Modifies a table.
Scope
Schema evolution includes operations such as adding columns of complex data types, deleting columns, changing the column order, and changing column data types in an existing table. If you change the column order, add a new column and change the column order, or delete a column, the read and write behavior of the table changes. The following limits apply:
If the job type is MapReduce 1.0, Graph tasks cannot read from or write to the modified table.
For CUPID jobs, only the following Spark versions can read from the table. They cannot write to the table:
Spark-2.3.0-odps0.34.0
Spark-3.1.1-odps0.34.0
PAI jobs can read from the table, but cannot write to it.
For Hologres jobs, if you use a Hologres version earlier than 1.3, you cannot read from or write to the modified table when it is referenced as a foreign table.
If schema evolution occurs, CLONE TABLE is not supported.
If schema evolution occurs, an error is reported when you use Streaming Tunnel.
Change the table owner
Changes the owner of a table.
Syntax
ALTER TABLE <table_name> changeowner TO <new_owner>;Parameters
table_name: Required. The name of the table whose owner you want to change.
new_owner: Required. The new owner account.
Examples
-- Change the owner of the test1 table to ALIYUN$xxx@aliyun.com. ALTER TABLE test1 changeowner TO 'ALIYUN$xxx@aliyun.com';
Change the table comment
Changes the comment of a table.
Syntax
ALTER TABLE <table_name> SET COMMENT '<new_comment>';Parameters
table_name: Required. The name of the table whose comment you want to change.
new_comment: Required. The new comment.
Examples
ALTER TABLE sale_detail SET COMMENT 'new comments for table sale_detail';You can run the MaxCompute
DESC <table_name>command to view the updatedCOMMENTin the table.
Change the last modified time of a table
The MaxCompute SQL touch operation changes the LastModifiedTime of a table to the current time. This operation causes MaxCompute to treat the table data as changed, which restarts the lifecycle calculation.
Syntax
ALTER TABLE <table_name> touch;Parameters
table_name: Required. The name of the table whose last modified time you want to change.
Examples
ALTER TABLE sale_detail touch;
Change the cluster properties of a table
For partitioned tables, you can use the ALTER TABLE statement in MaxCompute to add or remove cluster properties.
Syntax
The following syntax is used to add hash cluster properties to a table:
ALTER TABLE <table_name> [clustered BY (<col_name> [, <col_name>, ...]) [sorted BY (<col_name> [ASC | DESC] [, <col_name> [ASC | DESC] ...])] INTO <number_of_buckets> buckets];The following syntax is used to remove the hash cluster properties of a table:
ALTER TABLE <table_name> NOT clustered;To add range cluster properties, the number of buckets is not required and can be omitted. In this case, the system automatically determines the optimal number of buckets based on the data volume. The syntax is as follows:
ALTER TABLE <table_name> [RANGE clustered BY (<col_name> [, <col_name>, ...]) [sorted BY (<col_name> [ASC | DESC] [, <col_name> [ASC | DESC] ...])] INTO <number_of_buckets> buckets];The following syntax is used to remove the range cluster properties of a table or partition:
ALTER TABLE <table_name> NOT clustered; ALTER TABLE <table_name> PARTITION [<pt_spec>] NOT clustered;NoteChanging cluster properties with
ALTER TABLEis valid only for partitioned tables. For non-partitioned tables, cluster properties cannot be changed after they are created. TheALTER TABLEstatement applies to existing tables. After you add new cluster properties, new partitions are stored based on these properties.The
ALTER TABLEstatement affects only new partitions of a partitioned table, including those generated byINSERT OVERWRITE. New partitions are stored based on the new cluster properties, while the cluster properties and storage of old data partitions remain unchanged. This means that for a table where cluster properties were previously set, you can disable them, add new cluster settings, and then specify different cluster key columns, sort key columns, and bucket numbers for new partitions.Because
ALTER TABLEaffects only new partitions, you cannot specify a partition in this statement.
Parameters
The parameters are the same as those in CREATE TABLE.
Examples
-- Create a partitioned table. CREATE TABLE IF NOT EXISTS sale_detail( shop_name STRING, customer_id STRING, total_price DOUBLE) partitioned BY (sale_date STRING, region STRING); -- Change the cluster properties of the table. ALTER TABLE sale_detail clustered BY (customer_id) sorted BY (customer_id) INTO 10 buckets;For more information about cluster properties, see Hash Clustering and Range Clustering.
Change the properties of a PK Delta Table
Syntax
-- Update the number of buckets for a partitioned PK Delta Table. ALTER TABLE <table_name> SET tblproperties("write.bucket.num"="64"); -- Update the number of buckets for a non-partitioned PK Delta Table. After the update, existing data is redistributed based on the new number of buckets. ALTER TABLE <table_name> REWRITE tblproperties("write.bucket.num"="128"); -- Update the retain property, which specifies the time range (in hours) for which historical data states can be queried using TimeTravel. ALTER TABLE <table_name> SET tblproperties("acid.data.retain.hours"="60");
Rename a table
Renames a table. This operation only changes the table name and does not modify the data in the table.
