Serverless Application Center allows you to configure custom pipelines. You can efficiently publish code to Function Compute by configuring pipelines and orchestrating task flows. This topic describes how to manage pipelines in the Function Compute console, including how to configure pipelines, how to configure pipeline details, and how to view pipeline execution records.
Background information
When you create an application, Serverless Application Center creates a default environment for the application. You can specify a method to trigger Git events of the pipeline in the environment and configure pipeline settings. When you configure the pipeline, you can select Automatic Configuration or Custom Configuration. If you select Automatic Configuration, Serverless Application Center creates a pipeline based on default parameter settings. If you select Custom Configuration, you can specify a method to trigger the Git events of the pipeline in the environment. You can also select the execution environment for the pipeline. Information such as Git information and application information is passed on to the pipeline as the execution context.
When you modify pipeline configurations, you can modify the trigger method and execution environment. You can also configure DingTalk notifications and YAML files.
Configure a pipeline when you create an application or an environment
When you create an application or an environment, you can specify the Git trigger method and execution environment of the pipeline.
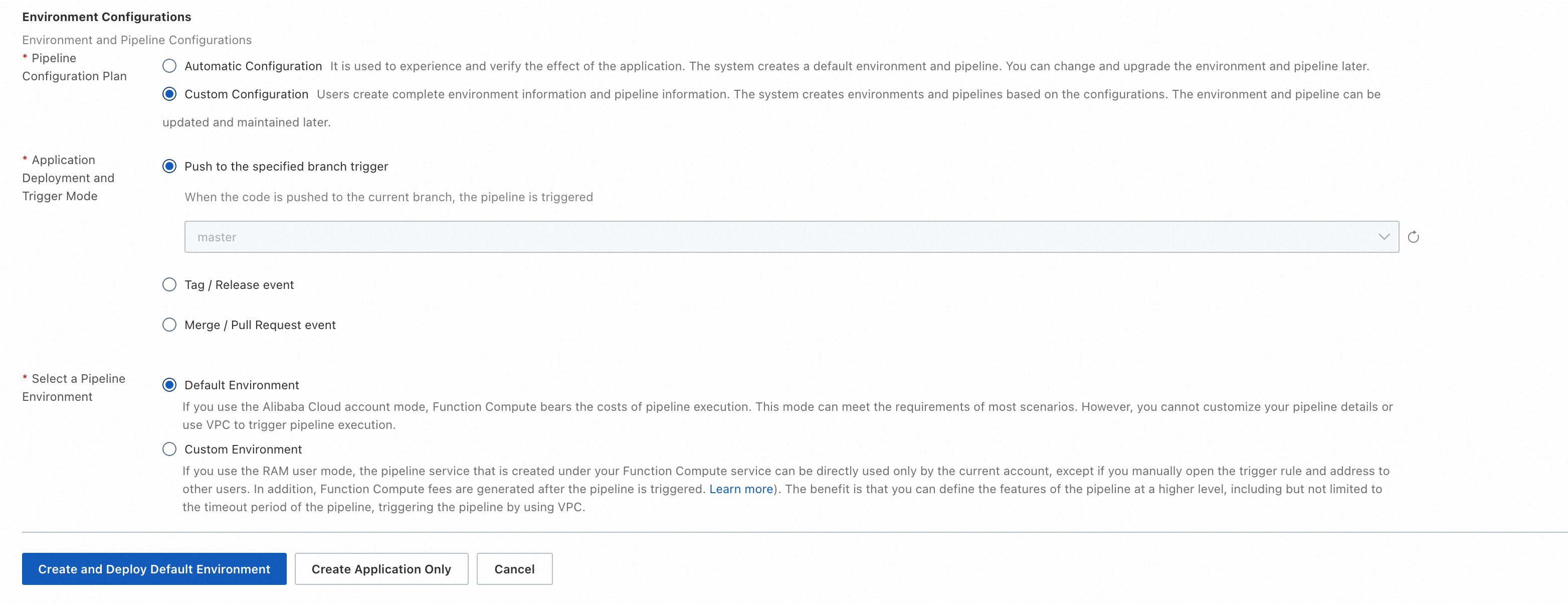
Modify the pipeline of an existing environment
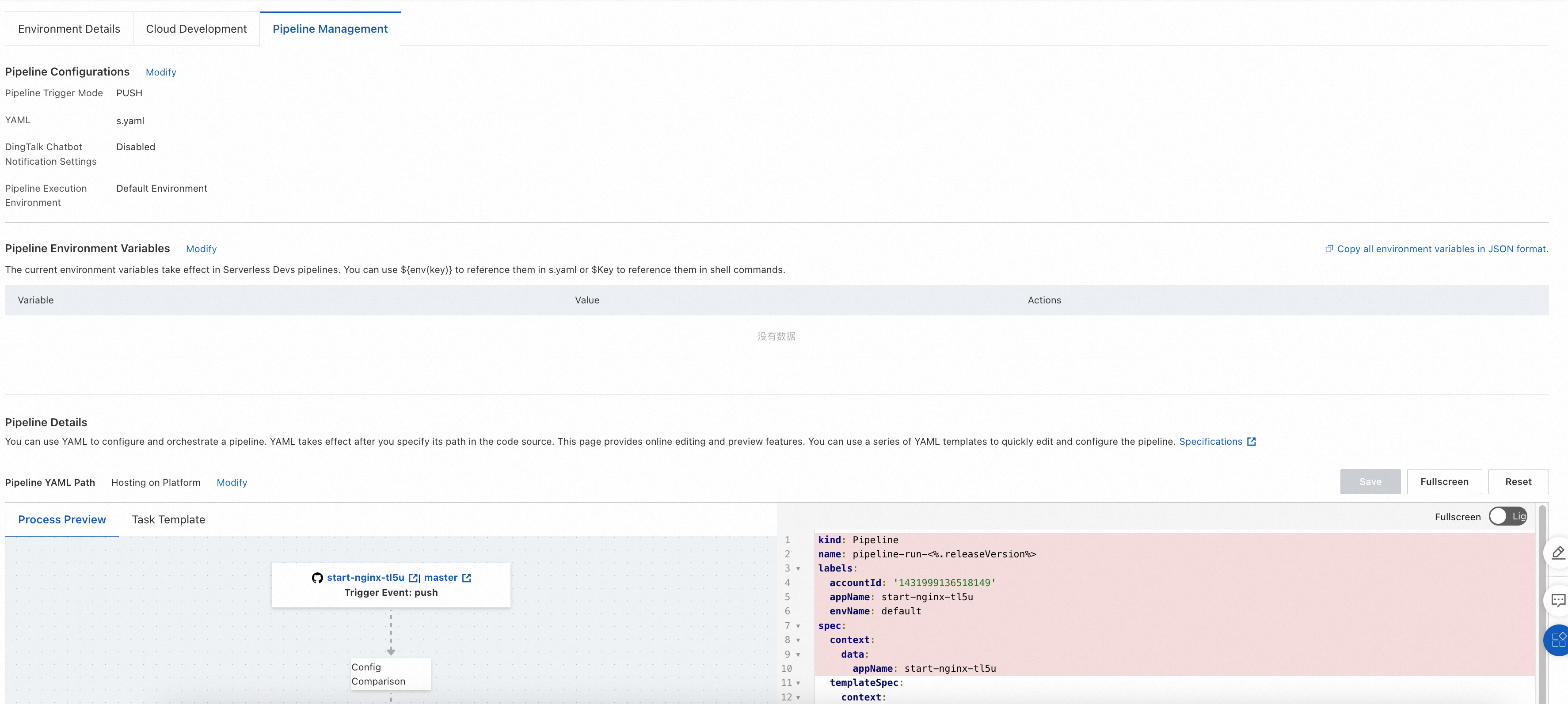
You can edit the Git event trigger method, execution environment, DingTalk notifications, and YAML files for a pipeline of an existing environment on the Pipeline Management tab.
Configure a pipeline
To configure a pipeline, you must configure the following parameters: Pipeline Trigger Mode, YAML, DingTalk Chatbot Notification Settings, and Pipeline Execution Environment. When you create an application and an environment, you can configure only the Pipeline Trigger Mode and Pipeline Execution Environment parameters. After you create an application and an environment, you can click Modify to the right of Pipeline Configurations on the Pipeline Management tab to modify the preceding four parameters.
