Apache Spark is a general-purpose framework for big data computing and has all the computing advantages of Hadoop MapReduce. The difference is that Spark caches data in memory to enable fast iterations of large datasets. This way, data can be directly read from the cache instead of disks. This enables Spark to provide higher processing performance than MapReduce. This topic describes how to enable Spark to write data to and read data from Alibaba Cloud Elasticsearch by using Elasticsearch-Hadoop (ES-Hadoop).
Preparations
- Create an Alibaba Cloud Elasticsearch cluster and enable the Auto Indexing feature for the cluster.For more information, see Create an Alibaba Cloud Elasticsearch cluster and Access and configure an Elasticsearch cluster. In this topic, an Elasticsearch V6.7.0 cluster is created.Important In a production environment, we recommend that you disable the Auto Indexing feature. You must create an index and configure mappings for the index in advance. The Elasticsearch cluster used in this topic is only for tests. Therefore, the Auto Indexing feature is enabled.
Create an E-MapReduce (EMR) cluster in the virtual private cloud (VPC) where the Elasticsearch cluster resides.
EMR cluster configuration:
EMR Version: Select EMR-3.29.0.
Required Services: Spark (2.4.5) is one of the required services. Default settings are retained for other services.
For more information, see Create a cluster.
ImportantBy default, 0.0.0.0/0 is specified in the private IP address whitelist of the Elasticsearch cluster. You can view the whitelist configuration on the cluster security configuration page. If the default setting is not used, you must add the private IP address of the EMR cluster to the whitelist.
For more information about how to obtain the private IP address of an EMR cluster, see View the cluster list and cluster details.
For more information about how to configure a private IP address whitelist for an Elasticsearch cluster, see Configure a public or private IP address whitelist for an Elasticsearch cluster. The IP addresses in the whitelist can be used to access the Elasticsearch cluster over a VPC.
Prepare a Java environment. The JDK version must be 1.8.0 or later.
Compile and run a Spark job
Prepare test data.
Log on to the E-MapReduce console and obtain the IP address of the master node of the EMR cluster. Then, use SSH to log on to the Elastic Compute Service (ECS) instance that is indicated by the IP address.
For more information, see Log on to a cluster.
Write the test data to a file.
In this example, the following JSON-formatted test data is written to the http_log.txt file:
{"id": 1, "name": "zhangsan", "birth": "1990-01-01", "addr": "No.969, wenyixi Rd, yuhang, hangzhou"} {"id": 2, "name": "lisi", "birth": "1991-01-01", "addr": "No.556, xixi Rd, xihu, hangzhou"} {"id": 3, "name": "wangwu", "birth": "1992-01-01", "addr": "No.699 wangshang Rd, binjiang, hangzhou"}Run the following command to upload the file to the /tmp/hadoop-es directory on the master node of the EMR cluster:
hadoop fs -put http_log.txt /tmp/hadoop-es
Add POM dependencies.
Create a Java Maven project and add the following POM dependencies to the pom.xml file of the project:
<dependencies> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.12</artifactId> <version>2.4.5</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_2.11</artifactId> <version>2.4.5</version> </dependency> <dependency> <groupId>org.elasticsearch</groupId> <artifactId>elasticsearch-spark-20_2.11</artifactId> <version>6.7.0</version> </dependency> </dependencies>ImportantMake sure that the versions of POM dependencies are consistent with those of the related Alibaba Cloud services. For example, the version of elasticsearch-spark-20_2.11 is consistent with that of your Elasticsearch cluster, and the version of spark-core_2.12 is consistent with that of HDFS.
Compile code.
Write data
The following sample code is used to write the test data to the company index of the Elasticsearch cluster:
import java.util.Map; import java.util.concurrent.atomic.AtomicInteger; import org.apache.spark.SparkConf; import org.apache.spark.SparkContext; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api.java.function.Function; import org.apache.spark.sql.Row; import org.apache.spark.sql.SparkSession; import org.elasticsearch.spark.rdd.api.java.JavaEsSpark; import org.spark_project.guava.collect.ImmutableMap; public class SparkWriteEs { public static void main(String[] args) { SparkConf conf = new SparkConf(); conf.setAppName("Es-write"); conf.set("es.nodes", "es-cn-n6w1o1x0w001c****.elasticsearch.aliyuncs.com"); conf.set("es.net.http.auth.user", "elastic"); conf.set("es.net.http.auth.pass", "xxxxxx"); conf.set("es.nodes.wan.only", "true"); conf.set("es.nodes.discovery","false"); conf.set("es.input.use.sliced.partitions","false"); SparkSession ss = new SparkSession(new SparkContext(conf)); final AtomicInteger employeesNo = new AtomicInteger(0); //Replace /tmp/hadoop-es/http_log.txt with the actual path of your test data. JavaRDD<Map<Object, ?>> javaRDD = ss.read().text("/tmp/hadoop-es/http_log.txt") .javaRDD().map((Function<Row, Map<Object, ?>>) row -> ImmutableMap.of("employees" employeesNo.getAndAdd(1), row.mkString())); JavaEsSpark.saveToEs(javaRDD, "company/_doc"); } }Read data
The following sample code is used to read and display the test data that is written to the Elasticsearch cluster:
import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaPairRDD; import org.apache.spark.api.java.JavaSparkContext; import org.elasticsearch.spark.rdd.api.java.JavaEsSpark; import java.util.Map; public class ReadES { public static void main(String[] args) { SparkConf conf = new SparkConf().setAppName("readEs").setMaster("local[*]") .set("es.nodes", "es-cn-n6w1o1x0w001c****.elasticsearch.aliyuncs.com") .set("es.port", "9200") .set("es.net.http.auth.user", "elastic") .set("es.net.http.auth.pass", "xxxxxx") .set("es.nodes.wan.only", "true") .set("es.nodes.discovery","false") .set("es.input.use.sliced.partitions","false") .set("es.resource", "company/_doc") .set("es.scroll.size","500"); JavaSparkContext sc = new JavaSparkContext(conf); JavaPairRDD<String, Map<String, Object>> rdd = JavaEsSpark.esRDD(sc); for ( Map<String, Object> item : rdd.values().collect()) { System.out.println(item); } sc.stop(); } }
Table 1. Parameters
Parameter
Default value
Description
es.nodes
localhost
The endpoint that is used to access the Elasticsearch cluster. We recommend that you use the internal endpoint. You can obtain the internal endpoint on the Basic Information page of the Elasticsearch cluster. For more information, see View the basic information of a cluster.
