aliyun-timestream is a plug-in developed by the Alibaba Cloud Elasticsearch team based on the features of time series products that are provided by the Elastic community. This plug-in allows you to use APIs to create, delete, modify, and query time series indexes, and write data to and query data in the indexes. This topic describes how to use the aliyun-timestream plug-in to manage time series data in your Alibaba Cloud Elasticsearch cluster.
Background information
The aliyun-timestream plug-in uses PromQL statements instead of domain-specific language (DSL) statements to query stored metric data. This helps simplify query operations and improve query efficiency. The plug-in also reduces storage costs. For more information, see Overview of aliyun-timestream.This topic describes how to use the aliyun-timestream plug-in. For more information about the related APIs, see Overview of APIs supported by aliyun-timestream and Integrate aliyun-timestream with Prometheus APIs.
Prerequisites
An Elasticsearch cluster of the Standard Edition that meets the following version requirements is created: The version of the cluster is V7.16 or later and the kernel version of the cluster is V1.7.0 or later, or the version of the cluster is V7.10 and the kernel version of the cluster is V1.8.0 or later. For information about how to create an Elasticsearch cluster, see Create an Alibaba Cloud Elasticsearch cluster.
Manage time series indexes
Create a time series index
PUT _time_stream/test_streamAn index that is created by calling the API is different from an index that is created by running the PUT test_stream command. The index that is created by calling the API is a data stream instead of a specific index. The index integrates the configurations of Elasticsearch best practices in time series scenarios.
GET _time_stream/test_stream{
"time_streams" : {
"test_stream" : {
"name" : "test_stream",
"data_stream_name" : "test_stream",
"time_stream_config" : {
"labels_fields" : {
"includes" : [
"labels.*"
],
"excludes" : [ ]
},
"metrics_fields" : {
"includes" : [
"metrics.*"
],
"excludes" : [ ]
},
"label_prefix" : "labels.",
"metric_prefix" : "metrics.",
"downsample" : [ ]
},
"template_name" : ".timestream_test_stream",
"template" : {
"index_patterns" : [
"test_stream"
],
"template" : {
"settings" : {
"index" : {
"mode" : "time_series",
"codec" : "ali",
"refresh_interval" : "10s",
"ali_codec_service" : {
"enabled" : "true",
"source_reuse_doc_values" : {
"enabled" : "true"
}
},
"translog" : {
"durability" : "ASYNC"
},
"doc_value" : {
"compression" : {
"default" : "zstd"
}
},
"postings" : {
"compression" : "zstd"
},
"source" : {
"compression" : "zstd"
},
"routing_path" : [
"labels.*"
]
}
},
"mappings" : {
"numeric_detection" : true,
"dynamic_templates" : [
{
"labels_template_match_labels.*" : {
"path_match" : "labels.*",
"mapping" : {
"time_series_dimension" : "true",
"type" : "keyword"
},
"match_mapping_type" : "*"
}
},
{
"metrics_double_match_metrics.*" : {
"path_match" : "metrics.*",
"mapping" : {
"index" : "false",
"type" : "double"
},
"match_mapping_type" : "double"
}
},
{
"metrics_long_match_metrics.*" : {
"path_match" : "metrics.*",
"mapping" : {
"index" : "false",
"type" : "long"
},
"match_mapping_type" : "long"
}
}
],
"properties" : {
"@timestamp" : {
"format" : "epoch_millis||strict_date_optional_time",
"type" : "date"
}
}
}
},
"composed_of" : [ ],
"data_stream" : {
"hidden" : false
}
},
"version" : 1
}
}
}| Parameter | Description |
| index.mode | The value time_series indicates that the index type is time_series. The system automatically integrates the configurations of Elasticsearch best practices in time series scenarios into the index. |
| index.codec | The value ali indicates that the aliyun-codec index compression plug-in is used. This parameter can be used together with the following parameters to reduce the amount of disk space that is occupied:
|
- Dimension fields: By default, the keyword type is used. The value of time_series_dimension is true for dimension fields. If the value of index.mode is time_series, all fields whose time_series_dimension is true are combined into an internal timeline field named _tsid.
- Metric fields: The double type and long type are supported. Metric fields store only doc values and do not store index data.
