You can use the vector processing feature of Hologres in multiple scenarios, such as similarity searches, image retrieval, and scenario recognition. You can flexibly use vector processing to improve data processing and analysis, and implement more accurate searches and recommendations. This topic describes how to use Proxima to perform vector processing in Hologres and provides related examples.
Procedure
Connect to a Hologres instance.
Use a development tool to connect to a Hologres instance. For more information, see Overview. If you use the Java Database Connectivity (JDBC) driver to connect to a Hologres instance, you must use prepared statements.
Install the Proxima extension.
Proxima is connected to Hologres as an extension. You must execute the following statement to install the Proxima extension as a superuser:
-- Install the Proxima extension. CREATE EXTENSION proxima;The Proxima extension works at the database level. You need to install it only once for each database. To drop the extension, execute the following statement:
DROP EXTENSION proxima;ImportantWe recommend that you do not execute the
DROP EXTENSION <extension_name> CASCADE;statement to drop an extension. The CASCADE statement drops not only the specified extension but also the extension data and the objects that depend on the extension. The extension data includes the PostGIS data, roaring bitmap data, Proxima data, binary log data, and BSI data. The objects include metadata, tables, views, and server data.Create a vector table and configure vector indexes.
In Hologres, vectors are arrays of FLOAT4 elements. To create a vector table, use the following syntax.
NoteVector indexes are supported only in column-oriented tables and row-column hybrid tables
When you define a vector, you must set the array dimension to
1. The second input parameter ofarray_ndimsandarray_lengthmust be set to1.In Hologres V2.0.11 and later, you can import data before you build vector indexes. You do not need to build vector indexes for files in the compaction process. This reduces the time for building indexes.
You can build vector indexes before you import data in real-time data processing scenarios.
-- Configure a single index. BEGIN; CREATE TABLE feature_tb ( id BIGINT, feature_col FLOAT4[] CHECK(array_ndims(feature_col) = 1 AND array_length(feature_col, 1) = <value>) -- Define a vector. ); CALL set_table_property( 'feature_tb', 'proxima_vectors', '{"<feature_col>":{"algorithm":"Graph", "distance_method":"<value>", "builder_params":{"min_flush_proxima_row_count" : 1000, "min_compaction_proxima_row_count" : 1000, "max_total_size_to_merge_mb" : 2000}}}'); -- Build an index for the vector field. COMMIT; -- Configure multiple indexes. BEGIN; CREATE TABLE t1 ( f1 INT PRIMARY KEY, f2 FLOAT4[] NOT NULL CHECK(array_ndims(f2) = 1 AND array_length(f2, 1) = 4), f3 FLOAT4[] NOT NULL CHECK(array_ndims(f3) = 1 AND array_length(f3, 1) = 4) ); CALL set_table_property( 't1', 'proxima_vectors', '{"f2":{"algorithm":"Graph", "distance_method":"InnerProduct", "builder_params":{"min_flush_proxima_row_count" : 1000, "min_compaction_proxima_row_count" : 1000, "max_total_size_to_merge_mb" : 2000}}, "f3":{"algorithm":"Graph", "distance_method":"InnerProduct", "builder_params":{"min_flush_proxima_row_count" : 1000, "min_compaction_proxima_row_count" : 1000, "max_total_size_to_merge_mb" : 2000}}}'); COMMIT;You can import data before you build vector indexes in offline data processing scenarios.
NoteHologres V2.1.17 and later support the Serverless Computing feature. The Serverless Computing feature is suitable for scenarios in which you want to import a large amount of data offline or query a large amount of data from foreign tables. You can use the Serverless Computing feature to perform the preceding operations based on additional serverless computing resources. This can eliminate the need to reserve additional computing resources for the instances. This improves instance stability and reduces the occurrences of out of memory (OOM) errors. You are charged only for the additional serverless computing resources used by tasks. For more information about the Serverless Computing feature, see Overview of Serverless Computing. For more information about how to use the Serverless Computing feature, see Serverless Computing guide.
-- Configure a single index. BEGIN; CREATE TABLE feature_tb ( id BIGINT, feature_col FLOAT4[] CHECK(array_ndims(feature_col) = 1 AND array_length(feature_col, 1) = <value>) -- Define a vector. ); COMMIT; -- Optional. We recommend that you use the Serverless Computing feature to import a large amount of data offline and run extract, transform, and load (ETL) jobs. SET hg_computing_resource = 'serverless'; -- Import data. INSERT INTO feature_tb ...; VACUUM feature_tb; -- Create an index for the vector field. CALL set_table_property( 'feature_tb', 'proxima_vectors', '{"<feature_col>":{"algorithm":"Graph", "distance_method":"<value>", "builder_params":{"min_flush_proxima_row_count" : 1000, "min_compaction_proxima_row_count" : 1000, "max_total_size_to_merge_mb" : 2000}}}'); -- Reset the configurations. This ensures that serverless computing resources are not used for subsequent SQL statements. RESET hg_computing_resource;
The following table describes the parameters in the preceding syntax.
