To understand how MaxCompute fees are distributed and reduce costs, download your billing usage records and analyze them with Excel or MaxCompute SQL.
MaxCompute supports both subscription and pay-as-you-go billing methods for computing resources. Charges are calculated per project on a daily basis, and daily bills are generated before 06:00 the next day. For full pricing details, see Overview.
Pay-as-you-go billing types
The following table summarizes each pay-as-you-go billing type and its pricing formula. For the latest unit prices, see Computing pricing (pay-as-you-go), Storage fees, and Download pricing.
| Billing type | MeteringType value | Pricing formula |
|---|---|---|
| SQL computing | ComputationSql | Input data (GB) x SQL complexity x USD 0.0438/GB |
| Storage (standard, single-zone) | Storage | Average daily storage (GB) x USD 0.0006/GB/day |
| Long-term storage | ColdStorage | Average daily storage (GB) x unit price |
| Infrequent Access (IA) storage | LowFreqStorage | Average daily storage (GB) x unit price |
| Long-term storage access | SqlLongterm | Input data (GB) x unit price |
| IA storage access | SqlLowFrequency | Input data (GB) x unit price |
| Internet download | DownloadEx | Downloaded data (GB) x USD 0.1166/GB |
| MapReduce computing | MapReduce | Billable hours x USD 0.0690/hour/task |
| Spark computing | spark | Billable hours x USD 0.1041/hour/task |
| Tablestore external table SQL | ComputationSqlOTS | Input data (GB) x USD 0.0044/GB |
| OSS external table SQL | ComputationSqlOSS | Input data (GB) x USD 0.0044/GB |
Step 1: Download billing usage records
Go to the Usage Details page to download daily resource usage records. These records show how fees are generated, including storage and computing fees for each day and the jobs that produced them.

Configure the following parameters:

Product: Select MaxCompute(Postpay).
Billable Item:
MaxCompute(Postpay): Pay-as-you-go computing, storage, and download billing items.
ODPSDataPlus: Pay-as-you-go storage and download-related billing items in subscription projects. Select this option in either of these scenarios:
Only subscription projects exist in a region with no pay-as-you-go projects.
Before April 25, 2024, both subscription and pay-as-you-go projects existed in the China (Hong Kong) region or a region outside China. In this case, ODPSDataPlus covers projects that use subscription computing quotas by default. To download records for projects using pay-as-you-go computing quotas by default, select MaxCompute(Postpay) instead.
ODPS_QUOTA: Not used. Ignore this option.
ODPS_QUOTA_USAGE: Usage records for elastically reserved resources used for computing or data transmission.
Time Period: Specify the start and end dates for the billing data. > Note: If a job starts on December 1 and completes on December 2, set the start date to December 1. Otherwise, the job's resource usage will not appear in the downloaded records. The resource consumption record for this job appears in the December 2 bill.
Time Unit: The default value is Hour.
Click Export CSV. After the export completes, go to the Export Record page to download the usage records.
Step 2 (optional): Upload usage records to MaxCompute
This step is only needed if you plan to use MaxCompute SQL for analysis. For Excel-only analysis, skip to Step 3.
