This topic describes how to use index lifecycle management (ILM) to implement a hot-warm architecture for time-series data such as logs and metrics. This architecture automatically moves aging data from hot nodes to warm nodes, improving indexing performance and reducing storage costs.
Prerequisites
To successfully implement Index Lifecycle Management (ILM), your Alibaba Cloud Elasticsearch cluster must meet the following conditions:
Elasticsearch V6.6.0 or later.
If you do not have an existing cluster, create one with the appropriate version.
If your existing cluster is older than V6.6.0, upgrade it.
Warm nodes configured.
Obtain warm nodes in one of two ways:
During cluster creation
For proper ILM functionality, ensure all nodes within your cluster (hot, warm, etc.) run the same version.
Usage notes
Policy granularity: Configure ILM policies based on your specific business requirements. We recommend using different aliases and policies for indexes with distinct structures or retention needs to simplify management.
Write operations: Avoid writing data directly to indexes that have entered the warm or cold phase. To maintain chronological order and data integrity, set actions within your ILM policy to make indexes read-only (e.g., using
shrinkorread_onlyactions) after they transition from the hot phase.Test before production: Always test your ILM policies thoroughly in a non-production environment before applying them to critical production clusters.
Policy name immutability: Policy names cannot be changed after creation. Plan your naming conventions carefully.
Rollover alias requirement: ILM's rollover feature requires an index template that uses a rollover alias.
Initial index naming: The initial index name must end with a six-digit number (e.g.,
-000001) for rollover to function correctly.
Procedure
This section guides you through configuring ILM in your Alibaba Cloud Elasticsearch cluster.
Step 1: Confirm warm node configuration
Before proceeding, verify that your cluster has correctly provisioned warm nodes.
Alibaba Cloud Elasticsearch console
Go to your Elasticsearch cluster's basic information page and check the cluster architecture in the Node Visualization section.
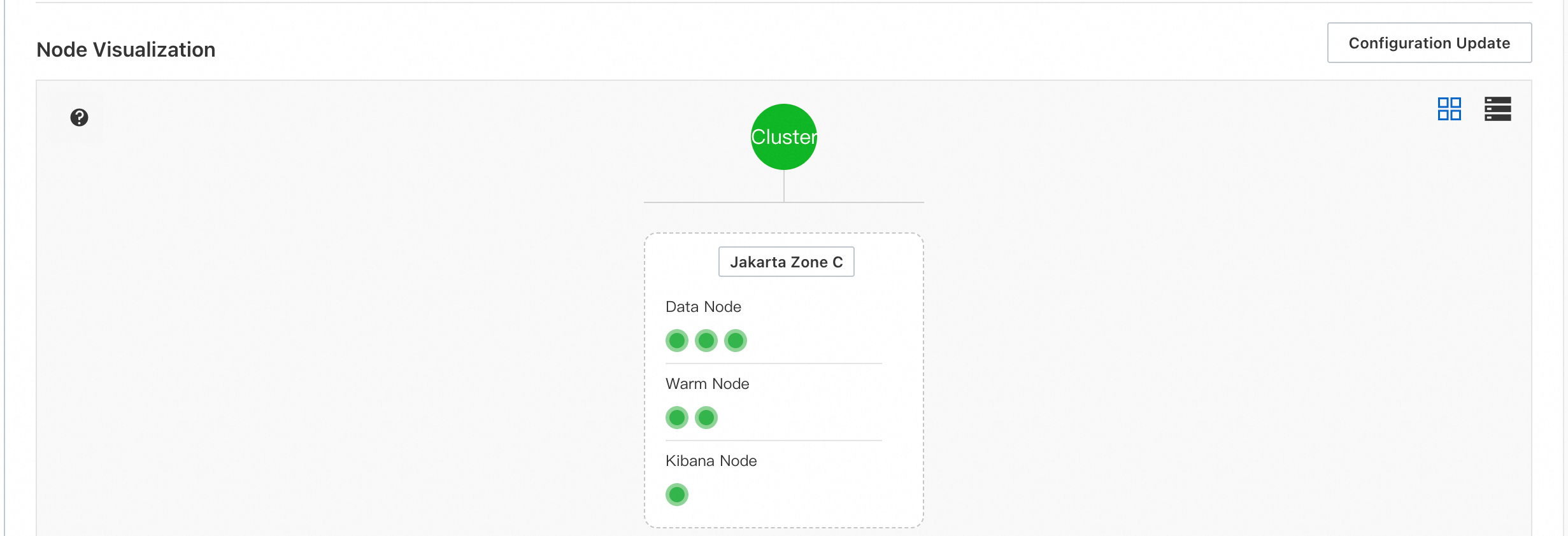
Kibana
Go to the Kibana console, choose Dev Tools, and run the following command in Console:
GET _cat/nodeattrs?v&h=node,attr,value&s=attr:descA response containing the box_type:warm attribute indicates the cluster is configured with warm nodes.
