This topic describes the algorithms and syntax that are used to detect time series anomalies.
Applicable engines and versions
The time series anomaly detection syntax is applicable only to LindormTSDB. The time series anomaly detection syntax is supported by all versions of LindormTSDB.
Limits
The time series anomaly detection syntax must be used together with the SAMPLE BY clause.
Overview
Time series anomaly detection supports the online anomaly detection algorithms developed by DAMO Academy to detect abnormal points in the specified time series. During detection, these algorithms continuously learn the characteristics of time series data, such as data trends or periods, to detect anomalies in time series points that are newly inserted. For example, if the value of a newly-added time series point is significantly different from other points, the algorithm assumes that this point may be abnormal.
You can use time series anomaly detection with the SAMPLE BY clause by using the following methods:
Use the
SAMPLE BY 0clause to detect each data point in all time series. For more information about how to use the clause, see Example 1, Example 2, and Example 3.Use the
SAMPLE BY INTERVALclause to specify the downsampling interval and use nested downsampling operators, such as MIN, MAX, AVG, COUNT, and SUM.ImportantThe value of INTERVAL cannot be 0.
For more information about how to use the clause, see Example 4.
Use the
SAMPLE BY 0clause and nested downsampling operators, such as LATEST, DELTA, and RATE, to query different data. For more information about how to use the clause, see Example 5.
Syntax
select_sample_by_statement ::= SELECT ( select_clause )
FROM table_identifier
WHERE where_clause
SAMPLE BY 0
select_clause ::= selector [ AS identifier ] ( ',' selector [ AS identifier ] )
selector ::= tag_identifier, | time | anomaly_detect '(' field_identifier ',' algo_identifier | model_identifier [ ',' options] ')'
where_clause ::= relation ( AND relation )* (OR relation)*
relation ::= ( field_identifier| tag_identifier, ) operator term
operator ::= '=' | '<' | '>' | '<=' | '>=' | '!=' | IN | CONTAINS | CONTAINS KEYIn the syntax, anomaly_detect indicates the anomaly detection function. The following table describes the parameters that you can configure.
Parameter | Description |
field_identifier | The name of the field column. Note Data in the specified field column cannot be of the VARCHAR or BOOLEAN type. |
algo_identifier | The name of the algorithm used to detect anomalies. The online anomaly detection algorithms developed by DAMO Academy are supported.
Note The algo_identifier parameter is applicable to scenarios in which in-database machine learning is not enabled and anomalies related to time series data must be detected. |
model_identifier | The name of the model used to detect anomalies. Note
|
options | The options used to adjust the detection effect. This parameter is optional. Configure the options in the |
Category
The following table describes the anomaly detection algorithms supported by LindormTSDB and scenarios to which the algorithms are applicable.
Algorithm | Scenario |
esd |
|
nsigma |
Note We recommend that you do not use this algorithm to detect a small numbers of abnormal points whose values are significantly different from other points. In this case, the detection results returned by this algorithm may be inaccurate. |
ttest |
|
Incremental STL with ESD (istl-esd) | This algorithm is applicable to detect anomalies in periodic data. The istl-esd algorithm is an Incremental STL algorithm developed by DAMO Academy. The Incremental STL algorithm can decompose periodic incremental data into periodic terms, trend terms, and residual terms. The istl-esd algorithm integrates the Incremental STL algorithm with the esd algorithm. The Incremental STL algorithm is used to decompose periodic incremental data, and the esd algorithm is used to detect anomalies in the residual terms decomposed from the periodic data. The esd algorithm can detect non-periodic spikes based on the decomposed residual terms. |
Incremental STL with Nsigma (istl-nsigma) | This algorithm is applicable to detect anomalies in periodic data. The Incremental STL algorithm can decompose periodic incremental data into periodic terms, trend terms, and residual terms. The istl-nsigma algorithm integrates the Incremental STL algorithm with the nsigma algorithm. The Incremental STL algorithm is used to decompose periodic incremental data, and the nsigma algorithm is used to detect anomalies in the residual terms decomposed from the periodic data. The nsigma algorithm can detect non-periodic spikes based on the decomposed residual terms. |
The following figures show the application scenarios of different algorithms.
esd: This algorithm can be used to detect each data point in time series and is applicable to scenarios in which a small number of abnormal data points exist among a large number of normal data points with stable values.
