After you create a MaxCompute catalog, you can access tables that are stored in MaxCompute on the SQL Editor page in the Realtime Compute for Apache Flink console without the need to define schemas. This topic describes how to create, view, use, and delete a MaxCompute catalog in the Realtime Compute for Apache Flink console.
Background
MaxCompute catalogs query MaxCompute to obtain the schemas of physical tables that are stored in MaxCompute. After you create a MaxCompute catalog, you can obtain specific fields of a MaxCompute table without the need to declare the schema of the MaxCompute table in Flink SQL. MaxCompute catalogs have the following characteristics:
A database name in a MaxCompute catalog corresponds to the name of a MaxCompute project. You can switch databases to use tables of different MaxCompute projects.
A table name in a MaxCompute catalog corresponds to the name of a physical table that is stored in MaxCompute. Data type mappings between the fields of the table of the MaxCompute catalog and the physical table in MaxCompute are automatically created. You do not need to manually register MaxCompute tables by using DDL statements. This improves development efficiency and correctness.
Tables of a MaxCompute catalog can be directly used as source tables, dimension tables, and result tables in Flink SQL deployments.
After you create a table in a MaxCompute catalog, the related physical table is automatically created in MaxCompute and the data type mappings between the tables are automatically created. This improves development efficiency.
This topic describes the following operations that you can perform to manage MaxCompute catalogs:
Limitations
Only Ververica Runtime (VVR) 6.0.7 or later supports MaxCompute catalogs.
You cannot use MaxCompute catalogs to create databases. Databases of MaxCompute catalogs refer to MaxCompute projects.
You cannot use MaxCompute catalogs to modify table schemas.
MaxCompute catalogs do not support the CREATE TABLE AS (CTAS).
Create a MaxCompute catalog
You can configure a MaxCompute catalog on the UI or by executing an SQL statement. We recommend that you create a MaxCompute catalog on the UI.
UI (recommended)
Go to the Catalogs page.
Log on to the Realtime Compute for Apache Flink console. Find the workspace that you want to manage and click Console in the Actions column.
In the left navigation pane, click Catalogs.
On the Catalog List page, click Create Catalog. In the dialog box, select ODPS, and click Next.
Configure the catalog.
ImportantAfter you create a catalog, the parameter configuration cannot be modified. If you want to modify the parameter configuration, you must delete the catalog that you created and create a catalog again.
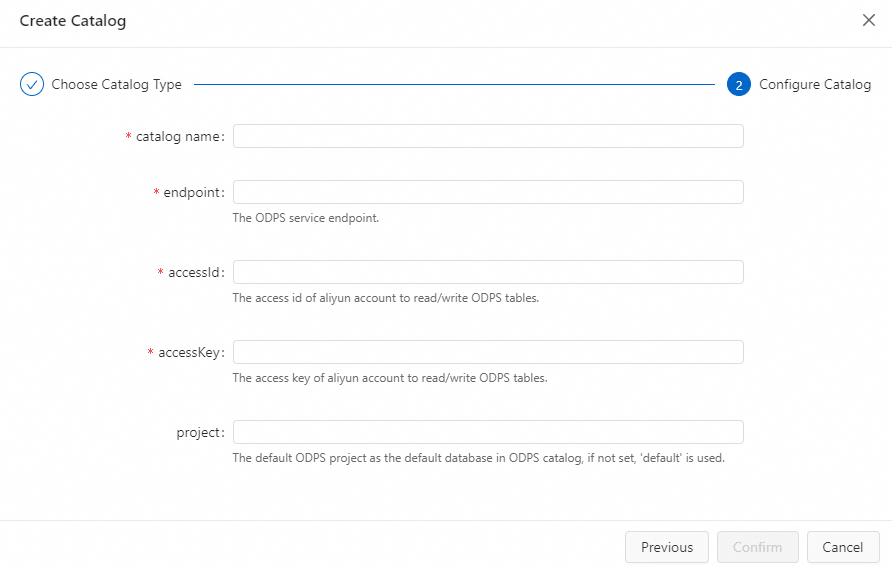
Parameter
Description
Data type
Required
Remarks
catalog name
The name of the MaxCompute catalog.
String
Yes
Enter a custom name.
endpoint
The endpoint of MaxCompute.
String
Yes
For more information, see Endpoints.
accessId
The AccessKey ID of the Alibaba Cloud account that is used to access MaxCompute.
