This topic describes the best practices for transactions and Read/Write Concern in ApsaraDB for MongoDB.
Background information
MongoDB 4.0 supports standalone transactions (replica set transactions). You can perform operations on transactions in one or more collections of a replica set instance. MongoDB 4.2 supports distributed transactions (shard transactions). You can perform operations on different documents in multiple collections across shards.
ApsaraDB for MongoDB always guarantees the atomicity of operations on a single document. Your application can use embedded documents and array structures to construct a single document that is more closely associated due to the flexibility of the document structure. This is much simpler than using a traditional relational database, where, you have to create multiple collections that follow structure rules and perform joins or update multiple transactions. In most scenarios of ApsaraDB for MongoDB that involve reasonable data modeling, the atomicity guarantee of operations on a single document has eliminated the requirements for distributed transactions.
However, some special scenarios, such as finance and accounting, still have strong requirements for distributed transactions. MongoDB 4.2 or later fully supports distributed documents and can meet the requirements in such scenarios.
Transactions
Background information
ApsaraDB for MongoDB can be used in the same manner as traditional relational databases. The APIs in ApsaraDB for MongoDB can be used in the same manner as that of the traditional relational databases. No learning curves are involved.
The following example shows a transaction. You can view the settings of APIs (startTransaction, abortTransaction, and commitTransaction) and related sessions, read concerns, and write concerns.
// Create collections.
db.getSiblingDB("mydb1").foo.insertOne(
{abc: 0},
{ writeConcern: { w: "majority", wtimeout: 2000 } }
)
db.getSiblingDB("mydb2").bar.insertOne(
{xyz: 0},
{ writeConcern: { w: "majority", wtimeout: 2000 } }
)
// Start a session.
session = db.getMongo().startSession( { readPreference: { mode: "primary" } } );
coll1 = session.getDatabase("mydb1").foo;
coll2 = session.getDatabase("mydb2").bar;
// Start a transaction.
session.startTransaction( { readConcern: { level: "local" }, writeConcern: { w: "majority" } } );
// Perform operations in the transaction.
try {
coll1.insertOne( { abc: 1 } );
coll2.insertOne( { xyz: 999 } );
} catch (error) {
// Abort the transaction when an error occurs.
session.abortTransaction();
throw error;
}
// Commit the transaction.
session.commitTransaction();
session.endSession();Take note of the following items when you use transactions:
A transaction must be associated with a session. A session can have only one outstanding transaction at a time. After a session ends, the outstanding transaction associated with the session is rolled back.
A distributed transaction can contain operations on different documents in different collections at the same time.
When a transaction is executed, the transaction can read write operations that are not committed by the transaction. However, other operations outside the transaction cannot read the write operations that are not committed in the transaction.
Uncommitted data written to a transaction is not replicated to secondary nodes until the transaction is committed. After a transaction is committed, data written to the transaction is replicated and automatically applied to all secondary nodes in a replica set instance.
When you modify a document, a transaction locks the document to prevent the document from being changed by other operations until the transaction is complete. A transaction cannot obtain a lock on the document that the transaction needs to modify because another transaction may already hold the lock. In this case, the transaction will be aborted and write conflicts will be reported after 5 milliseconds. The transaction abortion time is specified by the maxTransactionLockRequestTimeoutMillis kernel parameter. For more information about the parameter, see maxTransactionLockRequestTimeoutMillis.
Transactions are subject to a retry mechanism. If a temporary retry error is reported, such as a temporary network interruption, the transaction is automatically retried. Your client is unaware of retry operations.
A transaction has a lifecycle. A transaction that runs for more than 60 seconds is forcibly aborted by a background thread. The forcible abortion time for a transaction is specified by the transactionLifetimeLimitSeconds kernel parameter. For more information about the parameter, see transactionLifetimeLimitSeconds.
Limits
A distributed transaction does not allow you to create new collections and indexes.
A transaction cannot be written to a capped collection.