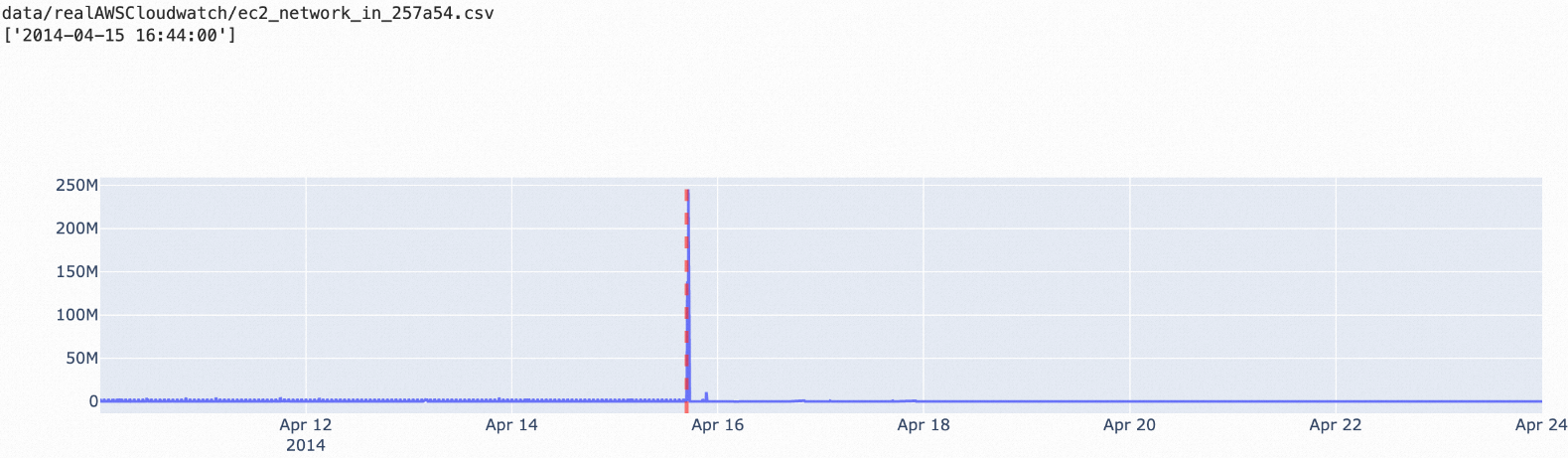
nsigma: This algorithm can be used to detect each data point in time series and is applicable to scenarios in which the values of abnormal data points are significantly different from the historical average value. You can configure the n parameter of this algorithm to adjust the allowed difference between the value of a data point and the historical average value.
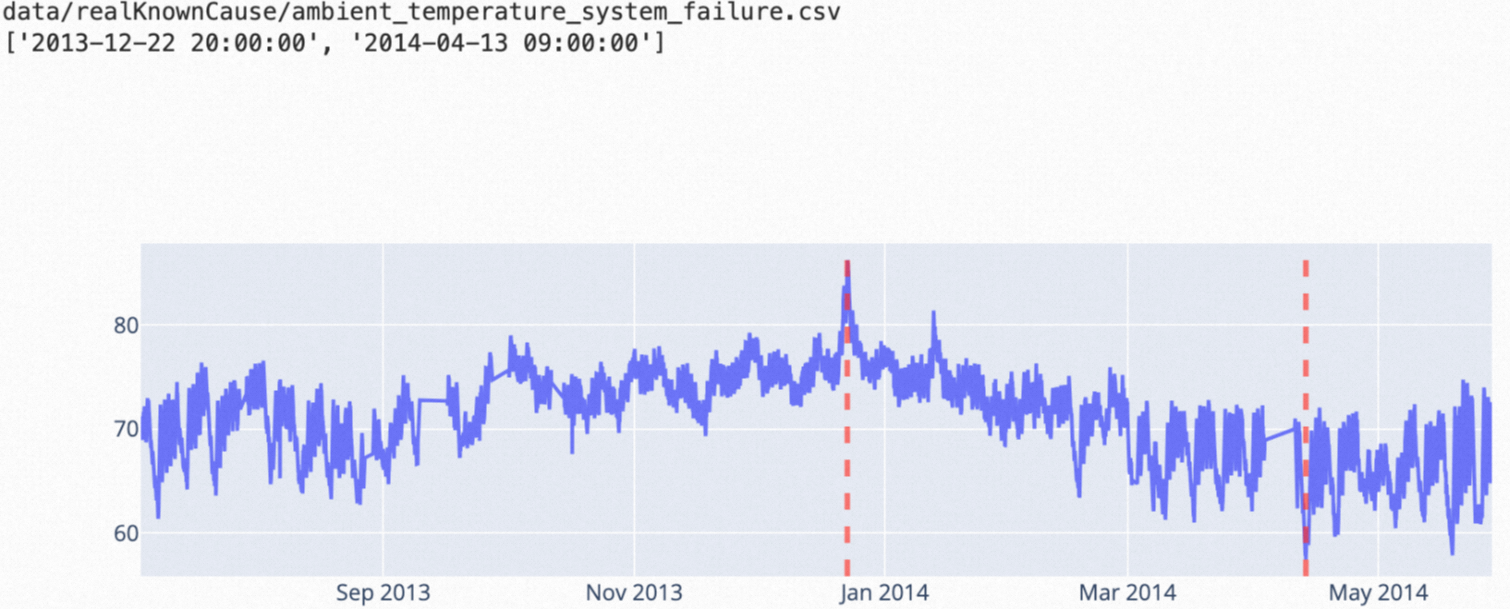
ttest: This algorithm can be used to detect anomalies from time series data within a time window and is applicable to scenarios in which the average value of the specified metrics significantly varies within two consecutive time windows.
