You can use the Recommended Solutions - Rank to train a ranking model based on the user feature table, item feature table, and user behavior table processed by feature engineering, and deploy the ranking model as an online service. This topic describes how to implement ranking.
Prerequisites
A feature engineering workflow is run and the datasets for ranking are generated. For more information, see Feature engineering.
rec_sln_demo_user_table_preprocess_all_feature_v2
rec_sln_demo_item_table_preprocess_all_feature_v2
rec_sln_demo_behavior_table_preprocess_v2
Instructions
Go to the Visualized Modeling (Designer) page.
Log on to the Machine Learning Platform for AI (PAI) console.
In the left-side navigation pane, click Workspaces. On the Workspaces page, click the name of the workspace that you want to manage.
In the left-side navigation pane, choose Model Training > Visualized Modeling (Designer). The Visualized Modeling (Machine Learning Designer) page appears.
Create a pipeline.
On the Visualized Modeling (Designer) page, click the Preset Templates tab.
In the template list, click Create in the Recommended Solutions - Rank section.
In the Create Pipeline dialog box, set the following parameters. You can use their default values.
The Data Storage uses the same OSS Bucket path as feature engineering to store temporary data and model files generated during workflow execution.
Click OK. It takes about 10 seconds to create the pipeline.
View the components of the pipeline on the canvas, as shown in the following figure. The system automatically creates the pipeline based on the preset template.
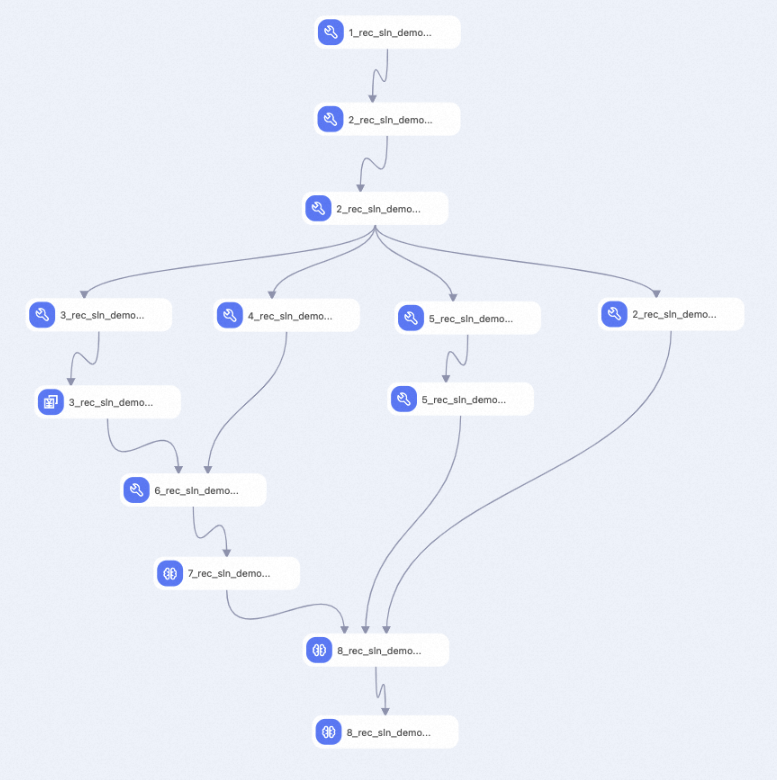
Component number
Description
1
The sample model.
2
Processes the sample model using feature generation (FG) based on the fg.json file.
3
Uses equal frequency binning of numeric feature to set the boundaries of the model.
4
Uses the number of unique values of the enumeration feature to set the embedding_dim and hash_bucket_size of the model.
5
Discretizes the 30-day sample data of the rec_sln_demo_sorting model to generate training samples.
6
Summarizes the results of the rec_sln_demo_rec_sln_demo_sorting_30d_binning_v2 table and the rec_sln_demo_rec_sln_demo_sorting_30d_count_v2 table to calculate the feature configuration information and step configuration information.
7
Specifies the EasyRec configuration file based on the calculation result of the component 6.
NoteYou need to run this component only once.
8
You need to run the component 7 to generate the EasyRec configuration file before model training.