PyODPS is an SDK for Python of MaxCompute. PyODPS provides a simple and convenient Python programming interface. This way, you can use Python to write code for MaxCompute jobs, query MaxCompute tables and views, and manage MaxCompute resources. PyODPS provides features that are similar to the features of the MaxCompute CLI tool. For example, you can use PyODPS to upload and download files, create tables, and execute MaxCompute SQL statements to query data. PyODPS also provides specific advanced features. For example, you can use PyODPS to commit MapReduce tasks and run MaxCompute user-defined functions (UDFs). This topic describes the use scenarios and supported platforms of PyODPS and the precautions when you use PyODPS.
Scenarios
For more information about the use scenarios of PyODPS, see the following topics:
Supported platforms
PyODPS can run in an on-premises environment, DataWorks, and Machine Learning Platform for AI (PAI) Notebooks.
To prevent an out of memory (OOM) error caused by the consumption of a large amount of memory, we recommend that you do not download full data to your on-premises machine for data processing, regardless of which type of platform is used to run the PyODPS nodes. We recommend that you commit computing tasks to MaxCompute for distributed execution. For more information about the comparison between the data processing methods, see Precautions in this topic.
On-premises environment: You can install and use PyODPS in an on-premises environment. For more information, see Use PyODPS in an on-premises environment.
DataWorks: PyODPS is installed on PyODPS nodes in DataWorks. You can develop PyODPS nodes in the DataWorks console and run the nodes at regular intervals. For more information, see Use PyODPS in DataWorks.
PAI Notebooks: You can also install and run PyODPS in the Python environment of PAI. PyODPS is installed in the built-in images of PAI, such as the custom Python component of Machine Learning Designer, and can be directly used. In PAI Notebooks, you can perform basic operations related to PyODPS. For more information, see Overview of basic operations and Overview of DataFrame.
Precautions
Do not download full data to your on-premises machine and run PyODPS. PyODPS is an SDK and can run on various clients, such as a PC, DataWorks (PyODPS nodes in DataStudio), and PAI Notebooks. 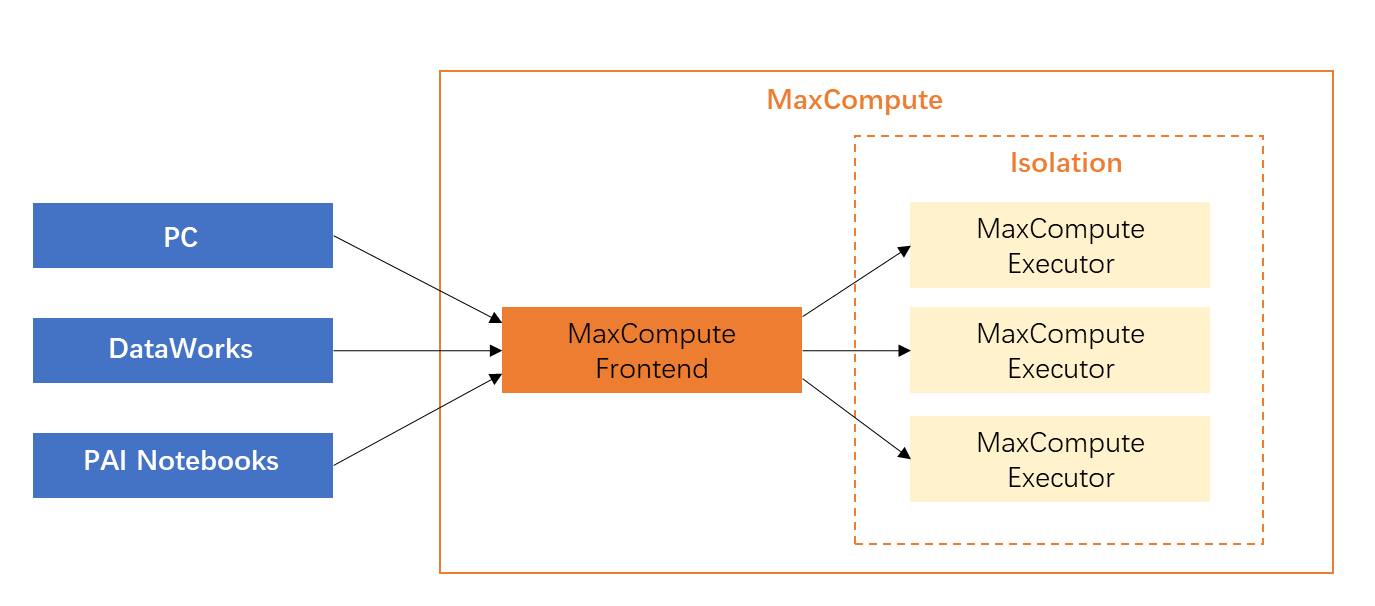 PyODPS allows you to download data to an on-premises machine by using different methods. For example, you can use Tunnel commands, the execute command, or the to_pandas method to download data. Therefore, multiple users who initially use PyODPS attempt to download data to an on-premises machine and upload the data to MaxCompute after the data is processed. In most cases, this data processing method is inefficient and does not take advantage of the large-scale parallel computing capability of MaxCompute.