Step 2: Create an ILM policy
Define the lifecycle stages for your data by creating an ILM policy. This example creates game-policy with hot, warm, cold, and delete phases.
In the Kibana console, run the following command:
PUT /_ilm/policy/game-policy
{
"policy": {
"phases": {
"hot": {
"actions": {
"rollover": {
"max_size": "1GB",
"max_age": "1d",
"max_docs": 1000
}
}
},
"warm": {
"min_age": "30m",
"actions": {
"forcemerge": {
"max_num_segments":1
},
"shrink": {
"number_of_shards":1
}
}
},
"cold": {
"min_age": "1h",
"actions": {
"allocate": {
"require": {
"box_type": "warm"
}
}
}
},
"delete": {
"min_age": "2h",
"actions": {
"delete": {}
}
}
}
}
}The policy name cannot be changed after it is created.
You can also create a policy in the Kibana console. However, the minimum unit for max_age in Kibana is hours. If you use the API, you can specify the minimum unit in seconds.
Step 3: Create an index template and apply the ILM policy
An index template automatically applies settings, including the ILM policy, to new indices matching a specified pattern.
Run the following command.
The index.routing.allocation.require.box_type:"hot" setting ensures new indices are initially created on hot nodes.
PUT _template/gamestabes_template
{
"index_patterns" : ["gamestabes-*"],
"settings": {
"index.number_of_shards": 5,
"index.number_of_replicas": 1,
"index.routing.allocation.require.box_type":"hot",
"index.lifecycle.name": "game-policy",
"index.lifecycle.rollover_alias": "gamestabes"
}
}Parameters:
index.routing.allocation.require.box_type: Specifies the node attribute that new indices must match.
index.lifecycle.name: The name of the ILM policy to apply.
index.lifecycle.rollover_alias: The alias used for rollover.
Step 4: Create an initial index
To use ILM with rolling indices, you must create an initial index manually. Ensure it follows the required naming convention.
Run the following command to create an index with an auto-incrementing suffix and is_write_index: true set on the alias:
PUT gamestabes-000001
{
"aliases": {
"gamestabes":{
"is_write_index": true
}
}
}For the rollover feature to work, the initial index name must end with a six-digit number (e.g., -000001). Subsequent rolled-over indices will increment this number.
Step 5: Verify ILM functionality
After configuring ILM, verify that data is correctly moving through the lifecycle phases.
Ingest data to the index using the alias.
PUT gamestabes/_doc/1 { "EU_Sales" : 3.58, "Genre" : "Platform", "Global_Sales" : 40.24, "JP_Sales" : 6.81, "Name" : "Super Mario Bros.", "Other_Sales" : 0.77, "Platform" : "NES", "Publisher" : "Nintendo", "Year_of_Release" : "1985", "na_Sales" : 29.08 }NoteThe system periodically checks for ILM policy matches (default: every 10 minutes, configurable via
indices.lifecycle.poll_interval). When conditions (e.g.,max_size,max_age,max_docs) are met, data will roll over to a new index, and the current index will enter the next phase (warm).Filter indexes by lifecycle phase and view index details.
