A multi-zone Alibaba Cloud Elasticsearch cluster provides enhanced disaster recovery capabilities and higher availability. By distributing nodes across multiple zones, the cluster can withstand zone-level failures with minimal disruption. This guide describes how to deploy a multi-zone cluster, understand its automatic shard allocation, and perform manual zone switchovers and recoveries in case of faults.
Scenarios and benefits
Multi-zone deployments enhance the resilience and availability of your Elasticsearch cluster. The system automatically selects zones with sufficient Elastic Compute Service (ECS) instances for optimal distribution.
Single zone:
Description: Default deployment method, with all nodes within a single zone.
Use case: Suitable for non-critical workloads where high availability is not a primary concern.
Two zones:
Description: Distributes nodes across two distinct zones.
Use case: Implements cross-zone disaster recovery, recommended for production workloads where service continuity is important. If replica shards are configured, nodes in the remaining zone can continue providing services if one zone fails.
Three zones:
Description: Distributes nodes across three distinct zones.
Use case: Provides the highest level of availability and implements advanced disaster recovery. Highly recommended for critical production workloads with stringent service availability requirements. If one or two zones become unavailable, the remaining zones can continue providing services.
How multi-zone works
When a multi-zone cluster is deployed and replica shards are configured for indices:
Automatic failover: If nodes in one zone fail, the cluster can automatically continue to provide services using nodes in the remaining zones, without interruption, significantly enhancing availability.
Resource augmentation (on switchover): During a switchover, Alibaba Cloud Elasticsearch can automatically add computing resources to the remaining healthy zones to compensate for the resources lost in the faulty zone.
Usage notes
Before deploying or managing a multi-zone cluster, review these critical points.
Node multiples
The number of data nodes, warm nodes (if any), and client nodes (if any) must be a multiple of the number of zones selected for deployment. (e.g., for two zones, you might have 4 data nodes, 2 in each zone).
Automatic zone selection
When purchasing, you select the number of zones (two or three). Alibaba Cloud Elasticsearch automatically selects the specific zones that have sufficient ECS instances to deploy the cluster; you do not need to manually choose each zone.
NoteThe Elasticsearch console typically displays only the "main" zone for client network traffic, while the cluster's nodes might be deployed across other available zones.
Region selection
If a region has at least three zones with sufficient ECS instances, dedicated master nodes are deployed in three zones, providing robust master node election in case of a single zone failure.
If a region has only two zones (or only two zones with sufficient ECS instances), dedicated master nodes are deployed in those two zones. If the zone with two master nodes fails, a switchover is necessary. Before recovery, write operations may be affected, but read operations can continue.
NoteFor important production business, avoid selecting regions with only one or two zones if high availability is paramount.
Replica shard configuration
Configuring replica shards is fundamental for achieving high availability and disaster recovery in a multi-zone cluster.
Two-zone deployment: Configure at least one replica shard for each primary shard of an index (
number_of_replicas: 1). If one zone becomes unavailable, the other zone can use the replicas to provide continuous service. (Defaultnumber_of_replicas: 1often suffices.)Three-zone deployment: Configure at least two replica shards for each primary shard of an index (
number_of_replicas: 2). If one or even two zones become unavailable, the remaining zones can still provide services.ImportantIf a cluster contains indices with no replica shards, data loss may occur during a switchover or zone failure.
How to configure replicas: To change the default number of replica shards (e.g., to 2 for three-zone deployment), modify your index templates.
json PUT _template/your_template_name { "index_patterns": ["your_index_prefix-*"], "settings": { "number_of_replicas": 2 }}
Deploy a multi-zone cluster
Log on to the Alibaba Cloud Elasticsearch console.
Follow the instructions to create an Alibaba Cloud Elasticsearch cluster.
For Number of Zones, select either 2-AZ or 3-AZ.
Alibaba Cloud Elasticsearch will automatically handle the distribution of nodes across the selected number of available zones.
