The TopK operator implementation in IMCI topic describes how the In-Memory Column Index (IMCI) feature of PolarDB uses statistics to prune data to improve the query performance of TopK algorithms. This topic describes the pruning methods of IMCI.
Background information and effects
In hybrid transaction/analytical processing (HTAP) scenarios, the IMCI feature of PolarDB uses column-oriented heap tables as the storage architecture to support real-time updates. Column store indexes of SQL Server and Oracle use the same storage architecture. However, the storage architecture that uses heap tables does not reduce the amount of data to be scanned during queries. In most cases, a full table scan is required. To minimize the amount of data to be scanned and reduce full table scans, SQL Server uses the MIN() and MAX() functions, partitions, and clustered indexes, whereas Oracle uses the MIN() and MAX() functions and the metadata dictionary based on in-memory column store indexes. The IMCI feature of PolarDB uses column-oriented tables and supports data storage to provide more diverse methods to optimize full table scans.
Storage architecture | Feature | Example |
Column-oriented heap tables |
|
|
Log-structured merge (LSM)-based column-oriented storage |
|
|
The IMCI feature of PolarDB organizes data by row group. Each row group contains about 64,000 rows. The column index of each column is stored without specific order based on the append write mode. Therefore, IMCI cannot filter out data based on query conditions as accurately as the ordered indexes of InnoDB. When IMCI reads data packs, IMCI loads the data packs from disks into memory, decompresses the data packs, traverses all the data records in the data packs, and then finds the data records that meet query conditions. When you scan a large table, a full table scan is inefficient and the least recently used (LRU) cache is affected, which increases the overall query latency and reduces queries per second (QPS).
To reduce full table scans, the IMCI feature of PolarDB provides pruning methods. IMCI uses pruning to filter out the data packs that you do not want to access in advance. This reduces the amount of data to be queried and improves query efficiency. To implement this, IMCI uses a pruning method to access partitions or statistics and prune data that does not meet the specified conditions before data is queried. This reduces the number of scans for stored data and the amount of resources that are consumed for data transfer and computing. Pruning is applicable to data queries from a single table and from multiple tables and can improve the query performance of PolarDB IMCI.
Basic principles and usage methods
Partition pruning
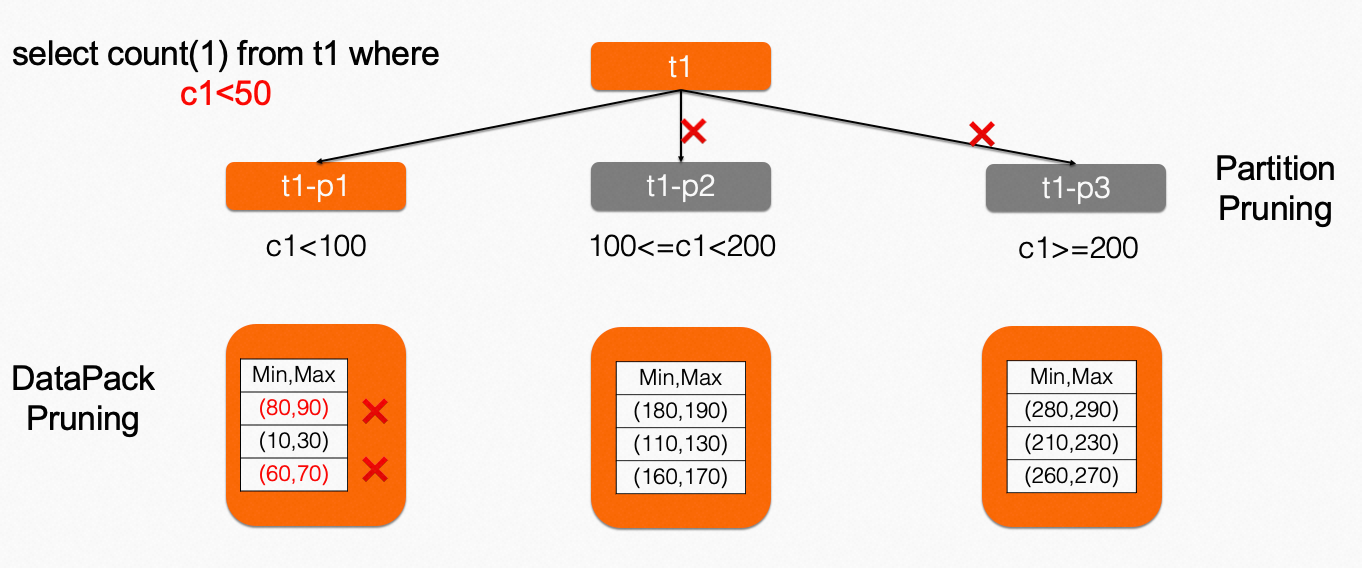
The partition pruning method of IMCI is used to filter out partitions that do not need to be queried based on partition keys when queries are performed. This reduces the amount of data to be queried and improves query efficiency. IMCI supports the following partitioning methods: RANGE, LIST, and HASH. The RANGE or LIST partitioning method splits a table into multiple ranges or lists. The HASH partitioning method hashes data to different partitions. When you use the partition pruning method, you must use query statements that meet the partitioning conditions and specify query conditions based on the partition key.