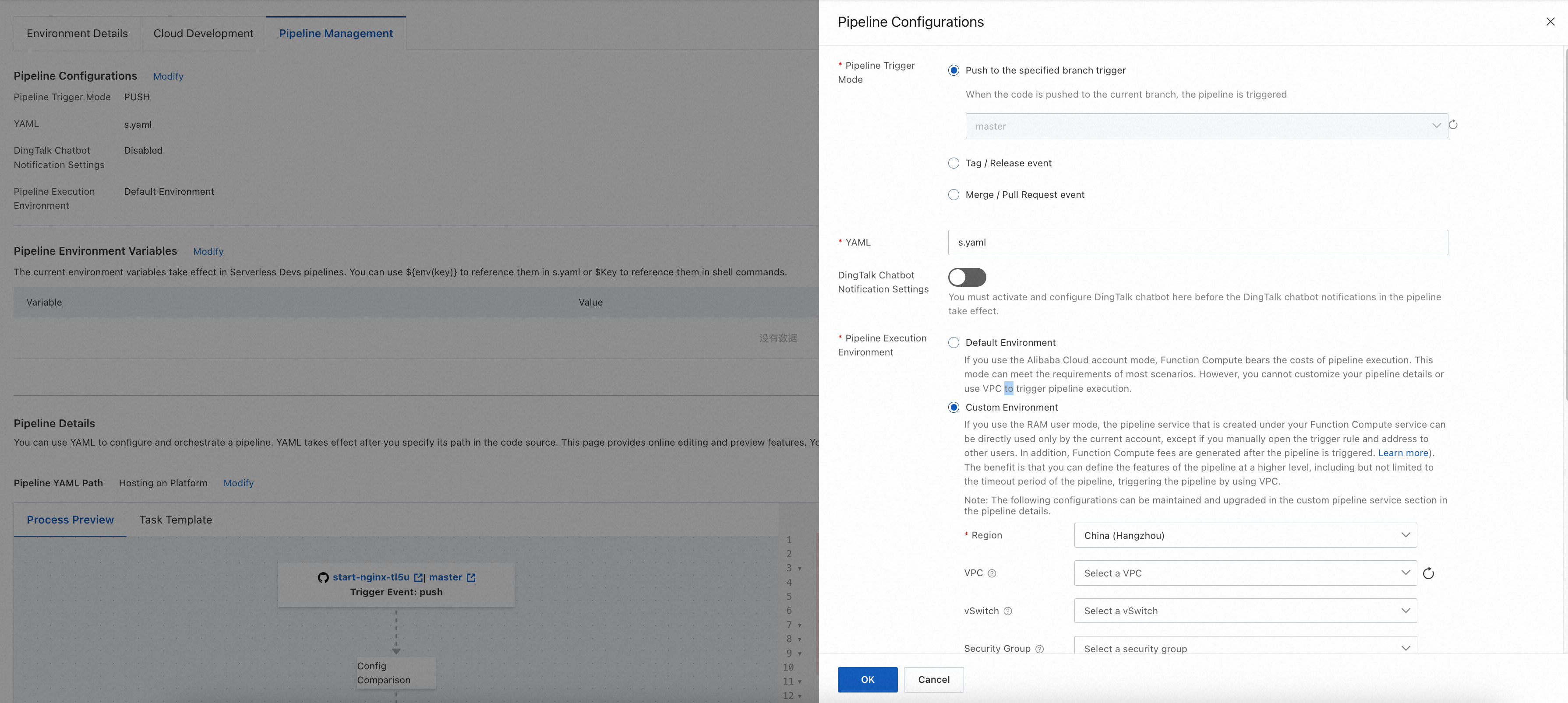
Pipeline Trigger Mode
Serverless Application Center allows you to specify a method to trigger Git events of a pipeline. Serverless Application Center uses webhooks to receive Git events. When an event that meets specified trigger conditions is received, Serverless Application Center creates and executes the pipeline based on the YAML file that you specify. The following trigger modes are supported:
Triggered by branch: The environment must be associated with a specific branch and all push events in the branch are matched.
Triggered by tag: All tag creation events of a specific tag expression are matched.
Triggered by branch merging: Merge and pull request events from the source branch to the destination branch with which the environment is associated are matched.
Pipeline Execution Environment
You can set this parameter to Default Environment or Custom Environment.
Default Environment
If you set the Pipeline Execution Environment parameter to Default Environment, Serverless Application Center fully manages pipeline resources and Function Compute bears fees generated during pipeline executions and you do not have to pay any fees. Each task of the pipeline runs on an independent and sandboxed VM. Serverless Application Center ensures the isolation of the pipeline execution environment. The following items describe the limits of the default environment:
Instance specification: 4 vCPUs and 8 GB of memory.
Temporary disk space: 10 GB.
Task execution timeout period: 15 minutes.
Region: If you create an environment by using a template or source code from GitHub, specify the Singapore region. If you create an environment by using Gitee, GitLab, or Codeup, specify the China (Hangzhou) region.
Network: You cannot use fixed IP addresses or CIDR blocks. You cannot configure an IP address whitelist to access specific websites. You cannot access resources in a virtual private cloud (VPC).
Custom Environment
If you set the Pipeline Execution Environment parameter to Custom Environment, the pipeline is executed in your Alibaba Cloud account. Compared with the default environment, a custom environment provides more custom capabilities. Serverless Application Center fully manages tasks in the custom environment and schedules Function Compute instances in real time to run the pipeline based on your authorization. Similar to the default environment, a custom environment provides the serverless feature, which eliminates the need to maintain infrastructure.
Custom environments provide the following custom capabilities:
Region and network: You can specify the region and the VPC for the execution environment to access internal code repositories, artifact repositories, image repositories, and Maven internal repositories. For more information about supported regions, see Supported regions.
Instance specification: You can specify CPU and memory specifications for the execution environment. For example, you can specify instances with larger specifications to speed up the build process.
