To deploy model services more cost-effectively, Elastic Algorithm Service (EAS) offers GPU slicing. This feature partitions a physical GPU's computing power and memory, sharing them among service instances to improve GPU utilization and reduce deployment costs.
Prerequisites
GPU slicing requires an EAS resource groups or Lingjun resources.
Configure GPU slicing
You can configure GPU slicing through the PAI console or the eascmd client when creating or updating a service.
Use the console
Log on to the PAI console. Select a region on the top of the page. Then, select the desired workspace and click Elastic Algorithm Service (EAS).
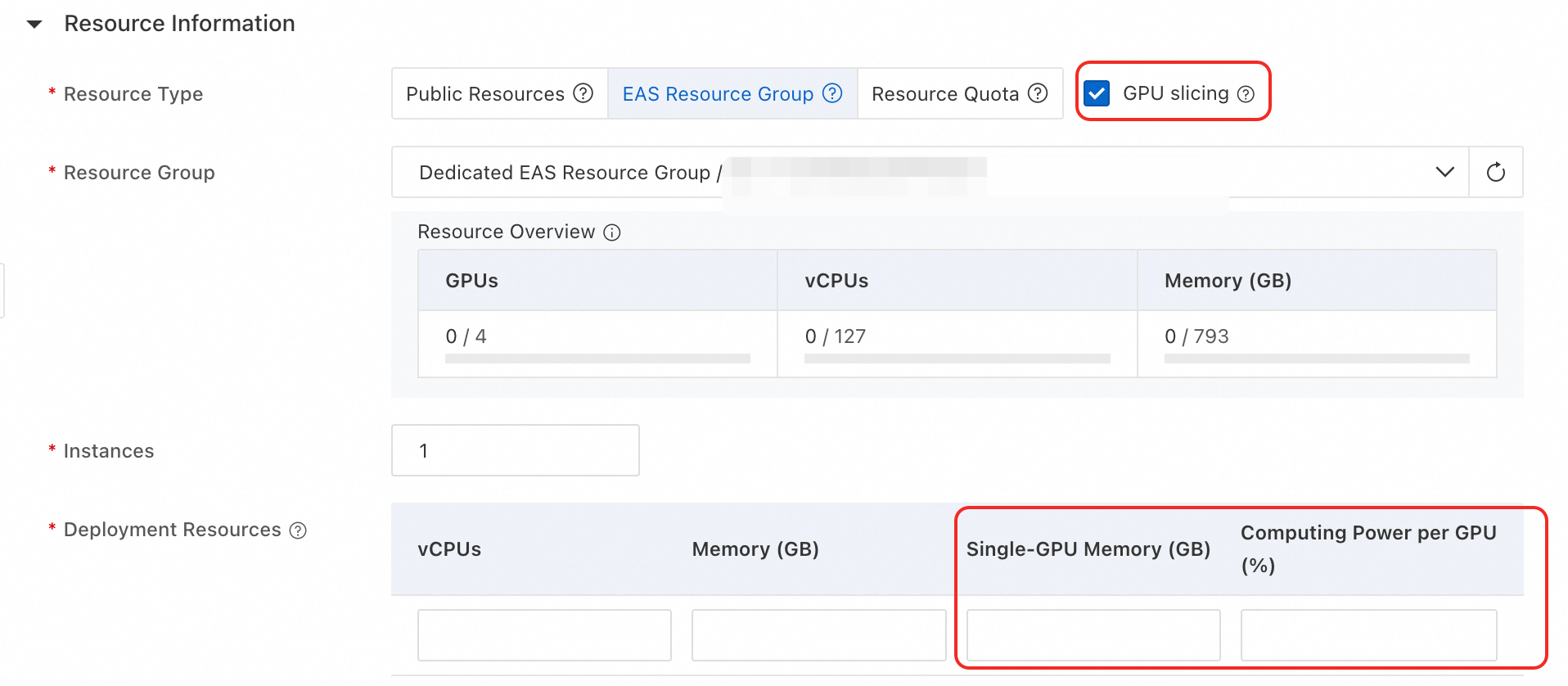
Create a new service or update an existing one to open the service configuration page.
In the Resource Information section, configure the following key parameters. For more information about other parameters, see Custom deployment.
Parameter
Description
Resource Type
Select EAS Resource Group or Resource Quota.
GPU Slicing
Select this checkbox to enable GPU slicing.
NoteThe GPU Slicing option appears only when you select an EAS dedicated resource group, a virtual resource group, or Lingjun resources.
Deployment Resources
Single-GPU Memory (GB): Required. The GPU memory required per instance on a single GPU, specified as an integer. The system supports memory-based scheduling for instances, enabling instances to share a single GPU.
ImportantFor resource specifications that start with
ml, the unit is GB. For those that start withecs, the unit is GiB.Computing Power per GPU (%): Optional. The percentage of GPU computing power required for each instance on a single GPU, specified as an integer from 1 to 100. The system supports computing power-based scheduling for instances, enabling instances to share a single GPU.
The system allocates resources only when both the Single-GPU Memory (GB) and Computing Power per GPU (%) requirements are met. For example, if you set GPU memory to 48 GB and the computing power percentage to 10%, an instance can use a maximum of 48 GB of GPU memory and 10% of the computing power.
After you configure the parameters, click Deploy or Update.
Use a local client
The following JSON example shows the configuration for GPU slicing:
{ "metadata": { "gpu_core_percentage": 5, "gpu_memory": 20 } }gpu_memory: Corresponds to Single-GPU Memory (GB) in the console.
gpu_core_percentage: Corresponds to Computing Power per GPU (%) in the PAI console. To use the
gpu_core_percentageparameter, you must also specify thegpu_memoryparameter. Otherwise, this parameter is ignored.
ImportantTo use memory-based scheduling, leave the gpu field unset or set it to 0. If the gpu field is set to 1, it means the instance exclusively uses the entire GPU card. In this case, the gpu_memory and gpu_core_percentage fields are ignored.
For more information, see the Command reference. Use the
createormodifycommand to create a service or update its configuration.