For example, a table named orders is split into 12 partitions based on the order date. You can execute the following statement to query the orders on a specific day:
SELECT * FROM orders WHERE order_date = '2022-01-01';When IMCI runs the query, IMCI finds the partition that meets the query conditions based on the order date and queries only the data of the partition. This reduces the amount of data to be queried and improves query efficiency. IMCI also supports inference based on the equivalence relation between joined columns to perform full partition pruning. For example, the partition key of Table R and Table S is a, and you execute the following query statement: select count(1) from R,S where R.a = S.a and R.a > 10. Based on the conditions R.a = S.a and R.a > 10, it can be inferred that S.a > 10, which can be used for the partition pruning of Table S.
The following list describes the pruning algorithms for different types of partitions:
For partitions that are generated by using the RANGE partitioning method, the boundary points of different partitions are stored in an array in sequence. Therefore, you can use the binary search method to search for partitions.
For partitions that are generated by using the LIST partitioning method, the list value of each partition and the partition ID form a tuple in the <value, part_id> format. The tuple is stored by list values in sequence. You can also use the binary search method to search for partitions.
For partitions that are generated by using the HASH partitioning method, possible values are enumerated for hashing, and the hash values are calculated to determine which partitions they fall into. This pruning algorithm can be used only for integer fields when a small number of values need to be enumerated.
The following figure shows the pruning algorithm of partitions.

In actual use, you must select appropriate partition types and partition keys based on the data volume and query requirements to achieve optimal query performance.
Statistics pruning
IMCI uses statistics on data packs to filter out data packs that do not need to be queried. This is similar to data skipping indexes in ClickHouse and the Knowledge Grid of Infobright. In IMCI, pruners help optimize query performance. When a query is performed, an IMCI pruner uses statistics and query conditions to prune data and determine whether a data pack needs to be scanned. Because the statistics occupy a small amount of memory, they can be resident in memory. If data is pruned, the number of I/O operations and the number of condition-based judgments are reduced. This way, the query performance is improved.
A data pack may be in one of the following states after the data pack is filtered by an IMCI pruner: Accept or AC, Reject or RE, and Partial Accept or PA. If the data pack is in the Accept state, IMCI does not need to scan each data record in the data pack, which reduces computing overheads. If the data pack is in the Reject state, IMCI does not need to load the data pack into the memory, which reduces the number of I/O operations and computing overheads and prevents the LRU cache from being affected. If the data pack is in the Partial Accept state, IMCI needs to further scan each data record in the data pack to find the data records that meet query conditions.
IMCI provides two types of pruners: minmax indexes and Bloom filters, which are suitable for different scenarios. In addition, IMCI optimizes queries on nullable columns. An IMCI pruner can filter out the data packs that contain null values during queries to further accelerate queries.
