Build a haze prediction model using one year of Beijing weather data to identify pollutants with greatest impact on PM 2.5 levels.
Dataset
This experiment uses hourly air quality data from Beijing in 2016. Field descriptions appear in the following table.
|
Field name |
Type |
Description |
|
time |
STRING |
Date, accurate to day. |
|
hour |
STRING |
Hour of data collection. |
|
pm2 |
STRING |
PM 2.5 index. |
|
pm10 |
STRING |
PM 10 index. |
|
so2 |
STRING |
Sulfur dioxide index. |
|
co |
STRING |
Carbon monoxide index. |
|
no2 |
STRING |
Nitrogen dioxide index. |
Haze prediction
-
Go to the Machine Learning Designer page.
-
Log on to the PAI console.
-
In the left-side navigation pane, click Workspaces. On the Workspaces page, click the name of the workspace that you want to manage.
-
In the left-side navigation pane, choose .
-
-
Build the workflow.
On the Designer page, click the Preset Template tab.
-
In the Haze Prediction section in the template list, click Create.
In the New Workflow dialog box, configure the parameters. You can use the default values.
The Workflow Data Storage is set to an OSS bucket path to store temporary data and models generated when the workflow is running.
Click OK.
The workflow is created in about 10 seconds.
-
In the workflow list, double-click the Haze Prediction workflow.
-
The workflow builds automatically based on the preset template, as shown in the following figure.
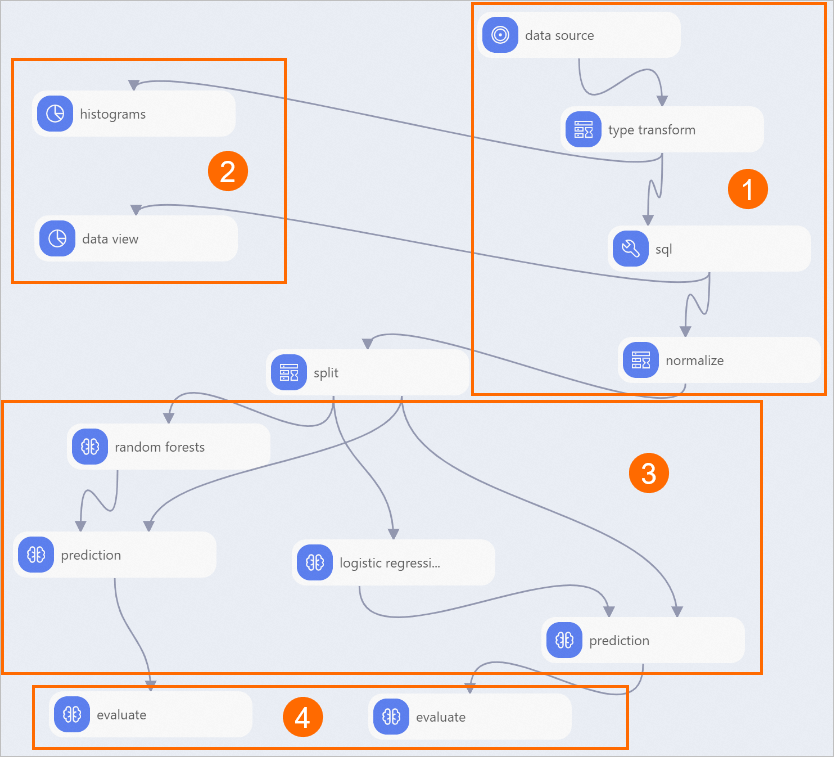
Area
Description
①
Data import and preprocessing:
-
Read Table component imports data source.
-
Type Transform component converts data from STRING type to DOUBLE type.
-
SQL Script component converts target column to binary type (0 and 1). In this experiment, pm2 column is the target. Values greater than 200 indicate severe haze and receive value 1; otherwise 0. SQL statement:
select time,hour,(case when pm2>200 then 1 else 0 end),pm10,so2,co,no2 from ${t1}; -
Normalization component unifies units across different pollutant indicators, removing dimensional differences.
②
Statistical analysis:
-
Histogram component visualizes distribution of each pollutant.
For PM2.5, most frequent value range is 11.74 to 15.61, with 430 occurrences, as shown in the following figure.