A transaction cannot use the snapshot read concert level to read a capped collection. This applies to MongoDB 5.0 or later.
A transaction cannot read or write collections in a database named
config/admin/local.A transaction cannot write data to a system collection in the
system.*format.A transaction does not support
explain.A transaction cannot use
getMoreto read cursors created outside the transaction. Cursors created in the transaction cannot be read by usinggetMoreoutside the transaction, either.The first operation in a transaction cannot be
killCursors/hello.Non-CRUD commands such as
listCollections, listIndexes, createUser, getParameter, and countcannot be executed in a transaction.You cannot set the writeConcernMajorityJournalDefault parameter to false for shards in a distributed transaction. For more information about the parameter, see writeConcernMajorityJournalDefault.
A distributed transaction does not support shards that contain arbiters. For more information about arbiters, see Production Considerations.
Best practices
Use standalone transactions instead of distributed transactions
In most scenarios, distributed transactions provide poorer performance than standalone transactions or write operations that do not involve transactions. This is because operations that involve transactions require operations that are more complex. Denormalized data models (embedded documents and array structures) are the optimal choice for data modeling in ApsaraDB for MongoDB. Reasonable data modeling and standalone transactions can fully meet the transaction requirements of your application in most scenarios.
Avoid long-running transactions
By default, ApsaraDB for MongoDB automatically aborts distributed transactions that run for more than 60 seconds. To resolve timeout issues, split a transaction into smaller parts to execute the transaction within a specified period of time. Make sure that query statements are optimized and provide appropriate index coverage to quickly access data in transactions.
Do not modify a large number of documents in a transaction
ApsaraDB for MongoDB does not impose limits on the number of documents that can be read in a transaction. However, if you modify a large number of documents in a transaction, the workload of data synchronization between the primary and secondary nodes may increase, which causes delayed synchronization and other issues on the secondary nodes. We recommend that you modify up to 1,000 documents in a transaction. If you want to modify more than 1,000 documents in a transaction, we recommend that you split the transaction into multiple parts and modify the documents in batches.
Do not execute large transactions that exceed 16 MB in size
In MongoDB 4.0, a transaction is represented by a single oplog entry. The entry must fall within 16 MB in size. In ApsaraDB for MongoDB, oplogs record the incremental content in the case of an update operation, and record the entire document in the case of an insert operation. Therefore, all oplog records for all statements in a transaction must fall within 16 MB in size. If this limit is exceeded, the transaction is aborted and completely rolled back. We recommend that you split a large transaction into smaller operation sets that each are 16 MB or less in size.
MongoDB 4.2 or later creates multiple oplog entries to store all write operations in a transaction. This way, a single transaction can exceed 16 MB in size. However, we recommend that you keep the transaction size within 16 MB. Large transactions may cause other issues.
Design a proper logic for handling transaction rollback on your client
When a transaction is abnormally aborted, an exception is returned to the driver and the transaction is rolled back. Add a logic for capturing and retrying transactions that are aborted due to temporary exceptions, such as primary/secondary switchovers and node failures, to your application. Drivers provided by ApsaraDB for MongoDB use retryable writes to automatically retry to commit transactions. However, your application still needs to handle transaction exceptions and errors that cannot be resolved by the retryable writes such as TransactionTooLarge, TransactionTooOld, and TransactionExceededLifetimeLimitSeconds. For more information about retryable writes, see Retryable Writes.
Avoid DDL operations in transactions
DDL operations on a collection, such as createIndex or dropDatabase, are blocked by active transactions that run on the collection. In this case, all transactions that attempt to access the same collection cannot obtain a lock within a specified time, which causes new transactions to be aborted.
MongoDB 4.4 or later optimizes related limits that are specified by the shouldMultiDocTxnCreateCollectionAndIndexes parameter. You can perform the createCollection or createIndex operation on distributed transactions. However, the operation has the following limits. For more information about the parameter, see MongoDB Server Parameters.