Minmax indexes
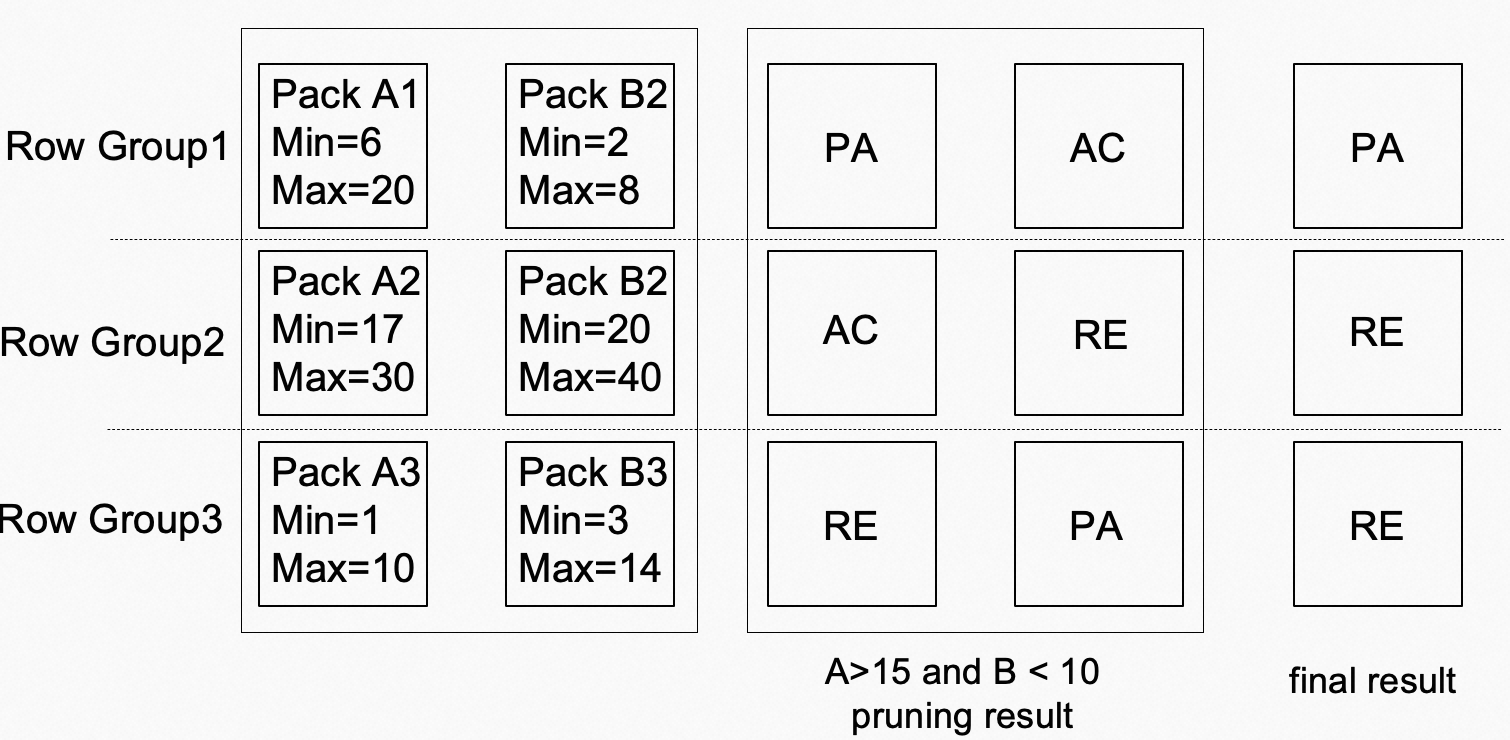
Minmax indexes are used as an enhanced indexing technology for large datasets. Minmax indexes provide fast and efficient data retrieval by storing the minimum and maximum values of each data pack to index datasets. Minmax indexes are suitable for data in a dataset with continuous values, such as timestamps or real values. A minmax index splits a dataset into data packs, and then calculates the minimum and maximum values of each data pack, which are stored in the index. When data is queried, the minmax index can quickly find data packs to be queried based on the minimum and maximum values of the query range, thereby reducing access to irrelevant data. The following figure shows an example. In this example, both Column A and Column B contain three data packs. Based on the conditions A > 15 and B < 10 and a minmax index, Row Group 2 and Row Group 3 can be skipped, and only Row Group 1 needs to be accessed. This reduces the scanning workload by two thirds.
A minmax index can process a large dataset in a short period of time. It can reduce the amount of data to be scanned during a query because it needs to process only data packs that are relevant to the query range. In addition, the minmax index helps reduce the space that is required to store indexes because it needs to store only the minimum and maximum values of each data pack instead of the indexes of all data.