NoteThe vCPU-to-memory ratio must range from 1:1 to 1:4. Memory capacity is measured in GB.
Persistence storage: You can configure File Storage NAS (NAS) or Object Storage Service (OSS) mounting. For example, you can use NAS to cache files to speed up the build process.
Logging: You can specify a Simple Log Service (SLS) project and Logstore to persist the execution logs of a pipeline.
Timeout period: You can specify custom timeout periods for pipeline tasks. Default value: 600. Maximum value: 86400. Unit: seconds.
A custom execution environment allows pipeline tasks to be executed in Function Compute within your Alibaba Cloud account. In this case, you are charged for task execution. For more information, see Billing overview.
YAML
Serverless Application Center is integrated with Serverless Devs. You can use YAML files of Serverless Devs to define resource configurations of your applications. The default YAML file is named s.yaml. You can also specify another YAML file. After you specify the YAML file, you can use it in the pipeline by using the following methods:
If you use the
@serverless-cd/s-deployplug-in for execution, the plug-in automatically uses the specified YAML file. The-t/--templatecommand is added to the operation instructions of Serverless Devs. In the following example, the specified YAML file isdemo.yaml, and the command executed by the plug-in iss deploy -t demo.yaml.
- name: deploy
context:
data:
deployFile: demo.yaml
steps:
- plugin: '@serverless-cd/s-setup'
- plugin: '@serverless-cd/checkout'
- plugin: '@serverless-cd/s-deploy'
taskTemplate: serverless-runner-taskIf you use scripts for execution, you can use
${{ ctx.data.deployFile }}to reference the specified YAML file. In the following example, the s plan command is run by using the specified file if you specify a YAML file. Otherwise, the s plan command is run by using the default s.yaml file.
- name: pre-check
context:
data:
steps:
- run: s plan -t ${{ ctx.data.deployFile || s.yaml }}
- run: echo "s plan finished."
taskTemplate: serverless-runner-taskDingTalk Chatbot Notification Settings
After you enable this feature, you must configure the Webhook address, Signing key, and custom message parameters and specify notification rules. You can manage the tasks that require notifications in a centralized manner. You can also use the YAML file of the pipeline to enable notifications for each task. After you configure notifications, you can configure notifications for each task in the Pipeline Details section.
Configure pipeline environment variables
In the Pipeline Environment Variables section, click Modify. In the panel that appears, select a configuration method, configure environment variables, and then click OK.
Edit using the form (default)
Click add variable.
Configure key-value pairs of environment variables.
variable: Enter a custom variable.
value: Enter a variable value.
Edit in JSON format
Click Edit in JSON format.
In the code editor, enter a key-value pair in the following JSON format:
{ "key": "value" }Example:
{ "REGION": "MY_REGION", "LOG_PROJECT": "MY_LOG_PROJECT" }
The specified environment variables take effect in Serverless Devs pipelines. You can use ${env(key)} to reference them in s.yaml or $Key to reference them in shell commands.
vars:
region: ${env(REGION)}
service:
name: demo-service-${env(prefix)}
internetAccess: true
logConfig:
project: ${env(LOG_PROJECT)}
logstore: fc-console-function-pre
vpcConfig:
securityGroupId: ${env(SG_ID)}
vswitchIds:
- ${env(VSWITCH_ID)}
vpcId: ${env(VPC_ID)}Configure pipeline details
In the Pipeline Details section, you can configure the pipeline process, tasks in the pipeline, and relationships between the tasks. The platform automatically generates a default pipeline process based on which you can modify configurations.
You can manage pipelines by using YAML files. When you configure pipeline details, you can select Hosting on Platform or Read from Repository as Pipeline YAML Path.
If you select Hosting on Platform, predefined variables in the YAML file are not supported. For more information, see Use a .yaml file to describe a pipeline.
If you select Read from Repository, predefined variables in the YAML file are supported.
Hosting on Platform
By default, the YAML files of pipelines are configured in and managed by Serverless Application Center in a centralized manner. After you update the YAML file of a pipeline, the new configurations take effect in the next deployment.
Read from Repository
The YAML files of pipelines are stored in Git repositories. After you modify and save the configurations of a pipeline in the Function Compute console, Serverless Application Center commits the modifications to the Git repository in real time. This does not trigger the execution of the pipeline. When an event in your code repository triggers the execution of the pipeline, Serverless Application Center creates and executes the pipeline by using the specified YAML file in the Git repository.
To read a YAML file from a Git repository, click Modify in the Pipeline Details section. In the dialog box that appears, select Read from Repository and enter the path of the YAML file, as shown in the following figure.

The Pipeline Details section consists of a tool area on the left and a YAML editing area on the right.
YAML editing area: You can edit the YAML file of a pipeline to modify the pipeline process. For more information, see the "Use a .yaml file to describe a pipeline" topic.
