You can use global variables to reduce the workload of repetitive parameter configurations in online pipelines and DataWorks offline scheduling pipelines. For online pipelines, global variables allow multiple components to share the same parameters. For DataWorks offline scheduling, global variables are used to replace timed scheduling parameters, thereby enhancing the flexibility and efficiency of the pipeline.
How to use
Configure global variables.
Enter a created pipeline, click on the blank area of the canvas. Then, click Add Global Variable on the right side of the interface.
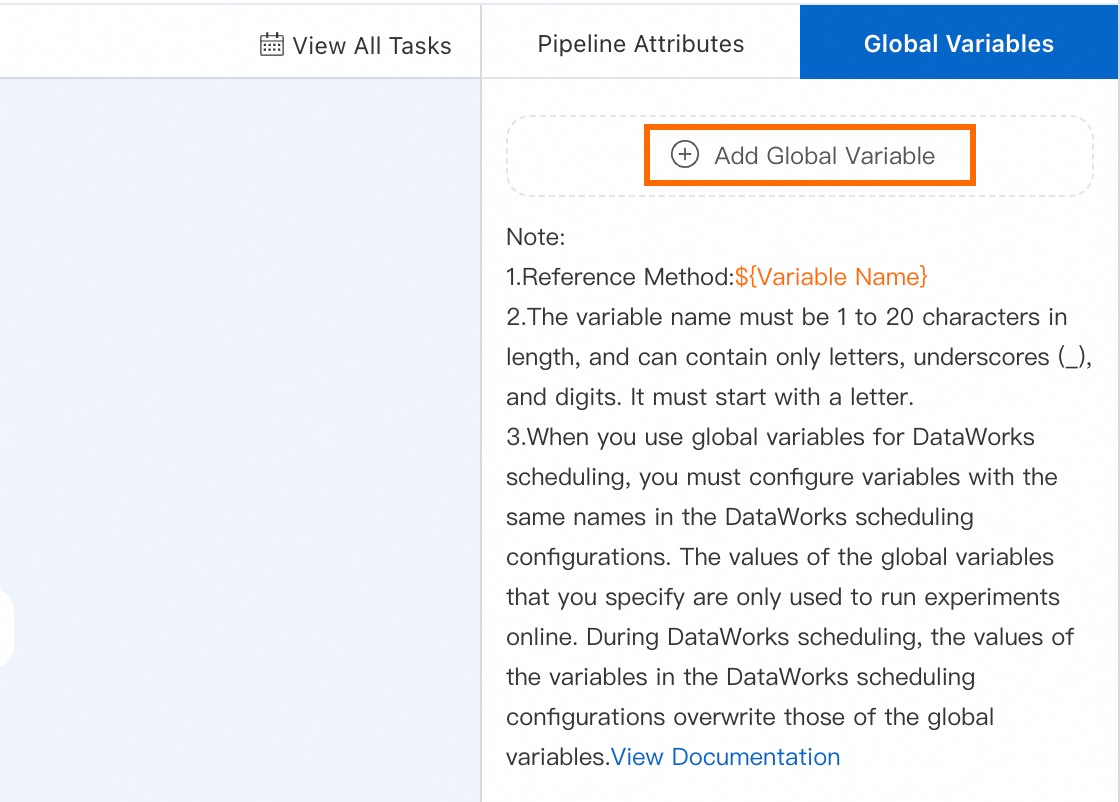
Enter
${variableName}where the variable is needed to reference the variable.
Example 1: Use global variables in online pipelines
This example uses a global variable para1 to change the column name status to ifHealth, and references the variable in the SQL script.
This example creates a pipeline based on the preset template "Heart Disease Prediction". Then, retain only the first two nodes and delete the others.
Click on the blank area of the canvas, and create a new global variable on the right side of the page.
Set Variable Name to
para1, and Variable Value toifHealth.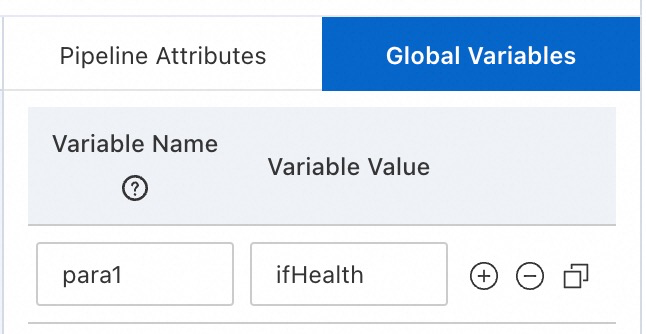
Use the global variable.
