PolarDB for MySQL supports multi-zone deployment to protect against data center-level failures. By distributing data and compute resources across availability zones, you maintain business continuity during large-scale outages.
How multi-zone deployment works
An availability zone (AZ) is an independent data center within a geographic region. In a multi-zone configuration, the primary and secondary zones each store a complete, independent copy of your data (3 replicas per zone), totaling 6 data replicas. The primary zone hosts active compute nodes that serve your application traffic. The secondary zone holds standby resources that take over during a failover.
If the primary zone experiences a large-scale failure such as a power outage or network disruption, your cluster fails over to the secondary zone automatically or manually.
Failover types
-
Automatic failover : Enable the cross-zone automatic switchover feature. The system auto-promotes the secondary zone when it detects a failure in the primary zone.
-
Manual failover : Trigger a failover manually at any time. This is useful for disaster recovery drills or for moving the database closer to ECS instances in the secondary zone.
High-availability modes
PolarDB for MySQL offers four high-availability (HA) modes. Choose one based on your resilience requirements and budget.
The following figure shows the architecture of each mode.

| Mode | Architecture | Switching rules | Best for |
|---|---|---|---|
| Single-zone | All data (3 replicas) and compute nodes in one zone. | Can switch to dual-zone (storage standby) or dual-zone (storage & compute standby). | Small websites, personal learning, development and testing. |
| Dual-zone with storage standby | Data distributed across two zones; primary and secondary zones each store a complete copy (6 total replicas). Compute nodes exist only in the primary zone. | Can only switch to dual-zone (storage & compute standby). | More than 80% of use cases across Internet, IoT, online retailing, logistics, and gaming. |
| Dual-zone with storage & compute standby | Same data distribution as storage standby, plus a matching set of compute nodes in the secondary zone. By default, the number and specifications of compute nodes in the secondary zone match those in the primary zone. | Can only switch to dual-zone (storage standby). | Large and medium-sized enterprises: financial institutions, online retailers, automobile enterprises, education enterprises, and ERP providers. |
| Three-zone | One primary, one secondary, and one logger node. Uses physical replication combined with the X-Paxos protocol for cross-zone strong consistency. Recovery Time Objective (RTO) is less than 60 seconds. Recovery Point Objective (RPO) = 0 (zero data loss). | Cannot switch to other HA modes. | Large and medium-sized enterprises: financial institutions, online retailers, automobile enterprises, education enterprises, and ERP providers. |
Single-zone
All data (3 replicas) and compute nodes reside in a single zone. This is the lowest-cost option, but recovery takes longer during a full zone failure.

Use cases:
-
Small websites and applications : Offload routine O&M tasks to Alibaba Cloud and focus on application development.
-
Personal learning : Get started with PolarDB using the Standard Edition for testing and learning.
-
Development and testing : Provision clusters quickly and scale your database as requirements change.
Dual-zone with storage standby
Data is distributed across two zones. The primary and secondary zones each store a complete copy of data, maintaining a high Service Level Agreement (SLA). Compute nodes are deployed only in the primary zone. The hot standby storage cluster in the secondary zone takes over when the primary zone fails.

Use cases: Suitable for more than 80% of use cases across industries such as Internet, IoT, online retailing, logistics, and gaming.
Dual-zone with storage & compute standby
Data is distributed across two zones with the same redundancy as storage standby. The secondary zone also contains a matching set of compute nodes. By default, the number and specifications of compute nodes in the secondary zone are the same as those in the primary zone. After a failover, the secondary zone provides sufficient read-only nodes to prevent service degradation.

Use cases: Large and medium-sized enterprises whose production databases handle many read requests during peak hours or perform intelligent data analysis. These include financial institutions, online retailers, automobile enterprises, education enterprises, and ERP service providers.
Three-zone
Uses a three-node architecture with one primary, one secondary, and one logger node for cross-zone strong consistency. Physical replication is combined with the X-Paxos protocol for higher disaster recovery capabilities than semi-synchronous and asynchronous methods.
When the primary zone fails, failover between the primary and secondary zones completes with a Recovery Time Objective (RTO) of less than 60 seconds and a Recovery Point Objective (RPO) of 0 (zero data loss).

