Creates a materialized view that supports clustering or partitioning based on the data for materialized view scenarios.
Background information
A view is a stored query accessible as a virtual table. Each time you query a view, the query statement is converted into the SQL statement that is used to define the view. A materialized view is a special physical table that occupies storage resources to store real data. For more information about the billing rules of materialized views, see the Billing rules section in this topic.
Materialized views are suitable for the following queries:
Queries that are in a fixed mode and are frequently executed
Queries that involve time-consuming operations, such as JOIN or AGGREGATE
Queries that involve only a small portion of data in a table
The following table compares traditional queries and queries based on materialized views.
Comparison item | Traditional query | Query based on a materialized view |
Query statements | SQL statements are used to query data. | Data is queried based on the materialized view that you created. Statement that is used to create a materialized view: Statement that is used to query data based on the materialized view that you created: If the query rewrite feature is enabled for the materialized view, data is directly obtained from the query result that is contained in the materialized view when you execute the first SQL statement in the following code: |
Query characteristics | Queries involve table reading, JOIN, and filter (WHERE clause) operations. If the source table contains a large amount of data, the query speed is slow. The query operation is complex and the query efficiency is low. | Queries involve table reading and filter operations. JOIN operations are not involved. MaxCompute automatically matches the optimal materialized view and reads data from the optimal materialized view. This greatly improves query efficiency. |
Billing rules
When you use materialized views, you are charged for the following items:
Storage
Materialized views occupy physical storage space. You are charged for the physical storage space that is occupied by materialized views. For more information about storage pricing, see Storage pricing (pay-as-you-go).
Computing
Data is queried when you create, update, and query materialized views, and rewrite queries (if materialized views are valid). These operations consume computing resources and generate computing costs.
If your MaxCompute project uses the subscription billing method, no extra computing costs are generated.
If your MaxCompute project uses the pay-as-you-go billing method, fees are calculated based on the SQL complexity and the amount of input data. For more information about billing, see the "Billing for standard SQL jobs" section in Computing pricing. Take note of the following points:
The SQL statements used to update a materialized view are the same as the SQL statements used to create a materialized view. If the project to which the materialized view belongs is bound to a subscription resource group, the purchased subscription resources are used, and no additional fees are generated. If the project is bound to a pay-as-you-go resource group, the fees vary based on the amount of input data and complexity of the SQL statements. After you update a materialized view, you are charged storage fees based on the storage space that is used.
If the materialized view is valid, data is read from the materialized view when the query rewrite operation is performed. The amount of input data that is read from the materialized view of the query statement is related to the materialized view and is irrelevant to the source table of the materialized view. If the materialized view is invalid, the query rewrite operation cannot be performed, and data is queried from the source table. The amount of input data for the query statement is related to the source table. For more information about how to query the status of a materialized view, see Query the status of a materialized view in this topic.
Data bloat may occur if a materialized view is generated based on the association of multiple tables. Therefore, the amount of data read by a materialized view may not be absolutely less than the amount of data in the source table. MaxCompute cannot ensure that data reading from a materialized view costs less than data reading from the source table.
Limits
Before you use materialized views, take note of the following limits:
Window functions are not supported.
User-defined table-valued functions (UDTFs) are not supported.
By default, non-deterministic functions, such as user-defined scalar functions (UDFs) and user-defined aggregate functions (UDAFs), are not supported. If you must use non-deterministic functions, run the
set odps.sql.materialized.view.support.nondeterministic.function=true;command at the session level.
Precautions
If the query statement based on which you create a materialized view fails to be executed, you cannot create the materialized view.
Partition key columns in a materialized view must be derived from a source table. The sequence and number of the columns in the materialized view must be the same as the sequence and number of the columns in the source table. Column names can be different.
You must specify comments for all columns, including partition key columns. If you specify comments only for some columns, an error is returned.
You can specify both the partitioning and clustering attributes for a materialized view. In this case, the data in each partition has the specified clustering attribute.