- Customize the number of primary shards for an index
PUT _time_stream/test_stream { "template": { "settings": { "index": { "number_of_shards": "2" } } } } - Customize the data model of an index
PUT _time_stream/test_stream { "template": { "settings": { "index": { "number_of_shards": "2" } } }, "time_stream": { "labels_fields": ["labels_*"], "metrics_fields": ["metrics_*"] }
Update a time series index
POST _time_stream/test_stream/_update
{
"template": {
"settings": {
"index": {
"number_of_shards": "4"
}
}
}
}- You must retain the configurations that do not need to be updated when you run the update command. Otherwise, all configurations of the index are updated. We recommend that you run the
GET _time_stream/test_streamcommand to obtain all configurations of the index and modify the required configurations to update the index. - After you update the configurations of a time series index, the new configurations do not immediately take effect on the index. You must roll over the index for the new configurations to take effect. After the rollover, a new index is generated. The new configurations take effect on the new index. You can run the
POST test_stream/_rollovercommand to roll over the index.
Delete a time series index
Delete _time_stream/test_streamUse a time series index
Time series indexes are used in the same way as common indexes.
Write time series data
POST test_stream/_doc
{
"@timestamp": 1630465208722,
"metrics": {
"cpu.idle": 79.67298116109929,
"disk_ioutil": 17.630910821570456,
"mem.free": 75.79973639970004
},
"labels": {
"disk_type": "disk_type2",
"namespace": "namespaces1",
"clusterId": "clusterId3",
"nodeId": "nodeId5"
}
}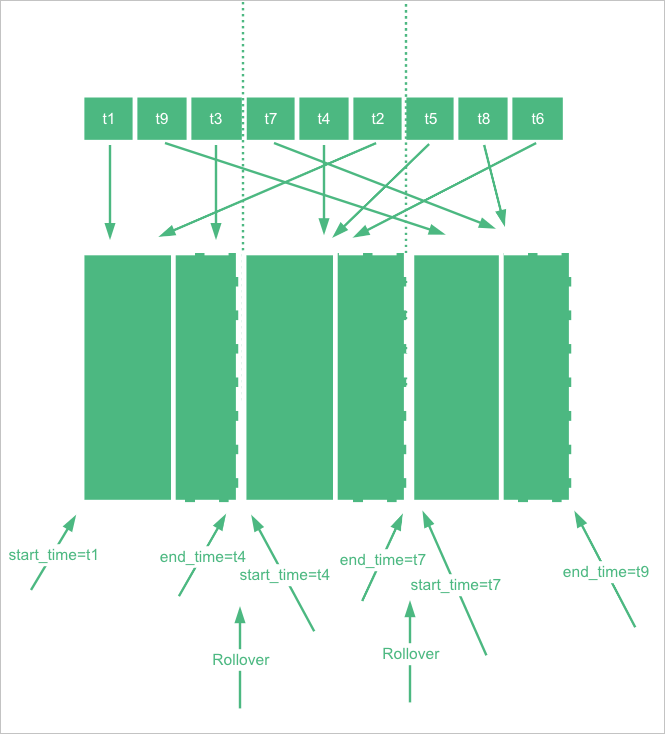
When you write data to an index in a data stream, the data stream determines the index for the data write based on the value of @timestamp. Therefore, in the preceding example, @timestamp must be set to a value that is in the time range of the test_stream index.
The time in a time range is in UTC, such as 2022-06-21T00:00:00.000Z. If your time zone is UTC+8, you must convert the time to time in UTC+8. In this example, the converted time is 2022-06-21T08:00:00.000, which is obtained based on 2022-06-21T00:00:00.000+08:00.
