EasyVision of Platform for AI (PAI) allows you to train models for end-to-end text recognition and use the trained models to make predictions. This topic describes how to use PAI commands to train a model for end-to-end text recognition.
EasyVision simplifies the training configuration. You can use the -Dparam_config parameter to set common parameters. This way, you do not need to know the rules or logic of the configuration files of EasyVision. If you need advanced parameters to train a model for end-to-end text recognition, you can use the -Dconfig parameter to pass the configuration file to EasyVision. The following figure shows the algorithm framework of the models for end-to-end text recognition.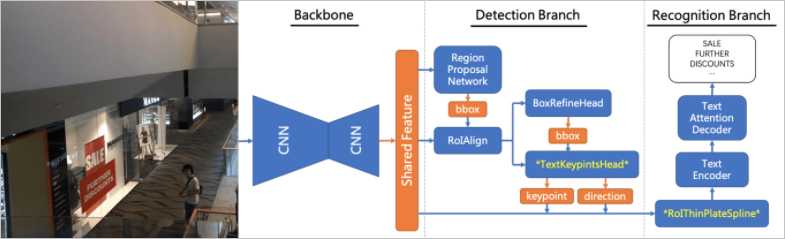
Training of end-to-end text recognition
pai -name easy_vision_ext
-Dbuckets='oss://{bucket_name}.{oss_host}/{path}'
-Darn='acs:ram::*********:role/aliyunodpspaidefaultrole'
-DgpuRequired=100
-Dcmd train
-Dparam_config '
--model_type TextEnd2End
--backbone resnet_v1_50
--num_classes 1
--use_pretrained_model true
--train_batch_size 1
--test_batch_size 1
--image_min_sizes 960
--image_max_sizes 1440
--initial_learning_rate 0.0001
--optimizer adam
--lr_type exponential_decay
--decay_epochs 40
--decay_factor 0.5
--num_epochs 10
--staircase true
--predict_text_direction true
--text_direction_trainable true
--text_direction_type smart_unified
--feature_gather_type fixed_height_pyramid
--train_data oss://pai-vision-data-sh/data/recipt_text/end2end_tfrecords/train_*.tfrecord
--test_data oss://pai-vision-data-sh/data/recipt_text/end2end_tfrecords/test.tfrecord
--model_dir oss://pai-vision-data-sh/test/recipt_text/text_end2end_krcnn_resnet50_attn
'Parameters
Parameter | Required | Description | Value format or example value | Default value |
buckets | Yes | The endpoint of the Object Storage Service (OSS) bucket. | oss://{bucket_name}.{oss_host}/{path} | N/A |
arn | Yes | The Alibaba Cloud Resource Name (ARN) of the RAM role that has the permissions to access OSS resources. For more information about how to obtain the ARN, see the "I/O parameters" section of the Parameters of PAI-TensorFlow tasks topic. | acs:ram::*:role/aliyunodpspaidefaultrole | N/A |
cluster | No | The configuration of parameters that are used for distributed training. | JSON string | "" |
gpuRequired | No | Specifies whether to use GPUs. Each worker uses one GPU by default. If you set this parameter to 200, each worker uses two GPUs. | 100 | 100 |
cmd | Yes | The type of the EasyVision task. Set this parameter to train when you train a model. | train | N/A |
param_config | Yes | The configuration of parameters that are used for model training. The format of the param_config parameter is the same as that of the ArgumentParser() object in Python. For more information, see param_config. | STRING | N/A |
param_config
The param_config parameter contains several parameters that are used for model training. The format of the param_config parameter is the same as that of the ArgumentParser() object in Python. The following example shows the configuration of the param_config parameter:
-Dparam_config = '
--backbone resnet_v1_50
--model_dir oss://your/bucket/exp_dir
'The values of all string parameters in the param_config parameter are not enclosed in double quotation marks (") or single quotation marks (').