If the query statement based on which you create a materialized view contains operators that are not supported by the materialized view, an error is returned. For more information about the operators that are supported by materialized views, see Perform a query rewrite operation based on a materialized view.
By default, MaxCompute does not allow you to create materialized views by using non-deterministic functions, such as UDFs or UDAFs. If you must use non-deterministic functions based on your business requirements, run the
set odps.sql.materialized.view.support.nondeterministic.function=true;command at the session level.If the source table of a materialized view contains an empty partition, you can refresh the materialized view to generate an empty partition in the materialized view.
Syntax
CREATE MATERIALIZED VIEW [IF NOT EXISTS][project_name.]<mv_name>
[LIFECYCLE <days>] -- The lifecycle of the materialized view.
[BUILD DEFERRED] -- Specifies that only the schema is created and no data is updated when you create the materialized view.
[(<col_name> [COMMENT <col_comment>],...)] -- The column comments.
[DISABLE REWRITE] -- Specifies whether to disable the query rewrite operation that is performed based on the materialized view.
[COMMENT 'table comment'] -- The materialized view comments.
[PARTITIONED BY (<col_name> [, <col_name>, ...]) -- The partitions in the materialized view. This parameter is required when you create a partitioned materialized view.
[CLUSTERED BY|RANGE CLUSTERED BY (<col_name> [, <col_name>, ...])
[SORTED BY (<col_name> [ASC | DESC] [, <col_name> [ASC | DESC] ...])]
INTO <number_of_buckets> BUCKETS] -- The shuffle and sort attributes of the materialized view. This parameter is required when you create a clustered materialized view.
[REFRESH EVERY <num> MINUTES/HOURS/DAYS]
[TBLPROPERTIES("compressionstrategy"="normal/high/extreme", -- The compression policy for data storage of the materialized view.
"enable_auto_substitute"="true", -- Specifies whether to query data from the source partitioned table if the partition data that you want to query is not contained in the materialized view.
"enable_auto_refresh"="true", -- Specifies whether to enable the scheduled update feature.
"refresh_interval_minutes"="120", -- The update interval.
"only_refresh_max_pt"="true" -- Specifies whether to automatically update the latest partition data in the source table to the materialized view.
)]
AS <select_statement>;Parameters
Parameter | Required | Description |
IF NOT EXISTS | No | If you do not specify IF NOT EXISTS and the materialized view already exists, an error is returned. |
project_name | No | The name of the MaxCompute project to which the materialized view belongs. If you do not configure this parameter, the current MaxCompute project is used. To view the name of a MaxCompute project, perform the following steps: Log on to the MaxCompute console. In the top navigation bar, select a region. View the name of the MaxCompute project on the Projects page. |
mv_name | Yes | The name of the materialized view that you want to create. |
days | No | The lifecycle of the materialized view that you want to create. Unit: days. Valid values: 1 to 37231. |
BUILD DEFERRED | No | If this keyword is added, only the schema is created and the data is not updated when you create the materialized view. |
col_name | No | The name of a column in the materialized view that you want to create. |
col_comment | No | The comment on a column in the materialized view that you want to create. |
DISABLE REWRITE | No | Specifies whether to disable the query rewrite operation that is performed based on this materialized view. If you do not configure this parameter, the query rewrite operation based on this materialized view is allowed. In this case, you can execute the |
PARTITIONED BY | No | The partition key columns in the materialized view that you want to create. If you want to create a partitioned materialized view, you must configure this parameter. |