Create a table named
maxcomputefeeon the MaxCompute client (odpscmd):CREATE TABLE IF NOT EXISTS maxcomputefee ( projectid STRING COMMENT 'ProjectId' ,feeid STRING COMMENT 'MeteringId' ,meteringtime STRING COMMENT 'MeteringTime' ,type STRING COMMENT 'MeteringType, such as Storage, ComputationSql, or DownloadEx' ,starttime STRING COMMENT 'StartTime' ,storage BIGINT COMMENT 'Storage' ,endtime STRING COMMENT 'EndTime' ,computationsqlinput BIGINT COMMENT 'SQLInput(Byte)' ,computationsqlcomplexity DOUBLE COMMENT 'SQLComplexity' ,uploadex BIGINT COMMENT 'UploadEx' ,download BIGINT COMMENT 'DownloadEx(Byte)' ,cu_usage DOUBLE COMMENT 'MRCompute(Core*Second)' ,Region STRING COMMENT 'Region' ,input_ots BIGINT COMMENT 'InputOTS(Byte)' ,input_oss BIGINT COMMENT 'InputOSS(Byte)' ,source_id STRING COMMENT 'DataWorksNodeID' ,source_type STRING COMMENT 'SpecificationType' ,RecycleBinStorage BIGINT COMMENT 'RecycleBinStorage' ,JobOwner STRING COMMENT 'JobOwner' ,Signature STRING COMMENT 'Signature' );
Field descriptions
| Field | Description |
|---|---|
| ProjectId | The ID or name of a MaxCompute project belonging to your Alibaba Cloud account, or to the Alibaba Cloud account that the current RAM user belongs to. |
| MeteringId | The billing ID. For SQL computing tasks, this is the InstanceID. For upload or download tasks, this is the Tunnel SessionId. |
| MeteringType | The billing type. Valid values: Storage, ComputationSql, UploadIn, UploadEx, DownloadIn, DownloadEx. Only the items outlined in red in the billing rules are charged. Additional values include MapReduce, spark, ComputationSqlOTS, ComputationSqlOSS, ColdStorage (long-term storage), LowFreqStorage (Infrequent Access storage), SqlLongterm (long-term storage access), and SqlLowFrequency (IA storage access). |
| Storage | Volume of data read per hour, in bytes. |
| StartTime / EndTime | The time when a job started or stopped. Storage data is collected hourly. |
| SQLInput(Byte) | Amount of input data for each SQL execution, in bytes. |
| SQLComplexity | Complexity multiplier for SQL statements. This is one of the billing factors for SQL jobs. |
| UploadEx / DownloadEx(Byte) | Amount of data uploaded or downloaded over the Internet, in bytes. |
| MRCompute(Core\*Second) | Billable hours for MapReduce or Spark jobs. Calculated as: Number of cores x Running time (seconds). Convert the result to hours for billing. |
| InputOTS(Byte) / InputOSS(Byte) | Amount of data read from Tablestore or Object Storage Service (OSS) through external tables, in bytes. |
| RecycleBinStorage | Volume of backup data read per hour, in bytes. |
| Region | The region where the MaxCompute project resides. |
| JobOwner | The user who submitted the job. |
| Signature | An identifier for SQL job content. Jobs with identical SQL content share the same signature, which helps identify repeated or scheduled jobs. |
Run the following Tunnel command to upload the billing usage records: > Note: The number and data types of columns in the CSV file must match those in the
maxcomputefeetable. If they do not match, the data upload fails.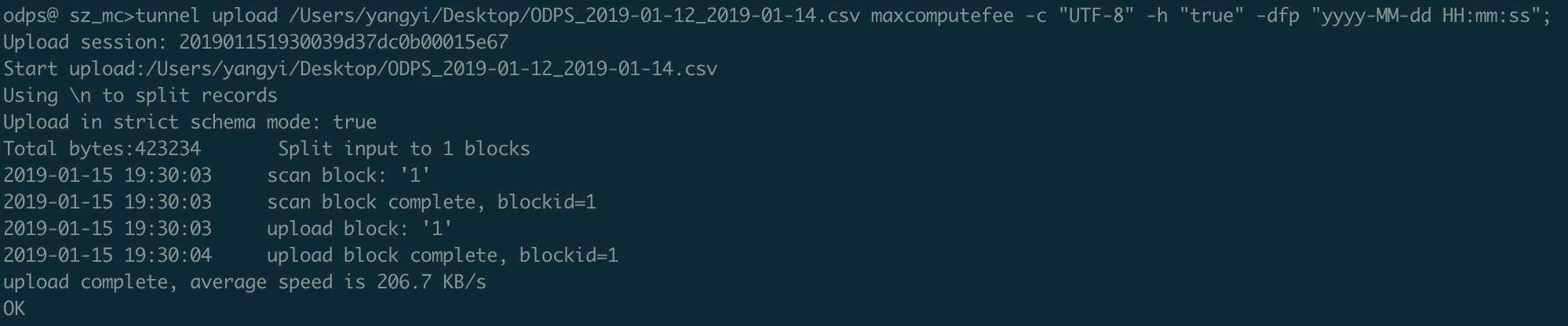 > Note: > - For more information about Tunnel commands, see Tunnel commands. > - You can also use the DataWorks data import feature to upload billing records. For details, see Use DataWorks (offline and real-time).