Syntax
ALTER TABLE <table_name> RENAME TO <new_table_name>;Parameters
table_name: Required. The table that you want to rename.
new_table_name: Required. The new name of the table. If a table with the same name as new_table_name already exists, an error is returned.
Examples
ALTER TABLE sale_detail RENAME TO sale_detail_rename;
Change the lifecycle of a table
Changes the lifecycle of an existing partitioned or non-partitioned table.
Syntax
ALTER TABLE <table_name> SET LIFECYCLE <days>;Parameters
table_name: Required. The name of the table whose lifecycle you want to change.
days: Required. The new lifecycle period. This must be a positive integer. The unit is days.
Examples
-- Change the lifecycle of the sale_detail_rename table to 50 days. ALTER TABLE sale_detail_rename SET LIFECYCLE 50;
Disable or enable the lifecycle
Disables or enables the lifecycle for a specified table or partition.
Syntax
ALTER TABLE <table_name> PARTITION [<pt_spec>] {enable|disable} LIFECYCLE;Parameters
table_name: Required. The name of the table for which you want to disable or enable the lifecycle.
pt_spec: Optional. The partition of the table for which you want to disable or enable the lifecycle. The format is
partition_col1=col1_value1, partition_col2=col2_value1.... For multi-level partitioned tables, you must specify all partition values.enable: Enables the lifecycle feature for the table or a specified partition.
Lifecycle reclamation is reapplied to the table and its partitions. By default, their current lifecycle configurations are used.
Before you enable the table lifecycle, you can modify the lifecycle configurations of the table and partitions to prevent data from being mistakenly reclaimed due to previous configurations.
disable: Disables the lifecycle feature for the table or a specified partition.
Prevents the table and all its partitions from being reclaimed by the lifecycle. This has a higher priority than enabling the lifecycle for a partition. For example, if you run
table disable LIFECYCLE, thept_spec enable LIFECYCLEsetting is invalid.After you disable the lifecycle feature for a table, the table's lifecycle configuration and the enable and disable flags of its partitions are retained.
After you disable the lifecycle feature for a table, you can still modify the lifecycle configurations of the table and its partitions.
Examples
Example 1: Disable the lifecycle feature for the `sale_detail_rename` table.
ALTER TABLE sale_detail_rename disable LIFECYCLE;Example 2: Disable the lifecycle feature for the partition where the time is '201912' in the `sale_detail_rename` table.
-- Insert test data. ALTER TABLE sale_detail_rename ADD IF NOT EXISTS PARTITION (sale_date= '201910',region = 'shanghai') PARTITION (sale_date= '201911',region = 'shanghai') PARTITION (sale_date= '201912',region = 'shanghai') PARTITION (sale_date= '202001',region = 'shanghai') PARTITION (sale_date= '202002',region = 'shanghai') PARTITION (sale_date= '201910',region = 'beijing') PARTITION (sale_date= '201911',region = 'beijing') PARTITION (sale_date= '201912',region = 'beijing') PARTITION (sale_date= '202001',region = 'beijing') PARTITION (sale_date= '202002',region = 'beijing'); ALTER TABLE sale_detail_rename PARTITION (sale_date= '201912',region='shanghai') disable LIFECYCLE;
Add partitions
Adds partitions to an existing partitioned table.
Limits
To add the values of partition key columns to a table that has multi-level partitions, you must specify all the partitions.
This operation can add only the values of partition key columns. The names of partition key columns cannot be added.
Syntax
ALTER TABLE <table_name> ADD [IF NOT EXISTS] PARTITION <pt_spec> [PARTITION <pt_spec> PARTITION <pt_spec>...];Parameters
Parameter
Required
Description
table_name
Yes
The name of the partitioned table to which you want to add partitions.
IF NOT EXISTS
No
If you do not specify IF NOT EXISTS and a partition with the same name already exists, this operation fails and an error is returned.
pt_spec
Yes
The partitions that you want to add. The value of this parameter is in the
(partition_col1 = partition_col_value1, partition_col2 = partition_col_value2, ...)format. partition_col indicates the names of the partition key columns. partition_col_value indicates the values of the partition key columns. The names of partition key columns are not case sensitive, but their values are case sensitive.Examples
The sale_detail table is used in this section. For information about the CREATE TABLE statement of this table, see Create a table named sale_detail.
Example 1: Add a partition to the sale_detail table. The partition stores the sales records in the China (Hangzhou) region in December 2013.
ALTER TABLE sale_detail ADD IF NOT EXISTS PARTITION (sale_date='201312', region='hangzhou');Example 2: Add two partitions to the sale_detail table. The partitions store the sales records in the China (Beijing) and China (Shanghai) regions in December 2013.
ALTER TABLE sale_detail ADD IF NOT EXISTS PARTITION (sale_date='201312', region='beijing') PARTITION (sale_date='201312', region='shanghai');Example 3: Add a partition to the sale_detail table and specify only the partition key column sale_date for the partition. An error is returned because you must specify the two partition key columns sale_date and region.
ALTER TABLE sale_detail ADD IF NOT EXISTS PARTITION (sale_date='20111011');Example 4: Add a partition to a Delta table.