Bloom filters
A Bloom filter is a probabilistic data structure that is used to check whether an element is a member of a set. It uses an array of bits and a set of hash functions to store and search for elements. When an element is added to a set with a Bloom filter, the hash functions map the element to several bits in the bit array and set the corresponding bits to 1. When the Bloom filter is used to check whether the element is a member of a set, the hash functions are applied to the element again. If all corresponding bits are 1, the element may be in the set. However, if one of the corresponding bits is 0, the element is not in the set. A Bloom filter is a space- and time-efficient data structure. However, false positives may occur. In this case, when you query an element that does not exist in a set, the Bloom filter may falsely report that the element exists in the set.
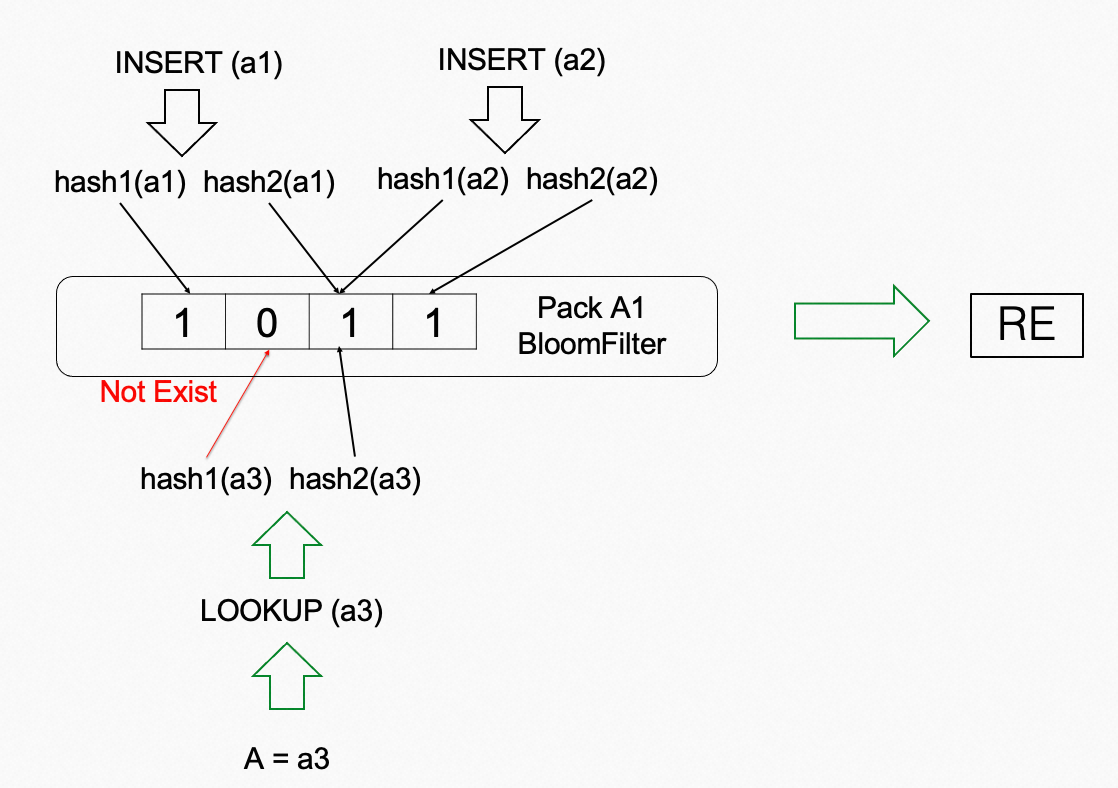
A Bloom filter is space- and time-efficient, scalable, and controllable in the misjudgment rate. These features make the Bloom filter a useful data structure for checking whether elements exist in large datasets.
A Bloom filter and a minmax index can be used together. IMCI determines whether to skip a data pack based on the results generated after they are used together.
Optimization of queries on nullable columns
Due to the special processing logic of null values, database indexes do not fully support columns with null values in most cases. Different databases process nullable columns in different ways.