Parameter | Required | Description | Value format or example value | Default value |
model_type | Yes | The type of the model to train. Set this parameter to TextEnd2End when you train a model for end-to-end text recognition. | STRING | N/A |
backbone | Yes | The name of the backbone network that is used by the model. Valid values:
| STRING | N/A |
weight_decay | No | The value of L2 regularization. | FLOAT | 1e-4 |
num_classes | No | The number of categories. By default, the value is obtained by analyzing the dataset that is used for the training. | 21 | -1 |
anchor_scales | No | The size of the anchor box. The size of the anchor box is the same as that of the input image where the anchor box resides after the image is resized. Set this parameter to the size of the anchor box in the layer that has the highest resolution. The total number of layers is five. The size of the anchor box in a layer is twice as that in the previous layer. For example, if the size of the anchor box in the first layer is 32, the sizes of the anchor boxes in the next four layers are 64, 128, 256, and 512. | FLOAT list. Example value: 32 (single scale). | 24 |
anchor_ratios | No | The ratios of the width to the height of the anchor boxes. | FLOAT list | 0.2 0.5 1 2 5 |
predict_text_direction | No | Specifies whether to predict the text orientation. | BOOL | false |
text_direction_trainable | No | Specifies whether to train the model to predict the text orientation. | BOOL | false |
text_direction_type | No | The type of the prediction of text orientation. Valid values:
| STRING | normal |
feature_gather_type | No | The type of the extractor that is used to extract features of the text lines. Valid values:
| STRING | fixed_height |
feature_gather_aspect_ratio | No | The ratio of the width to the height of the text lines. If you set feature_gather_type to fixed_size, this parameter specifies the ratio of the specified height to width after the features are resized. If you set feature_gather_type to fixed_height, this parameter specifies the maximum ratio of the specified height to the custom width after the features are resized. | FLOAT | 40 |
feature_gather_batch_size | No | The size of the current batch of the text lines that are used to train the model. | INT | 160 |
recognition_norm_type | No | The type of the normalization that is used by the encoder and feature extractor. Valid values:
| STRING | group_norm |
recognition_bn_trainable | No | Specifies whether the batch normalization value that is obtained by the encoder and feature extractor can be used for the training. This parameter takes effect only when norm_type is set to batch_norm. | BOOL | false |
encoder_type | No | The type of the encoder. Valid values:
| STRING | crnn |
encoder_cnn_name | No | The type of CNN that is used by the encoder. Valid values:
| STRING | senet5_encoder |
encoder_num_layers | No | The number of layers in the encoder, which refers to RNN layers. CNN layers are not counted. | INT | 2 |
encoder_rnn_type | No | The type of RNN that is used by the encoder. Valid values:
| STRING | uni |
encoder_hidden_size | No | The number of neurons in the hidden layer of the encoder. | INT | 512 |
encoder_cell_type | No | The type of RNN cells in the encoder. Valid values:
| STRING | basic_lstm |
decoder_type | No | The type of the decoder. Valid values:
| STRING | attention |
decoder_num_layers | No | The number of layers in the decoder. | INT | 2 |
decoder_hidden_size | No | The number of neurons in the hidden layer of the decoder. | INT | 512 |
decoder_cell_type | No | The type of RNN cells in the decoder. Valid values:
| STRING | basic_lstm |
embedding_size | No | The embedding size of the dictionary. | INT | 64 |
beam_width | No | The beam width of the beam search. | INT | 0 |
length_penalty_weight | No | The length penalty score of the beam search. This prevents shorter sentences from receiving higher scores. | FLOAT | 0.0 |
attention_mechanism | No | The type of the attention mechanism of the decoder. Valid values:
| STRING | normed_bahdanau |
aspect_ratio_min_jitter_coef | No | The minimum ratio of the width to the height at which images can be resized during the training. The value 0 indicates that the ratios of the width to the height of images remain unchanged during the training. | FLOAT | 0.8 |
aspect_ratio_max_jitter_coef | No | The maximum ratio of the width to the height at which images can be resized during the training. The value 0 indicates that the ratios of the width to the height of images remain unchanged during the training. | FLOAT | 1.2 |
random_rotation_angle | No | The maximum angle to which images can be randomly rotated during the training, in the clockwise or anticlockwise direction. The value 0 indicates that images are not randomly rotated during the training. | FLOAT | 10 |
random_crop_min_area | No | The minimum ratio of the size of an image after it is randomly cropped to the size of the original image. The value 0 indicates that images are not randomly cropped during the training. | FLOAT | 0.1 |
random_crop_max_area | No | The maximum ratio of the size of an image after it is randomly cropped to the size of the original image. The value 0 indicates that images are not randomly cropped during the training. | FLOAT | 1.0 |
random_crop_min_aspect_ratio | No | The minimum ratio of the width to the height of images after they are randomly cropped during the training. The value 0 indicates that images are not randomly cropped during the training. | FLOAT | 0.2 |
random_crop_max_aspect_ratio | No | The maximum ratio of the width to the height of images after they are randomly cropped during the training. The value 0 indicates that images are not randomly cropped during the training. | FLOAT | 5 |
