Machine Learning Designer supports batch prediction. You can use models to implement periodic batch prediction on datasets in business scenarios that do not require real-time results. This topic describes how to implement batch prediction on Machine Learning Designer.
Implement batch prediction in the development environment
Designer provides a variety of prediction components to support different algorithms and scenarios. You can directly drag and drop these components on the canvas.
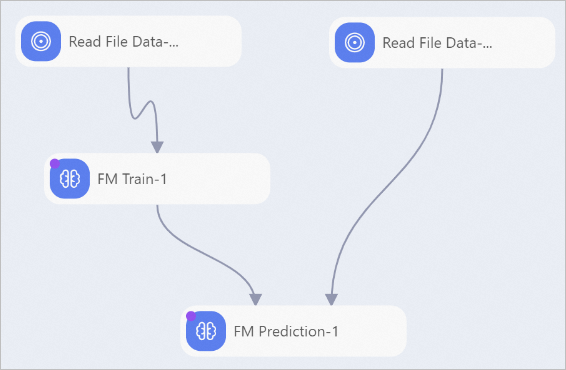
You can directly use the paired model training and prediction components (such as FM algorithm) displayed in the left-side component pane to train a model and then use the model to implement batch prediction.
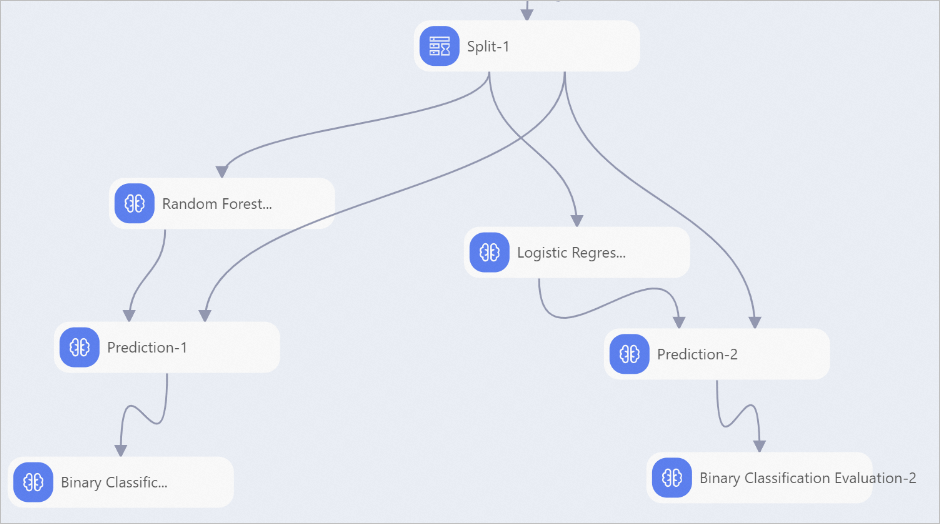
If no prediction component is available for the algorithm that you want to use, you can use the general-purpose prediction component to implement batch prediction after you train the model.
 Important
ImportantThe general-purpose prediction component supports only OfflineModel models. It does not support Predictive Model Markup Language (PMML) models.
If an existing model is available, you can also use a component to import the model and prediction data. Then, connect a prediction component as the downstream node of the component to implement prediction and deployment.
Periodically schedule a batch prediction pipeline
After the batch prediction pipeline pass the test, you can submit the pipeline to DataWorks and schedule it periodically.
synchronize the model that is trained offline to the production environment.
If your workspace is in DataWorks standard mode, the development environment and production environment maintain MaxCompute data separately. Therefore, before you periodically schedule an offline prediction workflow, you need to synchronize the model that is trained offline to the production environment.
Use the Model Export and Import MaxCompute Offline Model components (recommended)
Use the Model Export component to export the trained OfflineModel model to Object Storage Service (OSS), and then use the Import MaxCompute Offline Model component in the periodically scheduled pipeline to import the model from OSS.
Use the Copy MaxCompute Offline Model and Read MaxCompute Offline Model components
NoteYou need to use the workspace administrator account or production account to perform the replicate operation. For more information, see Permissions.
Use the Copy MaxCompute Offline Model component to replicate the trained OfflineModel model to the production environment, and then use the Read MaxCompute Offline Model component in the periodically scheduled pipeline to read the model in the production environment.
Use DataWorks tasks to schedule pipelines in Machine Learning Designer.
References
If the offline prediction results meet your expectations, you can deploy the model as an EAS online service or package the offline data processing pipeline and deploy the pipeline as an EAS online service.