The IMCI feature of PolarDB optimizes queries on nullable columns. This reduces the impact of null values on query performance. When you use PolarDB, columns that contain null values are frequently used. If you want to use default values to replace null values, you must perform DDL operations to change table schemas and may also need to change the existing SQL statements for querying business data. The IMCI feature of PolarDB allows you to create minmax indexes and Bloom filters for columns with null values to support the queries that contain predicates such as IS Null, IS NOT Null, >, <, and =.
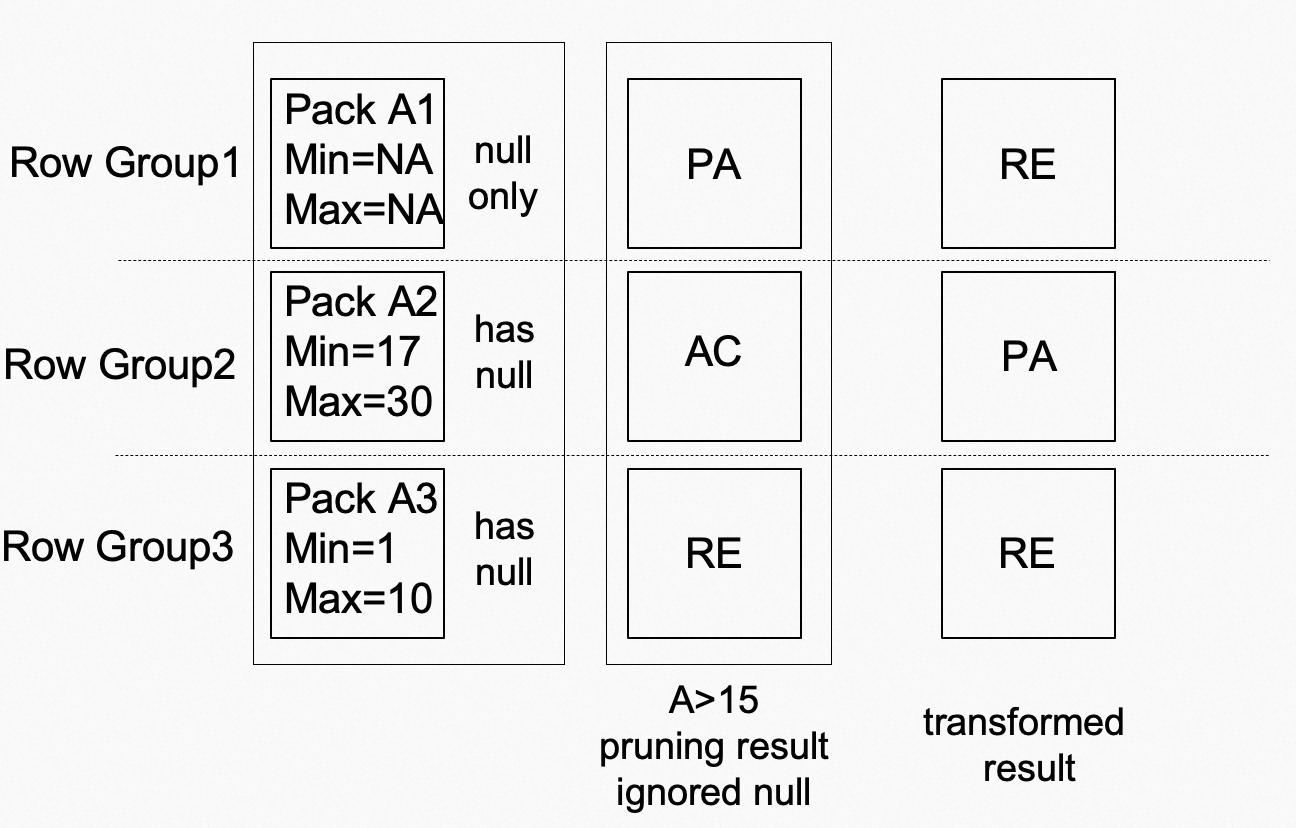
If a data pack contains a null value, the value is skipped when a pruner is built. For example, a data pack contains four data entries: 1, 2, 3, and null. The minimum value is 1 and the maximum value is 3. During a query on the data pack, the query is processed with null values ignored, and then the processing result is converted based on whether the data pack contains a null value. The preceding figure shows an example. In this example, Pack A1 contains only null values. Both Pack A2 and Pack A3 partially contain null values. Based on the condition A > 15, [PA, AC, RE] is obtained as the result without considering null values. Because Pack A1 contains only null values, it cannot be filtered. Then, the result is converted into [RE, PA, RE] based on the fact that each data pack contains null values. Finally, Pack A1 and Pack A3 can be pruned. This improves query performance.