Query time series data
GET test_stream/_searchGET _cat/indices/test_stream?v&s=iQuery the metrics of a time series index
GET _time_stream/test_stream/_stats{
"_shards" : {
"total" : 2,
"successful" : 2,
"failed" : 0
},
"time_stream_count" : 1,
"indices_count" : 1,
"total_store_size_bytes" : 19132,
"time_streams" : [
{
"time_stream" : "test_stream",
"indices_count" : 1,
"store_size_bytes" : 19132,
"tsid_count" : 2
}
]
}Use a Prometheus API to query data
- Configure a data source in the Grafana consoleConfigure a Prometheus data source in the Grafana console and specify the
/_time_stream/prom/test_streamURI in the URL to directly use the time series index as the Prometheus data source of Grafana, as shown in the following figure.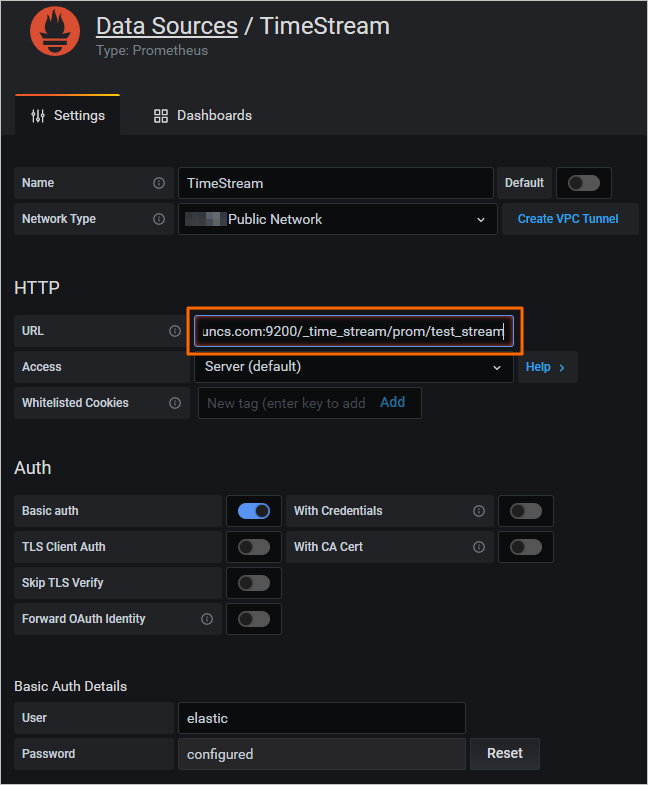
- Configure a data source by calling a Prometheus API
Call a Prometheus API to remove the keyword prefixes and suffixes of metric fields and dimension fields. If you use a Prometheus API to query data that is written based on the default time series data model, the prefix metrics. of metric fields that are returned is not displayed, and the prefix labels. of dimension fields that are returned is not displayed.
If you customize a data model when you create a time series index, you must specify prefixes and suffixes for metric fields and dimension fields. Otherwise, when you use a Prometheus API to query data in the time series index, the actual data is returned. The following code provides an example on how to specify the prefixes and suffixes:PUT _time_stream/{name} { "time_stream": { "labels_fields": "@labels.*_l", "metrics_fields": "@metrics.*_m", "label_prefix": "@labels.", "label_suffix": "_l", "metric_prefix": "@metrics.", "metric_suffix": "_m" } }
Query metadata
- View all metric fields in the test_stream index.
GET /_time_stream/prom/test_stream/metadataIf the command is successfully run, the following result is returned:{ "status" : "success", "data" : { "cpu.idle" : [ { "type" : "gauge", "help" : "", "unit" : "" } ], "disk_ioutil" : [ { "type" : "gauge", "help" : "", "unit" : "" } ], "mem.free" : [ { "type" : "gauge", "help" : "", "unit" : "" } ] } } - View all dimension fields in the test_stream index.
GET /_time_stream/prom/test_stream/labelsIf the command is successfully run, the following result is returned:{ "status" : "success", "data" : [ "__name__", "clusterId", "disk_type", "namespace", "nodeId" ] } - View all values of a specific dimension field in the test_stream index.
GET /_time_stream/prom/test_stream/label/clusterId/valuesIf the command is successfully run, the following result is returned:{ "status" : "success", "data" : [ "clusterId1", "clusterId3" ] } - View all timelines of the cpu.idle metric field in the test_stream index.
