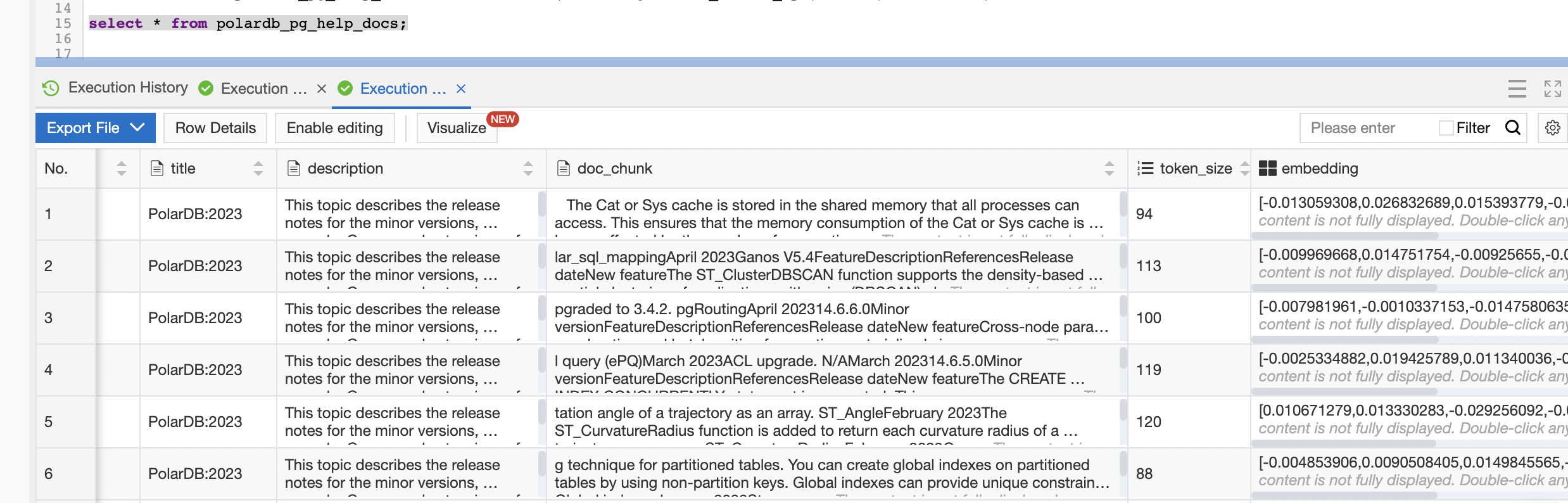
Phase 2: Q&A
In the Python project, create a
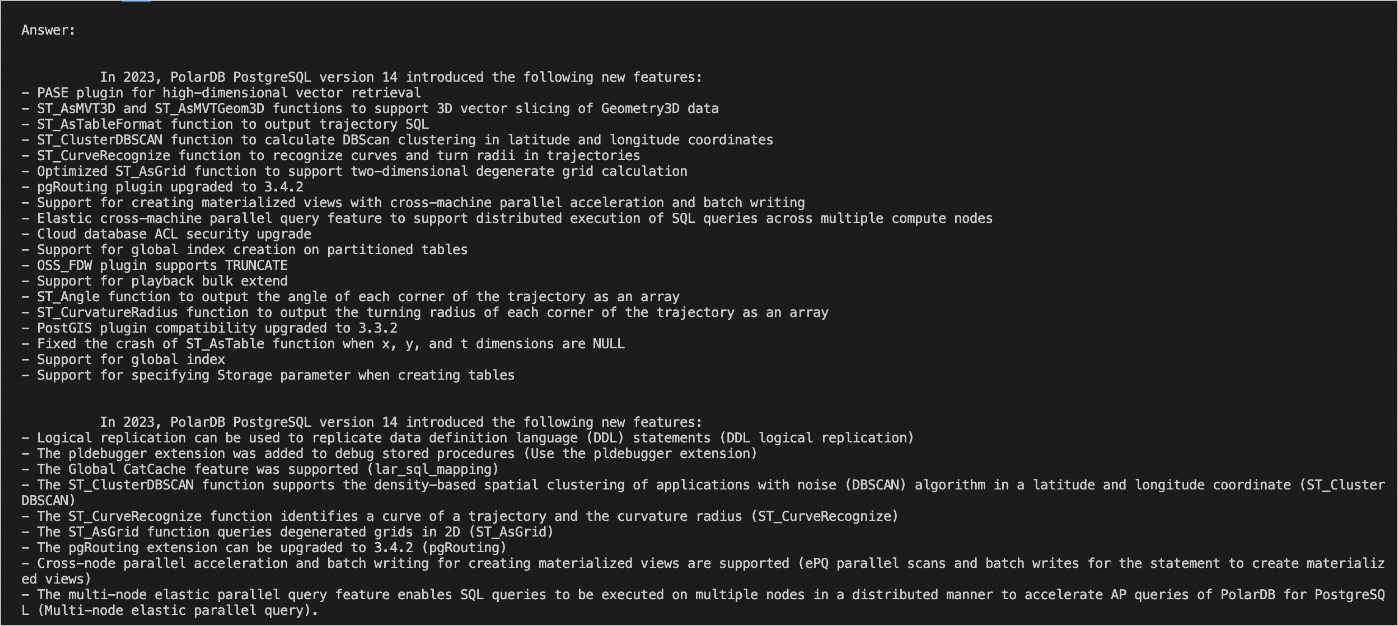
.pyfile, define a question in the file, and compare the similarity between the question and the data in the knowledge base of the PolarDB cluster. In this example, thechatbot.pyfile is created. Sample code:# Connect to a PolarDB for PostgreSQL database. conn=psycopg2.connect (database="<Database name>", host="<PolarDB for PostgreSQL cluster endpoint>", user="<Username>", password="<Password>", port="<Database port number>") conn.autocommit = True def answer(prompt_doc, prompt): improved_prompt = f""" Answer the following questions based on the following file and steps: a. Check whether the content in the file is related to the question. b. Reference the content in the file to answer the question and provide the detailed answer as a Markdown file. c. Use "I don't know because the question is beyond my scope" to answer the questions that are irrelevant to PolarDB for PostgreSQL. File: \"\"\" {prompt_doc} \"\"\" Question: {prompt} """ response = openai.Completion.create( model=GPT_COMPLETIONS_MODEL, prompt=improved_prompt, temperature=0.2, max_tokens=MAX_TOKENS ) print(f"{response['choices'][0]['text']}\n") similarity_threshold = 0.78 max_matched_doc_counts = 8 # Use the pgvector extension to search file chunks whose similarity is greater than the specified threshold. similarity_search_sql = f''' SELECT doc_chunk, token_size, 1 - (embedding <=> '{prompt_embedding}') AS similarity FROM polardb_pg_help_docs WHERE 1 - (embedding <=> '{prompt_embedding}') > {similarity_threshold} ORDER BY id LIMIT {max_matched_doc_counts}; ''' cur = conn.cursor(cursor_factory=DictCursor) cur.execute(similarity_search_sql) matched_docs = cur.fetchall() total_tokens = 0 prompt_doc = '' print('Answer: \n') for matched_doc in matched_docs: if total_tokens + matched_doc['token_size'] <= 1000: prompt_doc += f"\n---\n{matched_doc['doc_chunk']}" total_tokens += matched_doc['token_size'] continue answer(prompt_doc,prompt) total_tokens = 0 prompt_doc = '' answer(prompt_doc,prompt)View the answer after you run the Python program. The following figure shows a sample result.
NoteTo obtain a more accurate and complete answer, you can optimize the splitting method and the question prompts.