Runtime filters
A Runtime filter is used for query optimization. It is dynamically generated during queries. During a query, the Runtime filter can filter out data that does not meet the specified conditions based on the scanned data values or other information. This reduces the amount of data to be queried and improves query performance. IMCI provides two common types of Runtime filters: Bloom filters and minmax filters. They can be applied to various queries, such as JOIN, GROUP BY, and ORDER BY.
For example, the IMCI feature of PolarDB optimizes TopK queries that use the ORDER BY column LIMIT syntax. You can use a self-sharpening input filter built by the TopK operator and a minmax index that is created on data packs at the storage layer to perform pruning. This accelerates TopK queries. For more information, see the Computing pushdown section of the "TopK operator implementation in IMCI" topic.
In addition, Runtime filters can be used to accelerate hash joins. For example, you want to execute the SELECT * FROM sales JOIN items ON sales.item_id = items.id WHERE items.price > 1000 statement. In this statement, the sales table is a fact table, and the items table is a dimension table. The items table is small. The number of returned data records can be further reduced based on the following condition: price > 1000. When the sales table and the items table are joined, a Runtime filter can be built based on the item_id result set that meets the specified conditions. If the minimum value is 1 and the maximum value is 100, the id > 1 and id < 100 filter expression or the in(id1,id2,id3 ...) expression can be generated. The Runtime filter is passed to the left table. When the data records of the left table are scanned for probes, the Runtime filter can filter out data records that do not meet the specified conditions in advance to reduce the number of probes. For data of the STRING type, you can create a Bloom filter for the result set of the right table to filter data of the STRING type in advance. A Bloom filter increases resource overheads and is not suitable for large result sets. If a pruner exists on a column of the left table, the pruner can filter data records based on the Runtime filter to reduce data packs to be scanned. In massively parallel processing (MPP) scenarios, Runtime filters can help reduce the amount of data to be shuffled.

Bitmap indexes
Bitmap indexes are also used in row-oriented storage. For example, Oracle provides bitmap indexes, which are suitable for low-cardinality columns. In a bitmap index, each distinct value in a column is assigned a bit that represents the presence or absence of the value in each row of the table. When data is filtered during a query, you can obtain the bitmap information based on the column values to find a row. This is especially suitable for queries that contain predicates such as AND or OR for multiple columns. In most cases, B-tree indexes that help filter and find data records are suitable for high-cardinality columns. B-tree indexes complement bitmap indexes. B-tree indexes are suitable for scenarios in which the search mode is fixed. Bitmap indexes can also be used in these scenarios. However, B-tree indexes are not fully compatible with queries that contain the OR predicate.
Bitmap indexes occupy less storage space than B-tree indexes for low-cardinality columns. The following figure shows an example. In this example, bitmap indexes are created for the GENDER and RANK columns of the table. The table contains only five rows. The bitmap that corresponds to one column value needs only five bits. Compared with a traditional B-tree index, a bitmap index requires less storage space, and the required storage space depends on the cardinality and total number of rows. For global bitmap indexes, due to the characteristics of bitmap indexes, you must maintain the bitmap indexes and lock the entire table if you modify a row of the table. Therefore, global bitmap indexes are suitable for scenarios in which the amount of data to be read is more than that of data to be written.
The IMCI feature of PolarDB supports bitmap indexes for data packs. The row numbers of the required data can be directly returned based on bitmap indexes. This reduces access to data packs.

Benefits and scenarios
The IMCI feature of PolarDB supports multiple pruning methods that are complementary to each other. You can use a method based on your data characteristics and query scenarios. If you want to use the pruning methods supported by PolarDB IMCI, make sure that your data is distributed. The more distributed the data, the better the pruning effect. However, data may not be distributed as expected in actual scenarios. In this case, you must carefully plan to distribute data.