String
Yes
The Alibaba Cloud account must have the admin permission on the projects that the catalog accesses.
accessKey
The AccessKey secret of the Alibaba Cloud account that is used to access MaxCompute.
String
Yes
N/A.
project
The name of the MaxCompute project that is used as the default database in the catalog.
String
No
If you do not configure this parameter, the name of the default project is used.
NoteAfter the catalog is created, the project that you enter and the projects that are created in your Alibaba Cloud account are displayed in the metadata of the catalog.
catalog.schema.enabled
Specifies whether to enable schema.
Boolean
No
A schema is a mechanism used to classify tables, resources, and UDFs within a project. A project can contain multiple schemas. For more information, see Schema operations.
Valid values:
false (default): Does not enable schema. A database in Flink catalog maps to a MaxCompute project. This suits MaxCompute projects with schema disabled.
true: Enables schema. A database in the Flink catalog maps to a MaxCompute schema. This suits MaxCompute projects with schema enabled.
Click Confirm.
You can view the catalog that you create in the Catalogs pane on the left side of the Catalog List page.
ImportantIf the AccessKey pair used to create the catalog lacks permissions for specific tables or databases within the MaxCompute project, an error will be reported. This does not impact your ability to read or write to listed tables and databases.
Flink SQL
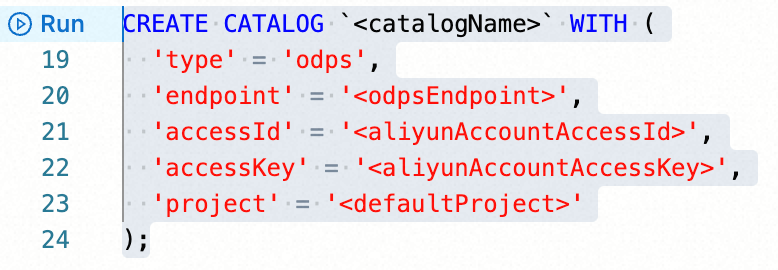
In the script editor, enter the following statement to create a MaxCompute catalog:
CREATE CATALOG `<catalogName>` WITH ( 'type' = 'odps', 'endpoint' = '<odpsEndpoint>', 'accessId' = '<aliyunAccountAccessId>', 'accessKey' = '<aliyunAccountAccessKey>', 'project' = '<defaultProject>', 'userAccount' = '<RAMUserAccount>' );The following table describes the parameters.
Parameter
Description
Data type
Required
Remarks
catalogName
The name of the MaxCompute catalog.
String
Yes
Enter a custom name.
type
The catalog type.
String
Yes
Set the value to odps.
endpoint
The endpoint of MaxCompute.
String
Yes
For more information, see Endpoints.
accessId
The AccessKey ID of the Alibaba Cloud account that is used to access MaxCompute.
String
Yes
The Alibaba Cloud account must have the admin permission on the projects that the catalog accesses.
accessKey
The AccessKey secret of the Alibaba Cloud account that is used to access MaxCompute.
String
Yes
N/A.
project
The name of the MaxCompute project that is used as the default database in the catalog.
String
No
If you do not configure this parameter, the name of the default project is used.
userAccount
The name of the Alibaba Cloud account or the name of the RAM user.
String
No
If the AccessKey secret belongs to a RAM user and the RAM user has the admin permission only on specific projects within the Alibaba Cloud account, you need to set this parameter to the account name. For example, you can set this parameter to
RAM$[<account_name>:]<RAM_name>. This way, the MaxCompute catalog displays only the list of projects on which the account has permissions.For more information about permission management of MaxCompute users, see User planning and management.
Select the code that is used to create a catalog and click Run that appears on the left side of the code.
View a MaxCompute catalog
UI
Go to the Catalogs page.
Log on to the Realtime Compute for Apache Flink console.
Find the workspace that you want to manage and click Console in the Actions column.
In the left-side navigation pane, click Catalogs.
On the Catalog List page, find the desired catalog and view the Catalog Name and Type columns of the catalog.
If you want to view the databases and tables in the catalog, click View in the Actions column.
Flink SQL
In the script editor, enter the following statement:
DESCRIBE `<catalogName>`.`<projectName>`.`<tableName>`;Parameter
Description
catalogName
The name of the MaxCompute catalog.
projectName
The name of the MaxCompute project.
tableName
The name of the physical table that is stored in MaxCompute.
Select the code that is used to view a catalog and click Run on the left side of the code.