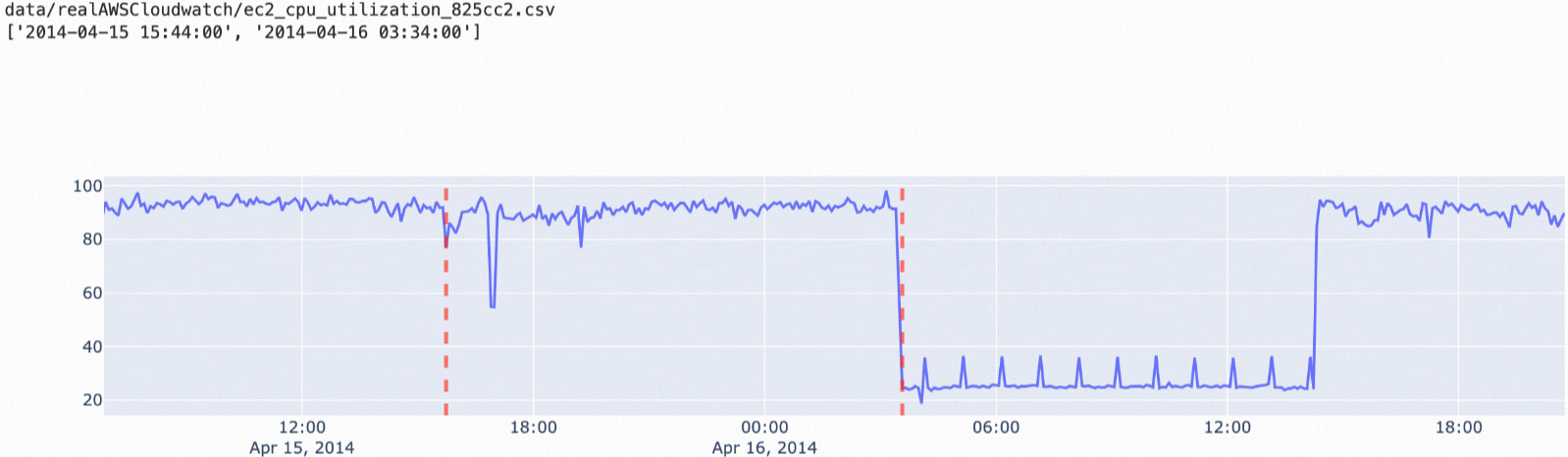
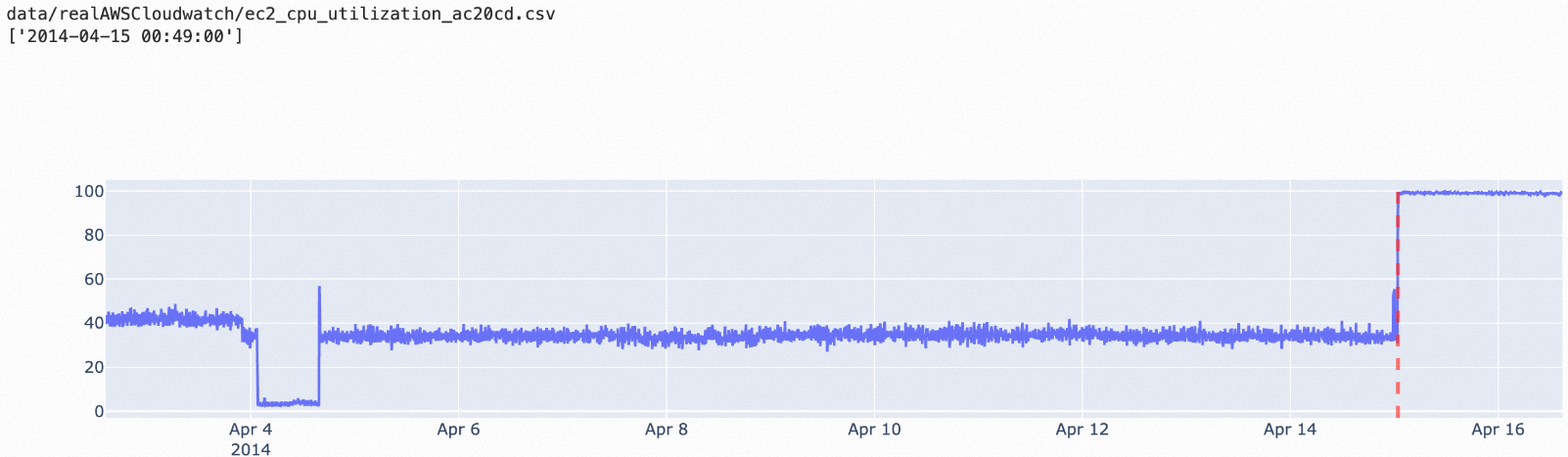
istl-esd: This algorithm can be used to detect anomalies in periodic time series data. This algorithm removes the periodic terms of the original data and then uses the esd algorithm to detect anomalies. The istl-esd algorithm is applicable to scenarios in which a small number of abnormal data points exist among a large number of normal periodic data points with stable values.