Modify the SQL component by referencing the variable
${para1}.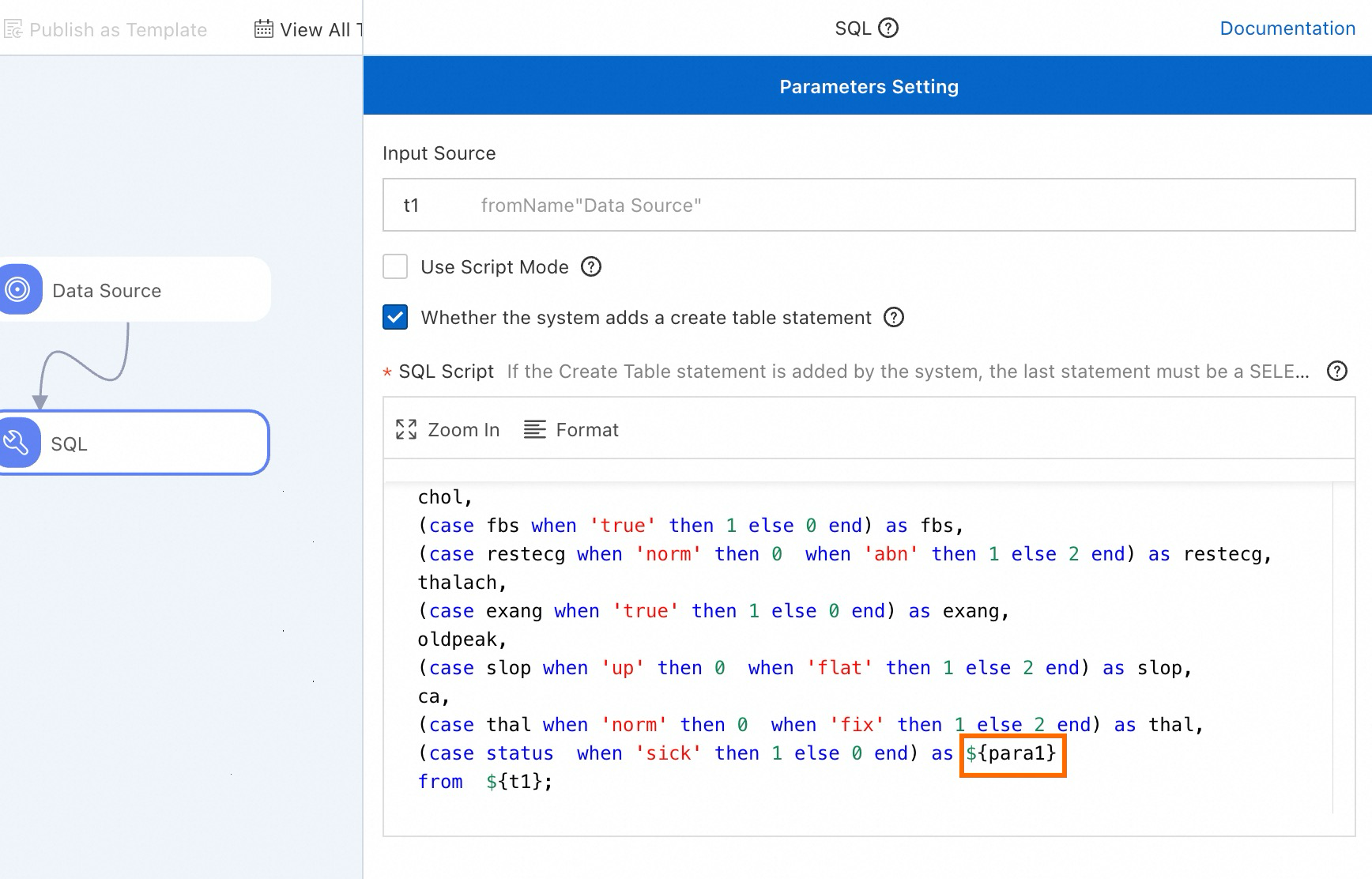
Run the pipeline.