> Note: > - For more information about Tunnel commands, see Tunnel commands. > - You can also use the DataWorks data import feature to upload billing records. For details, see Use DataWorks (offline and real-time).tunnel upload ODPS_2019-01-12_2019-01-14.csv maxcomputefee -c "UTF-8" -h "true" -dfp "yyyy-MM-dd HH:mm:ss";Verify that all records were uploaded:

SELECT * FROM maxcomputefee limit 10;
Step 3: Analyze billing usage records
SQL job fees
Formula: Input data (GB) x SQL complexity x USD 0.0438/GB
Excel method: Filter records where MeteringType is ComputationSql. Sort by fee to identify unexpectedly expensive jobs or large job volumes. Calculate each job's fee as:
Fee = SQLInput(Byte) / 1024 / 1024 / 1024 x SQL complexity x USD 0.0438
SQL method: Make sure the data upload in Step 2 is complete and the maxcomputefee table exists.
-- Sort SQL jobs by fee (descending) to find the most expensive jobs.
SELECT to_char(endtime,'yyyymmdd') as ds,feeid as instanceid
,projectid
,computationsqlcomplexity -- SQL complexity
,SUM((computationsqlinput / 1024 / 1024 / 1024)) as computationsqlinput -- Amount of input data (GB)
,SUM((computationsqlinput / 1024 / 1024 / 1024)) * computationsqlcomplexity * 0.0438 AS sqlmoney
FROM maxcomputefee
WHERE TYPE = 'ComputationSql'
AND to_char(endtime,'yyyymmdd') >= '20190112'
GROUP BY to_char(endtime,'yyyymmdd'),feeid
,projectid
,computationsqlcomplexity
ORDER BY sqlmoney DESC
LIMIT 10000
;Optimization tips:
To reduce fees for expensive jobs, reduce the amount of input data or lower the SQL complexity.
Aggregate results by the
dsfield to analyze daily fee trends over a period. Plot the trend in Excel or a tool such as Quick BI.
Identify the DataWorks node behind a costly job:
Get the LogView URL by running the
wait <instanceid>;command on the MaxCompute client (odpscmd) or in the DataWorks console.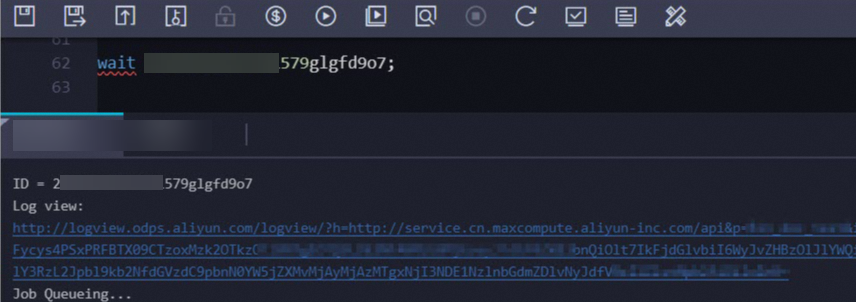
View job details with the following command: Sample output:
DESC instance 2016070102275442go3xxxxxx;ID 2016070102275442go3xxxxxx Owner ALIYUN$***@aliyun-inner.com StartTime 2016-07-01 10:27:54 EndTime 2016-07-01 10:28:16 Status Terminated console_query_task_1467340078684 Success Query select count(*) from src where ds='20160628';Open the LogView URL in a browser. Click the SourceXML tab and find the SKYNET_NODENAME parameter value.
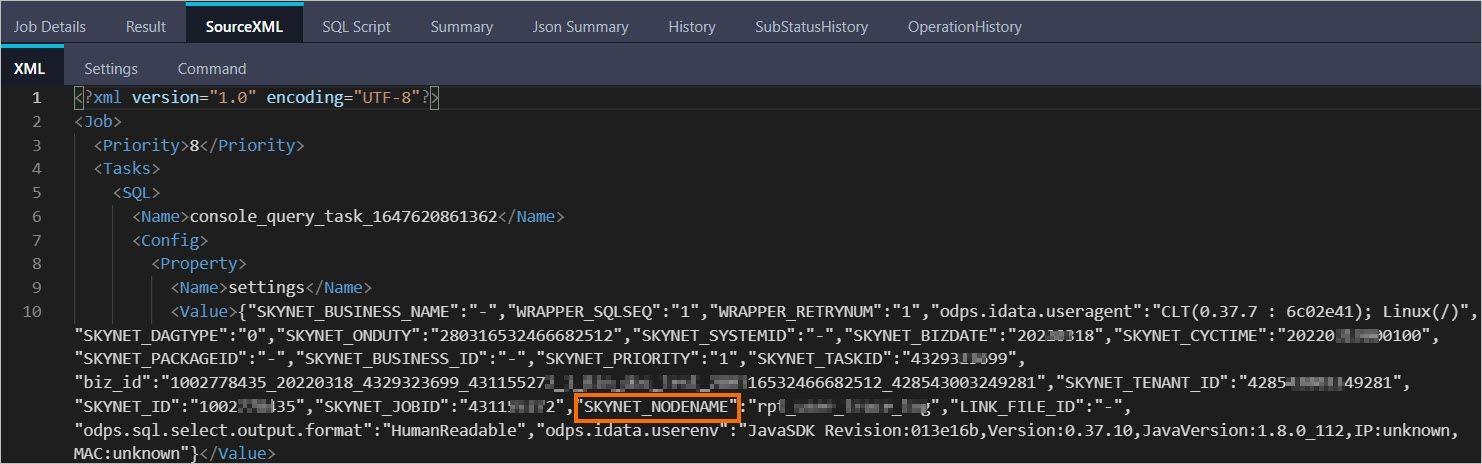 > Note: > - For more information about LogView, see Use LogView V2.0 to view job information. > - If the SKYNET_NODENAME parameter is empty, click the SQL Script tab to get the code snippet. Search for the node in the DataWorks console using that snippet. For details, see DataWorks code search.