The tool area provides auxiliary tools for editing YAML files. The following tabs are included:
Process Preview: allows you to preview and modify the pipeline process.
Task Template: provides common YAML templates.
In the upper-right corner of the Pipeline Details section, the Save, Fullscreen, and Reset buttons are displayed.
You can click Save to save all modifications in the YAML file. Then, all saved data is synchronized to the YAML file of the pipeline.
You can click Fullscreen to maximize the editing area.
You can click Reset to restore the YAML file to the last saved version.
If you click Reset, the modifications that are made since you last saved the YAML file are reverted. Proceed with caution and make sure that your data is backed up.
Process Preview
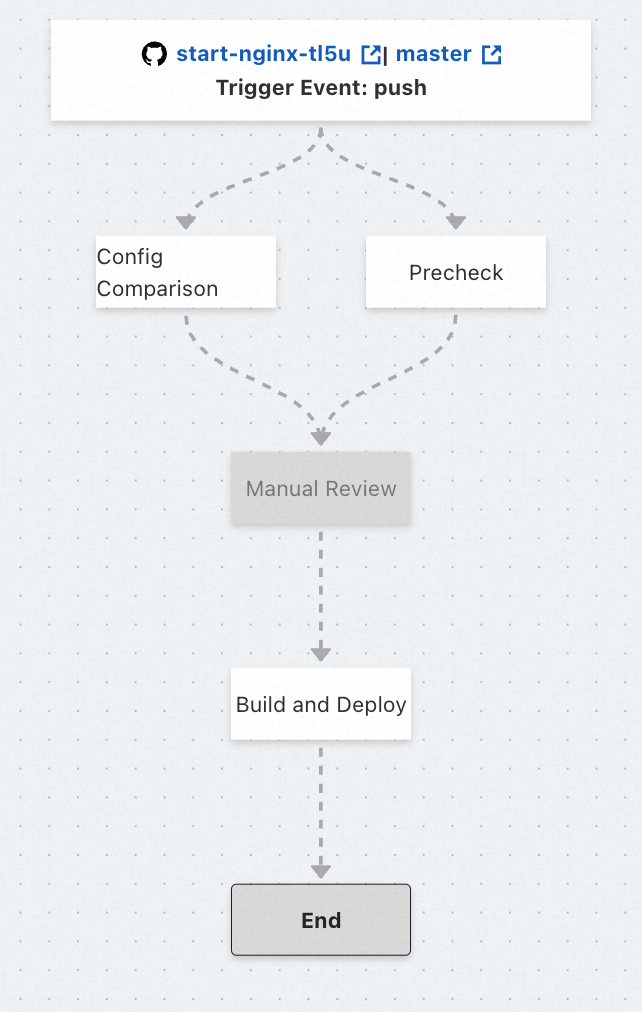
On the Process Preview tab, you can preview the pipeline process and edit the basic content of tasks and the relationships between tasks. You can also add template tasks. A pipeline process consists of the following types of nodes: start node (code source and trigger method), task node, and end node. The nodes are connected by dotted arrows, which indicate the dependencies among the nodes. When you move the pointer over a task node, the icons to add or delete the task node are displayed.
Start node (code source and trigger method)
This node contains the information about the code source and trigger method of a pipeline, and you cannot edit the information. If you want to modify the trigger method, go to the Pipeline Configurations section.
ImportantIf you want to change the code repository, go to the application details page. For more information, see Manage applications. After you change the code repository, all pipelines that use the code from the repository become invalid. Proceed with caution.
End node
The last node in the pipeline process. You cannot edit it.
Task node
A task node contains the basic information about a task. By default, a task node shows the task name. When you click a task node, a pop-up window appears, in which you can view and modify parameters such as Task Name, Pre-task, and Start Task. If you clear Start Task for a task, the task is skipped when the pipeline is executed and the task node is dimmed in the pipeline process.
Dependency
The dependency relationship between nodes are indicated by one-way dotted arrows. If an arrow points from Task A to Task B, Task B runs following Task A and depends on Task A. A task can follow or be followed by multiple tasks.
You can modify the dependencies by modifying the Pre-task parameter. For example, if you want to remove the dependency of Task B on Task A, click the Task B node and remove Task A from the Pre-task field.
Add a task
If you want to add a task, click the plus icon. You can click the plus icons at the top, bottom, and right sides of a task node. For example, if you want to add Task B to run before Task A, click the plus icon at the top side of the Task A node to create Task B. This way, Task A runs after and depends on Task B. If you want to add Task C to run after Task A, click the plus icon at the bottom side of the Task A node to create Task C. This way, Task C runs after and depends on Task A. If you want to add Task D that is parallel to Task A and has the same dependency relationships as Task A, click the plus icon at the right side of the Task A node to create Task D. This way, Task D has the same pre-task and is followed by the same task as Task A.