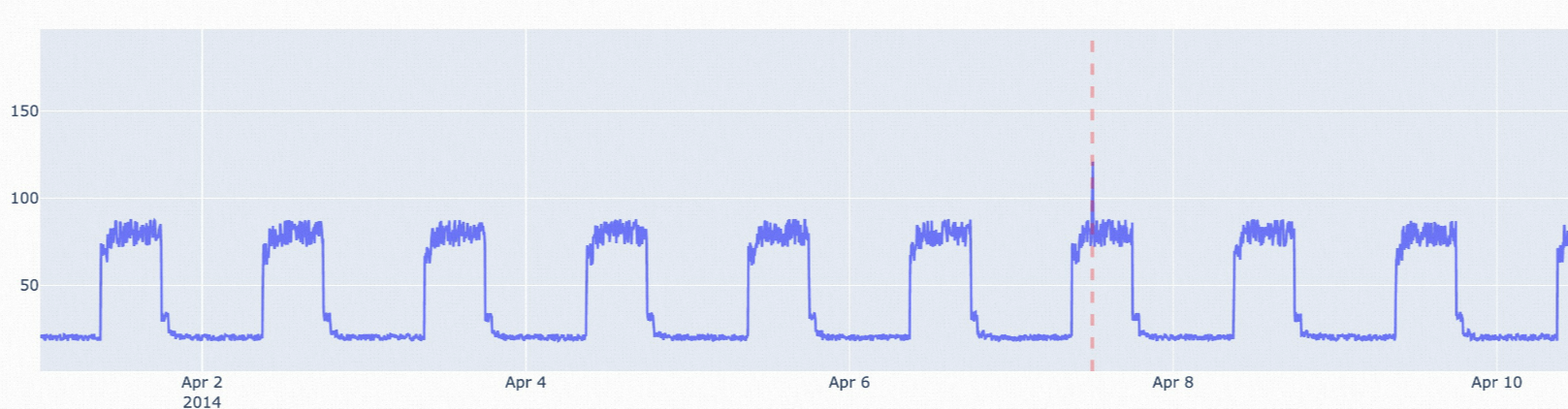
istl-nsigma: This algorithm can be used to detect anomalies in periodic time series data. This algorithm removes the periodic terms of the original data and then uses the nsigma algorithm to detect anomalies. The istl-nsigma algorithm is applicable to scenarios in which the values of abnormal data points are significantly different from the historical average value.