CLUSTERED BY|RANGE CLUSTERED BY | No | The shuffle attribute of the materialized view that you want to create. If you want to create a clustered materialized view, you must specify the clustered by or range clustered by parameter. |
SORTED BY | No | The sort attribute of the materialized view that you want to create. If you want to create a clustered materialized view, you must configure this parameter. |
REFRESH EVERY | No | Configure the scheduled update interval for materialized views. Available units are minutes, hours, or days. |
number_of_buckets | No | The number of buckets in the materialized view that you want to create. If you want to create a clustered materialized view, you must specify this parameter. |
TBLPROPERTIES | No |
|
select_statement | Yes | The SELECT statement. For more information about the syntax of the SELECT statement, see SELECT syntax. |
Examples
Create a materialized view
Create tables named
mf_tandmf_t1and insert data into the tables.CREATE TABLE IF NOT EXISTS mf_t( id bigint, value bigint, name string) PARTITIONED BY (ds STRING); ALTER TABLE mf_t ADD PARTITION (ds='1'); INSERT INTO mf_t PARTITION (ds='1') VALUES (1,10,'kyle'),(2,20,'xia'); SELECT * FROM mf_t WHERE ds ='1'; -- The following result is returned: +------------+------------+------------+------------+ | id | value | name | ds | +------------+------------+------------+------------+ | 1 | 10 | kyle | 1 | | 2 | 20 | xia | 1 | +------------+------------+------------+------------+ CREATE TABLE IF NOT EXISTS mf_t1( id bigint, value bigint, name string) PARTITIONED BY (ds STRING); ALTER TABLE mf_t1 ADD PARTITION (ds='1'); INSERT INTO mf_t1 PARTITION (ds='1') VALUES (1,10,'kyle'),(3,20,'john'); SELECT * FROM mf_t1 WHERE ds ='1'; -- The following result is returned: +------------+------------+------------+------------+ | id | value | name | ds | +------------+------------+------------+------------+ | 1 | 10 | kyle | 1 | | 3 | 20 | john | 1 | +------------+------------+------------+------------+Create a materialized view.
Sample 1: Create a materialized view that contains a partition key column named ds.
CREATE MATERIALIZED VIEW mf_mv LIFECYCLE 7 ( key comment 'unique id', value comment 'input value', ds comment 'partitiion' ) PARTITIONED BY (ds) AS SELECT t1.id AS key, t1.value AS value, t1.ds AS ds FROM mf_t AS t1 JOIN mf_t1 AS t2 ON t1.id = t2.id AND t1.ds=t2.ds AND t1.ds='1'; -- Query data from the created materialized view. SELECT * FROM mf_mv WHERE ds =1; +------------+------------+------------+ | key | value | ds | +------------+------------+------------+ | 1 | 10 | 1 | +------------+------------+------------+Sample 2: Create a non-partitioned materialized view that is clustered.
CREATE MATERIALIZED VIEW mf_mv2 LIFECYCLE 7 CLUSTERED BY (key) SORTED BY (value) INTO 1024 buckets AS SELECT t1.id AS key, t1.value AS value, t1.ds AS ds FROM mf_t AS t1 JOIN mf_t1 AS t2 ON t1.id = t2.id AND t1.ds=t2.ds AND t1.ds='1';Sample 3: Create a partitioned materialized view that is clustered.
CREATE MATERIALIZED VIEW mf_mv3 LIFECYCLE 7 PARTITIONED BY (ds) CLUSTERED BY (key) SORTED BY (value) INTO 1024 buckets AS SELECT t1.id AS key, t1.value AS value, t1.ds AS ds FROM mf_t AS t1 JOIN mf_t1 AS t2 ON t1.id = t2.id AND t1.ds=t2.ds AND t1.ds='1';
Implement query rewrite based on a materialized view
You have a page access table named visit_records, which logs each user's page ID, user ID, and access time. Users frequently analyze the traffic of different pages. The structure of visit_records is as follows:
+------------------------------------------------------------------------------------+
| Field | Type | Label | Comment |
+------------------------------------------------------------------------------------+
| page_id | string | | |
| user_id | string | | |
| visit_time | string | | |
+------------------------------------------------------------------------------------+To facilitate analysis, create a materialized view for the visit_records table that groups by page ID and counts the visits per page. Then, perform query operations based on the materialized view.