After the run is complete, right-click the SQL component, select View Data > SQL Script Output Port. You can see that the column name
statushas been changed toifHealth.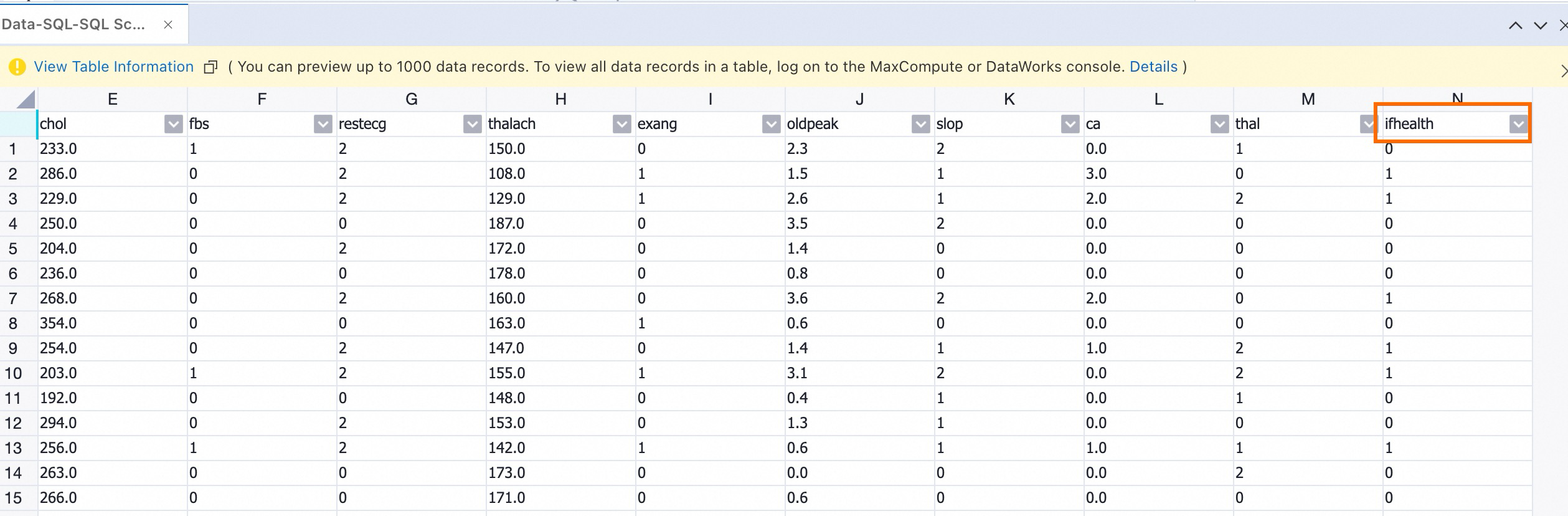
Example 2: Use global variables in DataWorks offline scheduling pipelines
This example uses a global variable gDate to associate the timed scheduling pipeline with a date, and then sets a scheduling parameter with the same name on DataWorks for scheduling.
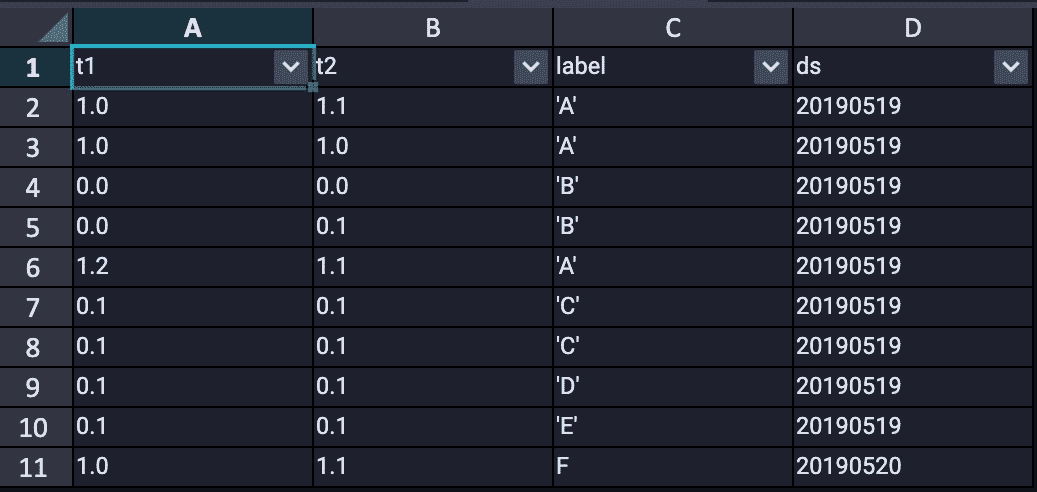
Create a test data table.