-- Create a Delta table. CREATE TABLE mf_tt (pk BIGINT NOT NULL PRIMARY KEY, val BIGINT NOT NULL) PARTITIONED BY (dd STRING, hh STRING) TBLPROPERTIES ("transactional"="true"); -- Add a partition to the table. ALTER TABLE mf_tt ADD PARTITION (dd='01', hh='01');Example 5: Change the properties of a Delta table.
-- Change the write.bucket.num property of a Delta table. You can change only the property of a partitioned Delta table. You cannot change the property of a non-partitioned Delta table. ALTER TABLE mf_tt3 SET tblproperties("write.bucket.num"="64"); -- Change the acid.data.retain.hours property of a Delta table. ALTER TABLE mf_tt3 SET tblproperties("acid.data.retain.hours"="60");
Change the value of LastModifiedTime for a partition
Changes the value of LastDataModifiedTime for a partition in a partitioned table by executing the TOUCH statement that is provided by MaxCompute SQL. This statement changes the value of LastModifiedTime to the current time. In this case, MaxCompute considers that data is updated, and a new lifecycle of the partition starts from the time specified by LastModifiedTime.
Limits
If a table contains multi-level partitions, you must specify all partition levels when you change the value of LastModifiedTime for a partition.
Syntax
ALTER TABLE <table_name> touch PARTITION (<pt_spec>);Parameters
Parameter
Required
Description
table_name
Yes
The name of the partitioned table for which you want to change the value of LastModifiedTime. If the table does not exist, an error is returned.
pt_spec
Yes
The partition for which you want to change the value of LastModifiedTime. Format:
(partition_col1 = partition_col_value1, partition_col2 = partition_col_value2, ...). partition_col indicates the names of the partition key columns. partition_col_value indicates the values of the partition key columns. If the specified column name or column value does not exist, an error is returned.Examples
-- Change the value of LastModifiedTime for the partition in which the value of the sale_date column is 201312 and the value of the region column is shanghai in the sale_detail table. ALTER TABLE sale_detail touch PARTITION (sale_date='201312', region='shanghai');
Change a value in a partition key column
Changes a value in a partition key column. MaxCompute SQL allows you to execute the RENAME statement to change values in partition key columns.
Limits
The RENAME statement can change values in partition key columns but cannot change the column names.
If a table contains multi-level partitions, you must specify all partition levels when you change the value of LastModifiedTime for a partition.
Syntax
ALTER TABLE <table_name> PARTITION (<pt_spec>) rename TO PARTITION (<new_pt_spec>);Parameters
Parameter
Required
Description
table_name
Yes
The name of the table in which you want to change a value in a partition key column.
pt_spec
Yes
The partition in which you want to change partition key column values. Format:
(partition_col1 = partition_col_value1, partition_col2 = partition_col_value2, ...). partition_col indicates the names of the partition key columns. partition_col_value indicates the values of the partition key columns. If the specified column name or column value does not exist, an error is returned.new_pt_spec
Yes
The new partition information. Format:
(partition_col1 = new_partition_col_value1, partition_col2 = new_partition_col_value2, ...). partition_col indicates the names of the partition key columns. new_partition_col_value indicates the new values of the partition key columns.Examples
-- Change the partition key column values of the sale_detail table. ALTER TABLE sale_detail PARTITION (sale_date = '201312', region = 'hangzhou') rename TO PARTITION (sale_date = '201310', region = 'beijing');
Merge partitions
Merges multiple partitions of a partitioned table into one partition. MaxCompute SQL allows you to execute the MERGE PARTITION statement to merge multiple partitions of a table into one partition. This operation deletes the dimension information about the merged partitions and migrates the partition data to the specified partition.
Limits
Partitions of external tables cannot be merged. After partitions of a clustered table are merged into one partition, the partition does not have the clustering attribute.
You can merge a maximum of 4,000 partitions at a time.
Syntax
ALTER TABLE <table_name> MERGE [IF EXISTS] PARTITION (<predicate>) [, PARTITION(<predicate2>) ...] overwrite PARTITION (<fullpartitionSpec>) [purge];Parameters
Parameter
Required
Description
table_name
Yes
The name of the partitioned table whose partitions you want to merge.
IF EXISTS
No
If you do not specify IF EXISTS and the specified partition does not exist, this operation fails and an error is returned. If IF EXISTS is specified but no partitions meet the
mergecondition, a new partition cannot be generated after merging. If the source data is modified by an operation such asinsert,rename, ordropduring the merging process, an error is returned even if IF EXISTS is specified.predicate
Yes
The condition that is used to match the partitions that you want to merge.
fullpartitionSpec
Yes
The partition that is generated after merging.
purge
No
Optional keyword. If you configure this parameter, the session directory is cleared. By default, logs that are generated in the last three days are deleted. For more information, see Purge.
Examples
Example 1: Merge the partitions that meet a specified condition into the destination partition.
