If you want to synchronize incremental data from a MySQL database to an Alibaba Cloud Elasticsearch cluster and have a high requirement for real-time performance, you can use Canal to synchronize the data.
Background information
Canal is an open source product provided by Alibaba Group. Canal can parse incremental log data in MySQL and allows you to subscribe to and consume incremental data. For more information about the working principles of and introduction to Canal, see Canal. In this example, Canal is used as a secondary node of an ApsaraDB RDS for MySQL instance and receives the binary logs that are generated for the incremental data of the instance. Then, a RESTful API is used to write the data to an Alibaba Cloud Elasticsearch cluster. The solution described in this topic is suitable for scenarios in which users have high requirements for real-time performance of data synchronization.
Prerequisites
An ApsaraDB RDS for MySQL instance, an Alibaba Cloud Elasticsearch cluster, and an Elastic Compute Service (ECS) instance are created. We recommend that you create them in the same virtual private cloud (VPC).
For information about how to create an ApsaraDB RDS for MySQL instance, see Create an ApsaraDB RDS for MySQL instance. In this example, an ApsaraDB RDS instance that runs MySQL 5.7 is created.
For information about how to create an Alibaba Cloud Elasticsearch cluster, see Create an Alibaba Cloud Elasticsearch cluster. In this example, an Elasticsearch V6.7 cluster of the Kernel-enhanced Edition is created.
NoteBefore you use Canal to write data to your Elasticsearch cluster, you must add the IP address of the ECS instance on which Canal is deployed to an IP address whitelist of the Elasticsearch cluster. For more information, see Configure a public or private IP address whitelist for an Elasticsearch cluster.
The ECS instance is used to deploy the Canal server and Canal adapter. For information about how to create an ECS instance, see Create an instance by using the wizard. In this example, an ECS instance that runs an image of CentOS 7.6 64-bit is created.
Limits
The solution described in this topic can be used to synchronize only incremental MySQL data to an Alibaba Cloud Elasticsearch cluster.
The version of the Java development kit (JDK) that you install must be 1.8.0 or later.
Canal 1.1.4 cannot be used to synchronize data to an Elasticsearch V7.X cluster.
You need to use Canal 1.1.5 to synchronize data to an Elasticsearch V7.X cluster and use Canal 1.1.7 to synchronize data to an Elasticsearch V8.X cluster. You can also use a method such as Logstash or Data Transmission Service (DTS) to synchronize MySQL data.
When you make configurations to synchronize data, you can customize mappings for the required index. You must make sure that the names and data types of the fields that are defined in the mappings for the index are the same as the names and data types of the fields in the desired ApsaraDB RDS for MySQL database.
If you use the solution described in this topic to synchronize data, you must make sure that Canal is available. Otherwise, faults may occur, or services may be interrupted. For example, you must make sure that data synchronization is not interrupted in scenarios such as ECS instance restart and exit of Canal due to exceptions.
The Canal adapter cannot connect to an Alibaba Cloud Elasticsearch cluster over HTTPS.
Procedure
Step 1: Prepare a MySQL data source
Log on to the ApsaraDB RDS console, and create an ApsaraDB RDS for MySQL database and a table. For more information, see General workflow to use ApsaraDB RDS for MySQL. In this example, the following statement is used to create a table:
-- create table
CREATE TABLE `es_test` (
`id` bigint(32) NOT NULL,
`name` text NOT NULL,
`count` text NOT NULL,
`color` text NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB
DEFAULT CHARACTER SET=utf8;Step 2: Create an index and configure mappings for the index
Log on to the Kibana console of the Elasticsearch cluster. For more information, see Log on to the Kibana console.
NoteIn this example, an Elasticsearch V6.7.0 cluster is used. Operations on clusters of other versions may differ.
- In the left-side navigation pane of the page that appears, click Dev Tools.
On the Console tab, run the following command to create an index.
In this example, an index named es_test is created. The index contains the following fields: count, id, name, and color.
ImportantYou must make sure that the names and data types of fields that are defined in the mappings for the index are the same as the names and data types of the fields that are prepared in Step 1: Prepare a MySQL data source.