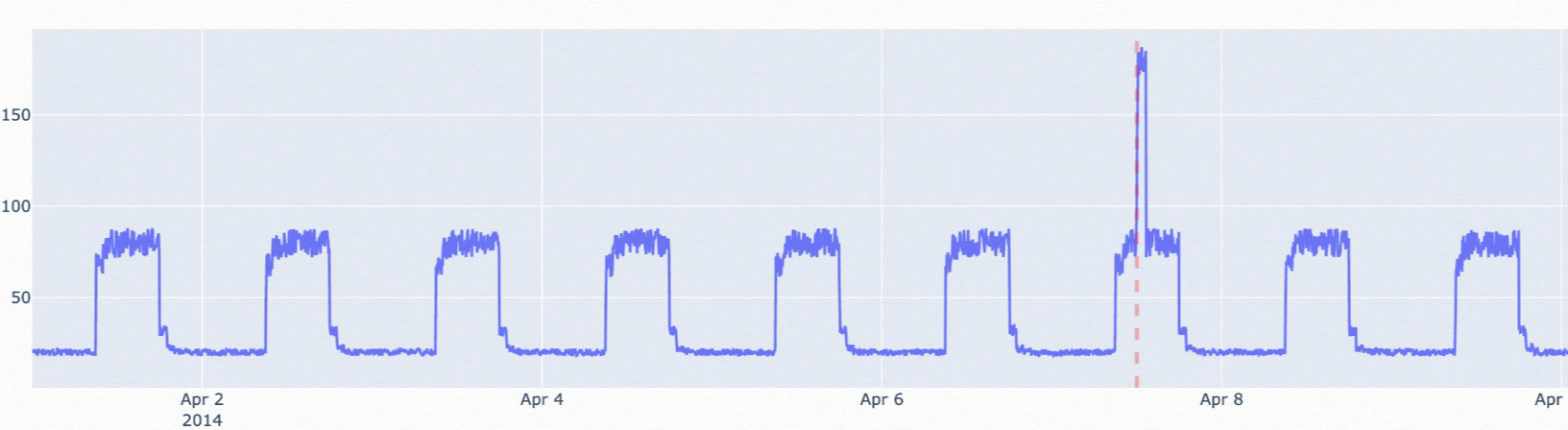
Parameters
You can configure parameters for the anomaly detection algorithms that you use. These parameters can be categorized into common parameters, training parameters, and inference parameters. You can specify the optional parameter options to adjust the detection performance of the anomaly detection algorithm.
Common parameters, training parameters, and inference parameters are configured in the same parameter list. For example, you can configure parameters for the ttest algorithm in the following format:
lenDetectWindow=100,adhoc_stat=true.For more information about how to configure parameters for ideal detection results, see Parameter tuning for statistical algorithms and Parameter tuning for decomposition algorithms.
Common parameters
You can configure common parameters to control the debugging, diagnosis, and other behaviors performed by algorithms during anomaly detection. Common parameters are applicable for all supported anomaly detection algorithms. The following table describes the common parameters that you can configure.
Parameter | Type | Default value | Description |
verbose | BOOLEAN | FALSE | Specifies whether to return detailed information and identify the detection result of the specified columns. The returned information varies with the algorithm that you use. Valid values:
If you set this parameter to |
adhoc_state | BOOLEAN | FALSE | Specifies whether the anomaly detection status of the algorithm is available only in the current query. For more information about the anomaly detection status, see Exception detection status. |
direction | VARCHAR | UP | The types of anomalies that you want to detect. Valid values:
|
Training parameters
You can specify an algorithm and configure the training parameters to determine the model used to detect anomalies. The values of training parameters are cleared after you restart LindormTSDB. In this case, you must configure the training parameters again to train the model. The model is trained in real time during detection to adapt to learn and adapt the characteristics of the time series data.
Take note of the following items when you configure training parameters:
The names of the parameters are not case-sensitive.
The values of training parameters can be digits and strings and cannot be NULL.
The values of the parameters must be within the specific ranges.
