Large language models (LLMs) lack private knowledge, and their general knowledge can be outdated. The industry commonly uses retrieval-augmented generation (RAG) technology to retrieve relevant information from external sources based on user input. This retrieved content is then combined with the user's query and provided to the LLM to generate more accurate answers. The knowledge base feature, which is the RAG capability of Model Studio, effectively supplements private knowledge and provides the latest information.
Console restrictions: Only International Edition users who created applications before April 21, 2025 can access the Application Development tab, as shown in the following figure.
This tab contains the following features: Applications (agent application and workflow application), Components (prompt engineering and plug-in), and Data (knowledge base and application data). These are all preview features. Use them with caution in production environments.

API call limits: Only International Edition users who created applications before April 21, 2025, can call the application data, knowledge base, and prompt engineering APIs.
Application without a dedicated knowledge base Without a dedicated knowledge base, the LLM cannot accurately answer questions about specific domains.
| Application with a dedicated knowledge base With a dedicated knowledge base, the LLM can accurately answer questions about specific domains.
|


Model availability
You can use a knowledge base with the following models. Set up a Qwen knowledge base
Qwen-Max/Plus/Turbo
QwenVL-Max/Plus
Qwen (Qwen2.5, etc.)
The list above may be updated at any time. Refer to the models that are available on the My Applications page when you create an application for the most current list.
Getting started
This section describes how to build a LLM Q&A application that can answer questions about a specific domain (in this case, a fictional "Bailian phone") without writing any code.
1. Build a knowledge base
Go to the Knowledge Base page and click Create Knowledge Base. Enter a Name, leave the other settings at their default values, and click Next Step.
Select the Default Category and upload the Bailian Phones Specifications.docx file. Click Next Step, and then click Import.
2. Integrate with a business application
After you create a knowledge base, you can associate it with a specific application (which must be in the same workspace as the knowledge base) or an external application to process retrieval requests.
Integrate with an agent application
Go to the My Applications page, find the target agent application, and click Configure on its card. Then, select a model for the application.

Click the + button to the right of Document to add the knowledge base that you created in the previous step. You can keep the default values for the similarity threshold and weight.
When an agent application is associated with multiple knowledge bases, you can assign a weight to each knowledge base based on the importance of the information source. During multi-channel recall, if multiple knowledge bases contain relevant text segments, the system prioritizes text segments from the knowledge base with a higher weight.
Key limitation: Weights only take effect between knowledge bases of the same type. For example, the weight of a Document Search knowledge base does not affect the retrieval order of a Data Query knowledge base, and vice versa.
How it works: The system first calculates the relevance of the user's question to the content in each knowledge base and filters for the most relevant text segments. Then, it multiplies the similarity score of each text segment by the weight of its corresponding knowledge base. After reranking the results based on these weighted scores, the system provides them to the LLM to reference when generating an answer. Segments with higher weighted scores are more likely to be used.

Ask a question in the input box on the right. The LLM will use the knowledge base that you created to generate an answer.
For example: "Please help me choose the best Bailian phone for photography that costs less than 3,000 yuan."
Integrate with a workflow application
Go to the My Applications page, find the target workflow application, and click Configure on its card. Then, drag a Knowledge Base node onto the canvas and connect it after the Start node.
Configure the Knowledge Base node:
Input: In the Value drop-down list to the right of the variable name
content, select .Select Knowledge Base: Select the knowledge base that you created in the previous step.
Set topK (Optional): This determines the number of knowledge segments returned to descendant nodes (usually LLM nodes).
Increasing this value usually improves the accuracy of the LLM's answers, but it also increases the number of input tokens consumed by the LLM.
Drag a LLM node onto the canvas and connect it after the Knowledge Base node and before the End node.
Configure the LLM node:
In the Model Configuration list, select a model for the node.
In the Prompt field, enter a prompt that instructs the LLM to use the knowledge base. You must enter / to insert the
resultvariable, which represents the results returned by the knowledge base retrieval.
Configure the End node: Enter
/, then select to output the result returned by the LLM.Click Test in the upper-right corner of the page. Then, ask a question in the input box on the right. The LLM will use the knowledge base that you created to generate an answer.
For example: "Please help me choose the best Bailian phone for photography that costs less than 3,000 yuan."
Integrate with an external application
In addition to building applications in Model Studio, you can also use the retrieval capability of a knowledge base as an independent RAG service. Using the GenAI Service Platform SDK, you can quickly integrate this service into external AI applications.
For detailed integration steps, see the Knowledge base API guide.
3. Optimize the knowledge base (Optional)
If knowledge retrieval is incomplete or the content is inaccurate during the Q&A process, see Optimize knowledge base performance.
User guide
On the Knowledge Base page, you can view and manage all knowledge bases in the current workspace.
Knowledge Base ID: The value of the ID field on each knowledge base card. It is used for API calls and other scenarios.Create a knowledge base
On the Knowledge Base page, click Create Knowledge Base.
Select the appropriate Knowledge Base Type based on your application scenario. A single knowledge base can only support one type. You cannot change the knowledge base type after creation.
Document Search (for retrieval scenarios)
Scenarios:
This type is suitable for retrieving unstructured data (data that is not organized in a predefined table schema, including text, tables, and images), such as internal company documents and product manuals.
If a file contains images and you need the application to return them in the answer, select Document Search.
Data Source Integration: You can upload local files or import from Alibaba Cloud Object Storage Service (OSS).
Select data: Specify the data source (containing files or content) for the knowledge base. The content of the data source is imported into the knowledge base for subsequent retrieval. Two methods are supported: Local Upload and Cloud Import (selecting an existing category or file).
Local Upload: Upload files directly from your computer. Expand the collapsible panel below to learn how to select a parsing method.
Configure the parsing policy based on your requirements. If you are unsure which to choose, you can keep the default settings.
Digital Parsing: Does not support parsing illustrations or charts in files.
Intelligent Parsing: For illustrations in a file, the parser identifies and extracts the text from the images and generates text summaries. These summaries, along with other non-image content in the file, are chunked, converted into embeddings, and used for knowledge base retrieval.
LLM Parsing: If you use an agent application with the Qwen-VL model, you can ask questions about the content of illustrations and charts in files. To enable the recognition and understanding of illustrations and charts in files, select LLM Parsing.
Qwen VL parsing: This method is specifically for image files. You can specify the Qwen-VL model and provide a prompt to guide the recognition and extraction of the image layout and elements.


