The diagnostics feature of PolarDB for MySQL integrates with specific features of Database Autonomy Service (DAS). You can use the autonomy center of DAS to enable the auto scaling feature. This topic describes how to enable the auto scaling feature.
Prerequisites
Your PolarDB for MySQL cluster must meet the following requirements:
Product edition:Enterprise Edition
Edition:Cluster Edition
No cluster specification change tasks are being performed.
A service-linked role for DAS is created. For more information, see AliyunServiceRoleForDAS role.
Billing
For information about the billing rules of this feature, see Configuration change fees.
Usage notes
The auto scaling feature of DAS does not support separate auto scale-out of the primary node and read-only nodes. After an auto scale-in or scale-down task is performed, all read-only nodes use the same specification as the primary node. Proceed with caution.
NoteIf your PolarDB cluster contains at least three nodes and uses different specifications for the primary and read-only nodes, and you enable Automatic Scale-up/out, PolarDB selects one of the following scaling methods based on the real-time read/write traffic of the cluster when the average CPU utilization of the cluster is greater than or equal to a specified threshold within an observation window:
Add read-only nodes that use the same specification as the primary node.
Add read-only nodes that use the same specification as an existing read-only node in the cluster.
NoteThis method is applicable to the scenario where the average CPU utilization of read-only nodes reaches the specified threshold.
Upgrade read-only nodes to the same specification as the primary node.
After you enable auto scaling-in, if the cluster is not in a specified quiescent period and the average CPU utilization of nodes that are automatically scaled remains at less than 30% for more than 99% of a specified scale-in observation window (the observation window plus 10 minutes), the cluster is scaled back tier-by-tier to the original specifications. The following scale-in methods may be used:
Delete the added read-only nodes.
NoteThe specifications of the remaining read-only nodes remain unchanged.
Downgrade all read-only nodes to the same specifications as the primary node.
When you scale out or in a cluster, data stored in the cluster is not affected.
During the scale-out or scale-in process, your applications are temporarily disconnected from the cluster for approximately 30 seconds. We recommend that you scale out or in your cluster during off-peak hours and make sure that your applications are configured with the automatic reconnection mechanism.
A cluster scale-out or scale-in has minor impacts on the primary node of a PolarDB cluster. However, the scale-out or scale-in degrades the performance of read-only nodes in the cluster. As a result, the read-only nodes require more time to handle requests during the scale-out or scale-in process.
Procedure
Log on to the PolarDB console. Click Clusters in the left-side navigation pane. Select a region in the upper-left corner and click the ID of the cluster in the list to go to the Basic Information page.
In the left-side navigation pane, choose .
On the page that appears, click the Autonomy Center tab.
In the upper-right corner of the Autonomy Center tab, click Autonomy Service Settings.
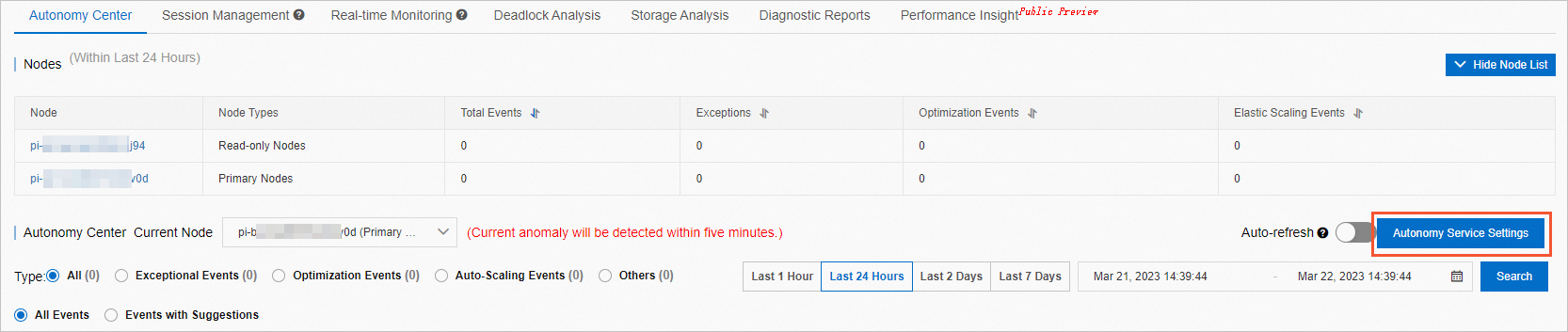
On the Autonomous Function Settings tab of the Autonomous Function Management panel, enable the autonomy service.