In Kibana's left navigation menu, click Management.
Under Elasticsearch, click Index Management.
Filter indices by their Lifecycle phase or Lifecycle status to observe their transition.
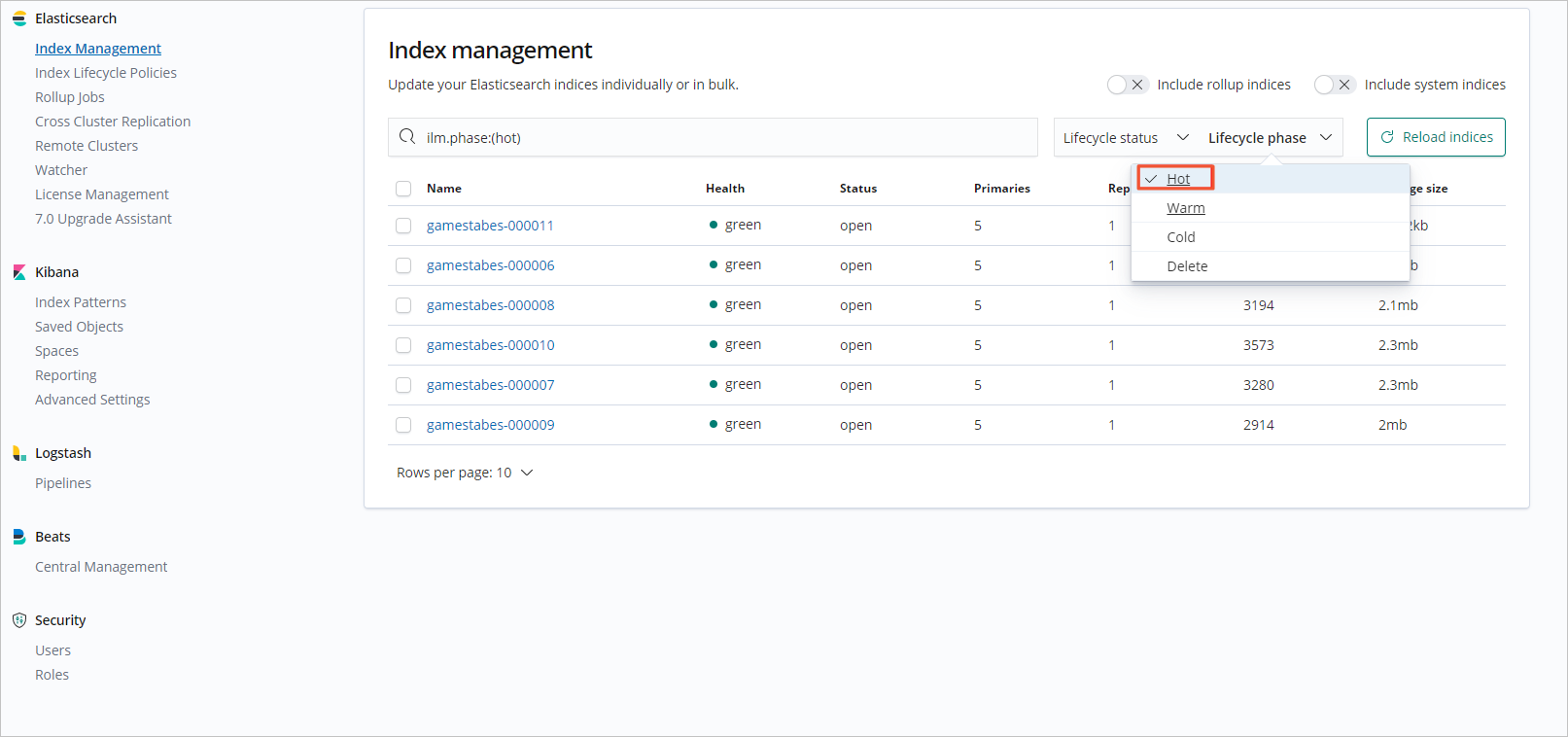
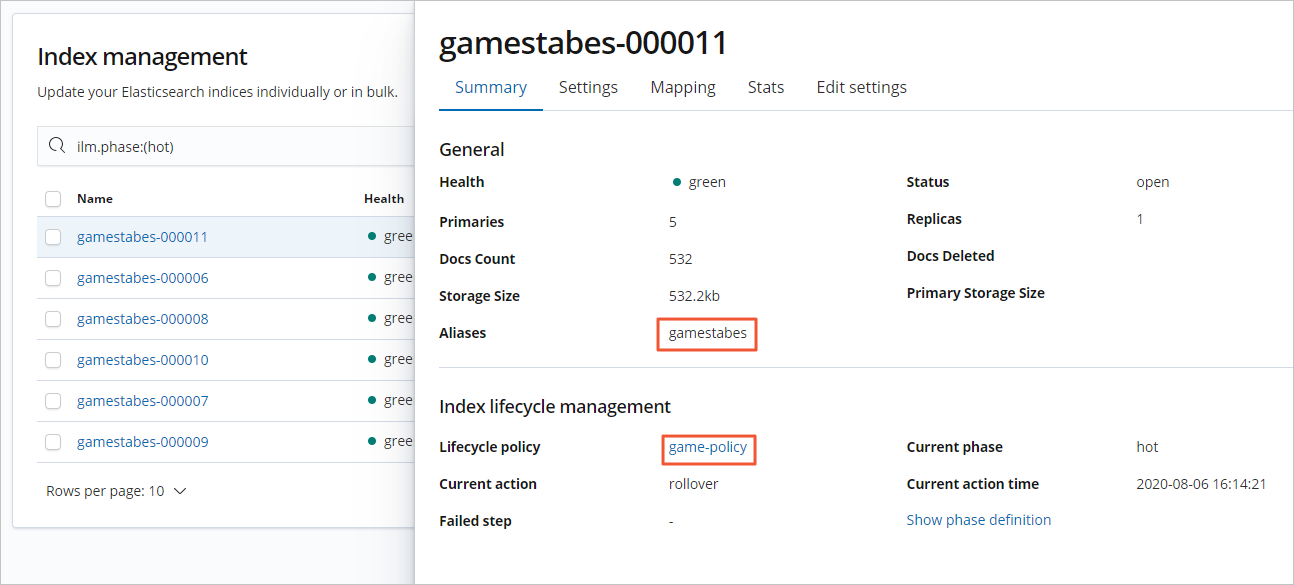
Click an index name to view its detailed lifecycle information and status.
View data distribution
To confirm indices have correctly moved to warm nodes as per your policy:
Query indices in the cold phase and view the configurations of the indexes.