-- View the partitions in a partitioned table. SHOW partitions intpstringstringstring; ds=20181101/hh=00/mm=00 ds=20181101/hh=00/mm=10 ds=20181101/hh=10/mm=00 ds=20181101/hh=10/mm=10 -- Merge all partitions that meet the hh='00' condition into the ds='20181101', hh='00', mm='00' partition. ALTER TABLE intpstringstringstring MERGE PARTITION(hh='00') overwrite PARTITION(ds='20181101', hh='00', mm='00'); -- View the partition that is generated after merging. SHOW partitions intpstringstringstring; ds=20181101/hh=00/mm=00 ds=20181101/hh=10/mm=00 ds=20181101/hh=10/mm=10Example 2: Merge specified partitions into one partition.
-- Merge specified partitions into one partition. ALTER TABLE intpstringstringstring MERGE IF EXISTS PARTITION(ds='20181101', hh='00', mm='00'), PARTITION(ds='20181101', hh='10', mm='00'), partition(ds='20181101', hh='10', mm='10') overwrite partition(ds='20181101', hh='00', mm='00') purge; -- View the partitions in the partitioned table. SHOW partitions intpstringstringstring; ds=20181101/hh=00/mm=00
Drop partitions
Drops partitions from an existing partitioned table.
MaxCompute allows you to drop partitions based on a specified filter condition. If you want to drop multiple partitions that meet a specified filter condition at a time, you can use an expression to specify the filter condition, use the filter condition to match partitions, and drop the partitions at a time.
Limits
You can specify the information of only one partition key column in a PARTITION (<partition_filtercondition>) clause.
If you use an expression to specify PARTITION (<partition_filtercondition>), only the built-in scalar function can be used for the expression.
Precautions
After you drop a partition, the volume of stored data in a MaxCompute project decreases.
You can specify a lifecycle for a partitioned table. This way, MaxCompute automatically reclaims partitions whose data is not updated within the time specified by the lifecycle. For more information about the lifecycle, see Lifecycle.
Syntax
The filter condition is not specified.
-- Drop one partition at a time. ALTER TABLE <table_name> DROP [IF EXISTS] PARTITION <pt_spec>; -- Drop multiple partitions at a time. ALTER TABLE <table_name> DROP [IF EXISTS] PARTITION <pt_spec>,PARTITION <pt_spec>[,PARTITION <pt_spec>....];The filter condition is specified.
ALTER TABLE <table_name> DROP [IF EXISTS] PARTITION <partition_filtercondition>;
Parameters
Parameter
Required
Description
table_name
Yes
The name of the partitioned table from which you want to drop partitions.
IF EXISTS
No
If you do not specify the if exists option and the specified partition does not exist, an error is returned.
pt_spec
Yes
The partitions that you want to drop. Format:
(partition_col1 = partition_col_value1, partition_col2 = partition_col_value2, ...). partition_col indicates the names of the partition key columns. partition_col_value indicates the values of the partition key columns. The names of partition key columns are not case sensitive, but their values are case sensitive.partition_filtercondition
No
The filter condition. This parameter is required when you specify the filter condition. It is not case-sensitive. Format:
partition_filtercondition : PARTITION (<partition_col> <relational_operators> <partition_col_value>) | PARTITION (scalar(<partition_col>) <relational_operators> <partition_col_value>) | PARTITION (<partition_filtercondition1> AND|OR <partition_filtercondition2>) | PARTITION (NOT <partition_filtercondition>) | PARTITION (<partition_filtercondition1>)[,PARTITION (<partition_filtercondition2>), ...]Parameters:
partition_col: the name of the partition key column.
relational_operators: the relational operator. For more information, see Operator.
partition_col_value: A comparison value or regular expression. The data type of this value must be the same as the data type of the partition key column.
scalar(): a scalar function. The scalar function generates a scalar based on the input value, processes the values in the column specified by partition_col, and uses relational operators specified by relational_operators to compare the processed values with the value specified by partition_col_value.
The filter conditions support the logical operators NOT, AND, and OR. You can use PARTITION (NOT <partition_filtercondition>) to obtain the complementary set of the filter conditions that you specified. You can use PARTITION (<partition_filtercondition1> AND|OR <partition_filtercondition2>) to obtain the condition that is used to match partitions.
Multiple PARTITION (<partition_filtercondition>) clauses are supported. If these clauses are separated by commas (,), the logical relationship between the clauses is OR. The filter condition is obtained based on the OR logical relationship and used to match partitions.
Examples
The filter condition is not specified.
-- Drop a partition from the sale_detail table. The partition stores the sales record in the China (Hangzhou) region in December 2013. ALTER TABLE sale_detail DROP IF EXISTS PARTITION(sale_date='201312',region='hangzhou'); -- Drop two partitions from the sale_detail table. The partitions store the sales records in the China (Hangzhou) and China (Shanghai) regions in December 2013. ALTER TABLE sale_detail DROP IF EXISTS PARTITION(sale_date='201312',region='hangzhou'),PARTITION(sale_date='201312',region='shanghai');The filter condition is specified.