PUT es_test?include_type_name=true { "settings" : { "index" : { "number_of_shards" : "5", "number_of_replicas" : "1" } }, "mappings" : { "_doc" : { "properties" : { "count": { "type": "text" }, "id": { "type": "integer" }, "name": { "type" : "text", "analyzer": "ik_smart" }, "color" : { "type" : "text" } } } } }After the index is created and the mappings are configured, the following result is returned:
{ "acknowledged" : true, "shards_acknowledged" : true, "index" : "es_test" }
Step 3: Install the JDK
Connect to the ECS instance.
For more information, see Connect to a Linux instance by using a password or key.
NoteIn this example, a regular user is used.
View available JDK packages.
sudo yum search java | grep -i --color JDKInstall the JDK of the required version.
In this example, java-1.8.0-openjdk-devel.x86_64 is used.
sudo yum install java-1.8.0-openjdk-devel.x86_64Configure environment variables.
Open the profile file in the etc folder.
vim ~/.bash_profileAdd the following environment variables to the file:
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.362.b08-1.el7_9.x86_64 export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar export PATH=$PATH:$JAVA_HOME/binImportantWhen you use the environment variables, you must replace JAVA_HOME with the installation path of your JDK. You can run the
find / -name 'java'command to query the installation path of your JDK.Press Esc, and run the
:wqcommand to save the file and exit from the vi mode. Then, run the following command to apply the configuration:source ~/.bash_profile
Run the following command to check whether the JDK is installed:
java -versionIf the following result is returned, the JDK is installed:
openjdk version "1.8.0_362" OpenJDK Runtime Environment (build 1.8.0_362-b08) OpenJDK 64-Bit Server VM (build 25.362-b08, mixed mode)
Step 4: Install and start the Canal server
Download the Canal server package.
In this example, a Canal 1.1.4 server is used.
wget https://github.com/alibaba/canal/releases/download/canal-1.1.4/canal.deployer-1.1.4.tar.gzNoteCanal 1.1.5 supports Elasticsearch V7.0 clusters. If you are using an Elasticsearch V7.0 cluster, you need to download the Canal 1.1.5 package. For more information, see Canal release note.
You must download the Canal server and Canal adapter packages over the Internet. Make sure that your ECS instance can access the Internet.
Run the following command to decompress the package:
tar -zxvf canal.deployer-1.1.4.tar.gzRun the following command to modify the
instance.propertiesfile in the conf/example/ directory:vi conf/example/instance.properties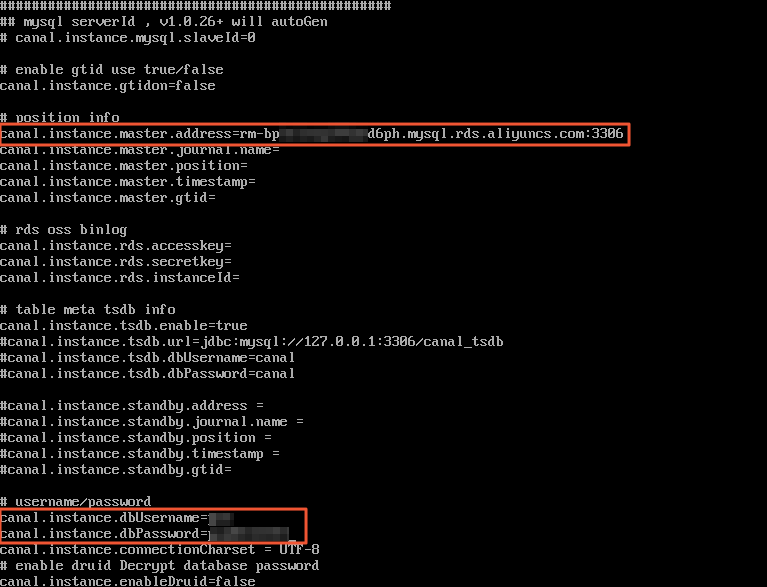
Parameter
Description
canal.instance.master.address
You must set this parameter to a value in the format of <Internal endpoint of the ApsaraDB RDS for MySQL instance>:<Internal port>. You can obtain the required information on the Basic Information page of the ApsaraDB RDS for MySQL instance. Example: rm-bp1u1xxxxxxxxx6ph.mysql.rds.aliyuncs.com:3306.
canal.instance.dbUsername
The username that is used to log on to the ApsaraDB RDS for MySQL database. You can obtain the username on the Accounts page of the ApsaraDB RDS for MySQL instance.
canal.instance.dbPassword
The password that is used to log on to the ApsaraDB RDS for MySQL database.