Cloud Import: Import existing files from application data or Object Storage Service (OSS). For detailed instructions, see Data import.
Index configuration: Defines how imported data is processed and stored, which directly affects retrieval performance.
Among the following configuration items, only "Vector storage" may incur fees if you choose ADB-PG. All other configurations are free.
Metadata extraction
Metadata is a set of additional properties related to unstructured data. These properties are integrated into text segments as key-value pairs.
Purpose: Metadata provides important contextual information for text segments and can significantly improve the accuracy of knowledge base retrieval. For example, imagine a knowledge base that contains thousands of product introduction files, where the file names are the product names. When a user searches for "functional overview of Product A", if the body of every file contains "functional overview" but does not mention "Product A", the knowledge base might retrieve many irrelevant text segments. However, if the product name is added as metadata to all text segments, the knowledge base can accurately filter for text segments related to "Product A" that also contain "functional overview". This improves retrieval accuracy and reduces the number of input tokens consumed by the model.
Usage: When you call an application using an API, you can specify metadata in the
metadata_filterrequest parameter. When retrieving from the knowledge base, the application first filters relevant files based on the metadata.Note: After a knowledge base is created, you cannot configure metadata extraction.
Enable Metadata Extraction, and then click Settings to add unified or personalized metadata to all files in the knowledge base. During chunking, the metadata of each file is integrated into its respective text segments. The figure below shows the meta information template used in the example above:
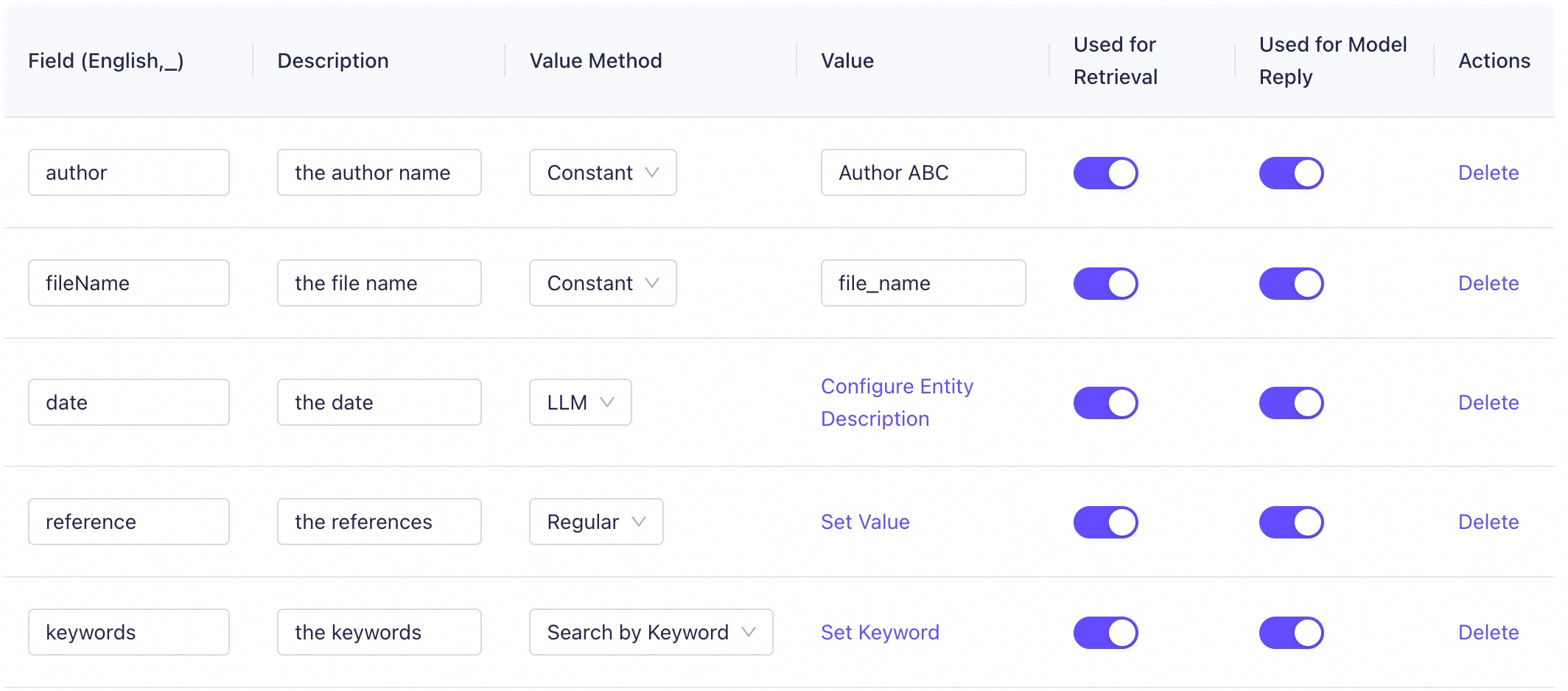
Value extraction methods:
Constant: Adds a fixed property to all files in the knowledge base.
As shown in the example above, if all files in the knowledge base have the same author, you can uniformly set a constant field named
author.Variable: Adds a variable property to each file in the knowledge base. Currently supported properties include
file_nameandcat_name. When you selectfile_name, Model Studio adds the file's name to its metadata, as shown in the example above. When you selectcat_name, Model Studio adds the name of the category where the file is located to the file's metadata.LLM: The system matches the text content of each file in the knowledge base according to the specified Entity Description rule. The system automatically identifies and extracts relevant information from the file and adds this information as properties to the file's metadata.
As shown in the meta information template in the example above, to extract all years mentioned in each file as a property of the file, you can set a LLM field named
datewith the following entity description configuration: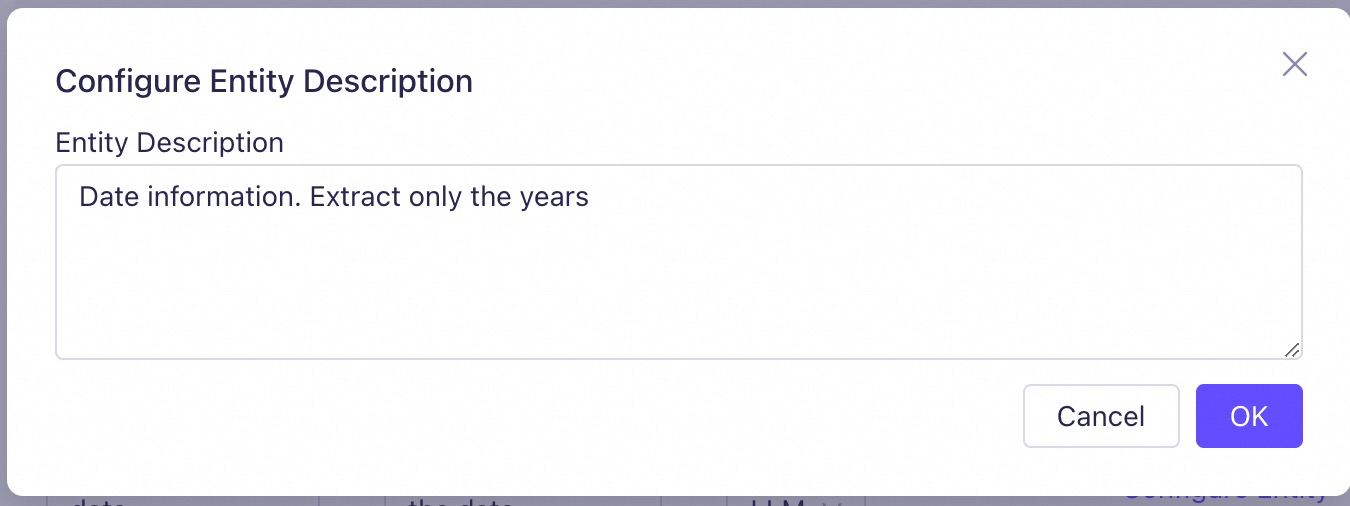
Regular: The system matches the text content of each file in the knowledge base according to the specified regular expression. Content that matches the expression is extracted and added as a property to the file's metadata.
As shown in the meta information template in the example above, to extract all references mentioned in each file, assuming the references follow the pattern of starting with " and ending with ", you can set a regular expression field named
referencewith the following regular expression configuration:
Keyword search: The system searches for preset keywords in each file and adds the found keywords as properties to that file's metadata.
For example, in the meta information template from the example above, our preset keywords are:

However, because only the keywords "financing", "industry", "green", and "capital" appeared in this file, the system only extracted these four keywords as the value for the file's
keywordsproperty.
Used for Retrieval: When enabled, the metadata fields and values are included in the knowledge base retrieval along with the text segment content. When disabled, only the text segment content is used for retrieval.
Used for Model Reply: When enabled, the metadata fields and values are included in the LLM's response generation process along with the text segment content. When disabled, only the text segment content is used for the LLM's response generation process.
Excel header assembly
When enabled, the knowledge base treats the first row of all XLSX and XLS format files as the table header and automatically appends it to each text segment (data row). This prevents the LLM from mistakenly treating the header as a regular data row.
If the knowledge base contains files in other formats, such as PDF, you do not need to enable this setting.
Chunking method
Select Intelligent Splitting (Recommended).
Purpose: The knowledge base splits files into text segments (chunks) and converts these chunks into vectors using a vector model. The text segments and their corresponding vectors are then stored as key-value pairs in a vector database. After the knowledge base is created, you can view or edit the specific content (text and images) of each text segment.
Note: After a knowledge base is created, you cannot change the document chunking method. An unsuitable chunking policy can reduce retrieval and recall performance.
Multi-round conversation rewriting
When this feature is enabled, the system calls a dedicated lightweight model to rewrite the user's current question into an independent, contextually complete new query by incorporating the conversation history. This new query is then used for knowledge base retrieval.