This example creates a table named dwtest on the MaxCompute console (see the table below). For more information, see SQL References.
Create a pipeline and configure global variables.
Click on the blank area of the canvas, and create a new global variable
gDateon the right side of the page.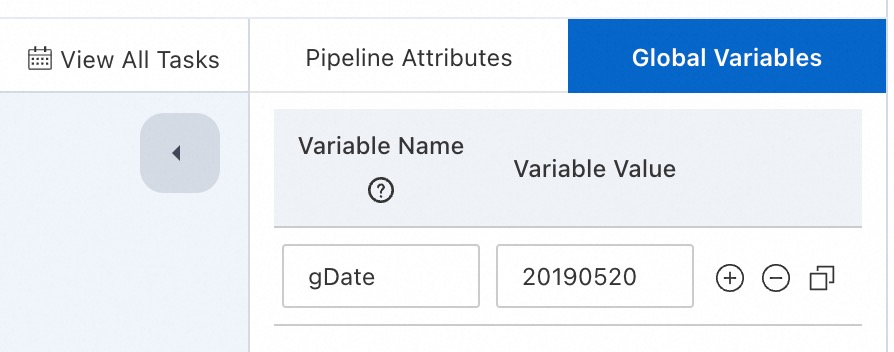
Configure pipeline components.

Read Table: Set Table Name to dwtest.
SQL Script: Reference the global variable
gDatein the SQL script.select * from ${t1} where ds=${gDate}
Run the pipeline.
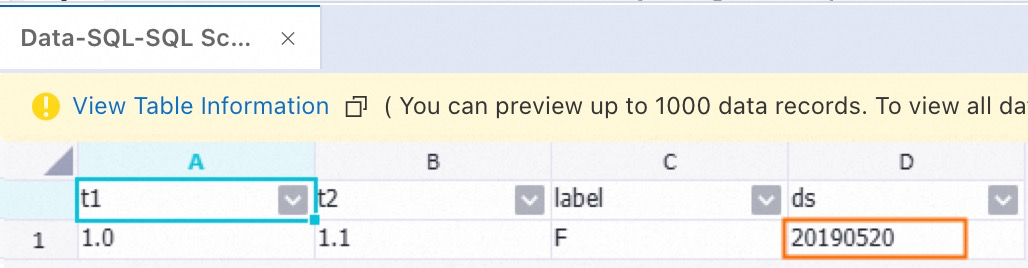
After the run is complete, right-click the SQL Script component, select View Data > SQL Script Output Port. You can see the data corresponding to the global variable gDate.
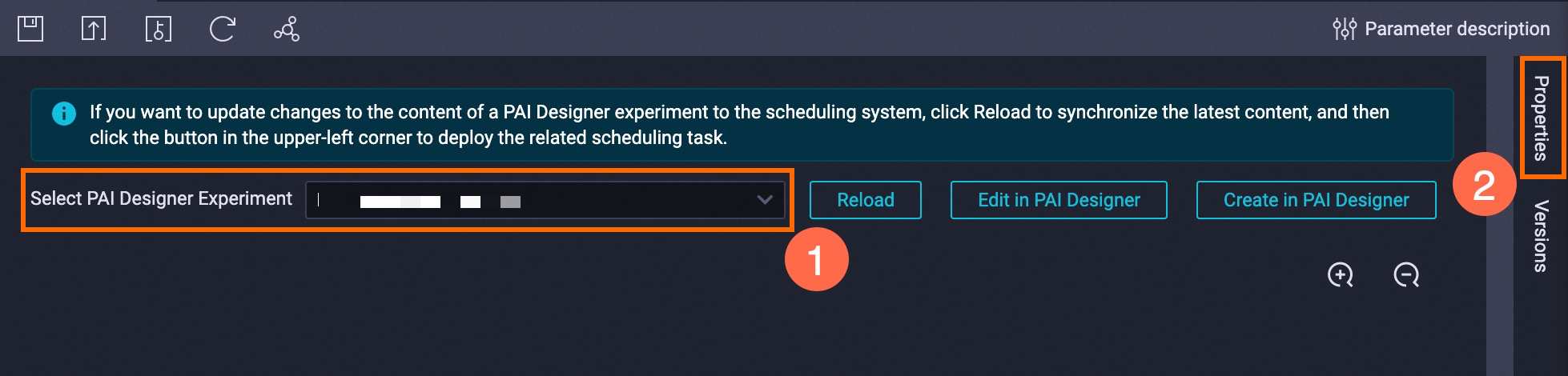
Click Periodic Scheduling to the upper left corner of the canvas, then click Create Scheduling Node to jump to DataWorks. In the Create Node dialog box, enter a name and click Confirm.