Category
Parameter
Description
Example
Basic vector properties
feature_col
The name of the vector field.
feature
array_ndims
The dimension of the vector. Only one-dimensional vectors are supported.
Create a one-dimensional vector with the length of 4.
feature float4[] check(array_ndims(feature) = 1 and array_length(feature, 1) = 4)array_length
The length of the vector. Maximum value: 1000000.
Vector index settings
proxima_vectors
The method in which the index is built for the vector field. The following parameters are nested under this parameter:
algorithm: the algorithm that is used to build the index. The only valid value is
Graph.distance_method: the distance calculation function that is used to build the index. Hologres supports the following distance calculation functions:
SquaredEuclidean: calculates the squared Euclidean distance. This function provides the highest query efficiency. We recommend that you use this function. This function is suitable for queries that use
pm_approx_squared_euclidean_distance.Euclidean: calculates the Euclidean distance. This function is suitable only for queries that use
pm_approx_euclidean_distance. If you use other distance calculation functions, the index is not used.InnerProduct: calculates the inner-product distance. The calculation method provided by this function is converted into the calculation of the Euclidean distance at the underlying layer. Therefore, this function incurs a high computing overhead in index building and index-based queries and is inefficient. Unless otherwise required, we recommend that you do not use this function. This function is suitable only for queries that use
pm_approx_inner_product_distance.
build_params: the thresholds that are used to build an index. The value of build_params is a JSON string that contains the following parameters:
min_flush_proxima_row_count: the minimum number of rows required in the vector field for which you want to build an index when you write data to a disk. We recommend that you set this parameter to 1000.
min_compaction_proxima_row_count: the minimum number of rows required in the vector field for which you want to build an index when you merge data in a disk. We recommend that you set this parameter to 1000.
max_total_size_to_merge_mb: the maximum size of files whose data you want to merge in a disk. Unit: MB. We recommend that you set this parameter to 2000.
proxima_builder_thread_count: the number of threads that are used to build the vector index during data writes. The default value is 4. In most cases, you do not need to change the value.
NoteThe index provides the optimal performance in specific scenarios.
Use the SquaredEuclidean function to build an index for the vector field.
call set_table_property( 'feature_tb', 'proxima_vectors', '{"feature":{"algorithm":"Graph", "distance_method":"SquaredEuclidean", "builder_params":{"min_flush_proxima_row_count" : 1000, "min_compaction_proxima_row_count" : 1000, "max_total_size_to_merge_mb" : 2000}}}');Import data to the vector table.
You can import data to the vector table in offline or real-time mode based on your business requirements. After you import multiple data entries at a time, you need to execute the VACUUM or ANALYZE statement to improve the query efficiency.
The VACUUM statement compacts multiple backend files into a large file. This improves the efficiency of vector queries. However, the VACUUM statement consumes CPU resources. The larger the amount of data is in the vector table, the more amount of time is required to execute the VACUUM statement. After you execute the VACUUM statement, wait for the execution result of the statement.
VACUUM <tablename>;The ANALYZE statement collects statistics to help Query Optimizer (QO) generate an optimal execution plan. This improves the performance of vector queries.
analyze <tablename>;
Query vector data.
Hologres supports vector queries based on exact match and approximate match. UDFs that start with
pm_are used to perform exact match queries. UDFs that start withpm_approx_are used to perform approximate match queries. For scenarios in which indexes are built for vector fields, we recommend that you use UDFs that start with pm_approx_ to perform approximate match queries. This way, indexes can be hit, and the query performance is high. We recommend that you use vector indexes for queries on a single table. In this case, indexes can be hit. Vector indexes are not recommended for join queries.Approximate match queries (using vector indexes)
In approximate match queries, vector indexes can be hit. Approximate match queries are suitable for scenarios in which a large amount of data needs to be scanned and a high execution efficiency is required. By default, the recall rate is higher than 99%. You can add
approx_before a distance calculation function to use a vector index. Sample functions:NoteIf you use the SquaredEuclidean or Euclidean function to perform approximate match queries, vector indexes can be hit only in scenarios in which
order by distance ascis specified. The descending order is not supported.If you use the InnerProduct function to perform approximate match queries, vector indexes can be hit only in scenarios in which
order by distance descis specified. The ascending order is not supported.