Embedding model
Embedding models convert original input prompts and knowledge text into numerical embeddings to calculate their semantic similarity.The default model (which cannot be changed) supports multiple languages in addition to Chinese and English and normalizes the resulting vectors.
Vector dimensions generated by different vector models in the knowledge base:
The following vector dimensions cannot be changed.
text-embedding-v2: 1,536 dimensions

Reranking model
The reranking model performs a secondary ranking on the candidate segments that are initially retrieved by the vector search and returns the top-K text segments with the highest similarity scores. The Official Ranking model (recommended) combines semantic relevance with keyword matching algorithms (such as BM25) to better handle queries that require precise keyword hits. If you only need semantic ranking, select the GTE-ReRank model.

Similarity threshold
This threshold represents the minimum similarity score for a text segment to be retrieved. It is used to filter the text segments returned by the reranking model. Only text segments with a score that exceeds this value are retrieved.
NoteThis setting is the default similarity threshold for the knowledge base. When you associate the knowledge base with a specific application, you can also set a separate threshold for that application, which overrides the knowledge base's default similarity threshold.
Lowering this threshold is expected to retrieve more text segments, but may retrieve some less relevant ones. Raising this threshold reduces the number of retrieved text segments. If set too high, it causes the knowledge base to discard relevant text segments.
You can use hit testing to fine-tune the similarity threshold to balance the recall rate and precision.
Maximum recalls
Suppose an application is associated with three knowledge bases: A1, A2, and A3. The system retrieves segments related to the user's input from these bases, reranks them using a reranking model, and selects the top-K most relevant segments to provide to the LLM as context for its response. This value, K, is the Maximum recall count (up to a limit of 20). It determines the number of text segments that the reranking model provides to the LLM for reference.
Increasing this value can improve the accuracy of the LLM's response, but it also increases the number of input tokens consumed by the LLM.
Vector storage
Select a vector database to store text vectors. The Platform Storage vector database is sufficient for the basic functional needs of a knowledge base. For advanced features, such as managing, auditing, or monitoring the database, we recommend selecting ADB-PG (AnalyticDB for PostgreSQL).
Note that when you purchase an ADB-PG instance, you must enable Vector Engine Optimization. Otherwise, Model Studio cannot use this instance.
Data Query (for Chatbot or NL2SQL scenarios)
Scenarios:
This type is suitable for building Q&A systems based on structured data (data organized in a predefined table schema), such as FAQ, product data, or personnel information query assistants.
If your data consists of complete FAQ Q&A pairs, select Data Query. For example, if you have an Excel file that contains two columns,
QuestionandAnswer, a Data Query knowledge base lets you retrieve information only from theQuestioncolumn and use only the content from theAnswercolumn as a reference for the LLM's response.A Document Search knowledge base cannot easily achieve this effect.
You can import multiple Excel files with completely identical table schemas.
Data Source Integration: You can upload local XLS or XLSX files.
Select data: Specify a data source, such as files or content, to import into the knowledge base for subsequent retrieval.The following two methods are supported: Local upload and Cloud import (select existing data tables from application data).
NoteThe data source cannot be changed after the knowledge base is created, and a single knowledge base cannot support multiple data sources at the same time.
Local Upload: Upload data tables (XLS or XLSX format, and the first row must be the table header) directly from your computer.
Cloud import (Select data table): Select an existing data table in your application. For the procedure, see Data Import.
Index configuration: Defines how imported data is processed and stored, which directly affects retrieval performance.
Among the following configuration items, only "Vector storage" may incur fees if you choose ADB-PG. All other configurations are free.
Participate in retrieval/Participate in model response
Participate In Retrieval: When enabled, the knowledge base is allowed to search within this column of data.
Include In Model Response: When enabled, the retrieval results from this column are used as input for the LLM to generate a response. For example, in the configuration shown in the following figure, Include In Retrieval is enabled for the "Name", "Gender", "Position", and "Age" columns, and Include In Model Response is enabled for the "Name" and "Position" columns. In this case, the knowledge base retrieves data from all columns. However, only the content from the "Name" and "Position" columns of the retrieved data is provided to the LLM to help generate the response.

As shown in the figure below, because "Age" is not enabled to participate in the model response, the LLM still cannot answer the question "What is Zhang San's age?" after being associated with this knowledge base.

Multi-round conversation rewriting
When this feature is enabled, the system calls a dedicated lightweight model to rewrite the user's current question into an independent, contextually complete new query by incorporating the conversation history. This new query is then used for knowledge base retrieval.

