This topic describes how to use index lifecycle management (ILM) to manage Heartbeat time-series data, automatically moving aging monitoring data from hot nodes to warm nodes to optimize performance and reduce storage costs.
Prerequisites
Managing heartbeat data with ILM requires the following:
Warm nodes are configured for the cluster.
Obtain warm nodes in one of two ways:
During cluster creation
Usage notes
Template and alias requirement: Define an index template and alias before setting a lifecycle policy.
Policy modification timing: If you modify a lifecycle policy during rollover, the new policy takes effect at the next rollover event.
Procedure
Step 1: Confirm warm node configuration
Before proceeding, verify that your cluster has correctly provisioned warm nodes.
Alibaba Cloud Elasticsearch console
Go to your Elasticsearch cluster's basic information page and check the cluster architecture in the Node Visualization section.
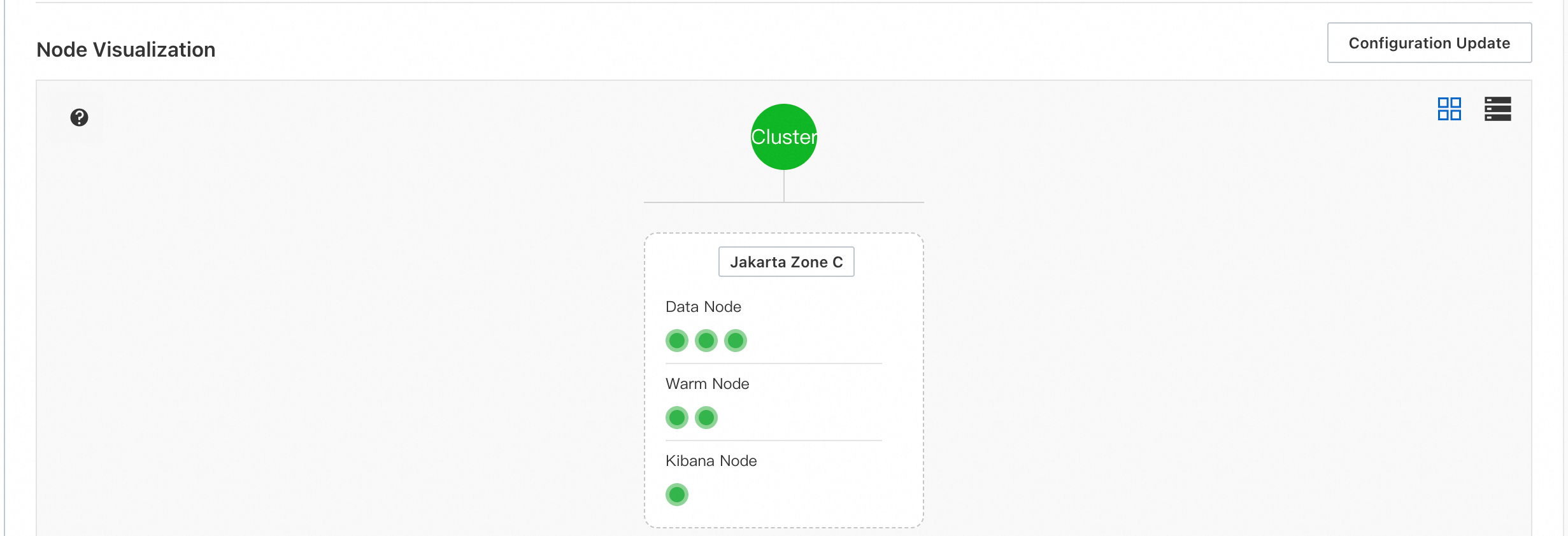
Kibana
Go to the Kibana console, choose Dev Tools, and run the following command in Console:
GET _cat/nodeattrs?v&h=node,attr,value&s=attr:descA response containing the box_type:warm attribute indicates the cluster is configured with warm nodes.