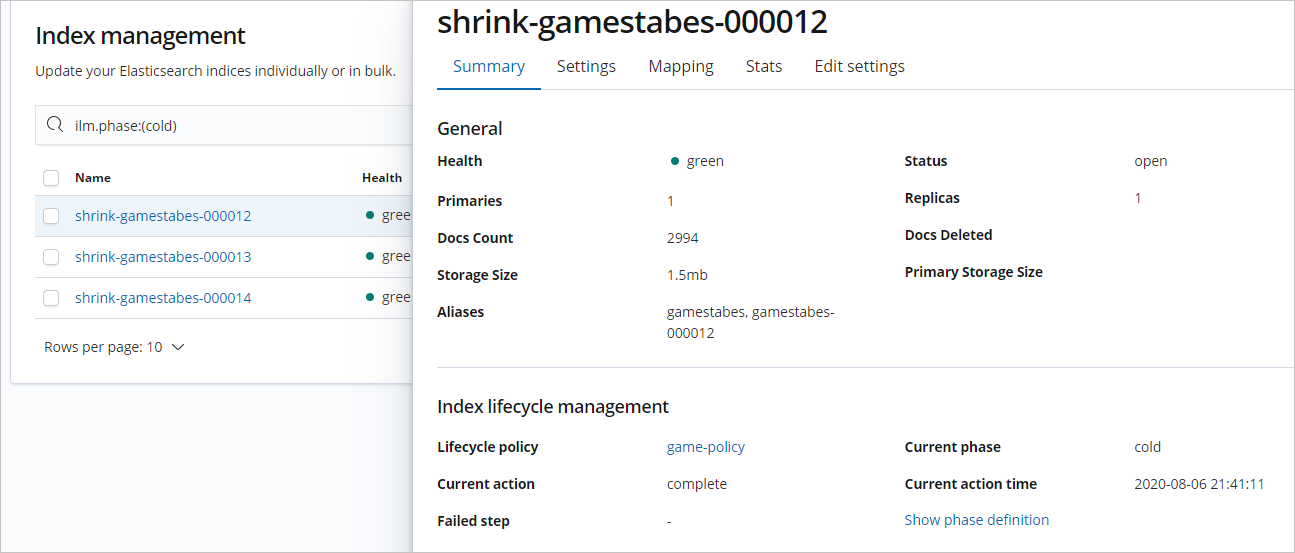
Run Get shard information to query the distribution of shards for cold indices.
GET _cat/shards?shrink-gamestables-000012The result indicates indices in the cold phase are on warm nodes:

Manage ILM policies
After initial configuration, you may need to update an existing policy or switch to a new one.
Update an existing policy
Modify your existing
game-policy(e.g., changemax_sizeto3GB) and re-run thePUT /_ilm/policy/game-policycommand.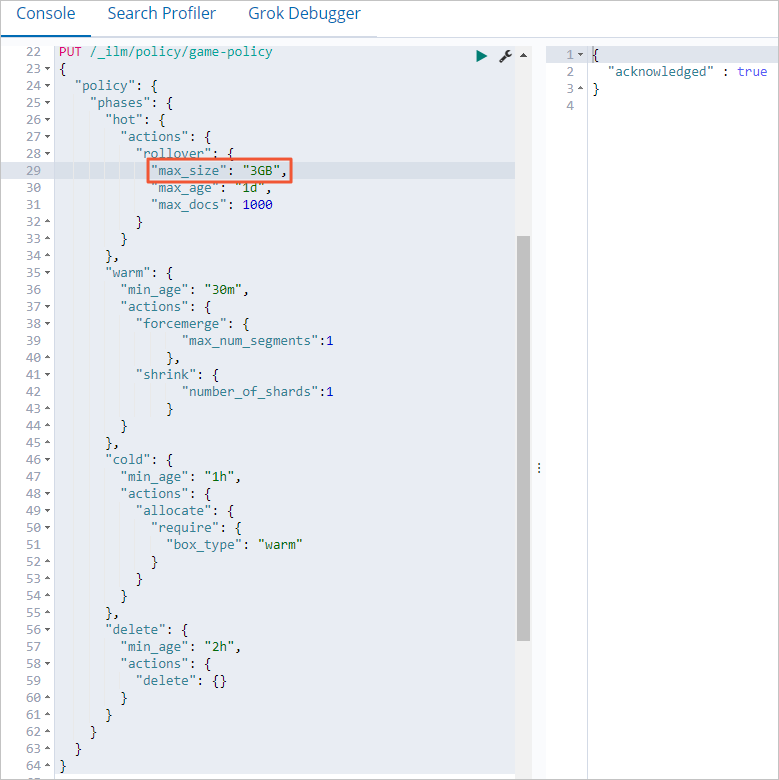
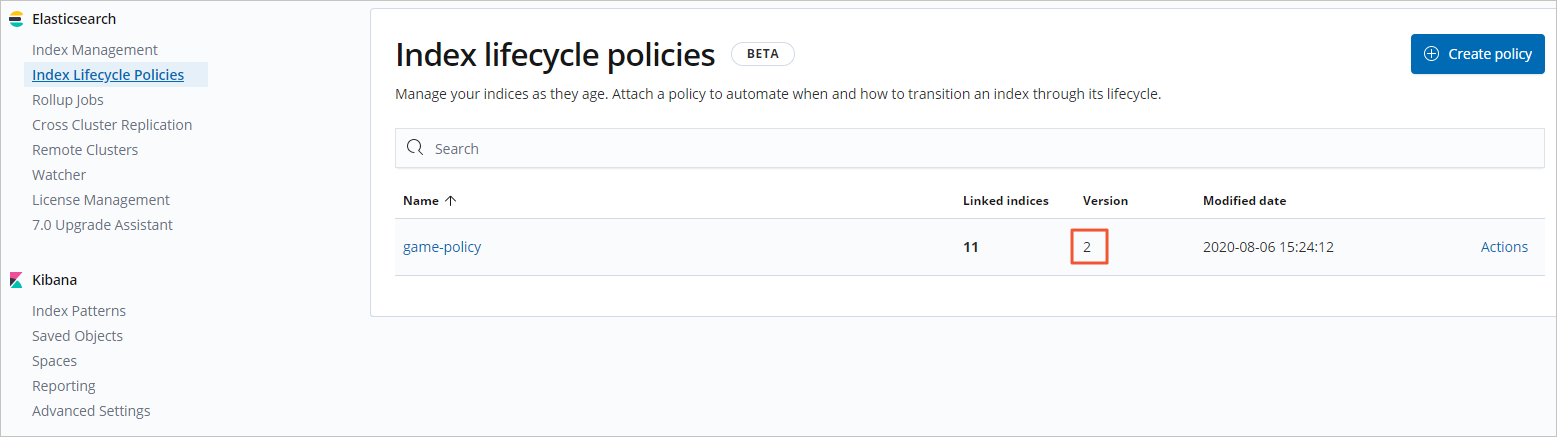
View the version of the updated policy in Kibana.
In the left navigation menu, click Management.
In the Elasticsearch section, click Index Lifecycle Policies.
Observe the version number for game-policy. It will be one greater than the original policy.
 Note
NoteThe updated policy takes effect from the next rollover event.
Switch to a new ILM policy
To apply an entirely new policy to indices, create the new policy and then update the index template.
Create a new ILM policy.
PUT /_ilm/policy/game-new { "policy": { "phases": { "hot": { "actions": { "rollover": { "max_size": "3GB", "max_age": "1d", "max_docs": 1000 } } }, "warm": { "min_age": "30m", "actions": { "forcemerge": { "max_num_segments":1 }, "shrink": { "number_of_shards":1 } } }, "cold": { "min_age": "1h", "actions": { "allocate": { "require": { "box_type": "warm" } } } }, "delete": { "min_age": "2h", "actions": { "delete": {} } } } } }Apply the new ILM policy to the index template by updating
index.lifecycle.name::PUT _template/gamestabes_template { "index_patterns" : ["gamestabes-*"], "settings": { "index.number_of_shards": 5, "index.number_of_replicas": 1, "index.routing.allocation.require.box_type":"hot", "index.lifecycle.name": "game-new", "index.lifecycle.rollover_alias": "gamestabes" } }NoteThe new policy will take effect from the next rollover for indices created after the template update. To migrate existing indices to a new ILM policy, run the
PUT <indexPatterns>/_settingscommand (e.g.,PUT gamestabes-*/_settings). For more information, see Switching policies for an index.
FAQ
Reference
Create an index lifecycle management policy in Elasticsearch