Embedding model
Embedding models convert original input prompts and knowledge text into numerical embeddings to calculate their semantic similarity.The default model (which cannot be changed) supports multiple languages in addition to Chinese and English and normalizes the resulting vectors.
Vector dimensions generated by different vector models in the knowledge base:
The following vector dimensions cannot be changed.
text-embedding-v2: 1,536 dimensions

Reranking model
The reranking model performs a secondary ranking on the candidate segments that are initially retrieved by the vector search and returns the top-K text segments with the highest similarity scores. The Official Ranking model (recommended) combines semantic relevance with keyword matching algorithms (such as BM25) to better handle queries that require precise keyword hits. If you only need semantic ranking, select the GTE-ReRank model.

Similarity threshold
This threshold represents the minimum similarity score for a text segment to be retrieved. It is used to filter the text segments returned by the reranking model. Only text segments with a score that exceeds this value are retrieved.
NoteThis setting is the default similarity threshold for the knowledge base. When you associate the knowledge base with a specific application, you can also set a separate threshold for that application, which overrides the knowledge base's default similarity threshold.
Lowering this threshold is expected to retrieve more text segments, but may retrieve some less relevant ones. Raising this threshold reduces the number of retrieved text segments. If set too high, it causes the knowledge base to discard relevant text segments.
You can use hit testing to fine-tune the similarity threshold to balance the recall rate and precision.
Maximum recalls
Suppose an application is associated with three knowledge bases: A1, A2, and A3. The system retrieves segments related to the user's input from these bases, reranks them using a reranking model, and selects the top-K most relevant segments to provide to the LLM as context for its response. This value, K, is the Maximum recall count (up to a limit of 20). It determines the number of text segments that the reranking model provides to the LLM for reference.
Increasing this value can improve the accuracy of the LLM's response, but it also increases the number of input tokens consumed by the LLM.
Vector storage
Select a vector database to store text vectors. The Platform Storage vector database is sufficient for the basic functional needs of a knowledge base. For advanced features, such as managing, auditing, or monitoring the database, we recommend selecting ADB-PG (AnalyticDB for PostgreSQL).
Note that when you purchase an ADB-PG instance, you must enable Vector Engine Optimization. Otherwise, Model Studio cannot use this instance.
Image Q&A (for search-by-image scenarios)
Scenarios:
This type is suitable for building multimodal retrieval applications such as search by image and search by image plus text, like a product shopping guide or Image Q&A assistant.
Data Source: You can upload local XLS or XLSX files.
XLS and XLSX files must contain publicly accessible image URLs to build image indexes. For details, see the creation instructions below.
Select data: Specify a data source, such as a file or content, for the knowledge base. The content from the data source is imported into the knowledge base for subsequent retrieval.The following two methods are supported: local upload and cloud import (select an existing data table from application data).
NoteThe data source cannot be changed after the knowledge base is created, and a single knowledge base cannot support multiple data sources at the same time.
Local Upload: Upload data tables (XLS or XLSX format) directly from your computer.
NoteField: The data table should contain at least one field of type
image_urlto generate the image index.Build process: The knowledge base accesses the image URL in the
image_urlfield, extracts visual features, and converts them into stored vectors.Retrieval process: The knowledge base compares the vector generated from the user's uploaded image with the stored image vectors for similarity and returns the most relevant records.
Cloud import (select a data table): Select an existing data table from the application data in Model Studio. For more information, see Data Import.
Index configuration: Defines how imported data is processed and stored, which directly affects retrieval performance.
Among the following configuration items, only "Vector storage" may incur fees if you choose ADB-PG. All other configurations are free.
Participate in retrieval/Participate in model response
Participate In Retrieval: When enabled, the knowledge base is allowed to search within this column of data.
Include In Model Response: When enabled, the retrieval results from this column are used as input for the LLM to generate a response. For example, in the configuration shown in the following figure, Include In Retrieval is enabled for the "Name", "Gender", "Position", and "Age" columns, and Include In Model Response is enabled for the "Name" and "Position" columns. In this case, the knowledge base retrieves data from all columns. However, only the content from the "Name" and "Position" columns of the retrieved data is provided to the LLM to help generate the response.
As shown in the figure below, because "Age" is not enabled to participate in the model response, the LLM still cannot answer the question "What is Zhang San's age?" after being associated with this knowledge base.
Multi-round conversation rewriting
When this feature is enabled, the system calls a dedicated lightweight model to rewrite the user's current question into an independent, contextually complete new query by incorporating the conversation history. This new query is then used for knowledge base retrieval.
Vector model
Vector models convert original input Prompts, knowledge text, and images into numerical vectors for similarity comparison. The default multimodal embedding v1 (multimodal-embedding-v1) model (which cannot be changed) supports both Chinese and English and various image and video formats, normalizes the vector results, and is suitable for most scenarios. For more information, see Text and Multimodal Embedding.
Reranking model
The reranking model performs a secondary ranking on the candidate segments that are initially retrieved by the vector search and returns the top-K text segments with the highest similarity scores. The Official Ranking model (recommended) combines semantic relevance with keyword matching algorithms (such as BM25) to better handle queries that require precise keyword hits. If you only need semantic ranking, select the GTE-ReRank model.
Similarity threshold
This threshold represents the minimum similarity score for a text segment to be retrieved. It is used to filter the text segments returned by the reranking model. Only text segments with a score that exceeds this value are retrieved.
NoteThis setting is the default similarity threshold for the knowledge base. When you associate the knowledge base with a specific application, you can also set a separate threshold for that application, which overrides the knowledge base's default similarity threshold.
Lowering this threshold is expected to retrieve more text segments, but may retrieve some less relevant ones. Raising this threshold reduces the number of retrieved text segments. If set too high, it causes the knowledge base to discard relevant text segments.
You can use hit testing to fine-tune the similarity threshold to balance the recall rate and precision.
Maximum recalls
Suppose an application is associated with three knowledge bases: A1, A2, and A3. The system retrieves segments related to the user's input from these bases, reranks them using a reranking model, and selects the top-K most relevant segments to provide to the LLM as context for its response. This value, K, is the Maximum recall count (up to a limit of 20). It determines the number of text segments that the reranking model provides to the LLM for reference.