FLOAT4 pm_approx_squared_euclidean_distance(FLOAT4[], FLOAT4[]) FLOAT4 pm_approx_euclidean_distance(FLOAT4[], FLOAT4[]) FLOAT4 pm_approx_inner_product_distance(FLOAT4[], FLOAT4[])The distance calculation function that you use must be consistent with the value of the
distance_methodparameter underproxima_vectorthat is specified when you create the vector table. Execute the following SQL statements to calculate the top K items. You must set the second parameter in the SQL statement of the approximate match query to a constant.NoteIndex-based queries do not ensure 100% precision. The default recall rate is higher than 99%.
-- Calculate the top K items based on the squared Euclidean distance. In this case, you must set the distance_method parameter under proxima_vector to SquaredEuclidean in the table creation statement. SELECT pm_approx_squared_euclidean_distance(feature, '{0.1,0.2,0.3,0.4}') AS distance FROM feature_tb ORDER BY distance ASC limit 10 ; -- Calculate the top K items based on the Euclidean distance. In this case, you must set the distance_method parameter under proxima_vector to Euclidean in the table creation statement. SELECT pm_approx_euclidean_distance(feature, '{0.1,0.2,0.3,0.4}') AS distance FROM feature_tb ORDER BY distance ASC limit 10 ; -- Calculate the top K items based on the inner product distance. In this case, you must set the distance_method parameter under proxima_vector to InnerProduct in the table creation statement. SELECT pm_approx_inner_product_distance(feature, '{0.1,0.2,0.3,0.4}') AS distance FROM feature_tb ORDER BY distance DESC limit 10 ;Exact match queries (without using vector indexes)
Exact match queries are suitable for scenarios in which a small amount of data needs to be scanned by SQL statements and a high recall rate is required. The distance calculation functions Euclidean, SquaredEuclidean, and InnerProduct are used for exact match queries:
FLOAT4 pm_squared_euclidean_distance(FLOAT4[], FLOAT4[]) FLOAT4 pm_euclidean_distance(FLOAT4[], FLOAT4[]) FLOAT4 pm_inner_product_distance(FLOAT4[], FLOAT4[])Execute the following SQL statements to query the top K nearest neighbors of a vector.
NoteIn these examples, exact match queries are used. In the execution process, all vector data in the feature column is scanned to calculate and sort the distances. The first 10 results are returned. This type of SQL statement is suitable for scenarios in which a small amount of data is available and a high recall rate is required.
-- Recall the top 10 nearest neighbors based on the squared Euclidean distance. SELECT pm_squared_euclidean_distance(feature, '{0.1,0.2,0.3,0.4}') AS distance FROM feature_tb ORDER BY distance ASC limit 10 ; -- Recall the top 10 nearest neighbors based on the Euclidean distance. SELECT pm_euclidean_distance(feature, '{0.1,0.2,0.3,0.4}') AS distance FROM feature_tb ORDER BY distance ASC limit 10 ; -- Recall the top 10 neighbors with the greatest inner-products. SELECT pm_inner_product_distance(feature, '{0.1,0.2,0.3,0.4}') AS distance FROM feature_tb ORDER BY distance DESC limit 10 ;
Example
In this example, a Proxima index is used to recall top 40 data entries that have the shortest squared Euclidean distance from a four-dimensional vector table that has 0.1 million data entries.
Create a vector table.
CREATE EXTENSION proxima; BEGIN; -- Create a table group whose shard count is 4. CALL HG_CREATE_TABLE_GROUP ('test_tg_shard_4', 4); CREATE TABLE feature_tb ( id BIGINT, feature FLOAT4[] CHECK (array_ndims(feature) = 1 AND array_length(feature, 1) = 4) ); CALL set_table_property ('feature_tb', 'table_group', 'test_tg_shard_4'); CALL set_table_property ('feature_tb', 'proxima_vectors', '{"feature":{"algorithm":"Graph","distance_method":"SquaredEuclidean","builder_params": {"min_flush_proxima_row_count" : 1000, "min_compaction_proxima_row_count" : 1000, "max_total_size_to_merge_mb" : 2000}}}'); COMMIT;Import data into the vector table.
-- Optional. We recommend that you use the Serverless Computing feature to import a large amount of data offline and run ETL jobs. SET hg_computing_resource = 'serverless'; INSERT INTO feature_tb SELECT i, ARRAY[random(), random(), random(), random()]::FLOAT4[] FROM generate_series(1, 100000) i; ANALYZE feature_tb; VACUUM feature_tb; -- Reset the configurations. This ensures that serverless computing resources are not used for subsequent SQL statements. RESET hg_computing_resource;Query data from the vector table.
