Swing Recommendation is a component provided by Swing to predict upstream batch data. You can use the Swing Recommendation component to perform offline prediction in Platform for AI (PAI) based on the model and prediction data generated by the Swing Train component. This topic describes the parameter configuration of the Swing Recommendation component.
Limits
The supported compute engines are MaxCompute and Realtime Compute for Apache Flink.
Configure the component
You can configure the component by using one of the following methods:
Method 1: Configure the component in the PAI console
Configure the Swing Recommendation component on the pipeline page of Machine Learning Designer. The following table describes the parameters.
Tab | Parameter | Description |
Fields Setting | itemCol | The name of the item column. |
initRecommCol | The name of the initially recommended item column. | |
reservedCols | The names of the reserved columns of the algorithm. | |
Parameters Setting | recommCol | The name of the recommendation result column. |
k | The number of top recommended items. Default value: 10. | |
numThreads | The number of threads of the component. Default value: 1. | |
Execute Tuning | Number of Workers | The number of worker nodes. The value must be a positive integer. This parameter must be used together with the Memory per worker parameter. Valid values: 1 to 9999. |
Memory per worker | The memory size of each worker node. Unit: MB. The value must be a positive integer. Valid values: 1024 to 65536 (64 × 1024). |
Method 2: Configure the component by using Python code
You can use the PyAlink script component to call Python code. For more information, see PyAlink Script. The following table describes the parameters.
Parameter | Required | Description | Default value |
itemCol | Yes | The name of the item column. | N/A |
recommCol | Yes | The name of the recommendation result column. | N/A |
initRecommCol | No | The name of the initially recommended item column. | N/A |
k | No | The number of top recommended items. | 10 |
reservedCols | No | The names of the reserved columns of the algorithm. | N/A |
numThreads | No | The number of threads of the component. | 1 |
Sample Python code:
df_data = pd.DataFrame([
["a1", "11L", 2.2],
["a1", "12L", 2.0],
["a2", "11L", 2.0],
["a2", "12L", 2.0],
["a3", "12L", 2.0],
["a3", "13L", 2.0],
["a4", "13L", 2.0],
["a4", "14L", 2.0],
["a5", "14L", 2.0],
["a5", "15L", 2.0],
["a6", "15L", 2.0],
["a6", "16L", 2.0],
])
data = BatchOperator.fromDataframe(df_data, schemaStr='user string, item string, rating double')
model = SwingTrainBatchOp()\
.setUserCol("user")\
.setItemCol("item")\
.setMinUserItems(1)\
.linkFrom(data)
predictor = SwingRecommBatchOp()\
.setItemCol("item")\
.setRecommCol("prediction_result")
predictor.linkFrom(model, data).print()Examples
The following figure shows a sample pipeline in which the Swing Recommendation component is used. 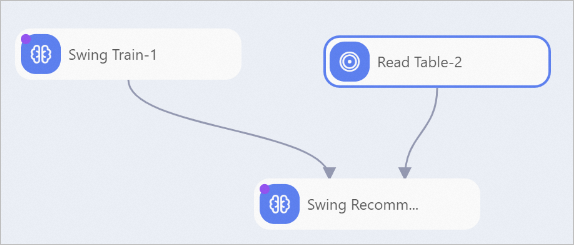 In this example, the following steps are performed to configure the components in the preceding figure:
In this example, the following steps are performed to configure the components in the preceding figure:
Use the Read Table-1 component to read the test dataset. Set the Table Name parameter of the Read Table-1 component to the name of the table that stores the test dataset. For information about how to obtain the name of the table, see the "Examples" section in the Swing Train topic.
Use the Swing Train component to train the model.
Import the test dataset and the model to the Swing Recommendation component and configure the component parameters. For more information, see the "Method 1: Configure the component in the PAI console" section of this topic.