Increasing this value can improve the accuracy of the LLM's response, but it also increases the number of input tokens consumed by the LLM.
Vector storage
Select a vector database to store text vectors. The Platform Storage vector database is sufficient for the basic functional needs of a knowledge base. For advanced features, such as managing, auditing, or monitoring the database, we recommend selecting ADB-PG (AnalyticDB for PostgreSQL).
Note that when you purchase an ADB-PG instance, you must enable Vector Engine Optimization. Otherwise, Model Studio cannot use this instance.
During peak hours, the entire creation process may take several hours, depending on the data volume. Please wait patiently.
Update a knowledge base
Any changes to the knowledge base content are synchronized in real time with all applications that reference it.
Document Search knowledge bases
Automatic update (Recommended)
You can achieve this by integrating the APIs for OSS, FC, and Model Studio knowledge bases. Just follow these simple steps:
Create a bucket: Go to the OSS console and create an OSS Bucket to store your original files.
Create a knowledge base: Create an unstructured knowledge base to store private knowledge content.
Create a user-defined function: Go to the FC console and create a function for file change events, such as file creation and deletion. For more information, see Create a function. These functions synchronize file changes in OSS to the created knowledge base by calling the relevant APIs from the Knowledge base API guide.
Create an OSS trigger: In FC, associate an OSS trigger with the user-defined function that you created in the previous step. When a file change event is detected (for example, when a new file is uploaded to OSS), the corresponding trigger is activated, which triggers FC to execute the corresponding function.
Manual update
On the Knowledge base page, find the target knowledge base, and click View Details on its card.
How to add a new file: Click Upload Data and select the existing files in the application data. For more information, see How to upload files to application data.
How to delete a file: Find the target file and click Delete on its right.
This operation only removes the file from the knowledge base and does not delete the source file in Application Data.
How to modify file content: In-place updates and overwriting file uploads are not supported. You must first delete the old version of the file from the knowledge base and then re-import the new, modified version.
Note: Keeping the old version of the file may lead to outdated content being retrieved and recalled.
Data Query and Image Q&A knowledge bases
Automatic update
Not supported.
Manual update
When the data source of a knowledge base is a data table in Application Data, it can only be updated manually. The process involves two steps.
Step 1: Update the data table
Go to the Application Data tab. In the list on the left, select the target data table, and click Import Data.
How to insert new data: Set Import Type to Incremental Upload. You need to upload an Excel file that only contains the table header and the new data rows.
The file's header must match the current table schema. You can use the Download Template feature on the page to obtain a standard header file and fill in the new data directly.
How to delete data: Set Import Type to Upload and Overwrite. You need to upload an Excel file that contains the header and the latest full data (with the records to be deleted removed).
How to obtain the full data: Click the
 icon on the page to download the data in XLSX format.
icon on the page to download the data in XLSX format.How to modify data: Set Import Type to Upload and Overwrite. You need to upload an Excel file that contains the header and the latest full data (including the corresponding modifications).
Step 2: Synchronize changes to the knowledge base
Return to the Knowledge Base list, find the target knowledge base, and click View Details on its card. Click the
 icon at the top left of the data table. After you confirm the operation, the latest content of the data table is synced to the knowledge base.
icon at the top left of the data table. After you confirm the operation, the latest content of the data table is synced to the knowledge base.You still need to manually repeat the above steps after each subsequent update. Data changes cannot be automatically synchronized for knowledge bases that use "Application Data" as the data source.
Edit a knowledge base
After a knowledge base is created, you can only modify the Knowledge Base Name, Knowledge Base Description, and Similarity Threshold. Other configurations cannot be changed. Editing a knowledge base using an API is not supported.
Procedure: On the Knowledge Base page, find the target knowledge base, click the ![]() icon on its card, and then click Edit.
icon on its card, and then click Edit.
Delete a knowledge base
This operation does not delete the source files or data tables in Application Data.
This operation is irreversible. Please proceed with caution.
Before you can delete a knowledge base, you must first disassociate it from all published applications.
Associated unpublished applications will not block the delete operation.
For each published application associated with the knowledge base, perform the following operations:
On the My Applications page, find the application associated with the knowledge base, and click Configure.
Remove the knowledge base from the knowledge base list. Click Publish in the upper-right corner of the page and follow the instructions to republish the application.
Repeat the above steps for all published applications associated with the knowledge base.
On the Knowledge Base page, find the target knowledge base, click the
 icon on the card, and then click Delete.
icon on the card, and then click Delete.
Hit testing
Imagine that you have built a knowledge base, but you find that in actual use, the AI application often provides irrelevant answers or fails to find information that exists in the knowledge base. Hit testing is a key tool that helps you identify and resolve these issues proactively.
With hit testing, you can:
Verify whether the knowledge base can provide effective knowledge input for the AI application.
Fine-tune the similarity threshold to balance recall rate and accuracy.
Discover content gaps or quality issues in the knowledge base.
Scenario examples
Scenario 1: Customer inquires about product price
Test input: "How much is your Bailian phone?" Expected result: Should be able to retrieve relevant text segments containing price information.Scenario 2: Troubleshooting a technical issue
Test input: "What should I do if my device can't connect to WiFi?" Expected result: Should be able to retrieve relevant text segments about WiFi connection troubleshooting.
Procedure
On the Knowledge Base page, find the target knowledge base, and click Hit Test on its card.
Enter a question in the test interface (we recommend collecting frequently asked user questions in advance) and observe the retrieval results.
Retrieval result: The hit result for this test keyword (sorted by similarity in descending order). Click any segment to view its specific content.
 Icon: For a Image Q&A knowledge base, the system first converts the input image into a vector and retrieves relevant records. Then, it sends these records along with the question to the LLM to generate an answer. For Document Search or Data Query knowledge bases, the uploaded image does not participate in the retrieval.
Icon: For a Image Q&A knowledge base, the system first converts the input image into a vector and retrieves relevant records. Then, it sends these records along with the question to the LLM to generate an answer. For Document Search or Data Query knowledge bases, the uploaded image does not participate in the retrieval.
Confirm whether the relevant text segments are correctly retrieved. If not, you need to adjust the similarity threshold and repeat the previous step.
Click View Historical Retrieval Records to compare the retrieval performance under different past threshold settings.