Create a materialized view with the following statement:
CREATE MATERIALIZED VIEW count_mv AS SELECT page_id, count(*) FROM visit_records GROUP BY page_id;Execute the query statement as follows:
SET odps.sql.materialized.view.enable.auto.rewriting=true; SELECT page_id, count(*) FROM visit_records GROUP BY page_id;When this query is run, MaxCompute automatically matches the materialized view count_mv and retrieves the aggregated data from it.
Verify whether the query statements match the materialized view by using the following command:
EXPLAIN SELECT page_id, count(*) FROM visit_records GROUP BY page_id;The result is as follows:
job0 is root job In Job job0: root Tasks: M1 In Task M1: Data source: doc_test_dev.count_mv TS: doc_test_dev.count_mv FS: output: Screen schema: page_id (string) _c1 (bigint) OKThe Data source in the result indicates that the query reads from the table count_mv of the doc_test_dev project, confirming the validity of the materialized view and successful query rewrite.
Perform a query rewrite operation based on a materialized view
The most important feature of materialized views is to perform query rewrite operations on query statements. To perform query rewrite operations on a query statement based on a materialized view, you must add set odps.sql.materialized.view.enable.auto.rewriting=true; before the query statement. If a materialized view is invalid, the materialized view cannot be used for query rewrite operations. In this case, data is queried from the source table, and the query speed is not accelerated.
By default, a MaxCompute project can use only its own materialized views for query rewrite operations. If you need to perform query rewrite operations on query statements based on the materialized views of other MaxCompute projects, you must add set odps.sql.materialized.view.source.project.white.list=<project_name1>,<project_name2>,<project_name3>; before the query statements to specify the MaxCompute projects.
The following table shows the supported operator types for query rewriting of materialized views in MaxCompute, along with their corresponding relationships with other products:
Operator type | Classification | MaxCompute | BigQuery | Amazon RedShift | Hive |
FILTER | Expression full match | Supported | Supported | Supported | Supported |
Expression partial match | Supported | Supported | Supported | Supported | |
AGGREGATE | Single AGGREGATE | Supported | Supported | Supported | Supported |
Multiple AGGREGATE | Not supported | Not supported | Not supported | Not supported | |
JOIN | JOIN type | INNER JOIN | Not supported | INNER JOIN | INNER JOIN |
Single JOIN | Supported | Not supported | Supported | Supported | |
Multiple JOIN | Supported | Not supported | Supported | Supported | |
AGGREGATE+JOIN | - | Supported | Not supported | Supported | Supported |
The query rewrite operations based on a materialized view require that the data in a query statement be obtained from the materialized view. The data includes output columns, the columns required by filter operations, the columns required by aggregate functions, and the columns required by JOIN operations. If the columns that are required in the query statement are not included in the materialized view or are not supported by the aggregate functions, you cannot perform query rewrite operations based on the materialized view.
Rewrite query statements with filter conditions
Create a materialized view with the following statement:
CREATE MATERIALIZED VIEW mv AS SELECT a,b,c FROM src WHERE a>5;The following table shows the comparison between the original query statement and the rewritten query statement for executing queries based on the created materialized view:
Original query statement
Rewritten query statement
SELECT a,b FROM src WHERE a>5;SELECT a,b FROM mv;SELECT a, b FROM src WHERE a=10;SELECT a,b FROM mv WHERE a=10;SELECT a, b FROM src WHERE a=10 AND b=3;SELECT a,b FROM mv WHERE a=10 AND b=3;SELECT a, b FROM src WHERE a>3;(SELECT a,b FROM src WHERE a>3 AND a<=5) UNION (SELECT a,b FROM mv);SELECT a, b FROM src WHERE a=10 AND d=4;Rewriting failed because the materialized view does not have column d.
SELECT d, e FROM src WHERE a=10;Rewriting failed because the materialized view does not have columns d and e.
