This topic describes how to use a PyODPS node of DataWorks to segment Chinese text in a data table based on the open source segmentation tool Jieba and write the segmented words and phrases to a new table. This topic also describes how to use closure functions to segment Chinese text based on a custom dictionary.
Prerequisites
A DataWorks workspace is created and a MaxCompute compute engine is associated with the workspace. For more information about how to create a workspace, see Create a workspace.
Background information
DataWorks provides PyODPS nodes. You can edit Python code and use MaxCompute SDK for Python on PyODPS nodes of DataWorks. PyODPS nodes of DataWorks include PyODPS 2 nodes and PyODPS 3 nodes. We recommend that you use PyODPS 3 nodes. For more information, see Develop a PyODPS 3 task.
Sample code in this topic is for reference only. We recommend that you do not use the code in your production environment.
Preparation: Download the open source Jieba package
Download the open source Jieba package from GitHub.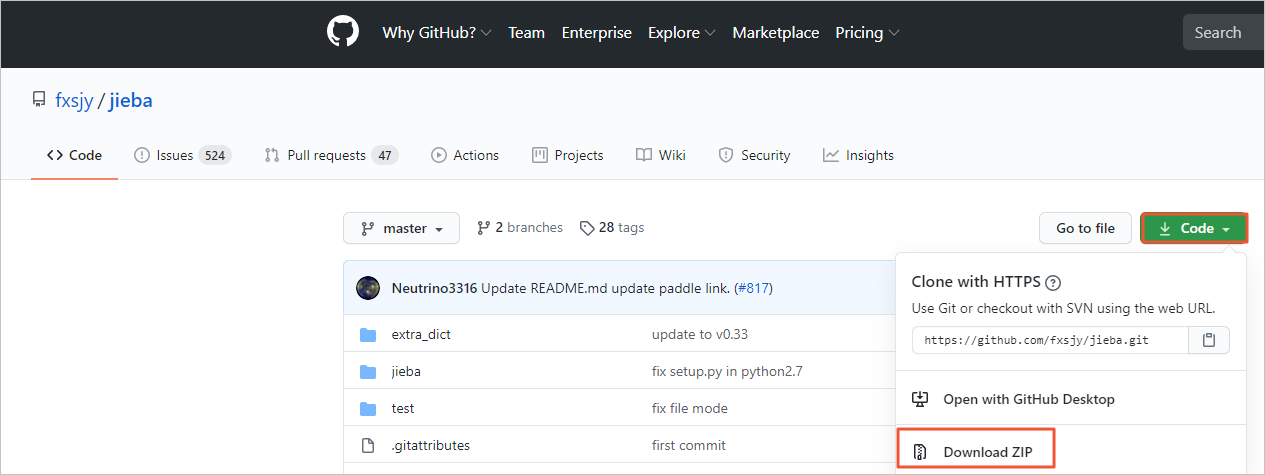
Practice 1: Use the open source Jieba package to segment Chinese text
Create a workflow.
For more information, see Create a workflow.
Create a MaxCompute resource and upload the jieba-master.zip package.
Right-click the name of the created workflow and choose .
In the Create Resource dialog box, configure the parameters and click Create.
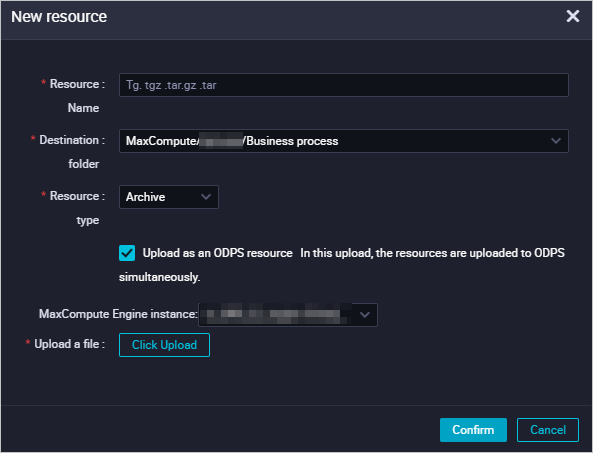 The following table describes some of the parameters.
The following table describes some of the parameters. Parameter
Description
File
Click Upload and upload the downloaded jieba-master.zip package as prompted.
Name
The name of the resource. The resource name can be different from the name of the file that you upload but must comply with specific conventions. You can specify a custom resource name as prompted. In this practice, this parameter is set to jieba-master.zip.
Click the
 icon in the top toolbar to commit the resource.
icon in the top toolbar to commit the resource.
Create a table named jieba_test and a table named jieba_result. The jieba_test table is used to store test data. The jieba_result table is used to store the test result.
To create a table, perform the following operations: Right-click the name of the created workflow and choose . In the Create Table dialog box, configure the parameters as prompted and click Create. Then, execute a DDL statement to configure fields in the table. The following table describes the DDL statements that are used to configure fields in the two tables.