After the code is run, you can view the schema of the MaxCompute physical table in the Realtime Compute for Apache Flink deployment on the Results tab below the editing section.
Use a MaxCompute catalog
Create a MaxCompute physical table by using a catalog
When you execute a Flink SQL DDL statement to create a table in a MaxCompute catalog, a physical table is automatically created in the related MaxCompute project and the data types that are supported by Realtime Compute for Apache Flink are automatically converted into the data types that are supported by MaxCompute. You can create partitioned tables and non-partitioned tables by using MaxCompute catalogs.
Sample statement for creating a non-partitioned table:
CREATE TABLE `<catalogName>`.`<projectName>`.`<tableName>` (
f0 INT,
f1 BIGINT,
f2 DOUBLE,
f3 STRING
);After the preceding statement is executed, you can view the tables in the related MaxCompute project. A non-partitioned table that has the specified name appears in the project. The column names and data types of the non-partitioned table in the MaxCompute project are consistent with the column names and data types of the table that you want to create by using the Flink SQL DDL statement.
Sample statement for creating a partitioned table:
CREATE TABLE `<catalogName>`.`<projectName>`.`<tableName>` (
f0 INT,
f1 BIGINT,
f2 DOUBLE,
f3 STRING,
ds STRING
) PARTITIONED BY (ds);Add a partition key column to the end of the schema in the Flink SQL DDL statement and declare the name of the partition key column in the PARTITIONED BY clause. After the statement is executed, a partitioned table that has the specified name appears in the related MaxCompute project. In the partitioned table, the common columns are f0, f1, f2, and f3, and the partition key column is ds.
Column names in MaxCompute tables are all in lowercase, and column names in a Flink DDL statement are case-sensitive. If a column name in a DDL statement contains uppercase letters, the uppercase letters are automatically converted into lowercase letters. If a DDL statement contains multiple columns that have the same name after uppercase letters are converted into lowercase letters, an error is returned.
Read data from a table of a MaxCompute catalog
MaxCompute catalogs can read the schemas of physical tables from MaxCompute. Therefore, you can obtain data of a table without the need to declare the schema of the table in a Flink DDL statement. Sample statement:
SELECT * FROM `<catalogName>`.`<projectName>`.`<tableName>`;If no parameter is specified in the preceding statement, the MaxCompute catalog performs the default behavior. In this case, the MaxCompute catalog reads full data from all partitions of a partitioned table. If you want to read data from the specified partition, use the table of the MaxCompute catalog as an incremental source table, or use the table of the MaxCompute catalog as a dimension table, you can refer to the parameter settings in MaxCompute and declare the related information in the SQL comment.
Sample statement for reading data from the specified partition:
SELECT * FROM `<catalogName>`.`<projectName>`.`<tableName>`
/*+ OPTIONS('partition' = 'ds=230613') */;Sample statement for using the table of the MaxCompute catalog as an incremental source table:
SELECT * FROM `<catalogName>`.`<projectName>`.`<tableName>`
/*+ OPTIONS('startPartition' = 'ds=230613') */;Sample statement for using the table of the MaxCompute catalog as a dimension table:
SELECT * FROM `<anotherTable>` AS l LEFT JOIN
`<catalogName>`.`<projectName>`.`<tableName>`
/*+ OPTIONS('partition' = 'max_pt()', 'cache' = 'ALL') */
FOR SYSTEM_TIME AS OF l.proc_time AS r
ON l.id = r.id;You can use the preceding statements to configure other parameters that are related to MaxCompute source tables and MaxCompute dimension tables. MaxCompute catalogs do not contain watermark information. If you want to specify a watermark when you use a table of a MaxCompute catalog as a source table to read data, you can use the CREATE TABLE ... LIKE ... statement. Sample statement:
CREATE TABLE `<newTable>` ( WATERMARK FOR ts AS ts )
LIKE `<catalogName>`.`<projectName>`.`<tableName>`;In the preceding sample statement, ts is the name of a column of the DATETIME data type in a MaxCompute physical table. You can specify the event time for a column of the DATETIME data type in Realtime Compute for Apache Flink and add watermark information to the column. After the table that is named by using the newTable parameter is created, all data that is read from the table contains the watermark information.
Write data to a table of a MaxCompute catalog
MaxCompute catalogs support data writing to static partitions or dynamic partitions. For more information, see Sample code for a result table. For example, if a MaxCompute physical table has two levels of partitions and the partition key columns are ds and hh, you can execute the following statements to write data to the related table of a MaxCompute catalog:
-- Write data to static partitions.