You can only implicitly create a collection.
You can perform the operation on collections that do not exist.
You can perform the operation on collections that do not contain data.
Therefore, we recommend that you avoid DDL operations in transactions.
Roll back transactions that you do not want to commit and transactions that have errors at your earliest opportunity
All modifications of transactions that are not committed are stored in the WiredTiger cache. If the system contains multiple transactions that you do not want to commit and transactions that have errors, the WiredTiger cache may encounter a higher load and cause other issues. Control the duration of operations on transactions and roll back transactions that you do not want to commit at your earliest opportunity to release resources.
Increase the values of parameters related to timeout if transactions are frequently rolled back due to timeout for obtaining locks
By default, if operations in a transaction cannot obtain required locks within 5 milliseconds, the transaction is automatically rolled back. If a transaction is rolled back or committed, the transaction releases all occupied locks. If transactions are frequently rolled back due to timeout for obtaining locks, increase the value of the maxTransactionLockRequestTimeoutMillis parameter. For more information, see maxTransactionLockRequestTimeoutMillis.
If the issue persists, review operations in a transaction, check whether the transaction contains operations that may occupy locks for a long time, such as DDL operations and queries to be optimized.
Avoid write conflicts caused by modifying the same document in and outside a transaction
If a write operation outside an ongoing transaction has modified a document, and an operation in the transaction also attempts to modify the document, the transaction is rolled back due to write conflicts. If the ongoing transaction has obtained the lock required to modify the document, external write operations must wait until the transaction ends before they can modify the document.
When a write conflict occurs, write operations outside the transaction do not fail or return an error to your client. ApsaraDB for MongoDB continues to retry the operations and increments the writeConflicts counter each time until the operations succeed. Your client is not aware of the exceptions. However, the requests take a long time to be responded.
In most cases, a small number of write conflicts do not have a significant impact. However, if a large number of write conflicts occur, database performance may be degraded. You can use audit logs or slow query logs to check whether a large number of write conflicts occurred.
Kernel risks
If you create long-running transactions or attempt to perform a large number of operations in a transaction, the WiredTiger cache encounters a high load because the cache must store data and maintain data status for all subsequent write operations in transactions that are not committed. Transactions in progress use the same snapshot. Therefore, new write operations continue to accumulate in the WiredTiger cache during transaction running. Write operations in the WiredTiger cache can be evicted until transactions that run in old snapshots are committed or aborted. In most cases, the overload of the WiredTiger cache caused by long-running transactions results in more issues, such as database stalling, significant increase in response latency, high CPU utilization and even deadlocks that affect your business. The overload of the cache occurs when the cache utilization and dirty cache utilization of the WiredTiger storage engine exceed specified thresholds. For more information about kernel risks, see SERVER-50365 and SERVER-51281.
To prevent risks, we recommend that you upgrade your ApsaraDB for MongoDB instance that frequently handles long-running transactions or performs a large number of operations in transactions to MongoDB 5.0 or later.
Read Concern
Background information
Read Concern provides the following data consistency and isolation levels. For more information, see Read Concern.
"local": Default for read against the primary node or the secondary nodes in a replica set instance. Data is read from local databases. Data that is rolled back may be read."available": Default for read against secondary nodes in a sharded cluster instance. Data that is rolled back may be read. The shard version is not checked before the data is read. Therefore, orphaned documents may be read. The level provides the lowest access latency."majority": Data that is acknowledged by a majority of nodes is read. The data is not rolled back."linearizable": linearization level that requires the highest data consistency. Read operations must wait until all write operations are acknowledged by a majority of nodes. The level provides the poorest performance and is available only for the primary node."snapshot": Data that is acknowledged by a majority of nodes is read based on a snapshot. A snapshot in a specific point in time can be associated with read operations. You can configure the atClusterTime parameter to specify a timestamp for the read operations. For more information about the parameter, see Read Concern and atClusterTime.
