This topic describes how to use graph algorithms to manage financial risks.
Background information
Graph algorithms are used in relationship analysis scenarios. Graph algorithms arrange data into a relationship graph that contains connections between vertices. The connections are represented as edges. Machine Learning Platform for AI (PAI) provides several graph algorithm components, including K-Core, Maximum Connected Subgraph, and Label Propagation Classification.
The following figure provides an example on the relationship graph of an interlinked group of people. The arrows in the figure represent the relationships between these people, such as colleagues or relatives. In this graph, Enoch is a trusted customer and Evan is a fraudster. Based on this information and the relationship graph, you can use graph algorithms to calculate the credit index of each person, that is, the probability of the person being a fraudster. 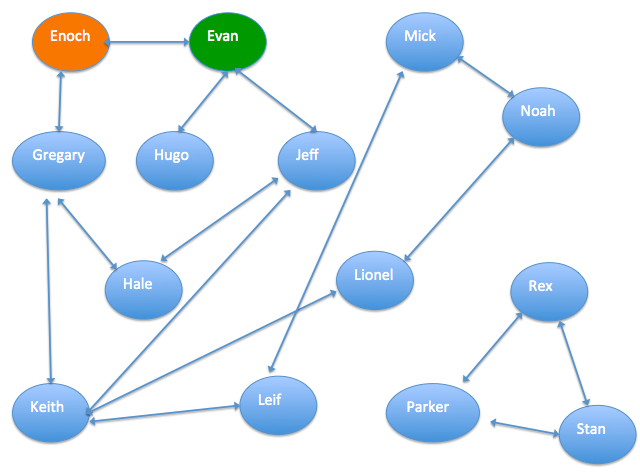
Datasets
The following table describes the fields in the dataset that is used in this topic.
Field | Meaning | Type | Description |
start_point | Start vertex of an edge | STRING | The name of a person. |
end_point | End vertex of an edge | STRING | The name of a person. |
count | Closeness | DOUBLE | The closeness between two persons. A greater value indicates a closer relationship between the two persons. |
The following figure shows the sample data that is used in the pipeline. 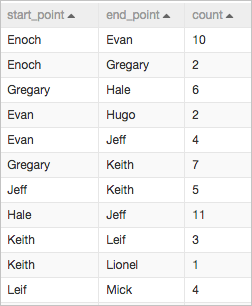
Procedure
Go to the Machine Learning Designer page.
Log on to the PAI console.
In the left-side navigation pane, click Workspaces. On the Workspaces page, click the name of the workspace that you want to manage.
In the left-side navigation pane, choose .
Create a pipeline.
On the Visualized Modeling (Designer) page, click the Preset Templates tab.
On this tab, find the Financial Risk Management template and click Create.
In the Create Pipeline dialog box, configure the following parameters. You can use their default values.
The value specified for the Data Storage parameter is the Object Storage Service (OSS) bucket path of the temporary data and models generated during the runtime of the pipeline.
Click OK.
It requires about 10 seconds to create the pipeline.
On the Pipelines tab, double-click the Financial Risk Management pipeline to open the pipeline.
View the components of the pipeline on the canvas, as shown in the following figure. The system automatically creates the pipeline based on the built-in template.
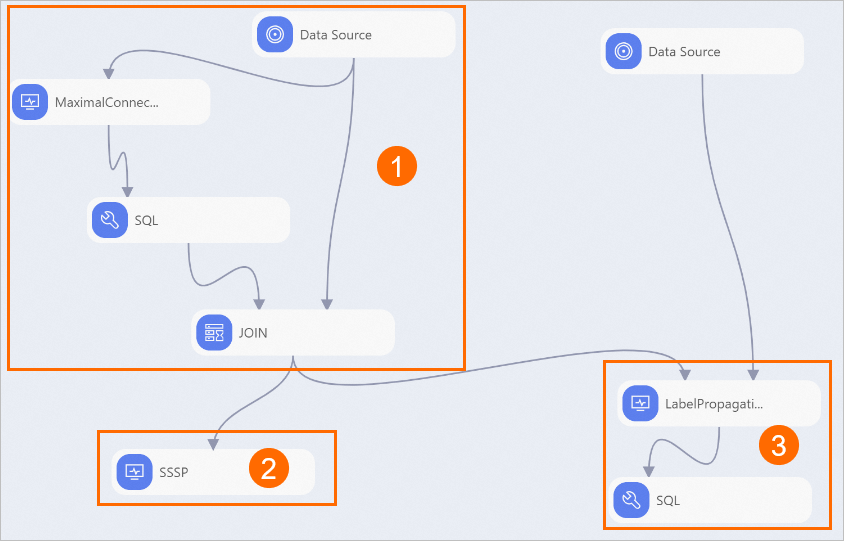
Section
Description
①
The Maximum Connected Subgraph component classifies the people in the relationship graph into two groups, and assigns an ID to each group. Then, the SQL Script and JOIN components remove unrelated people in the relationship graph.
The Maximum Connected Subgraph component can find the set that contains the largest number of interlinked people to remove unrelated people, as shown in the following figure.
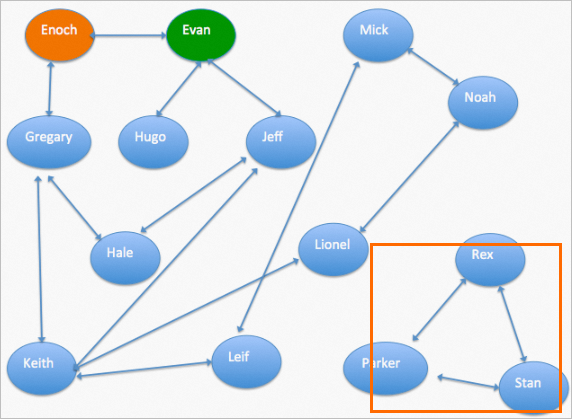
②
The component displayed in this section explores the distance between two vertices. In the output of the Single-source Shortest Path component, the distance field indicates the number of people that Enoch must contact to reach the desired people, as shown in the following figure.
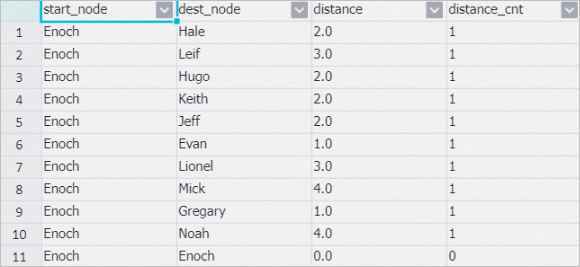
③
The Data Source component imports the labeled data. The weight field indicates the probability of a person being a fraudster. Then, the Label Propagation Classification component predicts the labels of unlabeled vertices. Finally, the SQL Script component filters results and shows the probability of each person being a fraudster.
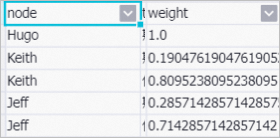
Label propagation classification is a semi-supervised classification algorithm. It uses a relationship graph and labeled data as its input and predicts the labels of unlabeled vertices based on the labels of labeled ones. Label propagation classification propagates the label of each vertex to the vertices next to the vertex.
Run the pipeline and view the results.
In the upper-left corner of the canvas, click
 .
. After the pipeline is run, right-click SQL on the canvas and select View Data. On the tab that appears, view the probability of each person being a fraudster.