Quotas and limits
For information about the data sources and capacity supported by a knowledge base, see Knowledge base quotas and limits.
Each application can be associated with a maximum of 5 Document Search knowledge bases, 5 Data Query knowledge bases, and 1 Image Q&A knowledge base.
Billing
The knowledge base feature is free of charge, but you may incur fees when you call an application that references a knowledge base.
Step | Billing information | |
Free of charge. | ||
When you call an application, text segments retrieved from the knowledge base increase the number of input tokens for the LLM. This may lead to an increase in model inference (call) costs. For details about model inference (call) costs, see Billable items. Note: If you only retrieve from a specified knowledge base by calling the Retrieve API and do not use an application for generation, you will not be charged. | ||
Free of charge. | ||
API reference
For the latest complete list of knowledge base APIs and their input and output parameters, see API references (knowledge base).
For specific usage instructions and code examples for the related APIs, see Knowledge base API guide.
FAQ
Building a knowledge base
Handling images and multimodal content
Use a Document Search knowledge base
When you create a knowledge base, for Knowledge base type, select Document Search, and for Scenario, select With Illustrations.
The knowledge base extracts summaries from the file's illustrations. The LLM autonomously decides whether to insert images based on the relevance of the summary to the question.

When you create or edit an agent application, select the Qwen-Plus or Qwen-Plus-Latest model (these two have been tested to have the best performance). Click the + button to the right of Document and add the knowledge base that you created in the previous step.
Note: The "With illustrations" and "Show source" features cannot be enabled at the same time.
Actual Q&A effect:
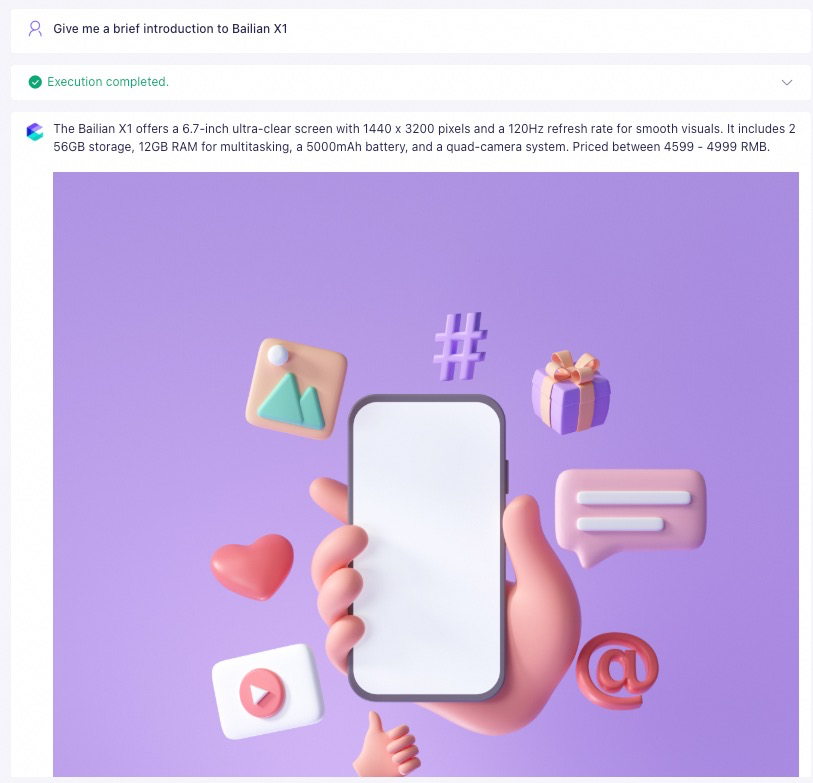
Upload an image to a publicly accessible location and obtain its complete URL. We recommend that you use OSS. For more information, see Upload an image to OSS and use its file URL.
Insert the full URL (relative paths are not supported) into the file. Please note: Directly embedding image files in the document is not supported (for example, by copying and pasting or inserting a local image from the menu). You must use a publicly accessible URL to reference the image.
If you have followed the instructions but the image still does not display, check if the URL in the text segment is complete. Confirm if there are any extra spaces or special characters, which might be misinterpreted by the system. If there are issues, you can edit and correct them directly.
Example of correctly referencing an image in a file
Sample prompt template
Actual Q&A effect