Take note of the following items:
The latest data on a mongos node does not represent the latest version of data in a replica set instance regardless of the read concern level.
You can specify different read concern levels for different operations. You can also specify the default read concern level for instances that run MongoDB 4.4 or later on a server. The read concern levels of the operations have a higher priority than that on the server.
When data is read from
localdatabases, the read concern level that you specify is ignored. In this case, you can always read all local data from thelocaldatabases.Distributed transactions support only the
"local","majority", and"snapshot"read concern levels.Causally consistent sessions support only the
"majority"read concern level.
Best practices
Specify a read concern level only for a distributed transaction
You do not need to specify a read concern level for each operation in a distributed transaction. The read concern level of the transaction overrides other settings or the default read concern level.
Read Concern, similar to Write Concern, can be applied to all queries on databases regardless of whether the queries are performed on a single document or a set of documents or are encapsulated in a multi-document read transaction.
Use the "majority" read concern level in most cases
To ensure data consistency and isolation, we recommend that you use the "majority" read concern level. Your application can read data only when the data is replicated to a majority of nodes in a replica set instance. Therefore, data is not rolled backed when a node is elected as the primary node.
Read data from the primary node and use the "local" or "linearizable" read concern level in the scenario where your own writes are read
To read written modifications at your earliest opportunity after a write operation is complete, read data from the primary node and use the "local" or "linearizable" read concern level. If the "majority" write concern level is used, the "majority" read concern level can be used.
You can use causally consistent sessions for instances that run MongoDB 3.6 or later in the scenario.
Configure the maxTimeMS parameter if the "linearizable" read concern level is used in scenarios that require the highest data consistency
The "linearizable" read concern level ensures that the primary node in a replica set instance is still the primary node of the instance when data is read from the node and that data returned by a node is not rolled back when the node is selected as the new primary node. However, the level has a significant impact on latency. Configure the maxTimeMS parameter to prevent read operations from being indefinitely blocked when a majority of nodes fail.
Write Concern
Background information
Use the following format to configure Write Concern: For more information about Write Concern, see Write Concern.
{ w: <value>, j: <boolean>, wtimeout: <number> }Write Concern that specifies the guarantee level of data persistence provides the following levels:
{w: 0}: Write operations are not acknowledged to be complete and written data may be lost.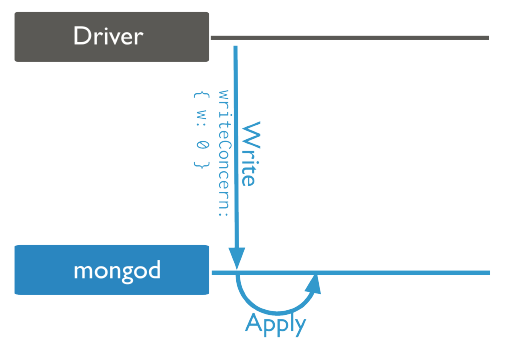
{w: 1}: Write operations are acknowledged to be complete. Default for instances that run versions earlier than MongoDB 5.0. Data loss may occur because data is not persisted.