es.port
9200
The port number that is used to access the Elasticsearch cluster.
es.net.http.auth.user
elastic
The username that is used to access the Elasticsearch cluster.
NoteIf you use the elastic account to access your Elasticsearch cluster and reset the password of the account, it may require some time for the new password to take effect. During this period, you cannot use the elastic account to access the cluster. Therefore, we recommend that you do not use the elastic account to access an Elasticsearch cluster. You can log on to the Kibana console and create a user with the required role to access an Elasticsearch cluster. For more information, see Use the RBAC mechanism provided by Elasticsearch X-Pack to implement access control.
es.net.http.auth.pass
/
The password that corresponds to the elastic username. The password is specified when you create the Elasticsearch cluster. If you forget the password, you can reset it. For more information, see Reset the access password for an Elasticsearch cluster.
es.nodes.wan.only
false
Specifies whether to enable node sniffing when the Elasticsearch cluster uses a virtual IP address for connections. Valid values:
true: indicates that node sniffing is enabled.
false: indicates that node sniff is disabled.
es.nodes.discovery
true
Specifies whether to prohibit the node discovery mechanism. Valid values:
true: indicates that the node discovery mechanism is prohibited.
false: indicates that the node discovery mechanism is not prohibited.
ImportantIf you use Alibaba Cloud Elasticsearch, you must set this parameter to false.
es.input.use.sliced.partitions
true
Specifies whether to use partitions. Valid values:
true: uses partitions. In this case, more time may be required for the index read-ahead phase. The time required for this phase may be longer than the time required for data queries. To improve query efficiency, we recommend that you set this parameter to false.
false: does not use partitions.
es.index.auto.create
true
Specifies whether the system creates an index in the Elasticsearch cluster when you use ES-Hadoop to write data to the cluster. Valid values:
true: indicates that the system creates an index in the Elasticsearch cluster.
false: indicates that the system does not create an index in the Elasticsearch cluster.
es.resource
/
The name and type of the index on which data read or write operations are performed.
es.mapping.names
/
The mappings between the field names in the table and those in the index of the Elasticsearch cluster.
For more information about the configuration items of ES-Hadoop, see open source ES-Hadoop configuration.
- Compress the code into a JAR package and upload it to an EMR client, such as the master node in the EMR cluster or the gateway cluster that is associated with this EMR cluster.
On the EMR client, run the following Spark jobs:
Write data
cd /usr/lib/spark-current ./bin/spark-submit --master yarn --executor-cores 1 --class "SparkWriteEs" /usr/local/spark_es.jarImportantReplace /usr/local/spark_es.jar with the path to which you have uploaded your JAR package.
Read data
cd /usr/lib/spark-current ./bin/spark-submit --master yarn --executor-cores 1 --class "ReadES" /usr/local/spark_es.jarAfter the data is read, the result shown in the following figure is returned.
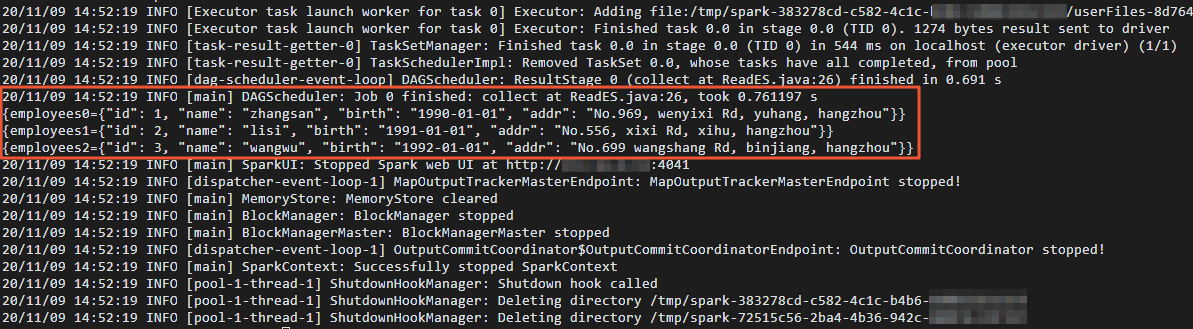
Verify results
- Log on to the Kibana console of the Elasticsearch cluster.For more information, see Log on to the Kibana console.