Step 2: Configure ILM in Heartbeat
To seamlessly integrate Heartbeat with Elasticsearch ILM, you must define the ILM configuration in the heartbeat.yml file. For details, see Set up index lifecycle management.
Download the Heartbeat installation package and decompress it.
Edit the
heartbeat.ymlfile to defineheartbeat.monitors,setup.template.settings,setup.kibana, andoutput.elasticsearch.The following configuration is used in this topic.
heartbeat.monitors: - type: icmp schedule: '*/5 * * * * * *' hosts: ["47.111.xx.xx"] setup.template.settings: index.number_of_shards: 3 index.codec: best_compression index.routing.allocation.require.box_type: "hot" setup.kibana: # Kibana Host # Scheme and port can be left out and will be set to the default (http and 5601) # In case you specify and additional path, the scheme is required: http://localhost:5601/path # IPv6 addresses should always be defined as: https://[2001:db8::1]:5601 host: "https://es-cn-4591jumei00xxxxxx.kibana.elasticsearch.aliyuncs.com:5601" output.elasticsearch: # Array of hosts to connect to. hosts: ["es-cn-4591jumei00xxxxxx.elasticsearch.aliyuncs.com:9200"] ilm.enabled: true setup.template.overwrite: true ilm.rollover_alias: "heartbeat" ilm.pattern: "{now/d}-000001" # Enabled ilm (beta) to use index lifecycle management instead daily indices. #ilm.enabled: false # Optional protocol and basic auth credentials. #protocol: "https" username: "elastic" password: "<your_password>"Parameters:
index.number_of_shards: The number of primary shards. The default value is 1.
index.routing.allocation.require.box_type: Writes index data to hot nodes.
host: Replace this with the public endpoint of your Kibana service. Obtain the endpoint from the Kibana configuration page.
hosts: Replace this with the public or internal endpoint of your Elasticsearch cluster. Get the endpoint from the Basic Information page of the cluster. For more information, see View the basic information of an instance.
NoteIf you set this to the public endpoint, configure a public network access whitelist for the cluster. For more information, see Configure a public or private access whitelist for an instance. If you set this to the internal endpoint, make sure the cluster and the server where Heartbeat is installed are in the same VPC.
ilm.enabled: Set to
trueto enable ILM.setup.template.overwrite: Specifies whether to overwrite the original index template. If you have already loaded this version of the index template into Elasticsearch, set this parameter to
trueto overwrite the original template.ilm.rollover_alias: The alias for the index generated during a rollover. The default is heartbeat-\{beat.version\}.
ilm.pattern: The pattern for the index generated during a rollover. Supports date math. The default is {now/d}-000001. When a rollover is triggered, the last digit of the new index name is incremented by 1. For example, the first rollover creates an index named heartbeat-2020.04.29-000001. When the rollover condition is met again, Elasticsearch creates a new index named heartbeat-2020.04.29-000002.
username: The default username is
elastic.password: The password for the elastic user is set when you create the cluster.
For more information about other parameters, see the official Heartbeat configuration documentation.
ImportantIf you modify ilm.rollover_alias or ilm.pattern after loading the index template, set setup.template.overwrite to
trueto rewrite the index template.Start Heartbeat.
sudo ./heartbeat -e
Step 3: Create an ILM policy
Create the heartbeat-policy using the ILM API or Kibana console. This example uses the ILM API.
Heartbeat includes a default policy. Load it with ./heartbeat setup --ilm-policy or export it with ./heartbeat export ilm-policy. You can modify the exported policy for custom configurations.
In the Kibana console, run the following command to create an ILM policy.
PUT /_ilm/policy/heartbeat-policy
{
"policy": {
"phases": {
"hot": {
"actions": {
"rollover": {
"max_size": "5mb",
"max_age": "1d",
"max_docs": 100
}
}
},
"warm": {
"min_age": "60s",
"actions": {
"forcemerge": {
"max_num_segments":1
},
"shrink": {
"number_of_shards":1
}
}
},
"cold": {
"min_age": "3m",
"actions": {
"allocate": {
"require": {
"box_type": "warm"
}
}
}
},
"delete": {
"min_age": "1h",
"actions": {
"delete": {}
}
}
}
}
}The policy name cannot be changed after it is created.