> Note: > - For more information about LogView, see Use LogView V2.0 to view job information. > - If the SKYNET_NODENAME parameter is empty, click the SQL Script tab to get the code snippet. Search for the node in the DataWorks console using that snippet. For details, see DataWorks code search.Search for the node in the DataWorks console using the SKYNET_NODENAME value, then optimize it.
Job count trends
Fee increases often correlate with surges in job count caused by repeated operations or misconfigured scheduling settings.
Excel method: Filter records where MeteringType is ComputationSql. Count jobs per day for each project and check for unusual spikes.
SQL method: Make sure the data upload in Step 2 is complete and the maxcomputefee table exists.
-- Analyze daily job count trends.
SELECT TO_CHAR(endtime,'yyyymmdd') AS ds
,projectid
,COUNT(*) AS tasknum
FROM maxcomputefee
WHERE TYPE = 'ComputationSql'
AND TO_CHAR(endtime,'yyyymmdd') >= '20190112'
GROUP BY TO_CHAR(endtime,'yyyymmdd')
,projectid
ORDER BY tasknum DESC
LIMIT 10000
;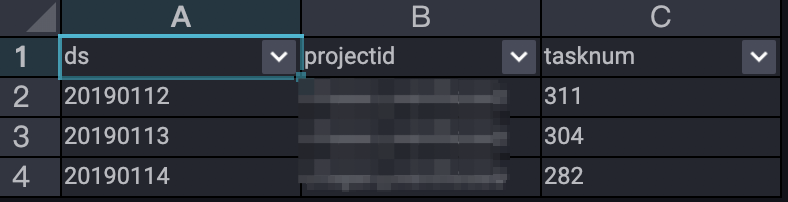
This result shows job submission trends from January 12 to January 14, 2019.
Storage fees
Minimum charge for small projects
View records where MeteringType is Storage. A project like maxcompute_doc with only 508 bytes of data is still charged CNY 0.01 because any storage up to 512 MB is billed at a flat minimum rate per storage billing rules.
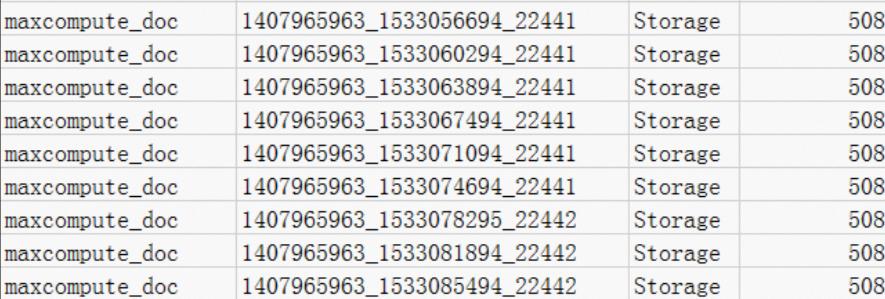
If the data is only used for testing:
Execute the
Drop Tablestatement to delete the table data.If the entire project is no longer needed, log on to the MaxCompute console and delete the project on the Projects page.