Algorithm | Parameter | Type | Valid value | Description |
esd | compression | INTEGER | A positive integer. Valid values: | The spatial complexity of the data structure in the algorithm. A larger value of this parameter indicates that the algorithm uses more memory during detection and returns more accurate results. |
lenHistoryWindow | INTEGER | Valid values: positive integers that are equal to or larger than 20. Default value: null. | The length of the reference time window. If you specify a short reference time window, only the recent data points within the time window are used as references during the detection. If you set this parameter to null, all data points that are inserted after the first detection are used as references. | |
nsigma | lenHistoryWindow | INTEGER | Valid values: positive integers that are equal to or larger than 20. Default value: null. | The length of the reference time window. If you specify a short reference time window, only the recent data points within the time window are used as references during the detection. If you set this parameter to null, all data points that are inserted after the first detection are used as references. |
ttest | lenDetectWindow | INTEGER | A positive integer. Default value: 10. | The length of the most recent time window within which you want to detect anomalies. |
lenHistoryWindow | INTEGER | Valid values: positive integers that are equal to or larger than 20. Default value: 100. | The length of the reference time window. If you specify a short reference time window, only the recent data points within the time window are used as references during the detection. If you set this parameter to Note The value of this parameter must be larger than the value of lenDetectWindow. | |
istl-esd | frequency | VARCHAR | A string that consists of a digit and a time unit. Examples: 5M, 24H, and 1D. Valid time units:
| The frequency at which the time series data is collected. For example, if one time series data point is collected per hour, set this parameter to Important
|
periods | VARCHAR | A string that consists of a digit and a time unit. Examples: 5M, 24H, and 1D. Valid time units:
| The total period length of the periodic data. You can use indexers to specify multiple period lengths. Example: Note If this parameter is not specified, the algorithm automatically calculates the period. | |
esd.* | N/A | The training parameters that are required to define the esd algorithm. These parameters are the same as the training parameters described in the esd section of this table. You can add the esd. prefix to the training parameters of the esd algorithm to configure these parameters. Example: | ||
istl-nsigma | frequency | VARCHAR | A string that consists of a digit and a time unit. Examples: 5M, 24H, and 1D. Valid time units:
| The frequency at which the time series data is collected. For example, if one time series data point is collected per hour, set this parameter to Important
|
periods | VARCHAR | A string that consists of a digit and a time unit. Examples: 5M, 24H, and 1D. Valid time units:
| The total period length of the periodic data. You can use indexers to specify multiple period lengths. Example: Note If this parameter is not specified, the algorithm automatically calculates the period. | |
nsigma.* | N/A | The training parameters that are required to define the nsigma algorithm. These parameters are the same as the training parameters described in the nsigma section of this table. You can add the nsigma. prefix to the training parameters of the nsigma algorithm to configure these parameters. Example: | ||
Inference parameters
Inference parameters take effect only during anomaly detection and are not case-sensitive.
Algorithm | Parameter | Type | Valid value | Description |
esd | alpha | DOUBLE | Default value: 0.1. Valid values: | The sensitivity of anomaly detection. A larger value of this parameter indicates that the algorithm is more sensitive to anomalies and reports more anomalies. |
direction | VARCHAR | Default value: Up. | The types of anomalies that you want to detect.
| |
maxAnomalyRatio | DOUBLE | Default value: 0.3. Valid values: | The maximum ratio based on which anomalies are detected. For example, if you set maxAnomalyRatio to 0.3 and direction to Up, data points whose values are less than the 70th percentile are not detected as anomalies.
| |
warmupCount | INTEGER | A positive integer. Default value: 20. | The minimum number of data points that is required for the algorithm to start to report anomalies. For example, if you set this parameter to 20, the algorithm does not report anomalies when the number of data points that need to be detected is less than 20. | |
nsigma | n | DOUBLE | A non-zero floating-point number. Default value: 3.0. |
|
warmupCount | INTEGER | A positive integer. Default value: 20. | The minimum number of data points that is required for the algorithm to start to report anomalies. For example, if you set this parameter to 20, the algorithm does not report anomalies when the number of data points that need to be detected is less than 20. | |
ttest | alpha | DOUBLE | Default value: 0.05. Valid values: | The sensitivity of anomaly detection. A larger value of this parameter indicates that the algorithm is more sensitive to anomalies and reports more anomalies. |
direction | VARCHAR | Default value: Up. | The types of anomalies that you want to detect.
| |
istl-esd | esd.* | N/A | The inference parameters that are required to define the esd algorithm. These parameters are the same as the inference parameters described in the esd section of this table. You can add the | |
istl-nsigma | nsigma.* | N/A | Define the inference parameters required by the nsigma algorithm. For more information, see Inference parameters of the nsigma algorithm. You can add the | |
Examples
Example 1: Use the esd algorithm to detect anomalies in the temperature data within a specific time range in a time series table named sensor.