-- Optional. We recommend that you use the Serverless Computing feature to run a vector-based query job in which a large amount of data is queried. SET hg_computing_resource = 'serverless'; SELECT pm_approx_squared_euclidean_distance (feature, '{0.1,0.2,0.3,0.4}') AS distance FROM feature_tb ORDER BY distance LIMIT 40; -- Reset the configurations. This ensures that serverless computing resources are not used for subsequent SQL statements. RESET hg_computing_resource;
Optimize performance
Create indexes for vector fields
If a vector table has a small amount of data, such as tens of thousands of data entries, we recommend that you calculate data without creating indexes. If your instance has sufficient resources and the amount of data that you want to query is small, you can also directly calculate data. If direct calculation cannot meet your requirements, such as requirements on latency and throughput, you can use a Proxima index. Take note of the following items:
Proxima indexes are lossy indexes and do not ensure the accuracy of calculation results. This means that the distance that you calculate may be inaccurate.
If you use a Proxima index, the number of returned data entries may be smaller than the expected number. For example, you use a Proxima index and specify
limit 1000in the SQL statement, but only 500 data entries are returned.Proxima indexes are not easy to use.
Specify an appropriate shard count
The larger the shard count is, the more files are generated when Proxima indexes are built, and the lower the query throughput is. Therefore, we recommend that you specify an appropriate shard count based on the resources of your instance. In most cases, you can set the shard count to the number of worker nodes. For example, you can set the shard count to 4 for an instance with 64 cores. If you want to reduce the latency of a single query, you can decrease the shard count. However, this operation degrades the write performance.
-- Create a vector table in a table group whose shard count is 4. BEGIN; CALL HG_CREATE_TABLE_GROUP ('test_tg_shard_4', 4); CREATE TABLE proxima_test ( id BIGINT NOT NULL, vectors FLOAT4[] CHECK (array_ndims(vectors) = 1 AND array_length(vectors, 1) = 128), PRIMARY KEY (id) ); CALL set_table_property ('proxima_test', 'proxima_vectors', '{"vectors":{"algorithm":"Graph","distance_method":"SquaredEuclidean","builder_params":{}, "searcher_init_params":{}}}'); CALL set_table_property ('proxima_test', 'table_group', 'test_tg_shard_4'); COMMIT;(Recommended) Perform queries without using filter conditions
If you use a
wherefilter condition, the performance of indexes is negatively affected. We recommend that you perform queries without using filter conditions. For queries without using filter conditions, the ideal case is that each shard has only one index file. In this case, each query can be performed on a specific shard.The following syntax of table creation is usually used to perform queries without using filter conditions:
BEGIN; CREATE TABLE feature_tb ( uuid text, feature FLOAT4[] NOT NULL CHECK (array_ndims(feature) = 1 AND array_length(feature, 1) = N) -- Define a vector. ); CALL set_table_property ('feature_tb', 'shard_count', '?'); -- Specify the shard count based on your business requirements. You can also retain the default shard count. CALL set_table_property ('feature_tb', 'proxima_vectors', '{"feature":{"algorithm":"Graph","distance_method":"InnerProduct"}'); -- Create an index for the vector field. END;Perform queries by using filter conditions
If you perform this type of queries, you can configure filter conditions by using one of the following methods:
Method 1: Configure a string as a filter condition
You can configure a string as a filter condition if you want to query vector data of an organization, such as querying the face data of a class. Sample statement:
SELECT pm_xx_distance(feature, '{1,2,3,4}') AS d FROM feature_tb WHERE uuid = 'x' ORDER BY d limit 10;We recommend that you optimize the statement by performing the following operations:
Configure the universally unique identifier (UUID) as the distribution key of the vector table. This way, the returned duplicate data is stored in the same shard, and each query is performed on only one shard.
Configure the UUID as the clustering key of the vector table. This way, the returned data is sorted in the file based on the clustering key.