Partition pruning: To use this method, you must select appropriate partition keys to create partitioned tables. Data is distributed in advance based on partition keys. In most cases, irrelevant data is filtered out as expected. If most of the query conditions that you specify contain partition keys and you want to manage the data lifecycle by partitions, you can prune partitioned tables and create level-1 or level-2 partitions based on your business requirements.
Minmax index: To use this pruner, the data in a column must be well distributed and support range queries. For example, data of the TIMESTAMP type is inserted into a table in sequence. A minmax index that is created on the column of the TIMESTAMP type facilitates data filtering.
Bloom filter: A Bloom filter can be used to improve the filtering performance of equivalent conditions and IN conditions. It provides expected filtering results based on equivalent conditions with good filtering performance. For example, you can use a Bloom filter for various IDs that are randomly generated. In most cases, a single ID corresponds only to a small number of data records. An equivalent filter condition that contains such an ID can prune data that does not meet the condition.
Bitmap index: A bitmap index is suitable for queries that contain a single filter condition or multiple powerful filter conditions, or queries that do not require materialized data, such as
select count(*) from t where xxx.
Limits and solutions
The various pruning methods of IMCI have their own limits. In actual scenarios, they must be combined with multiple methods to improve data pruning capabilities.
Partition pruning: High costs are generated when DDL operations are performed on existing data. In addition, query conditions must contain partition keys to take effect. You can perform DDL operations on existing data during off-peak hours. If multiple query conditions do not contain partition keys, we recommend that you use another method to optimize queries.
Statistics pruning: Statistics are sorted without specific order. Therefore, the statistics are less effective in scenarios in which the data is evenly dispersed and distributed. You can use one of the following optimization solutions:
Reduce data pack sizes. For minmax indexes and Bloom filters, a smaller data pack size indicates a finer-grained index and a better pruning effect in most cases. IMCI allows you to change the data pack size of a table. However, if the data pack size is reduced, a data pack may occupy more memory resources.
Sort data. If the data is randomly distributed, you can use the sort key feature of PolarDB IMCI to perform statistics pruning.
Disable pruners. Statistics pruning may not help optimize queries but generates computing and memory overheads. Bloom filters also increase I/O overheads. In this case, you can disable the pruners during queries.
Performance test
This section tests the performance of pruners and bitmap indexes in PolarDB HTAP scenarios. The pruners include minmax indexes and Bloom filters. The test dataset uses 100 GB of TPC-H data. Several typical queries are tested, including point query and range query. Data types involve NUMERIC and STRING types.
Test SQL statements
The effectiveness of lightweight indexes depends on data distribution and query types. The effectiveness of lightweight indexes is tested in the following way: Several SQL statements that are constructed based on the scan operator are used to compare the acceleration effects before and after pruners and bitmap indexes are used. The test environment uses in-memory storage and the concurrency is set to 1. In scenarios in which I/O is involved, the acceleration effect of indexes is better.
Q1:select count(*) from partsupp where ps_suppkey = 41164;
Q2:select count(*) from partsupp where ps_suppkey in (41164,58321);
Q3:select count(*) from partsupp where ps_suppkey between 40000 and 50000;
Q4:select count(*) from orders where o_clerk = 'Clerk#000068170';
Q5:select count(*) from orders where o_clerk in ('Clerk#000068170', 'Clerk#000087784');
Q6:select count(*) from customer where c_mktsegment = 'AUTOMOBILE';
Q7:select count(*) from customer where c_mktsegment in ('AUTOMOBILE','FURNITURE','BUILDING');
Q8:select count(*) from customer where c_mktsegment = 'AUTOMOBILE' or c_phone = '18-338-906-3675';
Q9:select count(*) from customer where c_mktsegment = 'AUTOMOBILE' and c_phone = '18-338-906-3675';Test results
Q1 to Q5 verify the acceleration effect of pruners. Queries on the ps_suppkey column of the partsupp table can be accelerated by using a minmax index and queries on the o_clerk column of the orders table can be accelerated by using a Bloom filter. The acceleration ratio is proportional to the number of filtered data packs.