Data stored less than one day
View records where MeteringType is Storage. For example, the alian project stores 333,507,833,900 bytes of data, uploaded at 08:00. Billing starts from 09:07, resulting in 15 hours of storage charges. > Note: When the billing cycle is one day, billing stops at the end of each day. The last hourly record is not included in that day's bill.
Calculate the average storage and daily fee per storage billing rules:
-- Average storage 333507833900 Byte x 15 / 1024 / 1024 / 1024 / 24 = 194.127109076362103 GB -- Daily storage fee (standard storage: USD 0.0006/GB/day) 194.127109076362103 GB x USD 0.0006 per GB per day = USD 0.1165 per day
Analyze storage fees with SQL
Formula: Tiered pricing applies. Storage less than 0.5 GB: CNY 0.01/GB/day. Storage 0.5 GB or above: CNY 0.004/GB/day.
SQL method: Make sure the data upload in Step 2 is complete and the maxcomputefee table exists.
-- Analyze storage fees.
SELECT t.ds
,t.projectid
,t.storage
,CASE WHEN t.storage < 0.5 THEN t.storage*0.01 --- If the actually used storage space of a project is greater than 0 MB and less than or equal to 512 MB, the unit price for the storage space is CNY 0.01 per GB per day.
WHEN t.storage >= 0.5 THEN t.storage*0.004 --- If the actually used storage space of a project is greater than 512 MB, the unit price for the storage space is CNY 0.004 per GB per day.
END storage_fee
FROM (
SELECT to_char(starttime,'yyyymmdd') as ds
,projectid
,SUM(storage/1024/1024/1024)/24 AS storage
FROM maxcomputefee
WHERE TYPE = 'Storage'
and to_char(starttime,'yyyymmdd') >= '20190112'
GROUP BY to_char(starttime,'yyyymmdd')
,projectid
) t
ORDER BY storage_fee DESC
;
Optimization tip: To reduce storage fees, specify a lifecycle for tables and delete unnecessary temporary tables.
Long-term and IA storage fees
The unit prices in the following SQL queries may not reflect the latest pricing. Before using these queries, verify the current unit prices for long-term storage, IA storage, and their data access fees on the Storage fees page, and update the price multipliers in the queries accordingly.
The following queries analyze fees for long-term storage (MeteringType: ColdStorage), Infrequent Access storage (MeteringType: LowFreqStorage), and their respective data access fees (SqlLongterm and SqlLowFrequency). Make sure the data upload in Step 2 is complete and the maxcomputefee table exists.
-- Analyze long-term storage fees.
SELECT to_char(starttime,'yyyymmdd') as ds
,projectid
,SUM(storage/1024/1024/1024)/24*0.0011 AS longTerm_storage
FROM maxcomputefee
WHERE TYPE = 'ColdStorage'
and to_char(starttime,'yyyymmdd') >= '20190112'
GROUP BY to_char(starttime,'yyyymmdd')
,projectid;
-- Analyze the IA storage fees.
SELECT to_char(starttime,'yyyymmdd') as ds
,projectid
,SUM(storage/1024/1024/1024)/24*0.0011 AS lowFre_storage
FROM maxcomputefee
WHERE TYPE = 'LowFreqStorage'
and to_char(starttime,'yyyymmdd') >= '20190112'
GROUP BY to_char(starttime,'yyyymmdd')
,projectid;
-- Analyze long-term storage access fees.
SELECT to_char(starttime,'yyyymmdd') as ds
,projectid
,SUM(computationsqlinput/1024/1024/1024)*0.522 AS longTerm_IO
FROM maxcomputefee
WHERE TYPE = 'SqlLongterm'
and to_char(starttime,'yyyymmdd') >= '20190112'
GROUP BY to_char(starttime,'yyyymmdd')
,projectid;
-- Analyze IA storage access fees.
SELECT to_char(starttime,'yyyymmdd') as ds
,projectid
,SUM(computationsqlinput/1024/1024/1024)*0.522 AS lowFre_IO
FROM maxcomputefee
WHERE TYPE = 'SqlLowFrequency'
and to_char(starttime,'yyyymmdd') >= '20190112'
GROUP BY to_char(starttime,'yyyymmdd')
,projectid;Download fees
Formula: Downloaded data (GB) x USD 0.1166/GB
Excel method: Filter records where MeteringType is DownloadEx. For example, a record showing 0.036 GB (38,199,736 bytes) of download traffic results in a fee of:
(38,199,736 / 1024 / 1024 / 1024) x USD 0.1166 = USD 0.004
See Download fees (pay-as-you-go) for the full pricing rules.