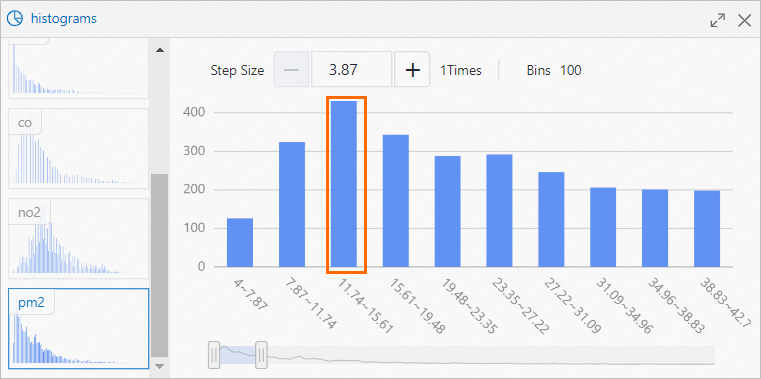
-
Data View component visualizes impact of different pollutant intervals on results.
For no2, the interval 112.33 to 113.9 produced 7 targets with value 0 and 9 targets with value 1, as shown in the following figure. When no2 value falls within 112.33 to 113.9, severe haze probability is high. Entropy and Gini quantify this feature interval's impact on target value in information theory terms. Larger values indicate greater impact.
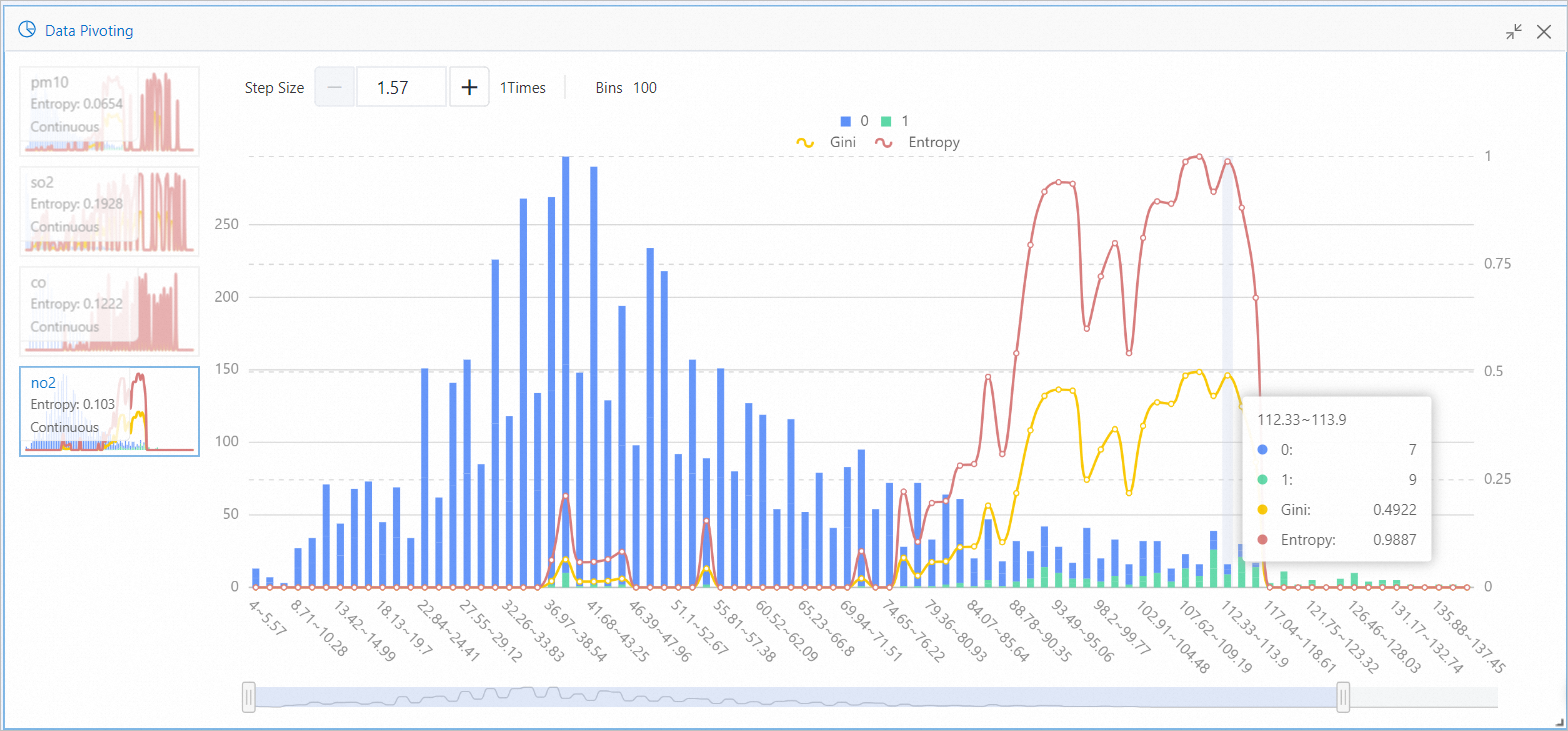
③
Model training and prediction. This experiment uses Random Forest and Binary Logistic Regression components to train models.
