This topic describes how to implement public opinion risk management based on the reviews from a takeaway platform.
Background information
Many merchants use online platforms to receive product feedback from consumers. Consumer feedback includes positive and negative feedback, that is, praises and criticisms. Merchants can learn whether their product quality meets consumer needs based on consumer feedback. Merchants can obtain the consumer opinion trend by analyzing consumer review content and use the trend as a guide for product research and development.
A large number of reviews are submitted on the online review platforms every day. Traditionally, merchants manually collect public opinion. This method is inefficient and fails to accurately collect statistics on public opinion if the data volume is large. Therefore, merchants need an approach to automatically collect statistics on public opinion to determine the public opinion trend. Machine Learning Platform for AI (PAI) provides a set of algorithms that are developed based on text vectorization and classification. These algorithms can create a classification model based on positive and negative reviews with historical labels. You can use the model to automatically predict the trend of new reviews. The overall modeling framework, which is developed based on 11,987 labeled reviews from a takeaway platform, is preset in Machine Learning Designer. The framework implements automatic risk management of positive and negative public opinion with an accuracy of about 75%.
You can use the pipeline template that is preset in Machine Learning Designer to develop a solution for public opinion risk management within one to two days. Then, you can use the solution to analyze a large number of reviews at a time. The prediction accuracy of the model is proportional to the number of reviews. This solution is applicable to text analysis such as spam classification and classification of positive and negative opinions on news.
Datasets
The pipeline described in this topic is based on masked real data that is collected from a takeaway platform. The following table describes the fields in the data.
Field | Data type | Description |
label | DOUBLE | Indicates whether the review is positive or negative. Valid values:
|
review | STRING | The review content. |
Implement public opinion risk management based on the reviews from a takeaway platform
Go to the Machine Learning Designer page.
Log on to the PAI console.
In the left-side navigation pane, click Workspaces. On the Workspaces page, click the name of the workspace that you want to manage.
In the left-side navigation pane, choose .
Create a pipeline.
On the Visualized Modeling (Designer) page, click the Preset Templates tab.
On this tab, find the Public Opinion Risk Control Based on Takeaway Reviews template and click Create.
In the Create Pipeline dialog box, configure the parameters. You can use their default values.
The value specified for the Data Storage parameter is the Object Storage Service (OSS) bucket path of the temporary data and models generated during the runtime of the pipeline.
Click OK.
It requires about 10 seconds to create the pipeline.
On the Pipelines tab, double-click the Public Opinion Risk Control Based on Takeaway Reviews pipeline to open the pipeline.
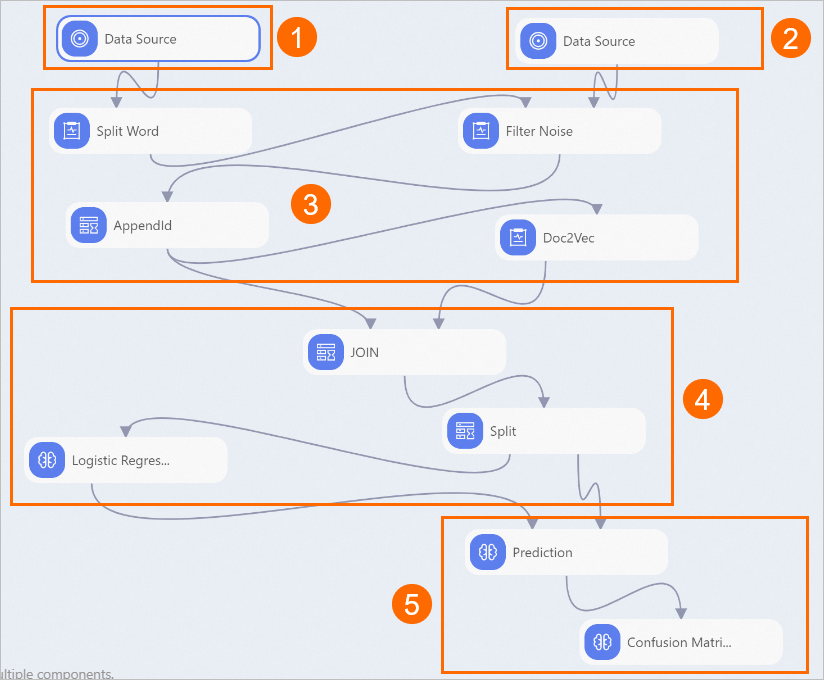
View the components of the pipeline on the canvas, as shown in the following figure. The system automatically creates the pipeline based on the built-in template.
Section
Description
①
The component displayed in this section imports the review data.
②
The component displayed in this section imports the stopwords. Stopwords include auxiliary verbs and punctuation marks. You must manually upload a stopword table, as shown in the following figure.

③
The components displayed in this section vectorize the text. The Doc2Vec-1 component uses the Doc2Vec algorithm to convert each review to a semantic vector. Each row represents a vector, and each vector represents the meaning of a review. After the pipeline is run, right-click Doc2Vec on the canvas and choose . On the tab that appears, view the text vector table.
④
The components displayed in this section generate a binary classification model. The Split-1 component uses a splitting algorithm to split the vectorized text into a training dataset and a prediction dataset. Then, the Logistic Regression for Binary Classification-1 component uses the logistic regression algorithm to train a binary classification model based on the training dataset. The model can determine whether a review is positive or negative.
⑤
The components displayed in this section use a confusion matrix to evaluate the quality of the model.
Run the pipeline and view the results.
In the upper-left corner of the canvas, click
 .
. Right-click Confusion Matrix on the canvas and click Visual Analysis.
In the Confusion Matrix section, click the Statistics tab and view the model statistics.