Delete a task
If you want to delete a task, click the cross icon in the upper-right corner of a task node. After you click the cross icon, the system prompts you to confirm the deletion of the task to prevent accidental operations.

Task Template
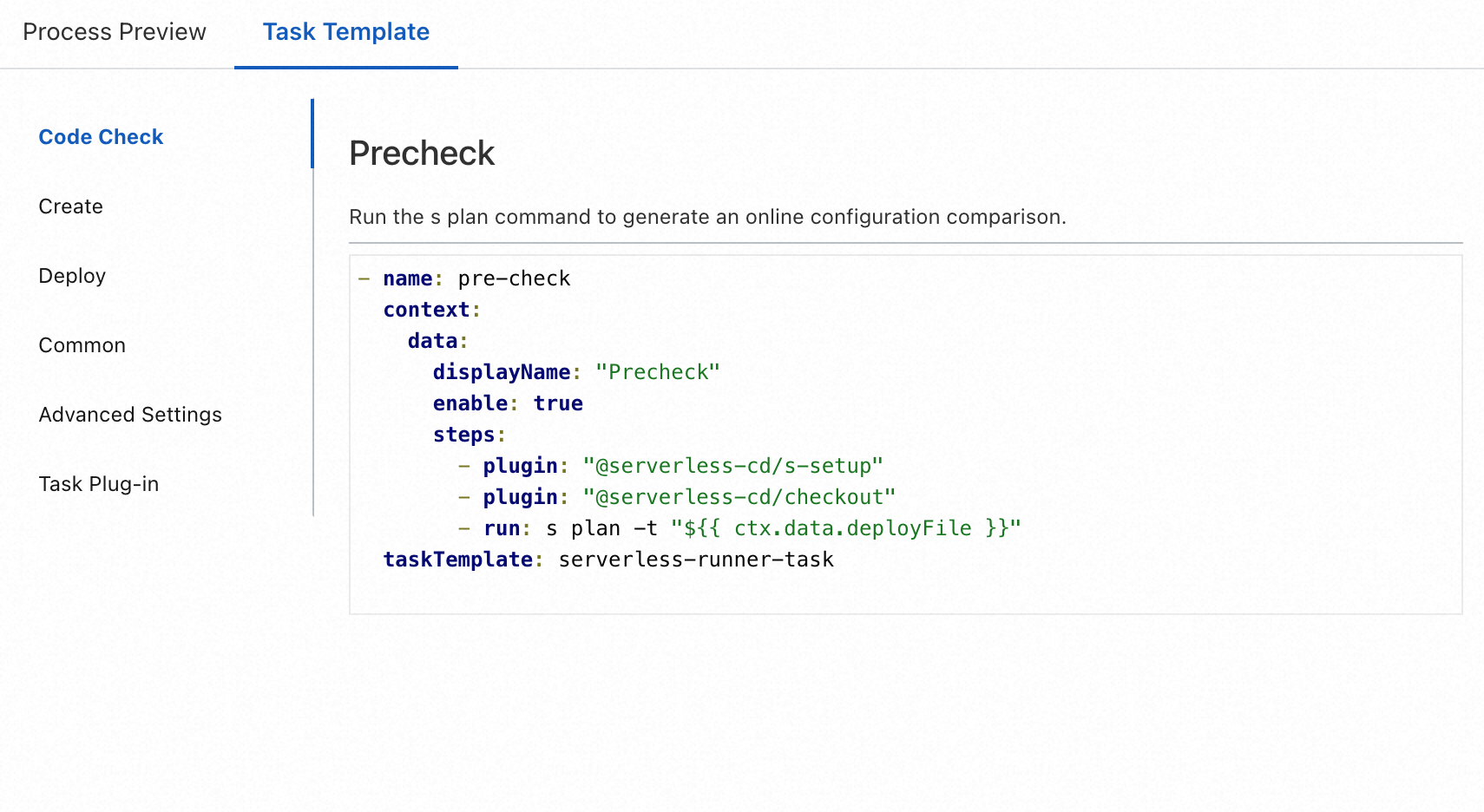
On the Task Template tab, the YAML templates of the following types of tasks are provided: Code Check, Create, Deploy, and Common. In addition, the YAML templates for task advanced settings and plug-ins are provided.
You can find the YAML template that you want to use on the Task Template tab, click it to view the template description and content, and copy the template content to an appropriate position in the YAML file of the pipeline.