SELECT a, b FROM src WHERE a=1;Rewriting failed because the materialized view does not have data where a=1.
Rewrite query statements with aggregate functions
Rewriting is supported if the SQL statement of the materialized view and the query statement have the same aggregation keys. If the aggregation keys differ, only SUM, MIN, and MAX are supported.
Create a materialized view with the following statement:
CREATE MATERIALIZED VIEW mv AS SELECT a, b, sum(c) AS sum, count(d) AS cnt FROM src GROUP BY a, b;The following table shows the comparison between the original query statement and the rewritten query statement for executing queries based on the created materialized view:
Original query statement
Rewritten query statement
SELECT a, sum(c) FROM src GROUP BY a;SELECT a, sum(sum) FROM mv GROUP BY a;SELECT a, count(d) FROM src GROUP BY a, b;SELECT a, cnt FROM mv;SELECT a, count(b) FROM (SELECT a, b FROM src GROUP BY a, b) GROUP BY a;SELECT a,count(b) FROM mv GROUP BY a;SELECT a,count(b) FROM mv GROUP BY a;Rewriting failed because the view has already performed aggregation on columns a and b, and thus cannot aggregate b again.
SELECT a, count(c) FROM src GROUP BY a;Rewriting failed because re-aggregation is not supported for the COUNT function.
When the aggregate function includes DISTINCT, rewriting is supported if the SQL statement of the materialized view and the query statement have the same aggregation keys. Otherwise, rewriting is not supported.
Create a materialized view with the following statement:
CREATE MATERIALIZED VIEW mv AS SELECT a, b, sum(DISTINCT c) AS sum, count(DISTINCT d) AS cnt FROM src GROUP BY a, b;The following table shows the comparison between the original query statement and the rewritten query statement for executing queries based on the created materialized view:
Original Query Statement
Revised Query Statement
SELECT a, count(DISTINCT d) FROM src GROUP BY a, b;SELECT a, cnt FROM mv;SELECT a, count(c) FROM src GROUP BY a, b;Rewrite failed because re-aggregation is not supported for the COUNT function.
SELECT a, count(DISTINCT c) FROM src GROUP BY a;Rewrite failed because additional aggregation on a is required.
Rewrite query statements with JOIN
Rewrite JOIN input
Create materialized views with the following statement:
CREATE MATERIALIZED VIEW mv1 AS SELECT a, b FROM j1 WHERE b > 10; CREATE MATERIALIZED VIEW mv2 AS SELECT a, b FROM j2 WHERE b > 10;The following table shows the comparison between the original query statement and the rewritten query statement for executing queries based on the created materialized view:
Original query statement
Rewritten query statement
SELECT j1.a,j1.b,j2.a FROM (SELECT a,b FROM j1 WHERE b > 10) j1 JOIN j2 ON j1.a=j2.a;SELECT mv1.a, mv1.b, j2.a FROM mv1 JOIN j2 ON mv1.a=j2.a;SELECT j1.a,j1.b,j2.a FROM (SELECT a,b FROM j1 WHERE b > 10) j1 JOIN (SELECT a,b FROM j2 WHERE b > 10) j2 ON j1.a=j2.a;SELECT mv1.a,mv1.b,mv2.a FROM mv1 JOIN mv2 ON mv1.a=mv2.a;
JOIN with filter conditions
Create materialized views with the following statement:
--Create a non-partitioned materialized view. CREATE MATERIALIZED VIEW mv1 AS SELECT j1.a, j1.b FROM j1 JOIN j2 ON j1.a=j2.a; CREATE MATERIALIZED VIEW mv2 AS SELECT j1.a, j1.b FROM j1 JOIN j2 ON j1.a=j2.a WHERE j1.a > 10; --Create a partitioned materialized view. CREATE MATERIALIZED VIEW mv LIFECYCLE 7 PARTITIONED BY (ds) AS SELECT t1.id, t1.ds AS ds FROM t1 JOIN t2 ON t1.id = t2.id;The following table shows the comparison between the original query statement and the rewritten query statement for executing queries based on the created materialized view:
Original query statement
Rewritten query statement
SELECT j1.a,j1.b FROM j1 JOIN j2 ON j1.a=j2.a WHERE j1.a=4;SELECT a, b FROM mv1 WHERE a=4;SELECT j1.a,j1.b FROM j1 JOIN j2 ON j1.a=j2.a WHERE j1.a > 20;SELECT a,b FROM mv2 WHERE a>20;SELECT j1.a,j1.b FROM j1 JOIN j2 ON j1.a=j2.a WHERE j1.a > 5;(SELECT j1.a,j1.b FROM j1 JOIN j2 ON j1.a=j2.a WHERE j1.a > 5 AND j1.a <= 10) UNION SELECT * FROM mv2;SELECT key FROM t1 JOIN t2 ON t1.id= t2.id WHERE t1.ds='20210306';SELECT key FROM mv WHERE ds='20210306';SELECT key FROM t1 JOIN t2 ON t1.id= t2.id WHERE t1.ds>='20210306';SELECT key FROM mv WHERE ds>='20210306';SELECT j1.a,j1.b FROM j1 JOIN j2 ON j1.a=j2.a WHERE j2.a=4;Rewriting failed because the materialized view does not have the column j2.a.
JOIN with additional tables
Create a materialized view with the following statement:
CREATE MATERIALIZED VIEW mv AS SELECT j1.a, j1.b FROM j1 JOIN j2 ON j1.a=j2.a;The following table shows the comparison between the original query statement and the rewritten query statement for executing queries based on the created materialized view:
Original query statement
Rewritten query statement
SELECT j1.a, j1.b FROM j1 JOIN j2 JOIN j3 ON j1.a=j2.a AND j1.a=j3.a;SELECT mv.a, mv.b FROM mv JOIN j3 ON mv.a=j3.a;SELECT j1.a, j1.b FROM j1 JOIN j2 JOIN j3 ON j1.a=j2.a AND j2.a=j3.a;SELECT mv.a, mv.b FROM mv JOIN j3 ON mv.a=j3.a;
The three types of statements above can be combined. If the query statement meets the conditions for rewriting, it can be rewritten accordingly.
MaxCompute selects the most efficient rewriting rule for execution. If post-rewriting operations do not result in an optimal execution plan, the rewriting rule will not be chosen.
Rewrite query statements with LEFT JOIN
Create a materialized view with the following statement:
CREATE MATERIALIZED VIEW mv LIFECYCLE 7( user_id, job, total_amount ) AS SELECT t1.user_id, t1.job, sum(t2.order_amount) AS total_amount FROM user_info AS t1 LEFT JOIN sale_order AS t2 ON t1.user_id=t2.user_id GROUP BY t1.user_id;The following table shows the comparison between the original query statement and the rewritten query statement for executing queries based on the created materialized view:
Original query statement
Rewritten query statement
SELECT t1.user_id, sum(t2.order_amount) AS total_amount FROM user_info AS t1 LEFT JOIN sale_order AS t2 ON t1.user_id=t2.user_id GROUP BY t1.user_id;SELECT user_id, total_amount FROM mv;
Rewrite query statements with UNION ALL
Create a materialized view with the following statement:
CREATE MATERIALIZED VIEW mv LIFECYCLE 7( user_id, tran_amount, tran_date ) AS SELECT user_id, tran_amount, tran_date FROM alipay_tran UNION ALL SELECT user_id, tran_amount, tran_date FROM unionpay_tran;The following table shows the comparison between the original query statement and the rewritten query statement for executing queries based on the created materialized view:
Original query statement
Rewritten query statement
SELECT user_id, tran_amount FROM alipay_tran UNION ALL SELECT user_id, tran_amount FROM unionpay_tran;SELECT user_id, total_amount FROM mv;
Perform a penetration query on a materialized view
A partitioned materialized view does not contain the data of all partitions in a source partitioned table if only the latest partition data is updated to the partitioned materialized view. If the partition data that you want to query does not exist in a partitioned materialized view, the system performs a penetration query to query data from the source partitioned table. The following figure shows how to perform a penetration query.