You can also create a policy in the Kibana console. However, the minimum unit for max_age in Kibana is hours. If you use the API, you can specify the minimum unit in seconds.
Step 4: Apply the ILM policy to an index template
After starting Heartbeat, a Heartbeat index template is automatically created in your Elasticsearch cluster. Apply the ILM policy created in Step 3: Create an ILM policy with this template.
In the left navigation menu, click Management.
In the Elasticsearch area, click Index Lifecycle Policies.
In the Index lifecycle policies list, select .
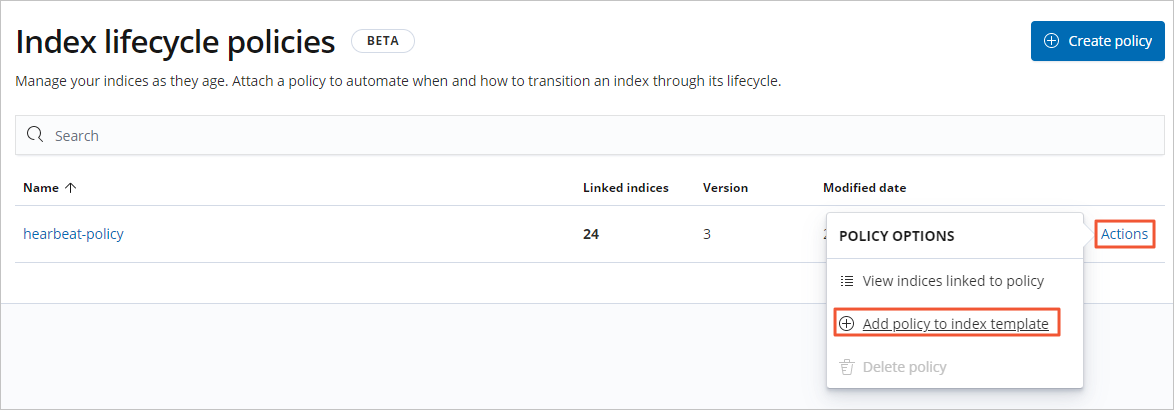
In the dialog box, select the index template from the Index template dropdown list, and enter an index alias in the Alias for rollover index text box.
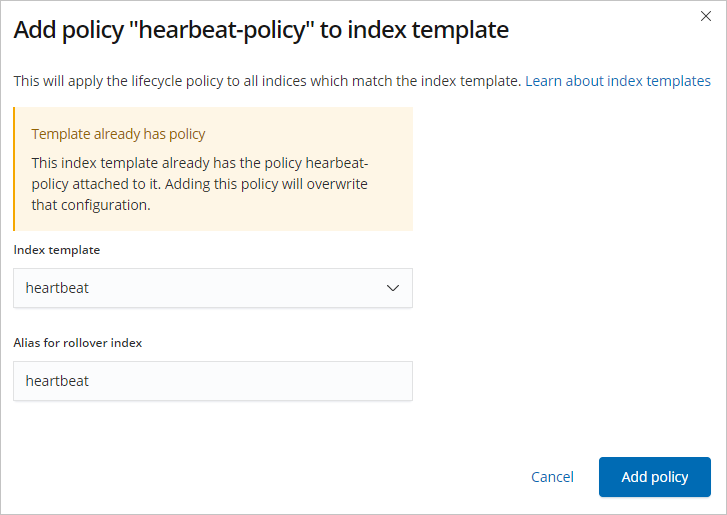
Click Add policy.
Step 5: Associate an index with the ILM policy
After starting Heartbeat, an index is automatically created in your Elasticsearch cluster. You must manually link the corresponding ILM policy with an index for initialization.
On the Management page, in the Elasticsearch area, choose Index Management.
In the Index management list, find the target index and click its name.