{j: true}: Write operations are acknowledged to be complete and flushed to WAL logs that are persistently stored. The operations are not lost.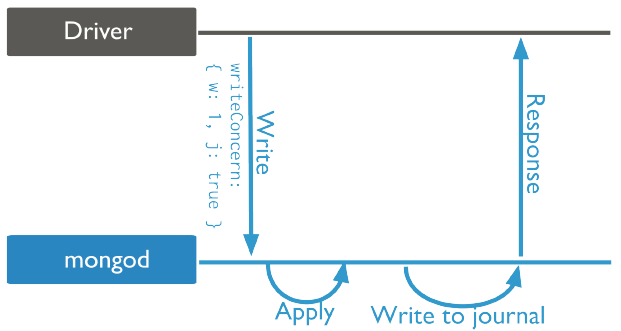
{ w: "majority" }: Write operations can be acknowledged until the operations are replicated to a majority of nodes in a replica set instance. Data is not rolled back. Default for instances that run MongoDB 5.0 or later.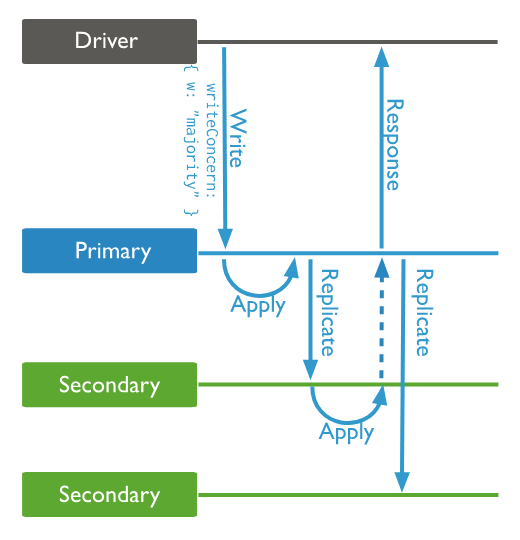
Replica acknowledgment: Write operations can be acknowledged until the operations are replicated to a specific number of nodes in a replica set instance.
Custom acknowledgment: Configure the settings.getLastErrorModes parameter to specify other custom acknowledgment methods by using tags. For more information about the parameter, see settings.getLastErrorModes.
Take note of the following items:
You can specify a write concern level for a write operation or a transaction. If you do not specify a level, the default write concern level is used.
NoteThe default global write concern level is changed from
{w:1}to{w:"majority"}in instances that run MongoDB 5.0 or later and use the standard three-replica topology architecture. This may cause performance degradation after you upgrade your instance to MongoDB 5.0 or later.Hidden nodes, latency nodes, or other nodes whose priority is 0 in a replica set instance can be considered as the members of nodes specified by the
"majority"write concern level.You can specify different write concern levels for different operations. You can also specify the default write concern level for instances that run MongoDB 4.4 or later on a server. The write concern levels of the operations have a higher priority than that on the server.
When data is written to
localdatabases, the write concern level that you specify is ignored.Causally consistent sessions support only the
"majority"write concern level.
Best practices
Specify a write concern level only for a distributed transaction
You do not need to specify a write concern level for each write operation in the transaction. Otherwise, an error is reported.
Use the "majority" write concern level in general scenarios
The “majority" write concern level ensures that the majority of nodes in a replica set instance acknowledge write operations. Data loss or rollback does not occur if a node failure occurs or a primary/secondary switchover encounters an exception.
Use the {w:1} write concern level in scenarios that require the highest write performance and focus on the replication latency of secondary nodes
In most cases, the {w:1} write concern level provides higher write performance and is suitable for scenarios where the frequency of writes is high. Take note of the replication latency on secondary nodes. If the replication latency is high, the primary node may fail to be rolled back. For more information, see ROLLBACK. If the replication latency exceeds the retention period of oplogs, the secondary nodes enter the abnormal recovering state and fail to automatically recover from failures, which reduces instance availability. For more information about the state, see RECOVERING.
The preceding issue may occur in an ApsaraDB for MongoDB instance that runs a version earlier than MongoDB 5.0 when you batch write a large amount of data to the instance or use Data Transmission Service (DTS) to migrate data to the instance. To resolve this issue, we recommend that you use the "majority" write concern level.
Specify a proper write concern level for an operation
Specify a write concern level for an operation based on the requirements of the operation. For example, you can use transactions for which write concern levels are specified for financial transaction data to ensure atomicity, use the "majority" write concern level for the data of core players to ensure that the data is not rolled back, and use the default or {w:1} write concern level for log data.
ApsaraDB for MongoDB provides enhanced flexibility to allow you to specify a write concern level based on your business requirements.