image_min_sizes | No | The length of the shorter side of images after they are resized. If you specify multiple lengths for the shorter sides of the images in the value of this parameter, the last one is used to evaluate the model, whereas one of the others is randomly selected to train the model. This way, the multi-scale training is supported. If you set only one length for the shorter sides of images, this length is used for both training and evaluation. | FLOAT list | 800 |
image_max_sizes | No | The length of the longer side of images after they are resized. If you specify multiple lengths for the longer sides of the images in the value of this parameter, the last one is used to evaluate the model, whereas one of the others is randomly selected to train the model. This way, the multi-scale training is supported. If you set only one length for the longer sides of images, this length is used for both training and evaluation. | FLOAT list | 1200 |
random_distort_color | No | Specifies whether to randomly change the brightness, contrast, and saturation of images during the training. | BOOL | true |
optimizer | No | The type of the optimizer. Valid values:
| STRING | momentum |
lr_type | No | The policy that is used to adjust the learning rate. Valid values:
| STRING | exponential_decay |
initial_learning_rate | No | The initial learning rate. | FLOAT | 0.01 |
decay_epochs | No | If you set the lr_type parameter to exponential_decay, the decay_epochs parameter is equivalent to the decay_steps parameter of tf.train.exponential.decay. In this case, the decay_epochs parameter specifies the epoch interval at which you want to adjust the learning rate. The system automatically converts the value of the decay_epochs parameter to the value of the decay_steps parameter based on the total number of training data entries. Typically, you can set the decay_epochs parameter to half of the total number of epochs. For example, you can set this parameter to 10 if the total number of epochs is 20. If you set the lr_type parameter to manual_step, the decay_epochs parameter specifies the epochs for which you want to adjust the learning rates. For example, the value 16 18 indicates that you want to adjust the learning rates for the 16th and 18th epochs. Typically, if the total number of epochs is N, you can set the two values of the decay_epochs parameter to 8/10 × N and 9/10 × N. | INTEGER list. Example value: 20 20 40 60. | 20 |
decay_factor | No | The decay rate. This parameter is equivalent to the decay_rate parameter of tf.train.exponential.decay. | FLOAT | 0.95 |
staircase | No | Specifies whether the learning rate changes based on the decay_epochs parameter. This parameter is equivalent to the staircase parameter of tf.train.exponential.decay. | BOOL | true |
power | No | The power of the polynomial. This parameter is equivalent to the power parameter of tf.train.polynomial.decay. | FLOAT | 0.9 |
learning_rates | No | The learning rates that you want to set for the specified epochs. This parameter is required when you set the lr_type parameter to manual_step. If you want to adjust the learning rates for two epochs, set two learning rates in the value. For example, if the decay_epoches parameter is set to 20 40, you must specify two learning rates in the learning_rates parameter, such as 0.001 0.0001. This indicates that the learning rate of the 20th epoch is adjusted to 0.001 and the learning rate of the 40th epoch is adjusted to 0.0001. We recommend that you adjust the learning rates to one tenth, one hundredth, and one thousandth of the initial learning rate in sequence. | FLOAT list | N/A |
lr_warmup | No | Specifies whether to warm up the learning rate. | BOOL | false |
lr_warm_up_epochs | No | The number of epochs for which you want to warm up the learning rate. | FLOAT | 1 |
train_data | Yes | The OSS endpoint of the data that is used to train the model. | oss://path/to/train_*.tfrecord | N/A |
test_data | Yes | The OSS endpoint of the data that is evaluated during the training. | oss://path/to/test_*.tfrecord | N/A |
train_batch_size | Yes | The size of the data that is used to train the model in the current batch. | INT. Example value: 32. | N/A |
test_batch_size | Yes | The size of the data that is evaluated in the current batch. | INT. Example value: 32. | N/A |
train_num_readers | No | The number of concurrent threads that are used to read the training data. | INT | 4 |
model_dir | Yes | The OSS endpoint of the model. | oss://path/to/model | N/A |
pretrained_model | No | The OSS endpoint of the pretrained model. If this parameter is specified, the actual model is finetuned based on the pretrained model. | oss://pai-vision-data-sh/pretrained_models/inception_v4.ckpt | "" |
use_pretrained_model | No | Specifies whether to use a pretrained model. | BOOL | true |
num_epochs | Yes | The number of training iterations. The value 1 indicates that all data is iterated once for the training. | INT. Example value: 40. | N/A |
num_test_example | No | The number of data entries that are evaluated during the training. The value -1 indicates that all training data is evaluated. | INT. Example value: 2000. | -1 |
num_visualizations | No | The number of data entries that can be visualized during the evaluation. | INT | 10 |
save_checkpoint_epochs | No | The epoch interval at which a checkpoint is saved. The value 1 indicates that a checkpoint is saved each time an epoch is complete. | INT | 1 |
save_summary_epochs | No | The epoch interval at which a summary is saved. The value of 0.01 indicates that a summary is saved each time 1% of the training data is iterated. | FLOAT | 0.01 |
num_train_images | No | The total number of data entries that are used for the training. This parameter is required if you use custom TFRecord files to train the model. | INT | 0 |
label_map_path | No | The category mapping file. This parameter is required if you use custom TFRecord files to train the model. | STRING | "" |