On the Summary page, click to remove the default policy that comes with Heartbeat.
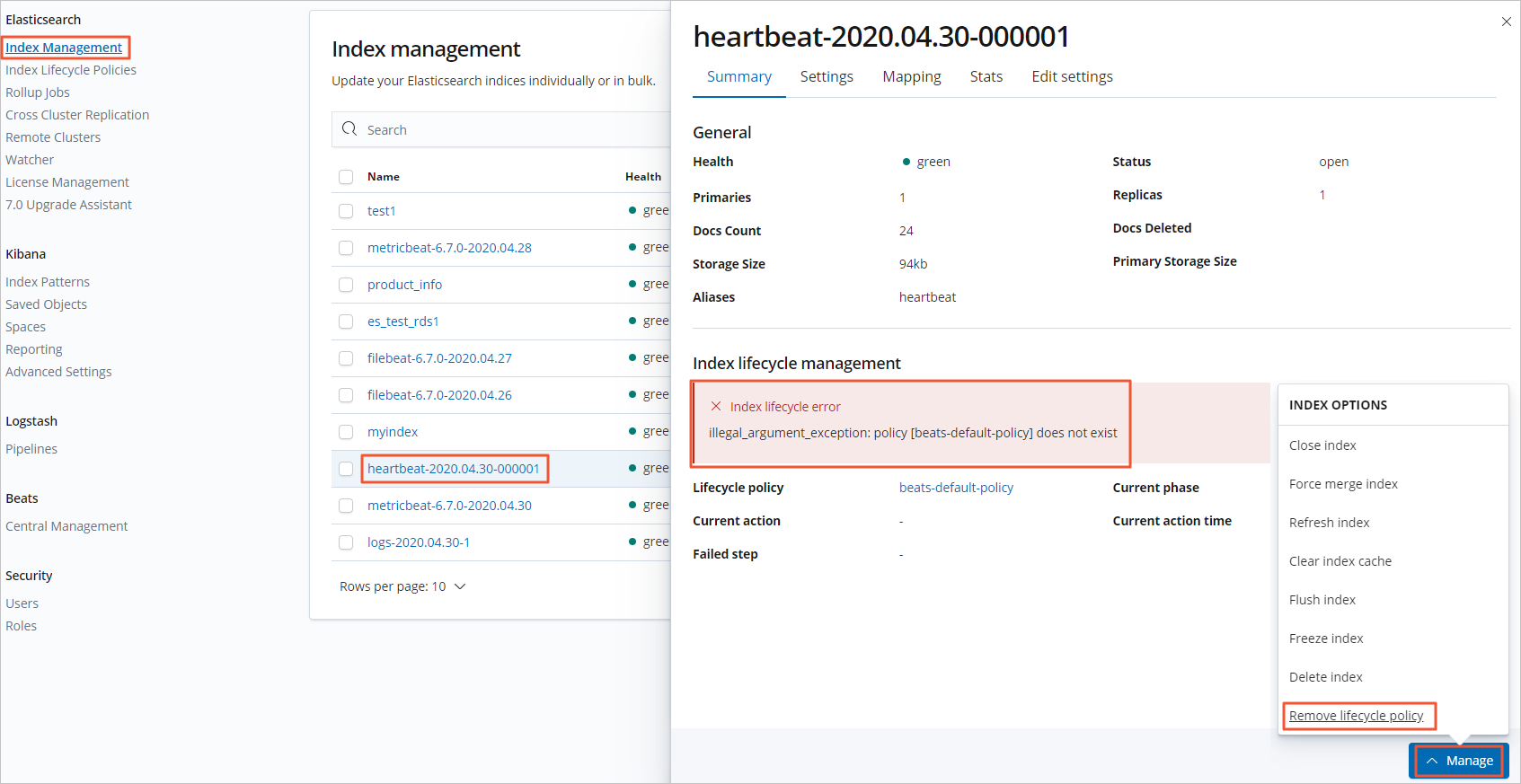
In the dialog box, click Remove policy.