# Knowledge Base Please remember the following materials, they may be helpful for answering questions. ${documents} # Requirements If there are images, please display them.Example of incorrectly referencing an image in a file
Sample prompt template
Actual Q&A effect

# Knowledge Base Please remember the following materials, they may be helpful for answering questions. ${documents} # Requirements If there are images, please display them.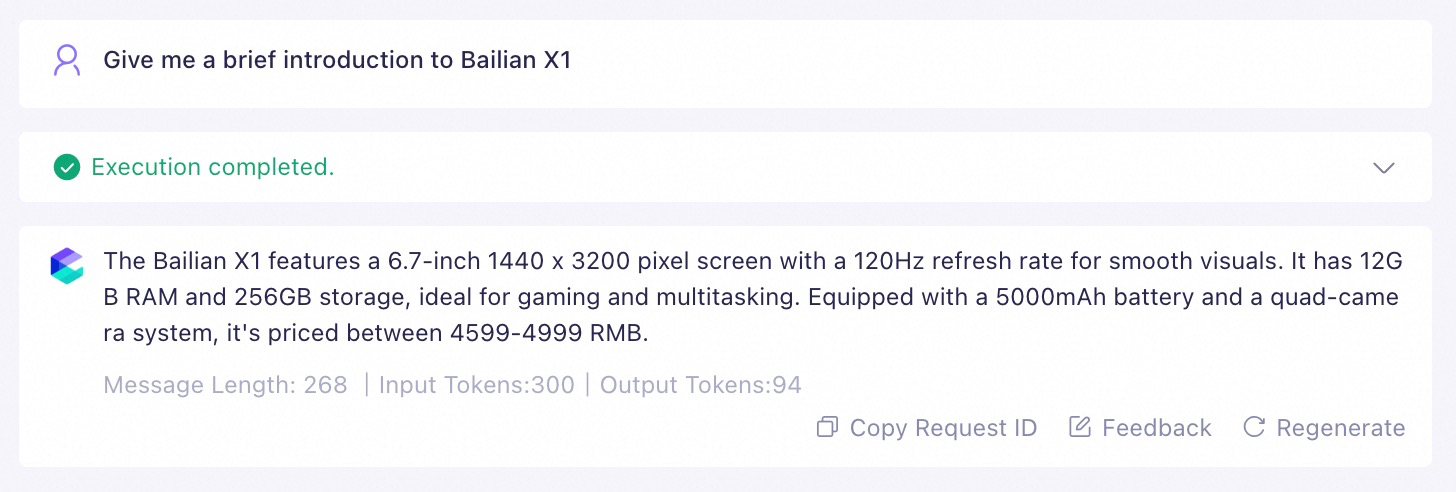
Explanation: When an image is inserted directly into a file, the application will not display the image in its response.
Use a Image Q&A knowledge base
Upload an image to a location that is accessible over the internet and obtain its full URL. We recommend that you use OSS. For detailed instructions, see Upload an image to OSS and use its file URL.
On the Table tab, create a new data table and add an image_url field to store the complete URL of an image.
NoteThe image_url field does not support relative paths.
A single image_url field does not support storing multiple image URLs. If a single record needs to be associated with multiple images, you must create a separate
image_urlfield for each image, such asimage_1andimage_2.The current version does not support storing multiple image URLs in a single field.
Ensure that the size of the image file pointed to by each image_url in the data table does not exceed 3 MB. Exceeding the limit causes the knowledge base creation to fail.
After a data table is created, you can no longer add or modify fields of type image_url. Please reserve all potentially needed image fields when you initially design the table schema.

When you build a knowledge base, select Image Q&A as the Knowledge Base Type.
When you create or edit an agent application, click the + button to the right of Image (Image Q&A knowledge base) and add the knowledge base that you created in the previous step. Change the prompt template to:
# Knowledge Base Please remember the following materials, they may be helpful for answering questions. ${documents} # Requirements If there are images, please display them.Next, ask a question in the input box on the right.
For example: "Briefly introduce the Model Studio X1 phone."
Example of correctly referencing an image
Sample prompt template
User prompt and the result returned by the application

# Knowledge Base Please remember the following materials, they may be helpful for answering questions. ${documents} # Requirements If there are images, please display them.