-- Create a partitioned table. CREATE TABLE IF NOT EXISTS sale_detail( shop_name STRING, customer_id STRING, total_price DOUBLE) partitioned BY (sale_date STRING); -- Add a partition to the table. ALTER TABLE sale_detail ADD if NOT EXISTS PARTITION (sale_date= '201910') PARTITION (sale_date= '201911') PARTITION (sale_date= '201912') PARTITION (sale_date= '202001') PARTITION (sale_date= '202002') PARTITION (sale_date= '202003') PARTITION (sale_date= '202004') PARTITION (sale_date= '202005') PARTITION (sale_date= '202006') PARTITION (sale_date= '202007'); -- Drop multiple partitions from the table at a time. ALTER TABLE sale_detail DROP IF EXISTS PARTITION(sale_date < '201911'); ALTER TABLE sale_detail DROP IF EXISTS PARTITION(sale_date >= '202007'); ALTER TABLE sale_detail DROP IF EXISTS PARTITION(sale_date LIKE '20191%'); ALTER TABLE sale_detail DROP IF EXISTS PARTITION(sale_date IN ('202002','202004','202006')); ALTER TABLE sale_detail DROP IF EXISTS PARTITION(sale_date BETWEEN '202001' AND '202007'); ALTER TABLE sale_detail DROP IF EXISTS PARTITION(substr(sale_date, 1, 4) = '2020'); ALTER TABLE sale_detail DROP IF EXISTS PARTITION(sale_date < '201912' OR sale_date >= '202006'); ALTER TABLE sale_detail DROP IF EXISTS PARTITION(sale_date > '201912' AND sale_date <= '202004'); ALTER TABLE sale_detail DROP IF EXISTS PARTITION(NOT sale_date > '202004'); -- Drop partitions by using multiple PARTITION (<partition_filtercondition>) clauses. The logical relationship between these clauses is OR. ALTER TABLE sale_detail DROP IF EXISTS PARTITION(sale_date < '201911'), PARTITION(sale_date >= '202007'); -- Add partitions in other formats. ALTER TABLE sale_detail ADD IF NOT EXISTS PARTITION (sale_date= '2019-10-05') PARTITION (sale_date= '2019-10-06') PARTITION (sale_date= '2019-10-07'); -- Use regular expressions to match the partitions that you want to drop and drop these partitions at a time. ALTER TABLE sale_detail DROP IF EXISTS PARTITION(sale_date RLIKE '2019-\\d+-\\d+'); -- Create a table named region_sale_detail. The table contains multi-level partitions. CREATE TABLE IF NOT EXISTS region_sale_detail( shop_name STRING, customer_id STRING, total_price DOUBLE) partitioned BY (sale_date STRING , region STRING ); -- Add partitions to the table. ALTER TABLE region_sale_detail ADD IF NOT EXISTS PARTITION (sale_date= '201910',region = 'shanghai') PARTITION (sale_date= '201911',region = 'shanghai') PARTITION (sale_date= '201912',region = 'shanghai') PARTITION (sale_date= '202001',region = 'shanghai') PARTITION (sale_date= '202002',region = 'shanghai') PARTITION (sale_date= '201910',region = 'beijing') PARTITION (sale_date= '201911',region = 'beijing') PARTITION (sale_date= '201912',region = 'beijing') PARTITION (sale_date= '202001',region = 'beijing') PARTITION (sale_date= '202002',region = 'beijing'); -- Execute the following statement to drop multi-level partitions at a time. The logical relationship between the two PARTITION (<partition_filtercondition>) clauses is OR. After the statement is executed, the partitions in which the value of the sale_date column is earlier than 201911 or the partitions in which the value of the region column is beijing are dropped. ALTER TABLE region_sale_detail DROP IF EXISTS PARTITION(sale_date < '201911'),PARTITION(region = 'beijing'); -- Execute the following statement to drop partitions in which the value of the sale_date column is earlier than 201911 and the value of the region column is beijing. ALTER TABLE region_sale_detail DROP IF EXISTS PARTITION(sale_date < '201911', region = 'beijing');When you drop multi-level partitions at a time, you cannot specify a filter condition that is based on multiple partition key columns in one
PARTITION (<partition_filtercondition>)clause. Otherwise, the following error is returned:FAILED: ODPS-0130071:[1,82] Semantic analysis exception - invalid column reference region, partition expression must have one and only one column reference.-- If you specify the information of multiple partition key columns in a PARTITION (<partition_filtercondition>) clause, an error is returned. Example of incorrect usage: ALTER TABLE region_sale_detail DROP IF EXISTS PARTITION(sale_date < '201911' AND region = 'beijing');
Add columns or comments
You can add columns or comments to an existing non-partitioned or partitioned table. Note the scope of schema evolution. MaxCompute supports adding columns of the STRUCT type, such as STRUCT<x: STRING, y: BIGINT> and MAP<STRING, STRUCT<x: DOUBLE, y: DOUBLE>>.
Parameter settings
To enable this feature, set the
setproject odps.schema.evolution.enable=true;parameter.Permissions: This is a project-level parameter. You must be the project owner or have the project-level Super_Administrator or Admin role. For more information, see Assign built-in management roles to a user.
Effective period: The parameter takes effect about 10 minutes after it is set.