Press Esc, and run the
:wqcommand to save the file and exit from the vi mode.Start the Canal server and query logs.
./bin/startup.sh cat logs/canal/canal.log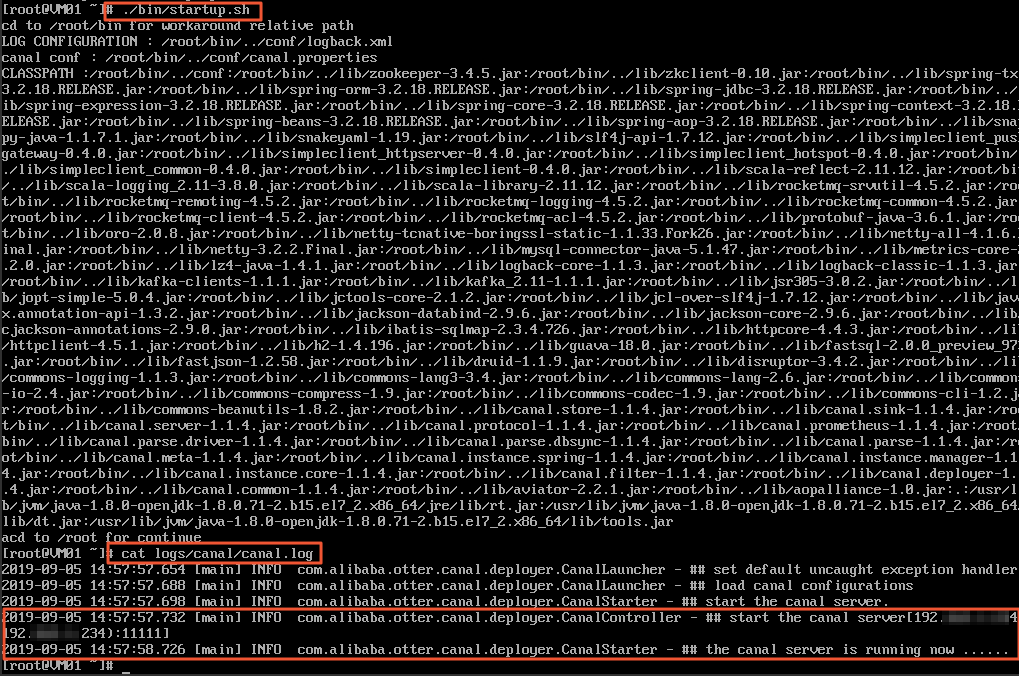
Step 5: Install and start the Canal adapter
Download the Canal adapter package.
In this example, a Canal 1.1.4 adapter is used.
wget https://github.com/alibaba/canal/releases/download/canal-1.1.4/canal.adapter-1.1.4.tar.gzNoteCanal 1.1.5 supports Elasticsearch V7.0 clusters. If you are using an Elasticsearch V7.0 cluster, you need to download the Canal 1.1.5 package. For more information, see Canal release note.
You must download the Canal server and Canal adapter packages over the Internet. Make sure that your ECS instance can access the Internet.