Table
DDL statement
Description
jieba_test
CREATE TABLE jieba_test ( `chinese` string, `content` string );Stores test data.
jieba_result
CREATE TABLE jieba_result ( `chinese` string ) ;Stores the test result.
After the tables are created, commit the tables to the development environment.
Download test data and import the test data to the jieba_test table.
Download the jieba_test.csv file that contains test data to your on-premises machine.
Click the
 icon in the Scheduled Workflow pane of the DataStudio page.
icon in the Scheduled Workflow pane of the DataStudio page. In the Data Import Wizard dialog box, enter the name of the table jieba_test to which you want to import data, select the table, and then click Next.
Click Browse, upload the jieba_test.csv file from your on-premises machine, and then click Next.
Select By Name and click Import Data.
Create a PyODPS 3 node.
Right-click the name of the created workflow and choose .
In the Create Node dialog box, set the Name parameter to an appropriate value, such as word_split, and click Confirm.
Use the open source Jieba package to run segmentation code.
Run the following sample code on the PyODPS 3 node to segment the test data in the jieba_test table and return the first 10 rows of segmentation result data:
def test(input_var): import jieba result = jieba.cut(input_var, cut_all=False) return "/ ".join(result) # odps.stage.mapper.split.size can be used to improve the execution parallelism. hints = { 'odps.isolation.session.enable': True, 'odps.stage.mapper.split.size': 64, } libraries =['jieba-master.zip'] # Reference the jieba-master.zip package. src_df = o.get_table('jieba_test').to_df() # Reference the data in the jieba_test table. result_df = src_df.chinese.map(test).persist('jieba_result', hints=hints, libraries=libraries) print(result_df.head(10)) # Display the first 10 rows of segmentation result data. You can view more data in the jieba_result table.Noteodps.stage.mapper.split.size can be used to improve the execution parallelism. For more information, see Flag parameters.
View the result.
View the execution result of the Jieba segmentation program on the Runtime Log tab in the lower part of the page.
You can also click Ad Hoc Query in the left-side navigation pane of the DataStudio page and create an ad hoc query node to view the data in the jieba_result table.
select * from jieba_result;
Practice 2: Use a custom dictionary to segment Chinese text
If the dictionary of the Jieba tool does not meet your requirements, you can use a custom dictionary. This section provides an example on how to use a custom dictionary to segment Chinese text.
Create a MaxCompute resource.
You can call a PyODPS user-defined function (UDF) to read resources uploaded to MaxCompute. The resources can be tables or files. In this case, you must write the UDF as a closure function or a function of the callable class. If you need to reference complex UDFs, you can create a MaxCompute function in DataWorks. For more information, see Create and use a MaxCompute UDF.
In this section, a closure function is called to reference the custom dictionary file key_words.txt that is uploaded to MaxCompute.
Create a MaxCompute function of the File type.
Right-click the name of the created workflow and choose . In the Create Resource dialog box, set the Name parameter to key_words.txt and click Create.
On the configuration tab of the key_words.txt resource, enter the content of the custom dictionary and save and commit the resource.
The following content is the example content of the custom dictionary. You can enter the content of the custom dictionary based on your test requirements.
增量备份 安全合规
Use the custom dictionary to run segmentation code.
Run the following sample code on the PyODPS 3 node to segment the test data in the jieba_test table and return the first 10 rows of segmentation result data.
ImportantBefore you run the following sample code, you must create a table named
jieba_result2to store the segmentation result data. For more information about how to create a table, see the step of creating a table named jieba_result.def test(resources): import jieba fileobj = resources[0] jieba.load_userdict(fileobj) def h(input_var): # Call the nested h() function to load the dictionary and segment text. result = jieba.cut(input_var, cut_all=False) return "/ ".join(result) return h # odps.stage.mapper.split.size can be used to improve the execution parallelism. hints = { 'odps.isolation.session.enable': True, 'odps.stage.mapper.split.size': 64, } libraries =['jieba-master.zip'] # Reference the jieba-master.zip package. src_df = o.get_table('jieba_test').to_df() # Reference the data in the jieba_test table. file_object = o.get_resource('key_words.txt') # Call the get_resource() function to reference the MaxCompute resource. mapped_df = src_df.chinese.map(test, resources=[file_object]) # Call the map function to transfer the resources parameter. result_df = mapped_df.persist('jieba_result2', hints=hints, libraries=libraries) print(result_df.head(10)) # Display the first 10 rows of segmentation result data. You can view more data in the jieba_result2 table.Noteodps.stage.mapper.split.size can be used to improve the execution parallelism. For more information, see Flag parameters.
View the result.
View the execution result on the Runtime Log tab in the lower part of the page.
You can also click Ad Hoc Query in the left-side navigation pane of the DataStudio page and create an ad hoc query node to view the data in the jieba_result2 table.
select * from jieba_result2;
Compare the result of the segmentation code that is run by using a custom dictionary with the result of the segmentation code that is run by using the open source Jieba package.
References
For more information about how to use a PyODPS 3 node in DataWorks, see Use PyODPS in DataWorks.