Method 2: Configure a time field as a filter condition
You can configure a time field as a filter condition if you want to filter vector data based on the time field. We recommend that you configure the time field time_field as the segment key of the vector table to quickly locate the file in which a specific data entry resides. Sample statement:
SELECT pm_xx_distance(feature, '{1,2,3,4}') AS d FROM feature_tb WHERE time_field BETWEEN '2020-08-30 00:00:00' AND '2020-08-30 12:00:00' ORDER BY d limit 10;
The following syntax of table creation is usually used to perform queries based on filter conditions:
BEGIN; CREATE TABLE feature_tb ( time_field timestamptz NOT NULL, uuid text, feature FLOAT4[] NOT NULL CHECK (array_ndims(feature) = 1 AND array_length(feature, 1) = N) ); CALL set_table_property ('feature_tb', 'distribution_key', 'uuid'); CALL set_table_property ('feature_tb', 'segment_key', 'time_field'); CALL set_table_property ('feature_tb', 'clustering_key', 'uuid'); CALL set_table_property ('feature_tb', 'proxima_vectors', '{"feature":{"algorithm":"Graph","distance_method":"InnerProduct"}}'); COMMIT; -- If you do not filter data by time, you can delete indexes related to time_field.
FAQ
What do I do if the following error message is returned:
ERROR: function pm_approx_inner_product_distance(real[], unknown) does not exist?Cause: The
create extension proxima;statement is not executed in the database to initialize the Proxima plug-in.Solution: Execute the
create extension proxima;statement to initialize the Proxima plug-in.What do I do if the following error message is returned:
Writing column: feature with array size: 5 violates fixed size list (4) constraint declared in schema?Cause: The dimension of data that is written to the characteristic vector field is different from the dimension that is defined for the vector field in the table.
Solution: Check whether dirty data exists.
What do I do if the following error message is returned:
The size of two arrays must be the same in DistanceFunction, size of left array: 4, size of right array:?Cause: In the
pm_xx_distance(left, right)function, the dimension of the left variable is different from that of the right variable.Solution: Change the dimension of the left variable to be the same as that of the right variable in the
pm_xx_distance(left, right)function.What do I do if the following error message is returned during real-time data writes:
BackPresure Exceed Reject Limit ctxId: XXXXXXXX, tableId: YY, shardId: ZZ?Cause: The real-time write job encounters a bottleneck, and a backpressure error occurs. The overheads incurred by the job are high, and the write operation is time-consuming. In most cases, this issue occurs because min_flush_proxima_row_count is set to a small value but the real-time input rate is high. As a result, the overheads incurred by the job for building indexes increase, and the job becomes stuck.
Solution: Set min_flush_proxima_row_count to a larger value.
How do I write data to a vector field in Java?
The following code block provides an example on how to write data to a vector field in Java:
private static void insertIntoVector(Connection conn) throws Exception { try (PreparedStatement stmt = conn.prepareStatement("insert into feature_tb values(?,?);")) { for (int i = 0; i < 100; ++i) { stmt.setInt(1, i); Float[] featureVector = {0.1f,0.2f,0.3f,0.4f}; Array array = conn.createArrayOf("FLOAT4", featureVector); stmt.setArray(2, array); stmt.execute(); } } }How do I check whether the Proxima index is used based on the execution plan?
If
Proxima filter: xxxxexists in the execution plan, the index is used, as shown in the following figure. Otherwise, the index is not used. In most cases, this is because the table creation statement does not match the query statement.
Distance calculation functions
Hologres supports the following functions that are used to calculate the vector distance:
The SquaredEuclidean function uses the following calculation formula.
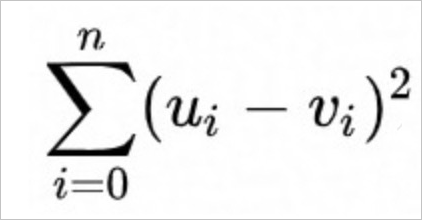
The Euclidean function uses the following calculation formula.
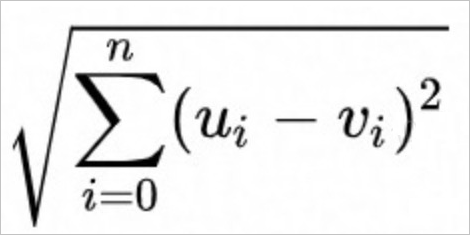
The InnerProduct function uses the following calculation formula.
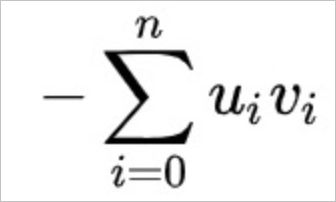
For example, you use the Euclidean or SquaredEuclidean function to perform vector processing. In comparison with the Euclidean function, the SquaredEuclidean function does not need to extract the square root to obtain the same top K items as the Euclidean function. Therefore, the SquaredEuclidean function provides higher performance. If the feature requirements are met, we recommend that you use the SquaredEuclidean function.