Summary
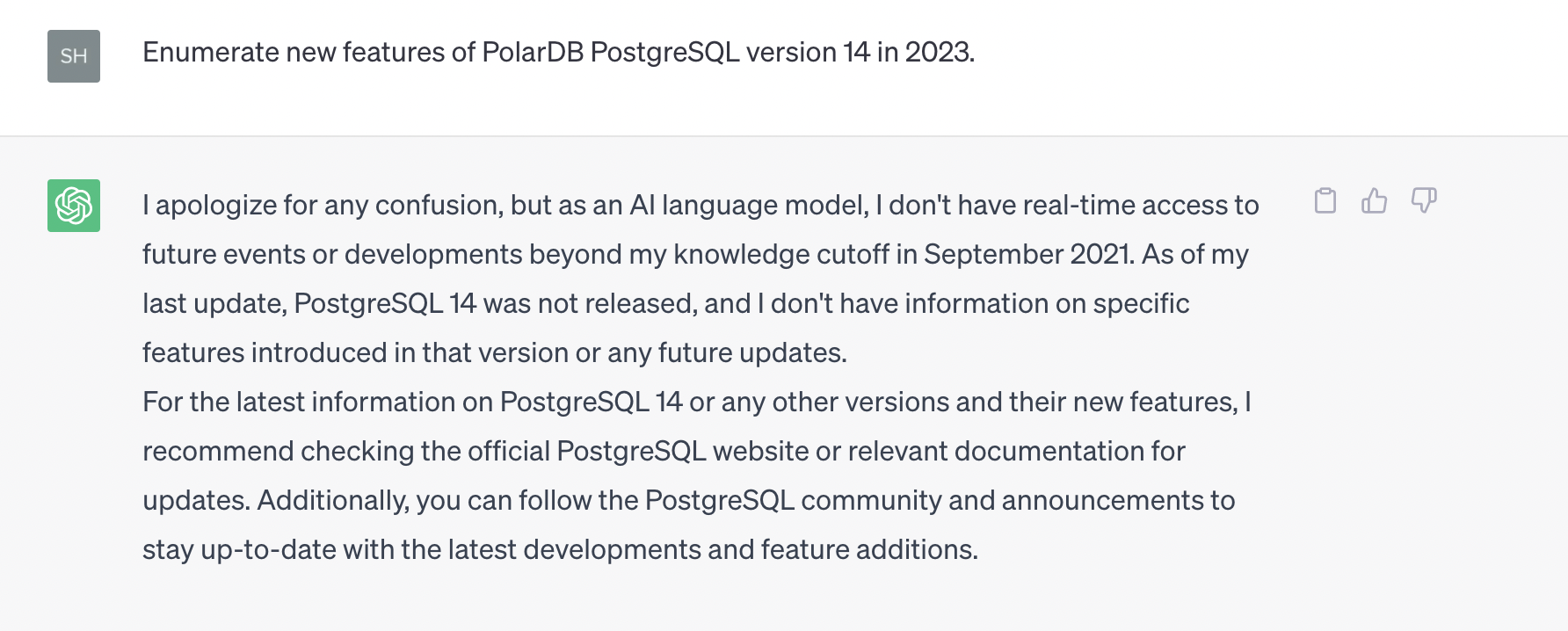
If the vector database is not connected, the answer of OpenAI to the question "What are the new features in 2023 of PolarDB for PostgreSQL 14 release notes?" is irrelevant to Alibaba Cloud. Example:
After the vector database in your PolarDB for PostgreSQL cluster is connected, the answer to the question "What are the new features in 2023 of PolarDB for PostgreSQL 14 release notes?" is closely relevant to PolarDB for PostgreSQL clusters.

In summary, PolarDB for PostgreSQL is fully capable of building an LLM-driven knowledge base for an industry vertical.
Related videos
AI Chatbots: From Limitations to Possibilities | Practical Guide to Enhance AI Chatbot Capabilities
References
For more information, visit https://github.com/openai/openai-cookbook/tree/main/examples/vector_databases/PolarDB.