Run the following command to decompress the package:
tar -zxvf canal.adapter-1.1.4.tar.gzRun the following command to modify the
application.ymlfile in the conf/ directory:vi conf/application.yml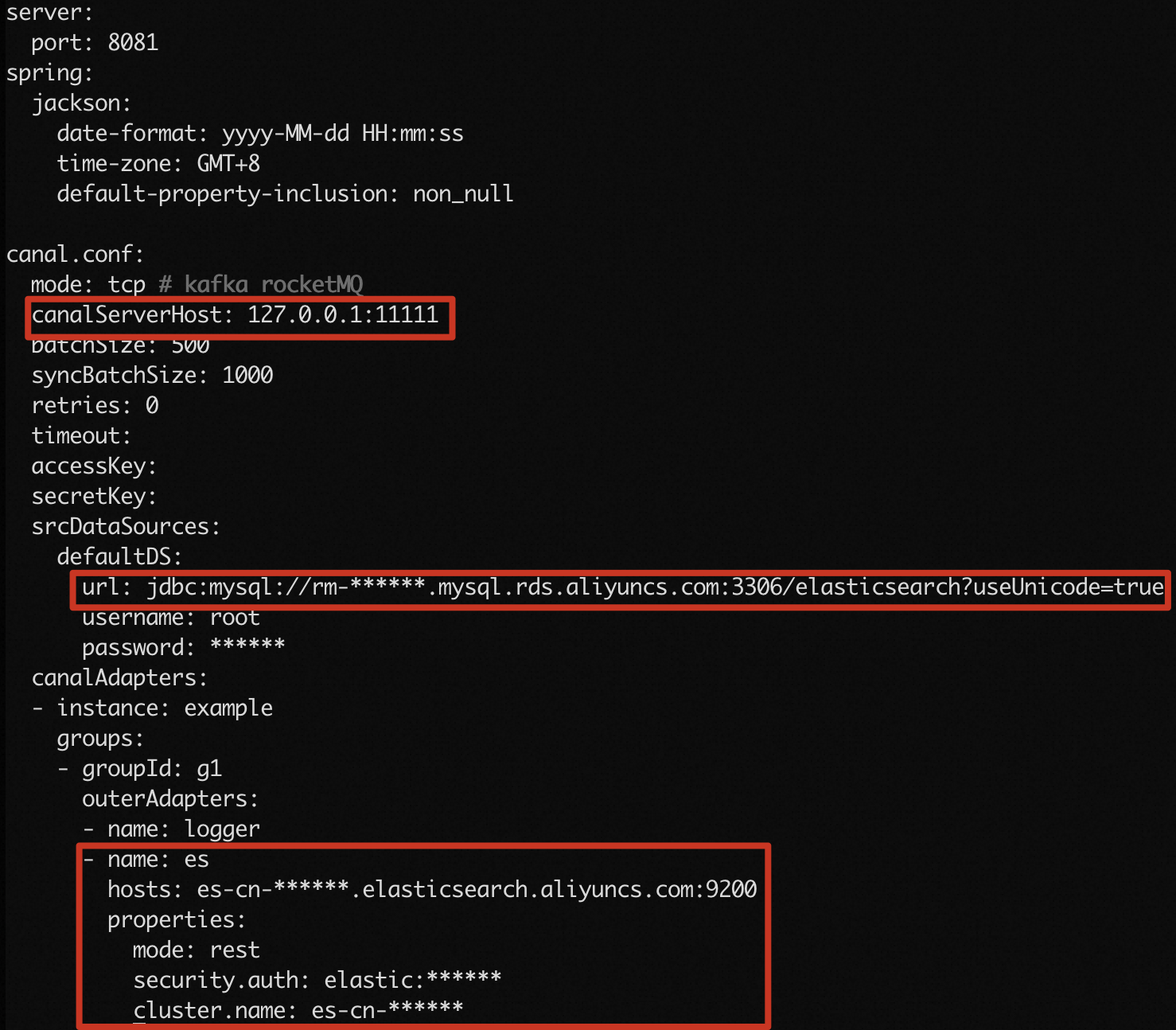
Parameter
Description
canal.conf.canalServerHost
The address of the Canal deployer. Retain the default value 127.0.0.1:11111.
canal.conf.srcDataSources.defaultDS.url
You must set this parameter to a value in the format of jdbc:mysql://<Internal endpoint of the ApsaraDB RDS for MySQL instance>:<Internal port>/<Database name>?useUnicode=true. You can obtain the required information on the Basic Information page of the ApsaraDB RDS for MySQL instance. Example: jdbc:mysql://rm-bp1xxxxxxxxxnd6ph.mysql.rds.aliyuncs.com:3306/elasticsearch?useUnicode=true.
canal.conf.srcDataSources.defaultDS.username
The username that is used to log on to the ApsaraDB RDS for MySQL database. You can obtain the username on the Accounts page of the ApsaraDB RDS for MySQL instance.
canal.conf.srcDataSources.defaultDS.password
The password that is used to log on to the ApsaraDB RDS for MySQL database.
canal.conf.canalAdapters.groups.outerAdapters.hosts
Find name:es and set hosts to a value in the format of <Internal endpoint of the Elasticsearch cluster>:<Internal port>. You can obtain the required information on the Basic Information page of the Elasticsearch cluster. Example: es-cn-v64xxxxxxxxx3medp.elasticsearch.aliyuncs.com:9200.