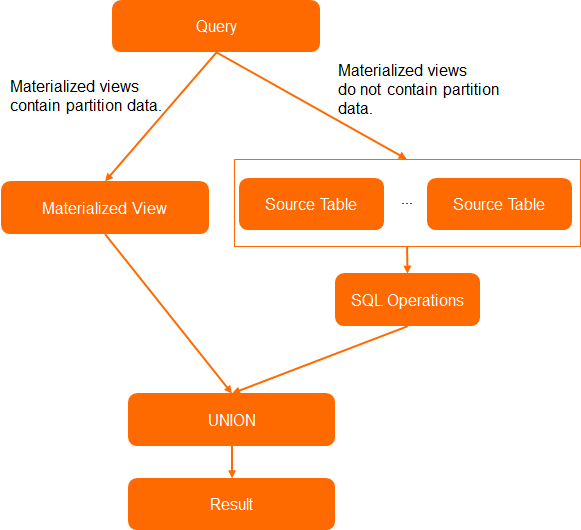
To allow a materialized view to support penetration query, you must configure the following parameters:
When you create a materialized view, add "enable_auto_substitute"="true" to tblproperties.
The following example shows how to perform a penetration query based on a materialized view.
Create a partitioned materialized view that supports penetration query.
-- Create a table named src. CREATE TABLE src(id bigint,name string) PARTITIONED BY (dt string); -- Insert data into the table. INSERT INTO src PARTITION(dt='20210101') VALUES(1,'Alex'); INSERT INTO src PARTITION(dt='20210102') VALUES(2,'Flink'); -- Create a partitioned materialized view that supports penetration query. CREATE MATERIALIZED VIEW IF NOT EXISTS mv LIFECYCLE 7 PARTITIONED BY (dt) tblproperties("enable_auto_substitute"="true") AS SELECT id, name, dt FROM src;Query the data of the 20210101 partition in the src table from the mv materialized view.
SELECT * FROM mv WHERE dt='20210101';Query the data of the 20210102 partition in the src table from the mv materialized view. The mv materialized view does not contain the partition data. Therefore, a penetration query is performed to query the partition data from the src table.
SELECT * FROM mv WHERE dt = '20210102'; -- The preceding statement is equivalent to the following statement because the mv materialized view does not contain the data of the 20210102 partition and the partition data needs to be queried from the src table. SELECT * FROM (SELECT id, name, dt FROM src WHERE dt='20210102') t;Query the data of partitions 20201230 to 20210102 from the mv materialized view. The mv materialized view does not contain all partition data. Therefore, a penetration query is performed to obtain the data that is not contained in the mv materialized view, and a UNION operation is performed on the obtained data and the data that is queried from the mv materialized view to return the final result.
SELECT * FROM mv WHERE dt >= '20201230' AND dt<='20210102' AND id='5'; -- The mv materialized view does not contain the data of the 20210102 partition and a penetration query is performed to query the data of the 20210102 partition from the source table. The preceding statement is equivalent to the following statement: SELECT * FROM (SELECT id, name, dt FROM src WHERE dt='20211231' OR dt='20210102' UNION ALL SELECT * FROM mv WHERE dt='20210101' ) t WHERE id = '5';
Related statements
ALTER MATERIALIZED VIEW: updates a materialized view, changes the lifecycle of a materialized view, enables or disables the lifecycle feature for a materialized view, or drops partitions from a materialized view.
DESC TABLE/VIEW: views the information about a materialized view in a MaxCompute project.
SELECT MATERIALIZED VIEW: queries the status of a materialized view.
DROP MATERIALIZED VIEW: drops an existing materialized view.