GET /_time_stream/prom/test_stream/series?match[]=cpu.idleIf the command is successfully run, the following result is returned:{ "status" : "success", "data" : [ { "__name__" : "cpu.idle", "disk_type" : "disk_type1", "namespace" : "namespaces2", "clusterId" : "clusterId1", "nodeId" : "nodeId2" }, { "__name__" : "cpu.idle", "disk_type" : "disk_type1", "namespace" : "namespaces2", "clusterId" : "clusterId1", "nodeId" : "nodeId5" }, { "__name__" : "cpu.idle", "disk_type" : "disk_type2", "namespace" : "namespaces1", "clusterId" : "clusterId3", "nodeId" : "nodeId5" } ] }
Query data
- Call the Prometheus instant query API to query data
GET /_time_stream/prom/test_stream/query?query=cpu.idle&time=1655769837Note The unit of time is seconds. If you do not configure this parameter, the data within the previous 5 minutes is queried by default.If the command is successfully run, the following result is returned:{ "status" : "success", "data" : { "resultType" : "vector", "result" : [ { "metric" : { "__name__" : "cpu.idle", "clusterId" : "clusterId1", "disk_type" : "disk_type1", "namespace" : "namespaces2", "nodeId" : "nodeId2" }, "value" : [ 1655769837, "79.672981161" ] }, { "metric" : { "__name__" : "cpu.idle", "clusterId" : "clusterId1", "disk_type" : "disk_type1", "namespace" : "namespaces2", "nodeId" : "nodeId5" }, "value" : [ 1655769837, "79.672981161" ] }, { "metric" : { "__name__" : "cpu.idle", "clusterId" : "clusterId3", "disk_type" : "disk_type2", "namespace" : "namespaces1", "nodeId" : "nodeId5" }, "value" : [ 1655769837, "79.672981161" ] } ] } } - Call the Prometheus range query API to query data
GET /_time_stream/prom/test_stream/query_range?query=cpu.idle&start=1655769800&end=16557699860&step=1mIf the command is successfully run, the following result is returned:{ "status" : "success", "data" : { "resultType" : "matrix", "result" : [ { "metric" : { "__name__" : "cpu.idle", "clusterId" : "clusterId1", "disk_type" : "disk_type1", "namespace" : "namespaces2", "nodeId" : "nodeId2" }, "value" : [ [ 1655769860, "79.672981161" ] ] }, { "metric" : { "__name__" : "cpu.idle", "clusterId" : "clusterId1", "disk_type" : "disk_type1", "namespace" : "namespaces2", "nodeId" : "nodeId5" }, "value" : [ [ 1655769860, "79.672981161" ] ] }, { "metric" : { "__name__" : "cpu.idle", "clusterId" : "clusterId3", "disk_type" : "disk_type2", "namespace" : "namespaces1", "nodeId" : "nodeId5" }, "value" : [ [ 1655769860, "79.672981161" ] ] } ] } }
Use the downsampling feature
PUT _time_stream/test_stream
{
"time_stream": {
"downsample": [
{
"interval": "1m"
},
{
"interval": "10m"
},
{
"interval": "60m"
}
]
}
}- Downsampling is performed on an original index to generate a downsampling index. After the original index is rolled over, a new index is generated, and no data is written to the original index within a specific period of time. Then, downsampling is performed on the original index. By default, downsampling starts if the current time is two hours later than the time indicated by end_time of the original index. To simulate this effect, you can manually configure start_time and end_time when you create an index. Important The system changes the value of end_time for the new index to the latest time, which affects the downsampling demonstration. By default, the value is changed at an interval of 5 minutes. In the downsampling demonstration, you must make sure that the value of end_time is not changed. You can view the value of end_time by running the
GET {index}/_settingscommand.PUT _time_stream/test_stream { "template": { "settings": { "index.time_series.start_time": "2022-06-20T00:00:00.000Z", "index.time_series.end_time": "2022-06-21T00:00:00.000Z" } }, "time_stream": { "downsample": [ { "interval": "1m" }, { "interval": "10m" }, { "interval": "60m" } ] } } - Set end_time of the index to a point in time that is two or more hours earlier than the current time, and write data to the index. In addition, set @timestamp to a value that indicates a time between start_time and end_time.
POST test_stream/_doc { "@timestamp": 1655706106000, "metrics": { "cpu.idle": 79.67298116109929, "disk_ioutil": 17.630910821570456, "mem.free": 75.79973639970004 }, "labels": { "disk_type": "disk_type2", "namespace": "namespaces1", "clusterId": "clusterId3", "nodeId": "nodeId5" } } - After data is written to the index, remove start_time and end_time from the index.
POST _time_stream/test_stream/_update { "time_stream": { "downsample": [ { "interval": "1m" }, { "interval": "10m" }, { "interval": "60m" } ] } } - Roll over the index.