canal.conf.canalAdapters.groups.outerAdapters.mode
Set this parameter to rest.
canal.conf.canalAdapters.groups.outerAdapters.properties.security.auth
You must set this parameter to a value in the format of <Username of the Elasticsearch cluster>:<Password that corresponds to the username>. Example: elastic:es_password.
canal.conf.canalAdapters.groups.outerAdapters.properties.cluster.name
The ID of the Elasticsearch cluster. You can obtain the ID on the Basic Information page of the Elasticsearch cluster. Example: es-cn-v64xxxxxxxxx3medp.
Press Esc, and run the
:wqcommand to save the file and exit from the vi mode.Repeat the preceding steps to modify the
*.ymlfile in the conf/es/ directory and specify the fields that you want to map from the ApsaraDB RDS for MySQL database to the Elasticsearch cluster.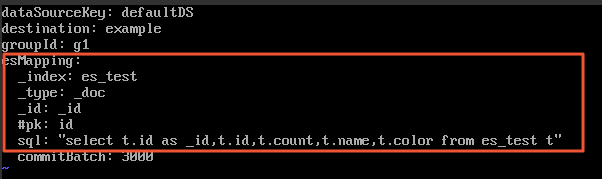
Parameter
Description
esMapping._index
Set the value to the name of the index created in the Elasticsearch cluster in Step 2: Create an index and configure mappings for the index. In this example, es_test is used.
esMapping._type
Set the value to the type of the index created in the Elasticsearch cluster in Step 2: Create an index and configure mappings for the index. In this example, _doc is used.
esMapping._id
The ID of the document generated for the fields that you want to synchronize to the Elasticsearch cluster. You can specify a custom ID. In this example, _id is used.
esMapping.sql
The SQL statement that is used to query the fields that you want to synchronize to the Elasticsearch cluster. In this example, the
select t.id as _id,t.id,t.count,t.name,t.color from es_test tstatement is used.Start the Canal adapter and query logs.
./bin/startup.sh cat logs/adapter/adapter.logNoteIn this example, an ApsaraDB RDS for MySQL instance that runs MySQL 5.7 is used. If you use an ApsaraDB RDS for MySQL instance that runs MySQL of another version, you must make sure that the version of the MySQL driver in the Canal adapter is consistent with the MySQL version of the ApsaraDB RDS for MySQL instance that you want to connect. Otherwise, the Canal adapter fails to be started. For more information, see the FAQ section in this topic.
If the result shown in the following figure is returned, the Canal adapter is started.

Step 6: Verify the synchronization result of incremental data
In the ApsaraDB RDS for MySQL database, add data to, modify data in, or remove data from the es_test table.
insert `ES`.`es_test`(`count`,`id`,`name`,`color`) values('11',2,'canal_test2','red');Log on to the Kibana console of the Elasticsearch cluster. For more information, see Log on to the Kibana console.
- In the left-side navigation pane of the page that appears, click Dev Tools.
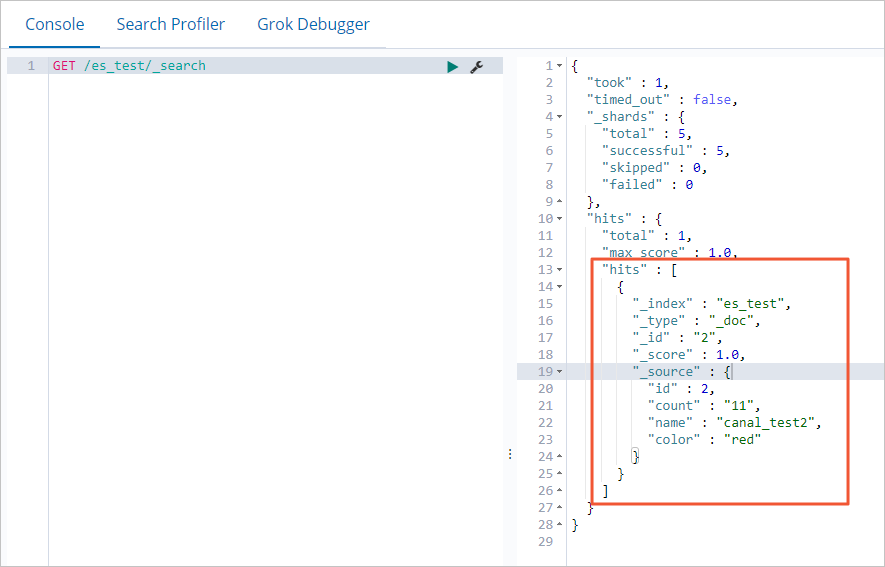
On the Console tab, run the following command to query the synchronized data:
GET /es_test/_searchIf the data synchronization is successful, the result shown in the following figure is returned.