④
Model evaluation.
-
-
Run workflow and view model performance.
-
Click Run button
 above the canvas.
above the canvas. -
When workflow completes, right-click Binary Classification Evaluation component downstream of Random Forest component on the canvas. Select Visual Analytics from shortcut menu.
-
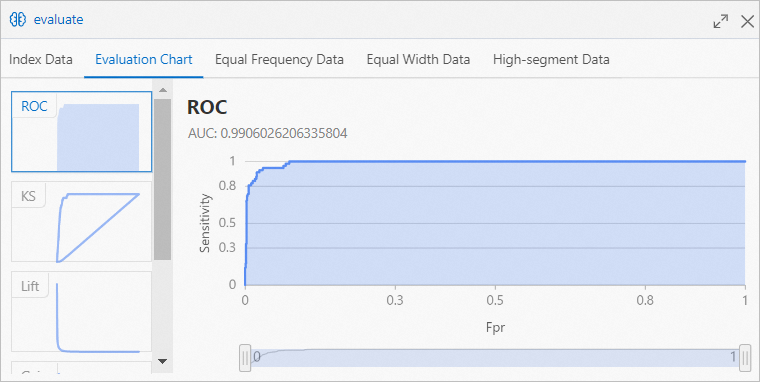
Click Evaluation Chart tab in Binary Classification Evaluation dialog box to view prediction performance of model trained by Random Forest component.
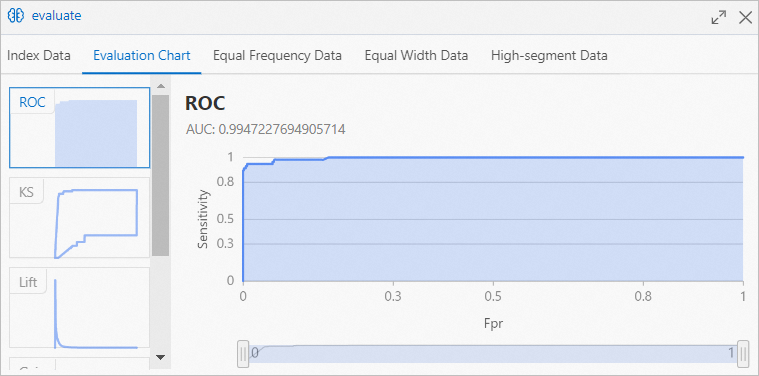 Area Under the Curve (AUC) value indicates over 99% accuracy for haze prediction model trained by Random Forest component.
Area Under the Curve (AUC) value indicates over 99% accuracy for haze prediction model trained by Random Forest component. -
On canvas, right-click Binary Classification Evaluation component downstream of Binary Logistic Regression component. Select Visual Analytics from shortcut menu.
-
In Binary Classification Evaluation dialog box, click Evaluation Chart tab to view prediction performance of model trained by Binary Logistic Regression component.
 AUC value indicates hazy weather prediction model trained by Logistic Regression component has over 98% accuracy.
AUC value indicates hazy weather prediction model trained by Logistic Regression component has over 98% accuracy.
-