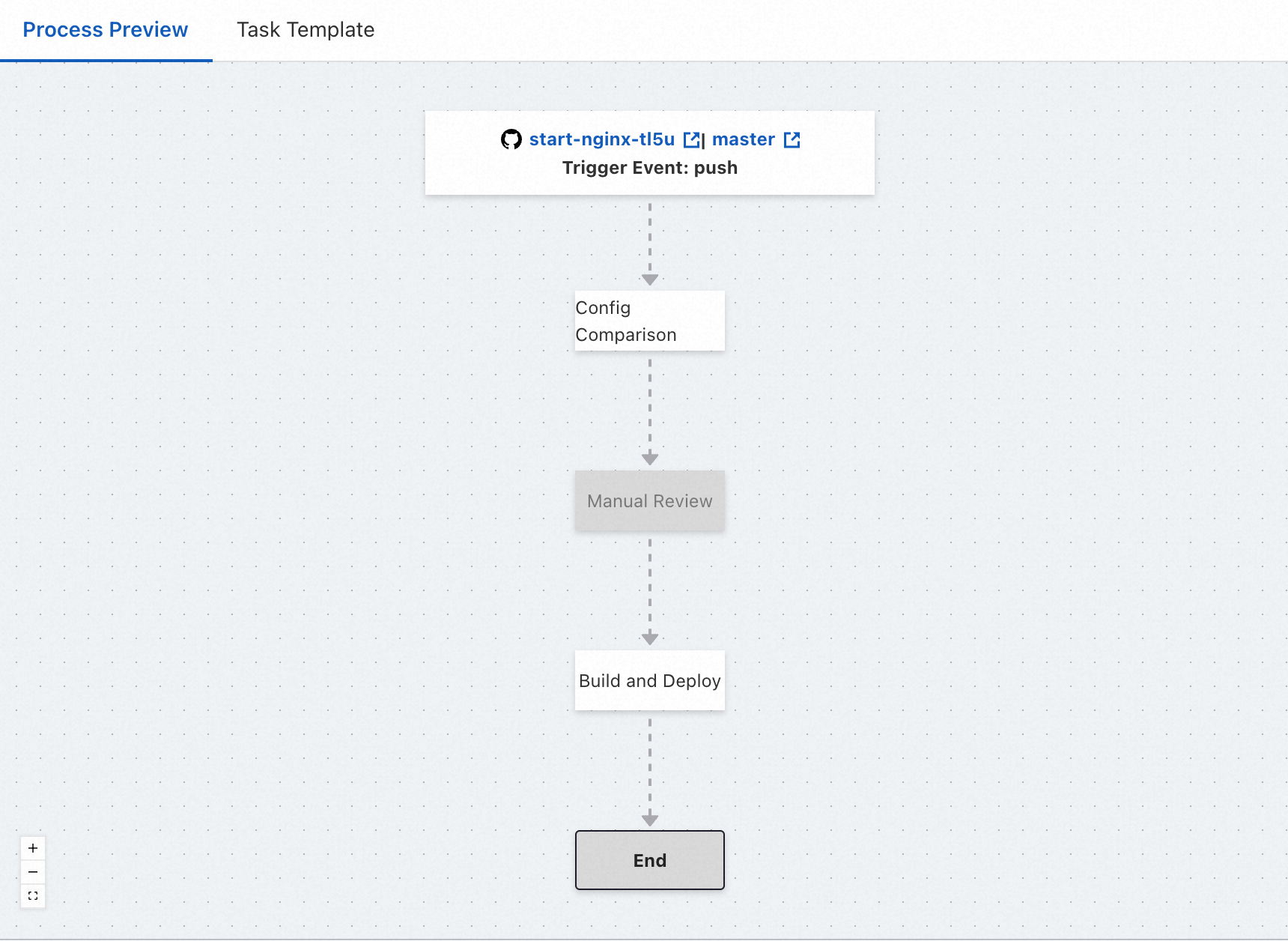
Default pipeline process
By default, a pipeline process consists of three tasks: Config Comparison, Manual Review, and Build and Deploy. The three tasks are executed in sequence. By default, the Manual Review task is disabled. You must manually enable it if you need this task.
Config Comparison
This task checks whether the YAML file of the pipeline is consistent with the online configurations. This helps you detect unexpected configuration changes in advance.
Manual Review
To ensure the secure release and stability of an application, you can enable the Manual Review task. After you enable this task, the pipeline is blocked at this node until the manual review is complete. Subsequent operations are performed only after the changes are manually approved. Otherwise, the pipeline is terminated. By default, this task is disabled. You must manually enable this task.
Build and Deploy
This task builds an application and deploys the application to the cloud. By default, full deployment is performed.
View historical executions of a pipeline
On the details page of an environment, click the Pipeline Management tab. In the Pipeline Execution History section, you can view the execution records of a specific pipeline.
You can click an execution version of a pipeline to view the execution details. On the details panel, you can view the execution logs and status of the pipeline and troubleshoot issues.
Update the runtime of a pipeline
The following table describes the default build environments of pipelines. Built-in package managers of the default pipelines include Maven, pip, and npm. Only the Debian 10 OS is supported as the runtime environment.