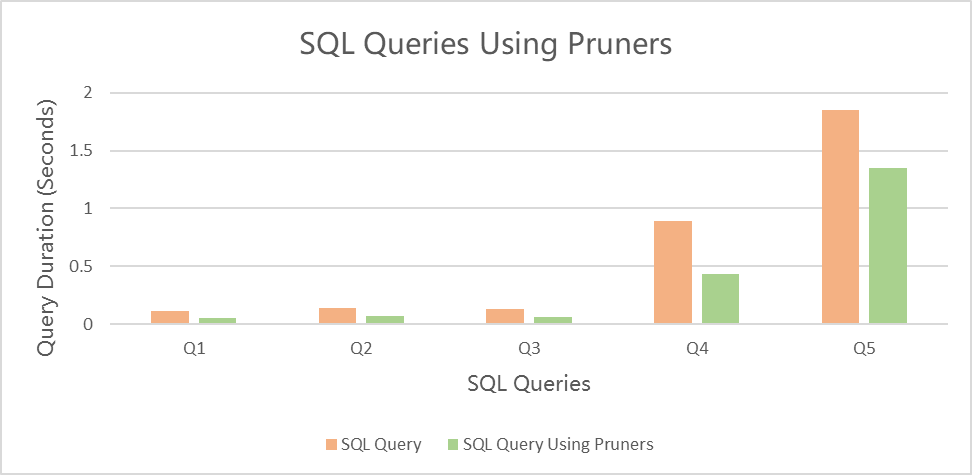
The following table compares query durations.
SQL query
Query duration (seconds)
SQL query duration (seconds)
SQL query duration using pruners (seconds)
Q1
0.11
0.05
Q2
0.14
0.07
Q3
0.13
0.06
Q4
0.89
0.43
Q5
1.85
1.35
The following figure compares query durations.
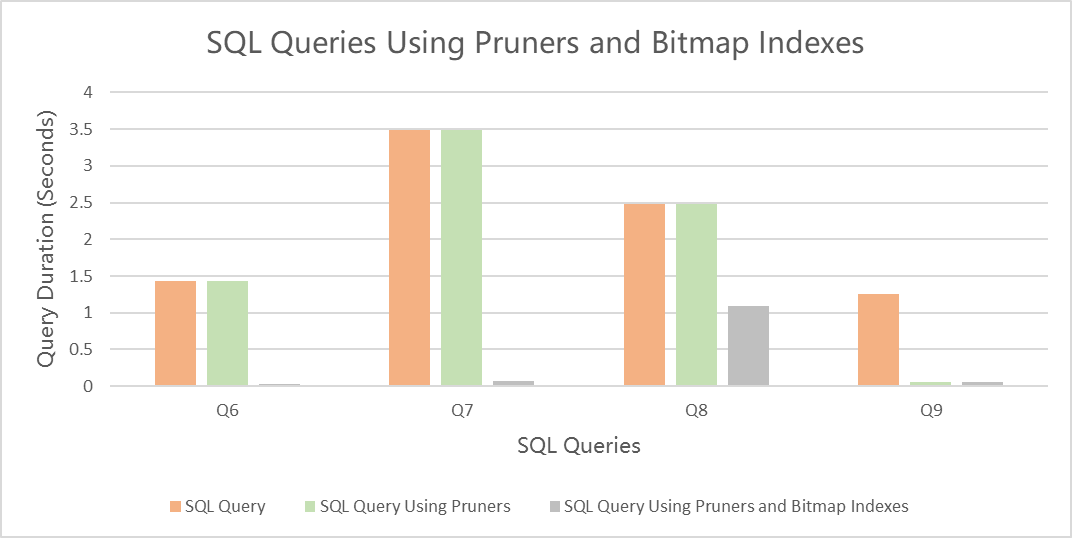
Q6 to Q9 verify the acceleration effect of bitmap indexes. The c_mktsegment column values of the customer table are evenly distributed in each data pack. Therefore, the pruners alone cannot accelerate the execution of the SQL statements. The execution of the SQL statements can be accelerated by using pruners and bitmap indexes together.
The following table compares query durations.
SQL query
Query duration (seconds)
SQL query duration (seconds)
SQL query duration using pruners (seconds)
SQL query duration using pruners and bitmap indexes (seconds)
Q6
1.43
1.43
0.03
Q7
3.49
3.49
0.07
Q8
2.48
2.48
1.09
Q9
1.25
0.05
0.05
The following figure compares query durations.