POST test_stream/_rollover - After the rollover is complete, run the
GET _cat/indices/test_stream?v&s=icommand to view the downsampling indexes generated by the test_stream index.If the command is successfully run, the following result is returned:health status index uuid pri rep docs.count docs.deleted store.size pri.store.size green open .ds-test_stream-2022.06.21-000001 vhEwKIlwSGO3ax4RKn**** 1 1 9 0 18.5kb 12.1kb green open .ds-test_stream-2022.06.21-000001_interval_10m r9Tsj0v-SyWJDc64oC**** 1 1 1 0 15.8kb 7.9kb green open .ds-test_stream-2022.06.21-000001_interval_1h cKsAlMK-T2-luefNAF**** 1 1 1 0 15.8kb 7.9kb green open .ds-test_stream-2022.06.21-000001_interval_1m L6ocasDFTz-c89KjND**** 1 1 1 0 15.8kb 7.9kb green open .ds-test_stream-2022.06.21-000002 42vlHEFFQrmMAdNdCz**** 1 1 0 0 452b 226b
GET test_stream/_search?size=0&request_cache=false
{
"aggs": {
"1": {
"terms": {
"field": "labels.disk_type",
"size": 10
},
"aggs": {
"2": {
"date_histogram": {
"field": "@timestamp",
"fixed_interval": "120m"
}
}
}
}
}
}{
"took" : 15,
"timed_out" : false,
"_shards" : {
"total" : 2,
"successful" : 2,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"1" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "disk_type2",
"doc_count" : 9,
"2" : {
"buckets" : [
{
"key_as_string" : "2022-06-20T06:00:00.000Z",
"key" : 1655704800000,
"doc_count" : 9
}
]
}
}
]
}
}
}
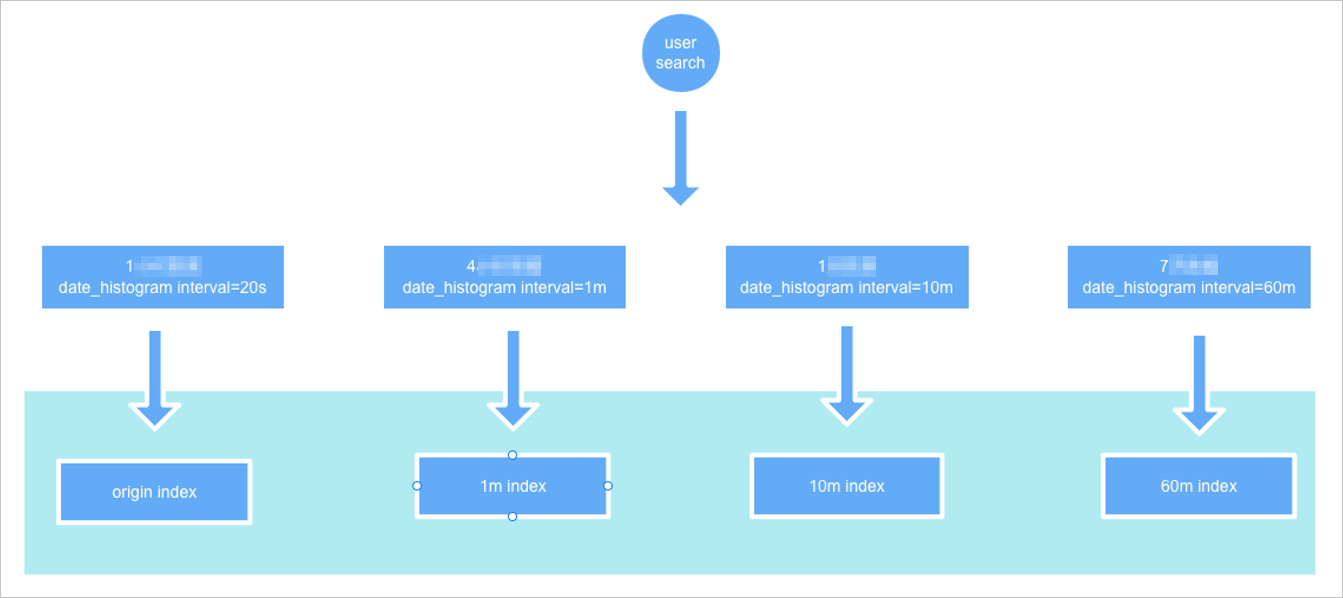
The value of hits.total.value is 1. This indicates that only one data record is hit. The value of doc_count in the aggregations part is 9. This indicates that the number of actual data records is 9. You can determine that the queried index is a downsampling index rather than the original index.
If you change the value of fixed_interval to 20s, the value of hits.total.value is 9, which is the same as the value of doc_count in the aggregations part. This indicates that the queried index is the original index.
The settings and mappings of downsampling indexes are the same as those of the original index, except that data is downsampled based on time ranges.