Use cases: Large and medium-sized enterprises whose production databases handle many read requests during peak hours or perform intelligent data analysis. These include financial institutions, online retailers, automobile enterprises, education enterprises, and ERP service providers.
Billing
Storage and compute costs vary by mode.
| Mode | Compute billing | Storage billing |
|---|---|---|
| Single-zone | Common compute node charges. | 3 data replicas. Lowest storage cost. |
| Dual-zone with storage standby | Common compute node charges (primary zone only). | 6 data replicas (3 per zone). Storage costs higher than single-zone. |
| Dual-zone with storage & compute standby | Compute nodes in the secondary zone are charged separately. By default, their number and specifications match the primary zone. | 6 data replicas (3 per zone). Storage costs higher than single-zone. |
| Three-zone | Secondary nodes and logger nodes are free of charge. Primary nodes and read-only nodes are charged as common compute nodes. | 6 data replicas (3 per zone). Storage costs higher than single-zone. |
For detailed pricing, see Billing .
Limitations
-
The cluster's region must have at least two zones with available PolarDB resources.
-
The secondary zone must have sufficient computing resources.
-
Multi-zone deployment is unavailable in the following regions: China (Qingdao), China (Hohhot), China (Chengdu), South Korea (Seoul), Philippines (Manila), and Thailand (Bangkok).
Configure a high-availability mode
Set the HA mode when you create a cluster or change it on an existing cluster.
Set the HA mode during cluster creation
When purchasing a cluster, select the high-availability mode in the Network And Zone section.
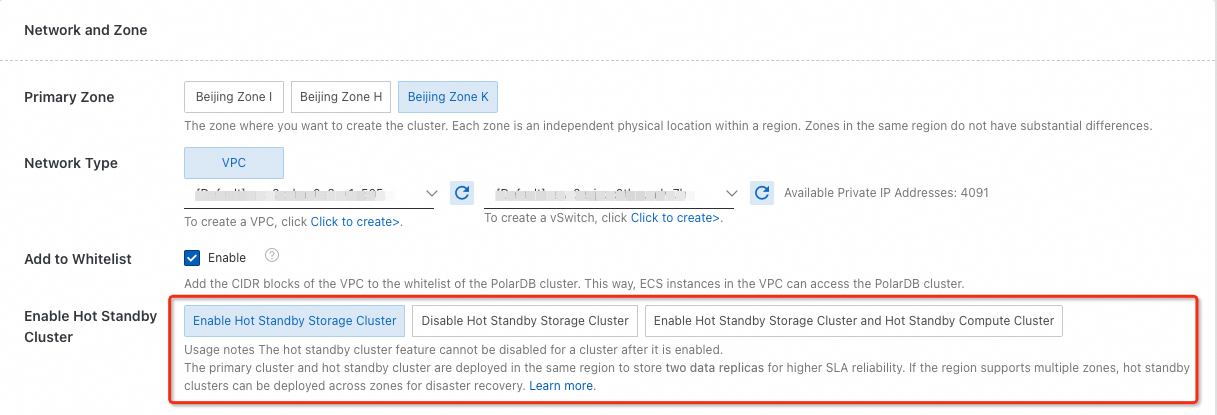
Change the HA mode on an existing cluster
Use one of the following methods:
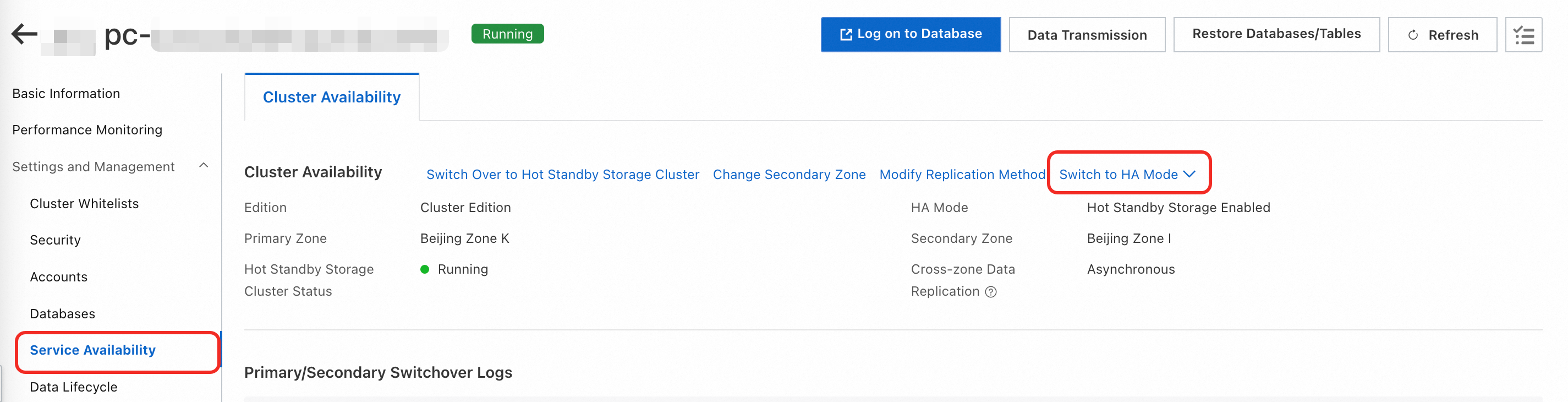
Method 1 : Go to the page. Click the cluster. In the Distributed Storage section of the Basic Information page, click Switch To HA Mode .

Method 2 : Go to the page. Click the cluster. Choose . On the Cluster Availability tab, click Switch To HA Mode .
FAQ
How do I check if the hot standby storage cluster is enabled?
Use either the console or the API.
Console
-
Log in to the PolarDB console .
-
In the left-side navigation pane, click Clusters .
-
Select the region where your cluster is located, and then click the target cluster ID to open the cluster details page.
-
View the Distributed Storage section at the bottom of the page.

API
-
Call the
DescribeDBClusterAttributeAPI to retrieve the cluster attributes. -
Check the
HotStandbyClusterparameter in the response:-
StandbyClusterON: Storage hot standby is enabled, or storage hot standby and standby compute nodes are enabled. -
StandbyClusterOFF: The cluster is in single-AZ mode.
-