 Important
ImportantCanal synchronizes only incremental data.
FAQ
Q: What do I do if the following error message is returned in the logs generated for the Canal adapter when I start the adapter: java.lang.RuntimeException: java.lang.RuntimeException: java.lang.ClassCastException: com.alibaba.druid.pool.DruidDataSource cannot be cast to com.alibaba.druid.pool.DruidDataSource
at com.alibaba.otter.canal.client.adapter.es7x.ES7xAdapter.init(ES7xAdapter.java:54) ~[client-adapter.es7x-1.1.5-jar-with-dependencies.jar:na]
A: Replace client-adapter.es7x-1.1.5-jar-with-dependencies.jar in the canal.adapter-1.1.5\plugin directory with the related file for canal-1.1.5-alpha-2.
For more information, Canal issues.
In this example, the root user is used.
Download the package of canal-1.1.5-alpha-2. For more information, see Canal release note.
wget https://github.com/alibaba/canal/releases/download/canal-1.1.5-alpha-2/canal.adapter-1.1.5-SNAPSHOT.tar.gzDecompress the package.
tar -zxvf canal.adapter-1.1.5-SNAPSHOT.tar.gzCopy client-adapter.es7x-1.1.5-SNAPSHOT-jar-with-dependencies.jar in the plugin folder for canal-1.1.5-alpha-2 to the canal.adapter-1.1.5\plugin directory.
NoteThe directory of the file that you need to copy may differ. The actual directory prevails.
cp canal.adapter-1.1.5-SNAPSHOT/plugin/client-adapter.es7x-1.1.5-SNAPSHOT-jar-with-dependencies.jar canal/canal.adapter/pluginDelete client-adapter.es7x-1.1.5-jar-with-dependencies.jar from the canal.adapter-1.1.5\plugin directory.
rm -rf client-adapter.es7x-1.1.5-jar-with-dependencies.jarModify the file name.
mv client-adapter.es7x-1.1.5-SNAPSHOT-jar-with-dependencies.jar client-adapter.es7x-1.1.5-jar-with-dependencies.jar
Q: What do I do if the following error message is returned in the logs generated for the Canal adapter when I start the adapter: java.sql.SQLException: Unknown system variable 'query_cache_size'?
A: A possible reason is that the version of the MySQL driver in the Canal adapter is inconsistent with the MySQL version of the ApsaraDB RDS for MySQL database that you want to connect. For example, the version of the MySQL driver in the Canal adapter 1.1.4 is 5.1.40. If you use Canal that uses the Canal adapter of this version to connect to an ApsaraDB RDS for MySQL database that runs MySQL 8.x, the error message is returned. Change the MySQL driver in the Canal adapter and make sure that the version of the MySQL driver is consistent with the MySQL version of the ApsaraDB RDS for MySQL database.
Q: I want to synchronize data from an ApsaraDB RDS for MySQL instance that runs MySQL 8.0 to an Elasticsearch cluster. How do I change the existing MySQL driver to the MySQL 8.0 driver?
A: In this example, the root user is used.
Download the package of the MySQL 8.0 driver.
wget https://dev.mysql.com/get/Downloads/Connector-J/mysql-connector-java-8.0.29.zipDecompress the package:
unzip mysql-connector-java-8.0.29.zipCopy the obtained file to the lib directory of the Canal adapter.
mv mysql-connector-java-8.0.29/mysql-connector-java-8.0.29.jar lib/Add permissions.
chmod 777 lib/mysql-connector-java-8.0.29.jar chmod +st lib/mysql-connector-java-8.0.29.jarDelete the MySQL 5.x driver.
rm -rf lib/mysql-connector-java-5.1.40.jar