Runtime | Supported version |
Node.js |
|
Java |
|
Python |
|
Golang |
|
PHP |
|
.NET |
|
You can specify the runtime version of a pipeline by using the runtime-setup plug-in or modifying the variables in the YAML file.
runtime-setup plug-in (recommended)
To use this method, log on to the Function Compute console, find the application that you want to manage on the Applications page, and then click its name. In the Pipeline Details section of the Pipeline Management tab, update the YAML file of the pipeline on the right side by using the task template. To do so, perform the following steps: Click the Task Template tab, select Task Plug-in, click the Configure Runtime template, copy the template content to the YAML file on the right, and then click Save.
We recommend that you place the runtime-setup plug-in in the first step to ensure that it takes effect for all subsequent steps.
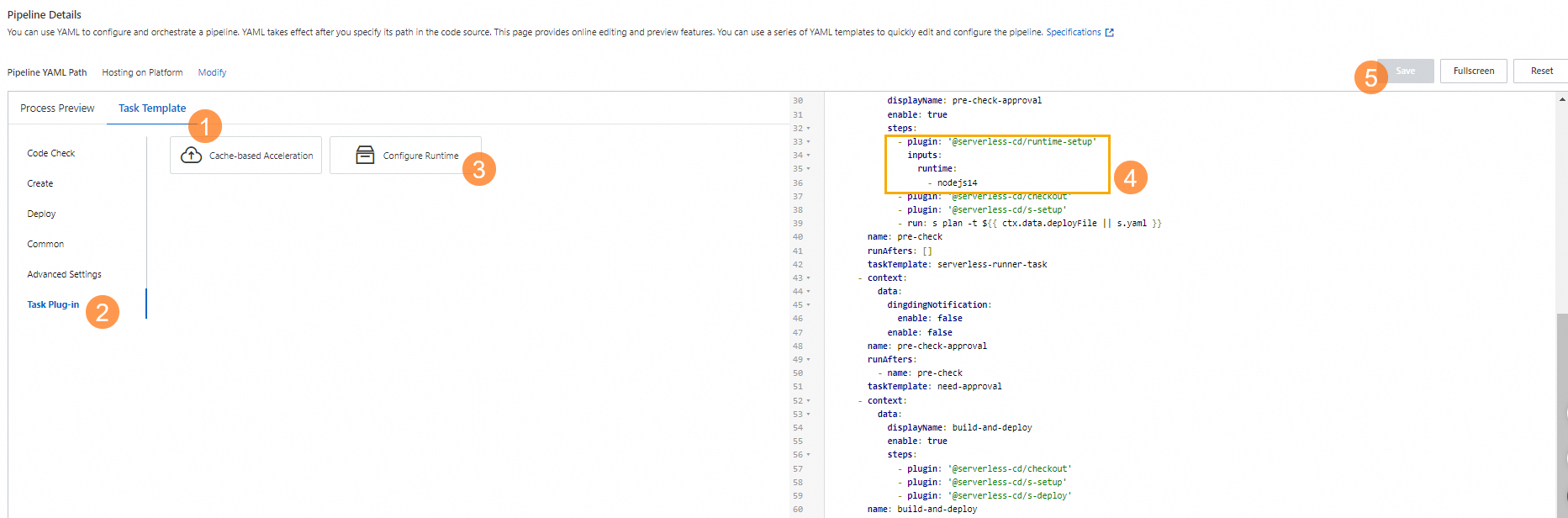
For information about the parameters of the runtime-setup plug-in, see Use the runtime-setup plug-in to initialize a runtime.
Variables in the YAML file
You can also use the action hook in the YAML file to change the version of Node.js or Python. The following items describe the details:
Node.js
export PATH=/usr/local/versions/node/v12.22.12/bin:$PATH
export PATH=/usr/local/versions/node/v16.15.0/bin:$PATH
export PATH=/usr/local/versions/node/v14.19.2/bin:$PATH
export PATH=/usr/local/versions/node/v18.14.2/bin:$PATH
The following sample code shows an example:
services: upgrade_runtime: component: 'fc' actions: pre-deploy: - run: export PATH=/usr/local/versions/node/v18.14.2/bin:$PATH && npm run build props: ...Python
export PATH=/usr/local/envs/py27/bin:$PATH
export PATH=/usr/local/envs/py36/bin:$PATH
export PATH=/usr/local/envs/py37/bin:$PATH
export PATH=/usr/local/envs/py39/bin:$PATH
export PATH=/usr/local/envs/py310/bin:$PATH
The following sample code shows an example:
services: upgrade_runtime: component: 'fc' actions: pre-deploy: - run: export PATH=/usr/local/envs/py310/bin:$PATH && pip3 install -r requirements.txt -t . props: ...