Set Dedicated Master Node to Yes.
At least 3 dedicated master nodes (the default setting) are required to ensure cluster stability and high availability in a multi-zone setup.
Perform a zone switchover and recovery
Perform a zone switchover
If a zone in your multi-zone cluster experiences a fault, you can initiate a switchover. After the faulty zone recovers, you can perform a recovery operation to reintegrate it.
Before performing a switchover, always verify that all indices in your cluster have configured replica shards. This is critical to ensure normal read and write operations continue without data loss or service interruption during and after the switchover.
Log on to the Alibaba Cloud Elasticsearch console.
In the left navigation menu, choose Elasticsearch Clusters.
Navigate to the target cluster.
In the top navigation bar, select the resource group to which the cluster belongs and the region where the cluster resides.
On the Elasticsearch Clusters page, find the cluster and click its ID.
In the Node Visualization section of the Basic Information page of the cluster, perform a switchover.
Hover your pointer over the faulty zone and click Switch Over.
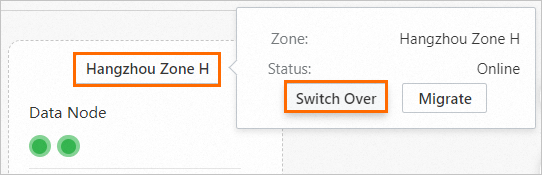
In the Confirm Operation message, click Continue.
Alibaba Cloud will then restart the cluster to apply the switchover. The zone's state will change from
EnabledtoDisabled.NoteResource augmentation: During a switchover, the system attempts to add corresponding nodes (dedicated master, client, data nodes) to the remaining enabled zones to maintain computing resources. However, success is not guaranteed due to factors like underlying resource availability.
Workload impact: A switchover reduces the total computing resources and maximum workload capacity of the cluster. It's crucial to control cluster usage and implement throttling if necessary during fault conditions.
Post-switchover shard reallocation (if needed):
If your cluster status is yellow after a switchover (indicating unassigned shards), you might need to force reallocation of shards from the disabled zone to the remaining zones.PUT /_cluster/settings { "persistent" : { "cluster.routing.allocation.awareness.force.zone_id.values" : {"0": null, "1": null, "2": null} } }
Perform a zone recovery (switch back)
After the faulty zone recovers, perform a recovery operation to reintegrate it into the cluster.
In the Node Visualization section, recover the zone for which the switchover is performed.
In the Confirm Operation message, click Continue.
The system will restart your Elasticsearch cluster to apply the recovery. The zone's state will change from
DisabledtoEnabled.Resource Adjustment: During recovery, the system removes nodes that were added during the switchover. Data on these removed data nodes will be migrated to other data nodes in the cluster.
Advanced configuration: automatic shard allocation awareness
During multi-zone cluster deployment, Alibaba Cloud Elasticsearch automatically enables shard allocation awareness. This mechanism helps distribute shards intelligently across different zones.
cluster.routing.allocation.awareness.attributes
This parameter is automatically set to zone_id.
The system adds the
node.attr.zone_idparameter to the startup configuration of each node, identifying its deployment zone (e.g.,-Dnode.attr.zone_id=ap-southeast-5c).ImportantDo not attempt to change this parameter using Elasticsearch API operations, as it may lead to cluster exceptions.
cluster.routing.allocation.awareness.force.zone_id.values (Optional)
This parameter can be configured to force even shard allocation.
Purpose: Prevents a zone from becoming overloaded by reallocating shards from a failed zone to an active one.
Example: For an index with one primary and three replica shards across Zone A and Zone B, both zones will have two shards. If Zone A becomes unavailable, forced awareness prevents the shards from Zone A from being reallocated to Zone B.
Default: This parameter is not configured by default, meaning forced awareness is disabled.
Example value:
["ap-southeast-5c", "ap-southeast-5b"]