INSERT INTO `<catalogName>`.`<projectName>`.`<tableName>`
/*+ OPTIONS('partition' = 'ds=20231024,hh=09') */
SELECT <otherColumns>, '20231024', '09' FROM `<anotherTable>`;
-- Write data to dynamic partitions.
INSERT INTO `<catalogName>`.`<projectName>`.`<tableName>`
/*+ OPTIONS('partition' = 'ds,hh') */
SELECT <otherColumns>, ds, hh FROM `<anotherTable>`;In the SELECT statement, the partition key columns must be placed after common columns based on the order of partition levels.
Delete a MaxCompute catalog
After you delete a MaxCompute catalog, the deployments that are running are not affected. However, the deployments that use a table of the catalog can no longer find the table when the deployments are published or restarted. Proceed with caution when you delete a MaxCompute catalog.
Delete a MaxCompute catalog on the UI
Go to the Catalogs page.
Log on to the Realtime Compute for Apache Flink console.
Find the workspace that you want to manage and click Console in the Actions column.
In the left-side navigation pane, click Catalogs.
On the Catalog List page, find the desired catalog and click Delete in the Actions column.
In the message that appears, click Delete.
NoteAfter you delete the catalog, you can view the Catalogs pane on the left side of the Catalog List page to check whether the catalog is deleted.
Delete a MaxCompute catalog by executing an SQL statement
In the script editor, enter the following statement:
DROP CATALOG `<catalogName>`;In the preceding statement, <catalogName> indicates the name of the MaxCompute catalog that you want to delete.
WarningAfter you delete a MaxCompute catalog, the related deployments that are running are not affected. However, the related drafts that are not published or the related deployments that need to be suspended and then resumed are affected. Proceed with caution.
Right-click the statement that is used to delete the catalog and choose Run from the shortcut menu.
View the Catalogs pane on the left side of the Catalog List page to check whether the catalog is dropped.
Data type mappings between MaxCompute and Realtime Compute for Apache Flink
For more information about the data types that are supported by MaxCompute, see MaxCompute data type system version 2.0.
Data type mappings from MaxCompute to Realtime Compute for Apache Flink
When Realtime Compute for Apache Flink reads data from an existing MaxCompute physical table, the data types of fields in the MaxCompute table are mapped to the data types of Realtime Compute for Apache Flink. The following table describes the data type mappings from MaxCompute to Realtime Compute for Apache Flink.
Data type of MaxCompute | Data type of Realtime Compute for Apache Flink |
BOOLEAN | BOOLEAN |
TINYINT | TINYINT |
SMALLINT | SMALLINT |
INT | INTEGER |
BIGINT | BIGINT |
FLOAT | FLOAT |
DOUBLE | DOUBLE |
DECIMAL(precision, scale) | DECIMAL(precision, scale) |
CHAR(n) | CHAR(n) |
VARCHAR(n) | VARCHAR(n) |
STRING | STRING |
BINARY | BYTES |
DATE | DATE |
DATETIME | TIMESTAMP(3) |
TIMESTAMP | TIMESTAMP(9) |
ARRAY | ARRAY |
MAP | MAP |
STRUCT | ROW |
JSON | STRING |
Data type mappings from Realtime Compute for Apache Flink to MaxCompute
When you use Flink DDL statements to create a MaxCompute table in a catalog, the data types of fields in the Flink DDL statements are mapped to the data types of MaxCompute. The following table describes the data type mappings from Realtime Compute for Apache Flink to MaxCompute.
Data type of Realtime Compute for Apache Flink | Data type of MaxCompute |
BOOLEAN | BOOLEAN |
TINYINT | TINYINT |
SMALLINT | SMALLINT |
INTEGER | INT |
BIGINT | BIGINT |
FLOAT | FLOAT |
DOUBLE | DOUBLE |
DECIMAL(precision, scale) | DECIMAL(precision, scale) |
CHAR(n) | CHAR(n) |
VARCHAR / STRING | STRING |
BINARY | BINARY |
VARBINARY / BYTES | BINARY |
DATE | DATE |
TIMESTAMP(n<=3) | DATETIME |
TIMESTAMP(3<n<=9) | TIMESTAMP |
ARRAY | ARRAY |
MAP | MAP |
ROW | STRUCT |