- In the left-side navigation pane, click Dev Tools.
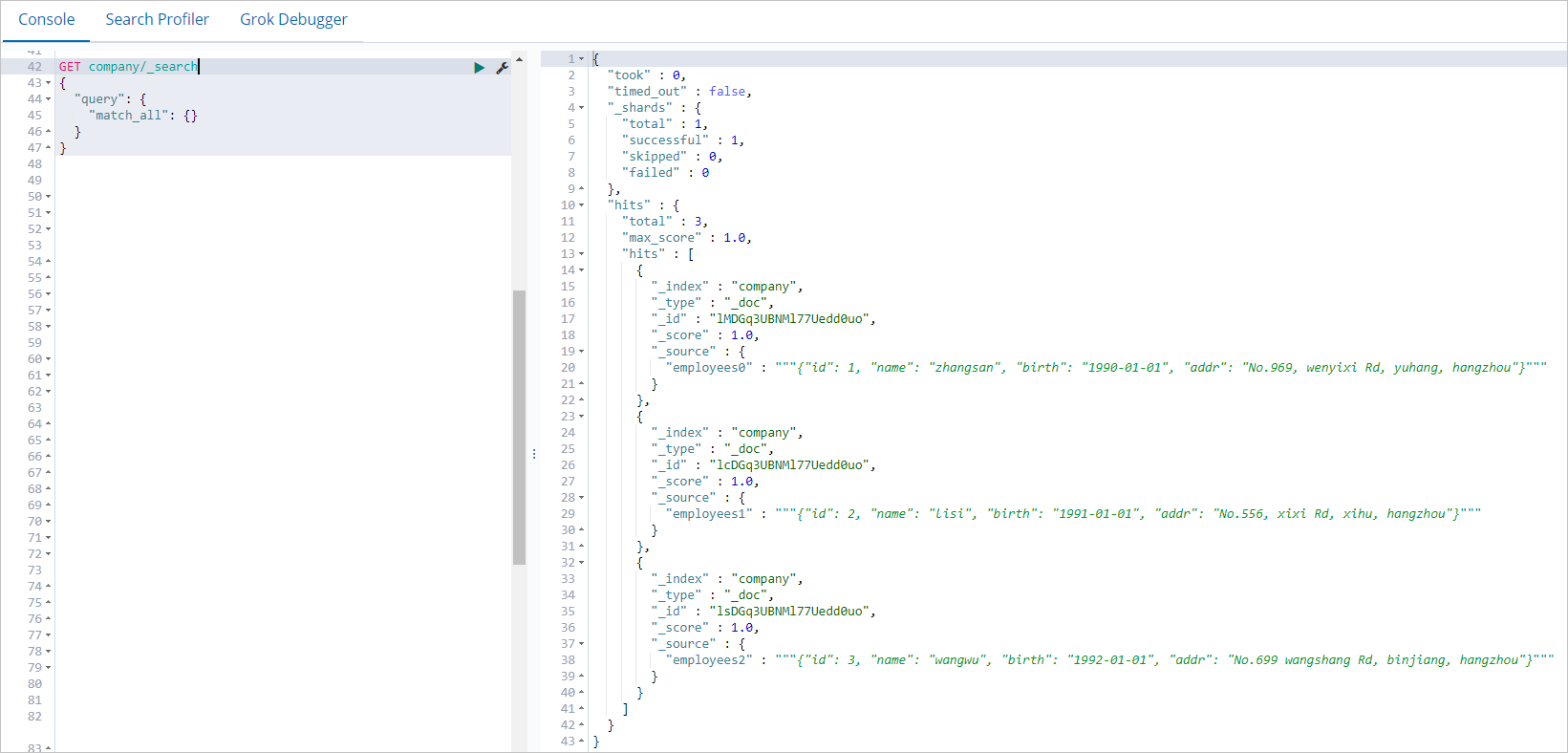
On the Console tab of the page that appears, run the following command to query the data that is written by a Spark job:
GET company/_search { "query": { "match_all": {} } }If the command is successfully run, the result shown in the following figure is returned.
Summary
This topic describes how to use ES-Hadoop to write data to and read data from Alibaba Cloud Elasticsearch by running Spark jobs in an EMR cluster. After ES-Hadoop is integrated with Spark, ES-Hadoop supports Spark datasets, resilient distributed datasets (RDDs), Spark Streaming, Scala, and Spark SQL. You can configure ES-Hadoop based on your requirements. For more information, see Apache Spark support.