Select PAI Designer Experiment, then click Properties on the right side of the screen. For more information, see Task scheduling configuration.
Configure the following parameters for this example, with the rest remaining as default:
Scheduling Parameter: Add a new scheduling parameter with the same name
gDate, with a value of$bizdate.
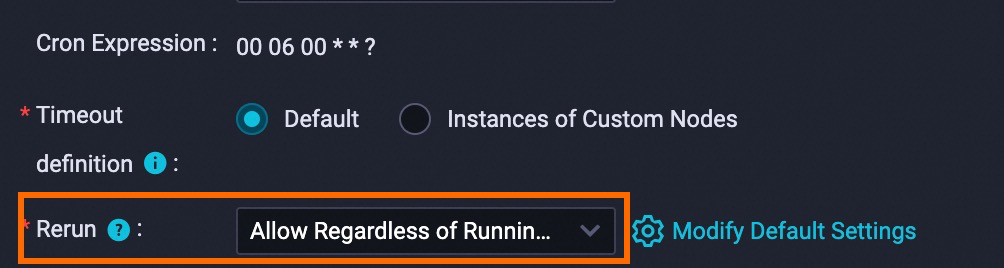
Schedule: Set Rerun to Allow Regardless of Running Status.
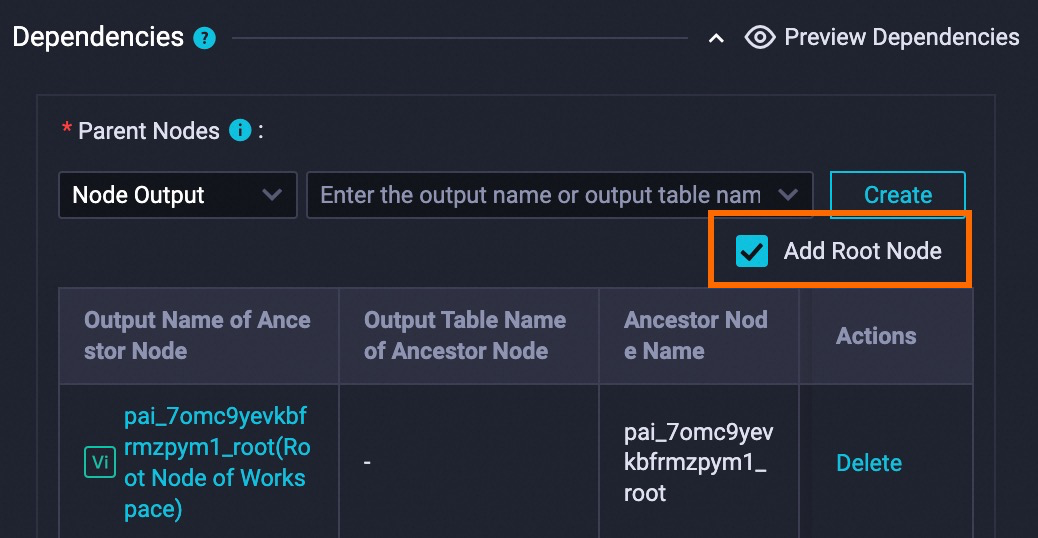
Dependencies: Select Add Root Node.
Click the
 and icons in the toolbar to save and submit the node.
and icons in the toolbar to save and submit the node.Click Operation Center at the top of the page to view the running status and operation log of the machine learning task.
You can also directly perform operations such as data backfill and pipeline trial runs, see View and manage auto triggered tasks.