Optimization tip: Check whether your Tunnel service is incurring Internet access charges. For endpoint details, see Endpoint. For example, if you are in Suzhou (part of the China (Shanghai) region) and need to download large volumes of data, use an Elastic Compute Service (ECS) instance in the China (Shanghai) region to download data to your VM first, avoiding Internet download fees.
SQL method: Make sure the data upload in Step 2 is complete and the maxcomputefee table exists.
-- Analyze download fees.
SELECT TO_CHAR(starttime,'yyyymmdd') AS ds
,projectid
,SUM((download/1024/1024/1024)*0.1166) AS download_fee
FROM maxcomputefee
WHERE type = 'DownloadEx'
AND TO_CHAR(starttime,'yyyymmdd') >= '20190112'
GROUP BY TO_CHAR(starttime,'yyyymmdd')
,projectid
ORDER BY download_fee DESC
;MapReduce job fees
Formula: Billable hours x USD 0.0690/hour/task
Excel method: Filter records where MeteringType is MapReduce. Calculate and sort fees using:
Fee = Number of cores x Running time (seconds) / 3600 x USD 0.0690
SQL method: Make sure the data upload in Step 2 is complete and the maxcomputefee table exists.
-- Analyze the fees of MapReduce jobs.
SELECT TO_CHAR(starttime,'yyyymmdd') AS ds
,projectid
,(cu_usage/3600)*0.0690 AS mr_fee
FROM maxcomputefee
WHERE type = 'MapReduce'
AND TO_CHAR(starttime,'yyyymmdd') >= '20190112'
GROUP BY TO_CHAR(starttime,'yyyymmdd')
,projectid
,cu_usage
ORDER BY mr_fee DESC
;Spark job fees
Formula: Billable hours x USD 0.1041/hour/task
Excel method: Filter records where MeteringType is spark. Calculate fees as:
Fee = Number of cores x Running time (seconds) / 3600 x USD 0.1041
SQL method: Make sure the data upload in Step 2 is complete and the maxcomputefee table exists.
-- Analyze the fees of Spark jobs.
SELECT TO_CHAR(starttime,'yyyymmdd') AS ds
,projectid
,(cu_usage/3600)*0.1041 AS mr_fee
FROM maxcomputefee
WHERE type = 'spark'
AND TO_CHAR(starttime,'yyyymmdd') >= '20190112'
GROUP BY TO_CHAR(starttime,'yyyymmdd')
,projectid
,cu_usage
ORDER BY mr_fee DESC
;External table fees (Tablestore and OSS)
Formula: Input data (GB) x USD 0.0044/GB
Excel method: Filter records where MeteringType is ComputationSqlOTS or ComputationSqlOSS. Calculate fees as:
Fee = SQLInput(Byte) / 1024 / 1024 / 1024 x USD 0.0044
The unit price in the SQL queries below (0.03) does not match the current official unit price (USD 0.0044/GB). Update the price multiplier in the queries to match the current pricing on the Computing pricing (pay-as-you-go) page.
SQL method: Make sure the data upload in Step 2 is complete and the maxcomputefee table exists.
-- Analyze the fees of SQL jobs that use Tablestore external tables.
SELECT TO_CHAR(starttime,'yyyymmdd') AS ds
,projectid
,(computationsqlinput/1024/1024/1024)*1*0.03 AS ots_fee
FROM maxcomputefee
WHERE type = 'ComputationSqlOTS'
AND TO_CHAR(starttime,'yyyymmdd') >= '20190112'
GROUP BY TO_CHAR(starttime,'yyyymmdd')
,projectid
,computationsqlinput
ORDER BY ots_fee DESC
;
-- Analyze the fees of SQL jobs that use OSS external tables.
SELECT TO_CHAR(starttime,'yyyymmdd') AS ds
,projectid
,(computationsqlinput/1024/1024/1024)*1*0.03 AS oss_fee
FROM maxcomputefee
WHERE type = 'ComputationSqlOSS'
AND TO_CHAR(starttime,'yyyymmdd') >= '20190112'
GROUP BY TO_CHAR(starttime,'yyyymmdd')
,projectid
,computationsqlinput
ORDER BY oss_fee DESC
;References
TO_CHAR is a date or string function in MaxCompute SQL. For details, see TO_CHAR.
For more information about bill fluctuations and cost analysis, see View billing details.