Command format
ALTER TABLE <table_name> ADD COLUMNS [IF NOT EXISTS] (<col_name1> <type1> COMMENT ['<col_comment>'] [, <col_name2> <type2> COMMENT '<col_comment>'...] );Parameters
Parameter
Required
Description
table_name
Yes
The name of the table to which you want to add columns. You cannot specify the order of the new columns. They are added to the end of the table by default.
col_name
Yes
The name of the new column.
type
Yes
The data type of the new column.
col_comment
No
The comment for the new column.
Examples
Example 1: Add two columns to the sale_detail table.
ALTER TABLE sale_detail ADD COLUMNS IF NOT EXISTS(customer_name STRING, education BIGINT);Example 2: Add two columns with comments to the sale_detail table.
ALTER TABLE sale_detail ADD COLUMNS (customer_name STRING COMMENT 'Customer', education BIGINT COMMENT 'Education' );Example 3: Add a column of a complex data type to the sale_detail table.
ALTER TABLE sale_detail ADD COLUMNS (region_info struct<province:string, area:string>);Example 4: If you run the SQL statement to add an existing column, such as the ID column, to the sale_detail table, a success message is returned and the column is not added again.
-- The statement is successful, but the ID column is not repeatedly added. ALTER TABLE sale_detail ADD COLUMNS IF NOT EXISTS(id bigint);Example 5: Add a column to a Delta table.
CREATE TABLE delta_table_test (pk BIGINT NOT NULL PRIMARY KEY, val BIGINT) TBLPROPERTIES ("transactional"="true"); ALTER TABLE delta_table_test ADD COLUMNS (val2 bigint);
Delete columns
You can delete one or more specified columns from an existing non-partitioned or partitioned table. Note the scope of schema evolution.
Parameter settings
To enable this feature, set the
setproject odps.schema.evolution.enable=true;parameter.Permissions: This is a project-level parameter. You must be the project owner or have the project-level Super_Administrator or Admin role. For more information, see Assign built-in management roles to a user.
Effective period: The parameter takes effect about 10 minutes after it is set.
Command format
-- Delete a single column. ALTER TABLE <table_name> DROP COLUMN <col_name>; -- Delete multiple columns. ALTER TABLE <table_name> DROP COLUMNS <col_name1>[, <col_name2>...];Parameters
table_name: Required. The name of the table from which you want to delete columns.
col_name: Required. The name of the column to delete.
Example
-- Delete the customer_id column from the sale_detail table. Enter yes to confirm the deletion. ALTER TABLE sale_detail DROP COLUMN customer_id; -- Delete the customer_id column from the sale_detail table. Enter yes to confirm the deletion. ALTER TABLE sale_detail DROP COLUMNS customer_id; -- Delete the shop_name and customer_id columns from the sale_detail table. Enter yes to confirm the deletion. ALTER TABLE sale_detail DROP COLUMNS shop_name, customer_id;
Change column data types
You can change the data type of an existing column. Note the scope of schema evolution.
Parameter settings
To enable this feature, set the
setproject odps.schema.evolution.enable=true;parameter.Permissions: This is a project-level parameter. You must be the project owner or have the project-level Super_Administrator or Admin role. For more information, see Assign built-in management roles to a user.
Effective period: The parameter takes effect about 10 minutes after it is set.
Command format
ALTER TABLE <table_name> CHANGE [COLUMN] <old_column_name> <new_column_name> <new_data_type>;Parameters
Parameter
Required
Description
table_name
Yes
The name of the table whose column data type you want to change.
old_column_name
Yes
The name of the column whose data type you want to change.
new_column_name
Yes
The name of the column after its data type is changed.
old_column_name can be the same as new_column_name, which means the column name is not changed. However, new_column_name cannot be the same as the name of any column other than old_column_name.
new_data_type
Yes
The new data type of the column.
Example
-- Change the data type of the id field in the sale_detail table from BIGINT to STRING. ALTER TABLE sale_detail CHANGE COLUMN id id STRING;Data type conversion table
NoteY indicates that the conversion is supported. N indicates that the conversion is not supported. - indicates that the conversion is not applicable. Y() indicates that the conversion is supported if the condition in the parentheses is met.
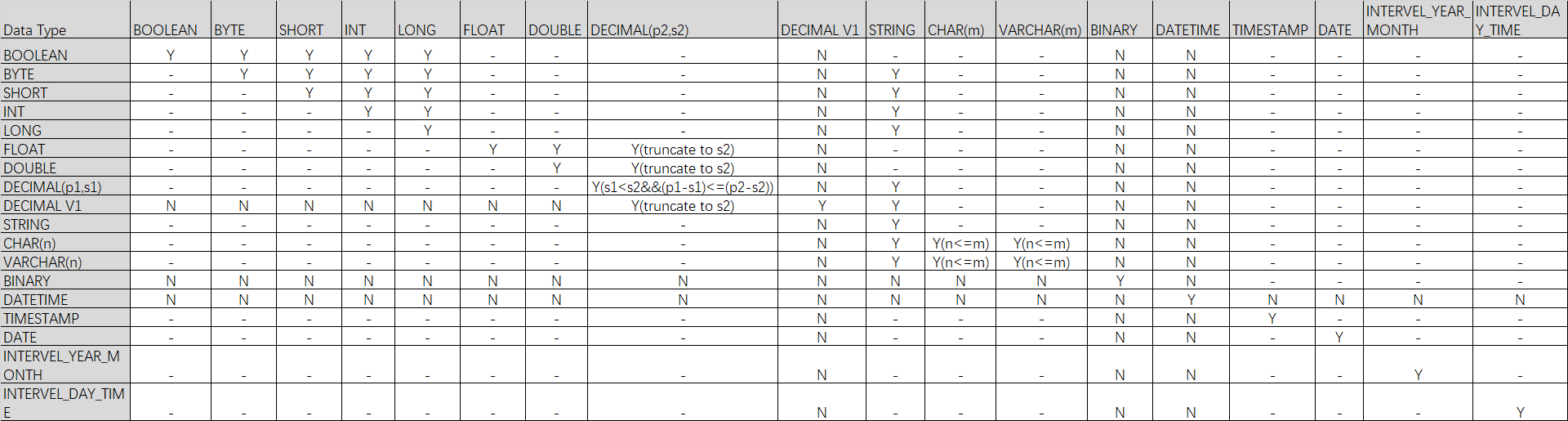
Change the column order
You can change the column order in an existing non-partitioned or partitioned table. Note the scope of schema evolution.