PyODPS allows you to download data to an on-premises machine by using different methods. For example, you can use Tunnel commands, the execute command, or the to_pandas method to download data. Therefore, multiple users who initially use PyODPS attempt to download data to an on-premises machine and upload the data to MaxCompute after the data is processed. In most cases, this data processing method is inefficient and does not take advantage of the large-scale parallel computing capability of MaxCompute.
Data processing method | Description | Scenario |
Download data to an on-premises machine for processing (This method is not recommended because an OOM error may occur.) | For example, a PyODPS node in DataWorks has a built-in PyODPS package and the required Python environment. The PyODPS node works as a client runtime container that has limited resources. The PyODPS node does not use the computing resources of MaxCompute and has limits on the memory. | PyODPS provides the |
Commit computing tasks to MaxCompute for distributed execution (recommended) | We recommend that you use the Distributed DataFrame (DDF) feature of PyODPS. This feature can commit major computing tasks to MaxCompute for distributed execution, instead of downloading and processing data on the client on which a PyODPS node runs. This is the key to the effective use of PyODPS. Note If you want to convert the SQL execution results into a DataFrame, you must first execute the
| We recommend that you call the PyODPS DataFrame interface to process data. In most cases, if you want to process each row of data in a table and write the data back to the table, or split a row of data into multiple rows, you can use the After the PyODPS DataFrame interface is called, all commands that use this interface are translated into SQL statements and committed to a MaxCompute computing cluster for distributed computing. This way, almost no memory on the on-premises machine is consumed and the performance is significantly improved compared with data computing on a single machine. |
The following example compares the code of the two data processing methods for tokenization.
Scenario
You want to extract specific information by analyzing the log strings that are generated every day. A table that contains only one column exists and the column is of the STRING data type. You can segment Chinese text based on jieba and find the desired keywords to store the keywords in the information table.
Sample code of inefficient data processing
import jieba t = o.get_table('word_split') out = [] with t.open_reader() as reader: for r in reader: words = list(jieba.cut(r[0])) # # The processing logic of the code segment is to generate processed_data. # out.append(processed_data) out_t = o.get_table('words') with out_t.open_writer() as writer: writer.write(out)The logic of data processing on a single machine is to read data row by row, process data row by row, and then write data to the destination table row by row. During the process, a long period of time is consumed to download and upload data, and a large amount of memory is required on the machine that runs the script to process all data. For users who use DataWorks nodes, OOM errors are most likely to occur because the required memory exceeds the default allocated memory.
Sample code of efficient data processing
from odps.df import output out_table = o.get_table('words') df = o.get_table('word_split').to_df() # Assume that the following fields and the related data types need to be returned. out_names = ["word", "count"] out_types = ["string", "int"] @output(out_names, out_types) def handle(row): import jieba words = list(jieba.cut(row[0])) # # The processing logic of the code segment is to generate processed_data. # yield processed_data df.apply(handle, axis=1).persist(out_table.name)Use the apply method to perform distributed execution.
The complex logic is included in the handle function. This function is automatically serialized to the machine and is used as a user-defined function (UDF). This function is called and run on the machine. When the handle function is run on the machine, data is also processed row by row. The logic is the same as the logic of data processing on a single machine. However, after the program that is written in this method is committed to MaxCompute, multiple machines process data at the same time. This reduces the time that is required to process data.
When the persist interface is called, the generated data is directly written to another MaxCompute table. All data is generated and consumed in the MaxCompute cluster. This also reduces the consumption of network and memory resources on the on-premises machine.
MaxCompute supports third-party packages in UDFs. In this example, the third-party package
jiebais used. Therefore, you do not need to worry about the cost of code changes. You can use the large-scale computing capabilities of MaxCompute without the need to modify the main logic.
Limits
MaxCompute has limits on SQL statements. For more information, see MaxCompute SQL limits.
PyODPS nodes in DataWorks have limits. For more information, see Use PyODPS in DataWorks.
Due to the limits of the sandbox, specific programs that are locally debugged by using the pandas computing backend cannot be debugged in MaxCompute.