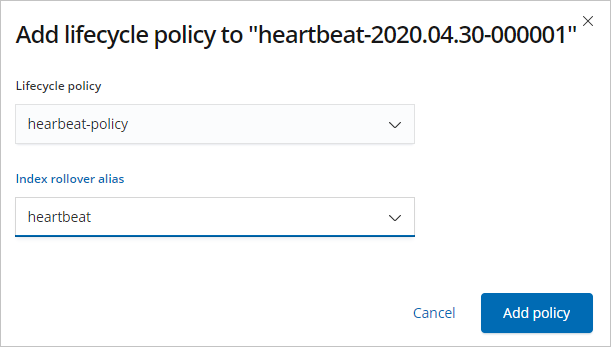
Then, select .
In the dialog box, select the lifecycle policy created in Step 3: Create an ILM policy from Lifecycle policy. In the Index rollover alias text box, enter the index alias defined in Step 4: Apply the ILM policy to an index template, and click Add policy.
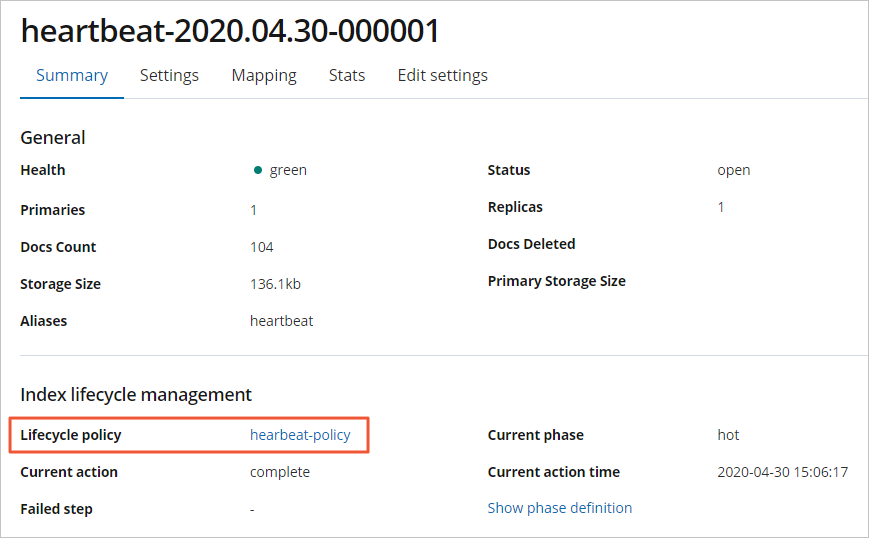
After the ILM policy is associated with an initial index, the result is shown in the following figure.
Step 6: View indices in each phase
To view indices in the hot phase, on the Index management page, select .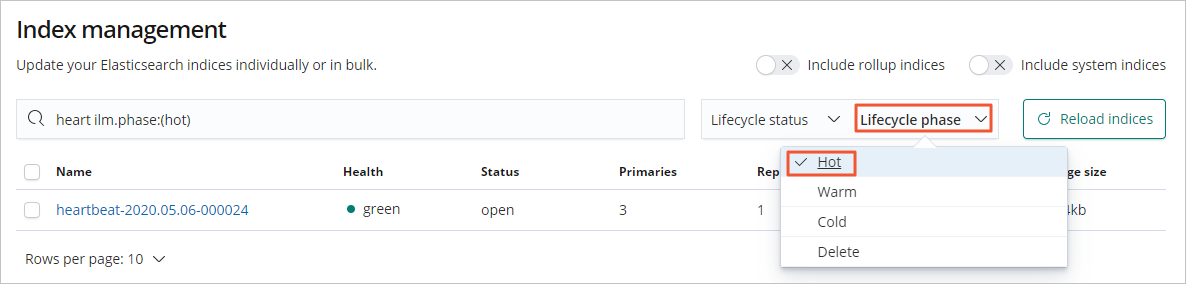
You can also use the same method to view indexes in other phases.