Parameter settings
To enable this feature, set the
setproject odps.schema.evolution.enable=true;parameter.Permissions: This is a project-level parameter. You must be the project owner or have the project-level Super_Administrator or Admin role. For more information, see Assign built-in management roles to a user.
Effective period: The parameter takes effect about 10 minutes after it is set.
Command format
ALTER TABLE <table_name> CHANGE <old_column_name> <new_column_name> <column_type> AFTER <column_name>;Parameters
Parameter
Required
Description
table_name
Yes
The name of the table in which you want to change the column order.
old_column_name
Yes
The original name of the column whose order you want to change.
new_col_name
Yes
The new name of the column.
new_col_name can be the same as old_column_name, which means the column name is not modified. However, new_col_name cannot be the same as the name of any column other than old_column_name.
column_type
Yes
The original data type of the column. This cannot be changed.
column_name
Yes
Moves the column to be reordered after column_name.
Example
-- Change the name of the customer column in the sale_detail table to customer_id and move it after the total_price column. ALTER TABLE sale_detail CHANGE customer customer_id STRING AFTER total_price; -- Move the customer_id column in the sale_detail table after the total_price column without changing the column name. ALTER TABLE sale_detail CHANGE customer_id customer_id STRING AFTER total_price;
Change a column name
You can change the name of a column in an existing non-partitioned or partitioned table.
Command format
ALTER TABLE <table_name> CHANGE COLUMN <old_col_name> RENAME TO <new_col_name>;Parameters
Parameter
Required
Description
table_name
Yes
The name of the table whose column name you want to change.
old_col_name
Yes
The name of the column to be renamed. The column must exist.
new_col_name
Yes
The new name for the column. The column name must be unique.
Example
-- Rename the customer_name column in the sale_detail table to customer. ALTER TABLE sale_detail CHANGE COLUMN customer_name RENAME TO customer;
Change a column comment
You can change the comment of a column in an existing non-partitioned or partitioned table.
Syntax
ALTER TABLE <table_name> CHANGE COLUMN <col_name> COMMENT '<col_comment>';Parameters
Parameter
Required
Description
table_name
Yes
The name of the table whose column comment you want to change.
col_name
Yes
The name of the column whose comment you want to change. The column must exist.
col_comment
Yes
The new comment. The comment must be a valid string of no more than 1024 bytes. Otherwise, an error is reported.
Example
-- Change the comment of the customer column in the sale_detail0113 table. ALTER TABLE sale_detail0113 CHANGE COLUMN customer COMMENT 'customer';
Change a column name and comment
You can change the name and comment of a column in a non-partitioned or partitioned table.
Command format
ALTER TABLE <table_name> CHANGE COLUMN <old_col_name> <new_col_name> <column_type> COMMENT '<col_comment>';Parameters
Parameter
Required
Description
table_name
Yes
The name of the table whose column name and comment you want to change.
old_col_name
Yes
The name of the column to be modified. The column must exist.
new_col_name
Yes
The new name for the column. The column name must be unique.
column_type
Yes
The data type of the column.
col_comment
Optional
The new comment. The content can be up to 1024 bytes in length.
Example
-- Change the name of the customer column in the sale_detail table to customer_newname and change its comment to 'customer'. ALTER TABLE sale_detail CHANGE COLUMN customer customer_newname STRING COMMENT 'customer';
Change the NOT NULL property of a column
You can change the NOT NULL property of a non-partition key column in a table to allow NULL values.
After you allow NULL values for a column, you cannot revert this change to disallow NULL values. Proceed with caution.
You can run the
DESC EXTENDED table_name;command to view the value of theNullableproperty and determine whether the column allows NULL values:If
Nullableistrue, NULL values are allowed.If
Nullableisfalse, NULL values are not allowed.
Command format
ALTER TABLE <table_name> CHANGE COLUMN <old_col_name> NULL;Parameters
Parameter
Required
Description
table_name
Yes
The name of the table whose column NOT NULL property you want to change.
old_col_name
Yes
The name of the non-partition key column to be modified. The column must be an existing non-partition key column.