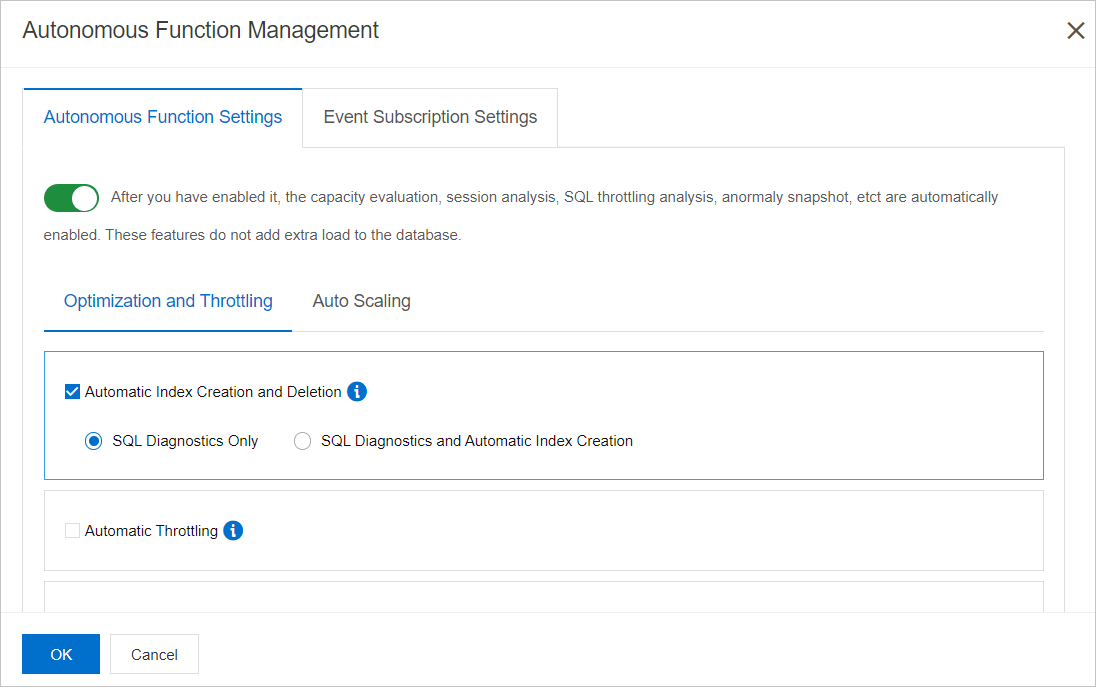
On the Optimization and Throttling tab, select Automatic Scale-up/out and Automatic Scale-down/in.
If you select Automatic Scale-up/out and the average CPU utilization is greater than or equal to the specified threshold within the observation window, the PolarDB cluster is scaled up based on loads after the observation window ends. For example, the average CPU utilization threshold is 70%, the observation window is 5 minutes, and the time required to complete a scale-out activity is 10 minutes. When the average CPU utilization of a node in the cluster exceeds 70%, an auto scaling activity is triggered. The system selects a scaling method based on the real-time read/write traffic. If the traffic surge is mainly caused by read traffic, read-only nodes are added. If the traffic surge is mainly caused by write traffic, the cluster specifications are scaled up. If the primary node is overloaded, the cluster specifications are scaled up.
After you select Automatic Scale-down/in, if the cluster is not in the quiescent period and the average CPU utilization of nodes that are automatically scaled remains at less than 30% for more than 99% of the scale-in observation window (the observation window plus 10 minutes), the cluster is scaled back tier-by-tier to the original specifications. If read-only nodes were added, they are released one by one during the cluster scale-in process. If cluster specifications were scaled up, the specifications are scaled down during the cluster scale-in process. You can scale up or down the specifications only of the entire PolarDB for MySQL cluster but not a single node in the cluster.
Configure the Automatic Scale-up/out and Automatic Scale-down/in parameters and then click OK. The following table describes the parameters that you can configure.
Parameter
Description
CPU Utilization ≥
The threshold that is used to trigger automatic scale-up. If the average CPU utilization is greater than or equal to the specified value, an auto scale-up activity is automatically triggered.
Maximum Specifications
The maximum specifications to which the cluster can be scaled out. After an automatic scaling is triggered, the system scales out your PolarDB cluster to the maximum specifications in small increments. For example, the CPU specification can be scaled up from 4 cores to 8 cores, and then to 16 cores until the upper limit is reached.
Max number of Read-Only Nodes
The maximum number of read-only nodes that can be automatically added to the cluster. After an auto scaling activity is triggered, the system adds one or two read-only nodes each time until the specified upper limit is reached.
NoteThe nodes that are automatically added are associated with the default endpoint of your cluster. If you use a custom endpoint, you must specify whether these nodes are automatically associated with the endpoint by using the Automatically Associate New Nodes parameter. For more information about how to configure the Automatically Associate New Nodes parameter, see Configure PolarProxy.
Observation Window
If the average CPU utilization is greater than or equal to the specified threshold within the observation window, PolarDB selects a scaling method based on the real-time read/write traffic after the observation window ends. For example, if the observation window is 5 minutes and the time required to complete a scaling activity is 10 minutes, you must wait 15 minutes before you can check the scaling result.
NoteThe scale-in observation window is equal to the observation window plus 10 minutes. For example, if the Observation Window parameter is set to 30 minutes, the scale-in observation window is 40 minutes.
Quiescent Period
The minimum interval between two scaling activities. During a quiescent period, PolarDB monitors the resource usage of a cluster but does not trigger scaling activities. If a quiescent period and an observation window end at the same time and the CPU utilization reaches the threshold within the observation window, PolarDB automatically triggers the auto scaling operation.