This topic describes the Prediction component provided by Machine Learning Designer. If your model is trained by using a traditional data mining component that does not have a paired prediction component, and you want to use the model to generate predictions, you can choose the Prediction component in most cases. The component uses the trained model and prediction data as input and generates the prediction results.
Configure the component
You can configure the component by using one of the following methods:
Method 1: Configure the component in Machine Learning Designer
Configure the component on the pipeline configuration tab of Machine Learning Designer in the Machine Learning Platform for AI console.
Tab | Parameter | Description |
Fields Setting | Feature Columns | The feature columns that are selected from the input table for prediction. By default, all columns in the input table are selected. |
Reserved Columns | The columns that you want to reserve in the output table. We recommend that you add a label column to facilitate evaluation. | |
Output Result Column | The result column in the output table. | |
Output Score Column | The score column in the output table. | |
Output Detail Column | The details column in the output table. | |
Sparse Matrix | Specifies whether the input data is sparse. Sparse data is presented by using key-value pairs. | |
KV Delimiter | The delimiter that is used to separate keys and values. By default, colons (:) are used. | |
KV Pair Delimiter | The delimiter that is used to separate key-value pairs. By default, commas (,) are used. | |
Tuning | Cores | The number of cores. This parameter must be used together with the Memory Size per Core parameter. The value of this parameter must be a positive integer. |
Memory Size per Core | The memory size of each core. This parameter must be used with the Cores parameter. Unit: MB. |
Method 2: Run Machine Learning Platform for AI commands
Configure the component parameters by using a Machine Learning Platform for AI command. You can use the SQL Script component to run Machine Learning Platform for AI commands. For more information, see SQL Script. The following table describes the parameters used in the command.
pai -name prediction
-DmodelName=nb_model
-DinputTableName=wpbc
-DoutputTableName=wpbc_pred
-DappendColNames=label;Parameter | Required | Description | Default value |
inputTableName | Yes | The name of the input table. | None |
featureColNames | No | The feature columns that are selected from the input table for prediction. Separate multiple columns with commas (,). | All columns |
appendColNames | No | The prediction columns that are selected from the input table and appended to the output table. | None |
inputTablePartitions | No | The partitions that are selected from the input table for training. The following formats are supported:
Note If you specify multiple partitions, separate them with commas (,). | Full table |
outputTablePartition | No | The partitions whose results are contained in the output table. | None |
resultColName | No | The column in the output table that contains the prediction results with the highest probabilities among all possible results. | prediction_result |
scoreColName | No | The column in the output table that contains the highest probabilities of the prediction results. | prediction_score |
detailColName | No | The details column in the output table that contains all possible results and their probabilities. | prediction_detail |
enableSparse | No | Specifies whether the input data is sparse. Valid values: true and false. | false |
itemDelimiter | No | The delimiter that is used to separate sparse key-value pairs. | , |
kvDelimiter | No | The delimiter that is used to separate sparse keys and values. | : |
modelName | Yes | The name of the input clustering model. | None |
outputTableName | Yes | The name of the output table. | None |
lifecycle | No | The lifecycle of the output table. | None |
coreNum | No | The number of cores. | Automatically allocated |
memSizePerCore | No | The memory size of each core. Unit: MB. | Automatically allocated |
Example
Execute the following SQL statements to generate test data:
create table pai_rf_test_input as select * from ( select 1 as f0,2 as f1, "good" as class union all select 1 as f0,3 as f1, "good" as class union all select 1 as f0,4 as f1, "bad" as class union all select 0 as f0,3 as f1, "good" as class union all select 0 as f0,4 as f1, "bad" as class )tmp;Run the following command to build a model. The random forest algorithm is used in this example.
PAI -name randomforests -project algo_public -DinputTableName="pai_rf_test_input" -DmodelName="pai_rf_test_model" -DforceCategorical="f1" -DlabelColName="class" -DfeatureColNames="f0,f1" -DmaxRecordSize="100000" -DminNumPer="0" -DminNumObj="2" -DtreeNum="3";Run the following command to submit the parameters configured for the Prediction component:
PAI -name prediction -project algo_public -DinputTableName=pai_rf_test_input -DmodelName=pai_rf_test_model -DresultColName=prediction_result -DscoreColName=prediction_score -DdetailColName=prediction_detail -DoutputTableName=pai_temp_2283_76333_1View the output result table pai_temp_2283_76333_1, as shown in the following figure.
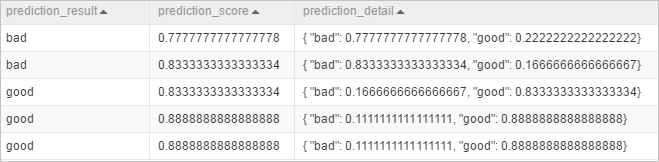
prediction_result: the column that contains the prediction results with the highest probabilities among all possible results.
prediction_score: the column that contains the probabilities of the prediction results.
In this example, the prediction result can be good or bad, depending on whose probability is higher. The prediction_score column contains the highest probabilities.
prediction_detail: the column that contains all possible results and their probabilities.