Example
-- Create a partitioned table in which the id column cannot be NULL. CREATE TABLE null_test(id INT NOT NULL, name STRING) PARTITIONED BY (ds string); -- View table properties. DESC EXTENDED null_test; -- The following result is returned: +------------------------------------------------------------------------------------+ | Native Columns: | +------------------------------------------------------------------------------------+ | Field | Type | Label | ExtendedLabel | Nullable | DefaultValue | Comment | +------------------------------------------------------------------------------------+ | id | int | | | false | NULL | | | name | string | | | true | NULL | | +------------------------------------------------------------------------------------+ | Partition Columns: | +------------------------------------------------------------------------------------+ | ds | string | | +------------------------------------------------------------------------------------+ -- Allow the id column to be NULL. ALTER TABLE null_test CHANGE COLUMN id NULL; -- View table properties. DESC EXTENDED null_test; -- The following result is returned: +------------------------------------------------------------------------------------+ | Native Columns: | +------------------------------------------------------------------------------------+ | Field | Type | Label | ExtendedLabel | Nullable | DefaultValue | Comment | +------------------------------------------------------------------------------------+ | id | int | | | true | NULL | | | name | string | | | true | NULL | | +------------------------------------------------------------------------------------+ | Partition Columns: | +------------------------------------------------------------------------------------+ | ds | string | | +------------------------------------------------------------------------------------+
Compact files of a transactional table
The underlying physical storage of a transactional table consists of Base files and Delta files, which cannot be directly read. When you run an update or delete operation on a transactional table, only Delta files are appended. The Base files are not modified. Therefore, frequent update or delete operations increase the table's storage footprint and query costs.
If you run multiple update or delete operations on the same table or partition, many Delta files are generated. When the system reads data, it must load these Delta files to determine which rows were updated or deleted. Many Delta files can degrade data read performance. In this case, you can compact the Base and Delta files to reduce storage and improve data read efficiency.
Syntax
ALTER TABLE <table_name> [PARTITION (<partition_key> = '<partition_value>' [, ...])] compact {minor|major};Parameters
table_name: Required. The name of the transactional table whose files you want to compact.
partition_key: Optional. If the transactional table is a partitioned table, specify the partition key column name.
partition_value: Optional. If the transactional table is a partitioned table, specify the value for the partition key column.
major|minor: You must select at least one. The differences are:
minor: Compacts only a Base file and all its Delta files to eliminate the Delta files.major: Not only compacts a Base file and all its Delta files to eliminate the Delta files, but also merges small files within the corresponding Base file of the table. If the Base file is small (less than 32 MB) or if Delta files exist, this is equivalent to running aninsert overwriteoperation on the table again. However, if the Base file is large enough (32 MB or larger) and no Delta files exist, the file is not rewritten.
Examples
Example 1: Compact the files of the transactional table `acid_delete`. The sample command is as follows:
ALTER TABLE acid_delete compact minor;The following result is returned:
Summary: Nothing found to merge, set odps.merge.cross.paths=true IF cross path merge is permitted. OKExample 2: Compact the files of the transactional table `acid_update_pt`. The sample command is as follows:
ALTER TABLE acid_update_pt PARTITION (ds = '2019') compact major;The following result is returned:
Summary: table name: acid_update_pt /ds=2019 instance count: 2 run time: 6 before merge, file count: 8 file size: 2613 file physical size: 7839 after merge, file count: 2 file size: 679 file physical size: 2037 OK
Merge small files
A distributed file system stores data in blocks. Files smaller than the block size (64 MB) are called small files. Distributed systems inevitably generate small files. For example, small files can be produced by the calculation results of SQL or other distributed engines, or by data ingestion through Tunnel. Merging small files can improve computing performance.
Syntax
ALTER TABLE <tablename> [PARTITION(<partition_key>=<partition_value>)] MERGE SMALLFILES;Parameters
table_name: Required. The name of the table whose files you want to merge.
partition_key: Optional. If the table is a partitioned table, specify the partition key column name.
partition_value: Optional. If the table is a partitioned table, specify the value for the partition key column.
Examples
SET odps.merge.cross.paths=true; SET odps.merge.smallfile.filesize.threshold=128; SET odps.merge.max.filenumber.per.instance = 2000; ALTER TABLE tbcdm.dwd_tb_log_pv_di PARTITION (ds='20151116') MERGE smallfiles;
If you use a pay-as-you-go instance, you are charged for using the small file merge feature. The billing rules are the same as those for pay-as-you-go SQL jobs. For more information, see Compute costs (pay-as-you-go).
For more information, see Merge small files.
Related commands
CREATE TABLE: Creates a non-partitioned table, partitioned table, foreign table, or clustered table.
TRUNCATE: Deletes all data from a specified table.
DROP TABLE: Deletes a partitioned or non-partitioned table.
DESC TABLE/VIEW: Displays information about a MaxCompute internal table, view, materialized view, foreign table, clustered table, or transactional table.
SHOW: Displays the SQL DDL statement of a table, lists all tables and views in a project, or lists all partitions in a table.