SELECT device_id, region, time, anomaly_detect(temperature, 'esd') AS detect_result FROM sensor WHERE time >= '2022-01-01 00:00:00' and time < '2022-01-01 00:01:00' SAMPLE BY 0;The following result is returned:
+-----------+----------+---------------------------+---------------+ | device_id | region | time | detect_result | +-----------+----------+---------------------------+---------------+ | F07A1260 | north-cn | 2022-01-01T00:00:00+08:00 | true | | F07A1260 | north-cn | 2022-01-01T00:00:01+08:00 | false | | F07A1260 | north-cn | 2022-01-01T00:00:02+08:00 | true | | F07A1261 | south-cn | 2022-01-01T00:00:00+08:00 | false | | F07A1261 | south-cn | 2022-01-01T00:00:01+08:00 | false | | F07A1261 | south-cn | 2022-01-01T00:00:02+08:00 | false | | F07A1261 | south-cn | 2022-01-01T00:00:03+08:00 | false | +-----------+----------+---------------------------+---------------+Example 2: Use the esd algorithm to detect anomalies in the temperature data of the F07A1260 device within a specific time range in the sensor table.
SELECT device_id, region, time, anomaly_detect(temperature, 'esd') AS detect_result FROM sensor WHERE device_id in ('F07A1260') and time >= '2022-01-01 00:00:00' and time < '2022-01-01 00:01:00' SAMPLE BY 0;The following result is returned:
+-----------+----------+---------------------------+---------------+ | device_id | region | time | detect_result | +-----------+----------+---------------------------+---------------+ | F07A1260 | north-cn | 2022-01-01T00:00:00+08:00 | true | | F07A1260 | north-cn | 2022-01-01T00:00:01+08:00 | false | | F07A1260 | north-cn | 2022-01-01T00:00:02+08:00 | true | +-----------+----------+---------------------------+---------------+Example 3: Use the esd algorithm and configure parameters to detect anomalies in the temperature data of the F07A1260 device within a specific time range in the sensor table.
SELECT device_id, region, time, anomaly_detect(temperature, 'esd', 'lenHistoryWindow=30,maxAnomalyRatio=0.1') AS detect_result FROM sensor WHERE device_id in ('F07A1260') and time >= '2022-01-01 00:00:00' and time < '2022-01-01 00:01:00' SAMPLE BY 0;The following result is returned:
+-----------+----------+---------------------------+---------------+ | device_id | region | time | detect_result | +-----------+----------+---------------------------+---------------+ | F07A1260 | north-cn | 2022-01-01T00:00:00+08:00 | false | | F07A1260 | north-cn | 2022-01-01T00:00:01+08:00 | false | | F07A1260 | north-cn | 2022-01-01T00:00:02+08:00 | true | +-----------+----------+---------------------------+---------------+Example 4: Use the nested downsampling operator MAX in the statement and specify the downsampling interval as 1 minute.
SELECT time, anomaly_detect(max(temperature), 'esd') AS ad_result, max(temperature) AS rawVal FROM sensor SAMPLE BY 1m;The following result is returned:
+---------------------------+-----------+-------------+ | time | ad_result | rawVal | +---------------------------+-----------+-------------+ | 2022-04-12T06:00:00+08:00 | null | 923091.3175 | | 2022-04-11T08:00:00+08:00 | null | 8035700 | | 2022-04-11T09:00:00+08:00 | null | 8035690.25 | | 2022-04-11T10:00:00+08:00 | null | 3306277.545 | | 2022-04-11T11:00:00+08:00 | null | 5921167.787 | | 2022-04-11T12:00:00+08:00 | null | 833541.304 | +---------------------------+-----------+-------------+Example 5: Use the nested non-downsampling operator LATEST in the statement and specify the downsampling interval as 0.
SELECT time, anomaly_detect(latest(temperature), 'esd') AS ad_result, latest(temperature) AS latestVal FROM sensor SAMPLE BY 0;The following result is returned:
+---------------------------+-----------+-------------+ | time | ad_result | latestVal | +---------------------------+-----------+-------------+ | 2022-04-12T06:00:00+08:00 | false | 923091.3175 | | 2022-04-13T07:00:00+08:00 | false | 8037506.75 | | 2022-04-13T07:00:00+08:00 | false | 50490.2 | +---------------------------+-----------+-------------+