This topic provides answers to some frequently asked questions about Hive.
Note
- For information about how to troubleshoot issues related to Hive jobs, see Troubleshoot issues related to Hive jobs.
- For information about how to troubleshoot issues related to HiveMetaStore and HiveServer, see Troubleshoot issues related to the Hive service.
- What do I do if jobs are in the waiting state for a long period of time?
- What do I do if small files are read in the map stage?
- What do I do if reduce tasks consume a large amount of time?
- How do I estimate the maximum number of Hive jobs that can be concurrently run?
- Why does an external table created in Hive contain no data?
What do I do if jobs are in the waiting state for a long period of time?
Perform the following steps to identify the issue:
- Go to the Access Links and Ports tab of the E-MapReduce (EMR) console and click the link in the Access URL column that corresponds to YARN UI.
- Click the ID of an application.
- Click the link next to Tracking URL. Multiple jobs are in the waiting state.
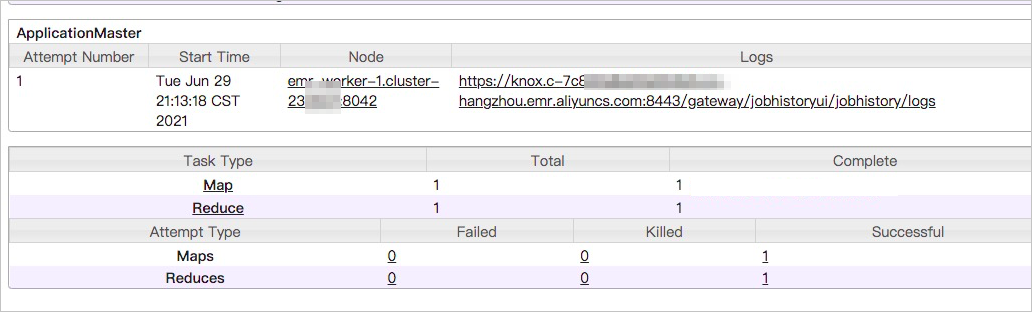
- In the left-side navigation pane, click Scheduler. You can check whether the resources in the queue are fully occupied or whether the current job consumes a large amount of time. If the queue has no sufficient resources, you can switch the jobs that are in the waiting state from the current queue to an idle queue. If the current job consumes a large amount of time, optimize the code.
What do I do if small files are read in the map stage?
Perform the following steps to identify the issue:
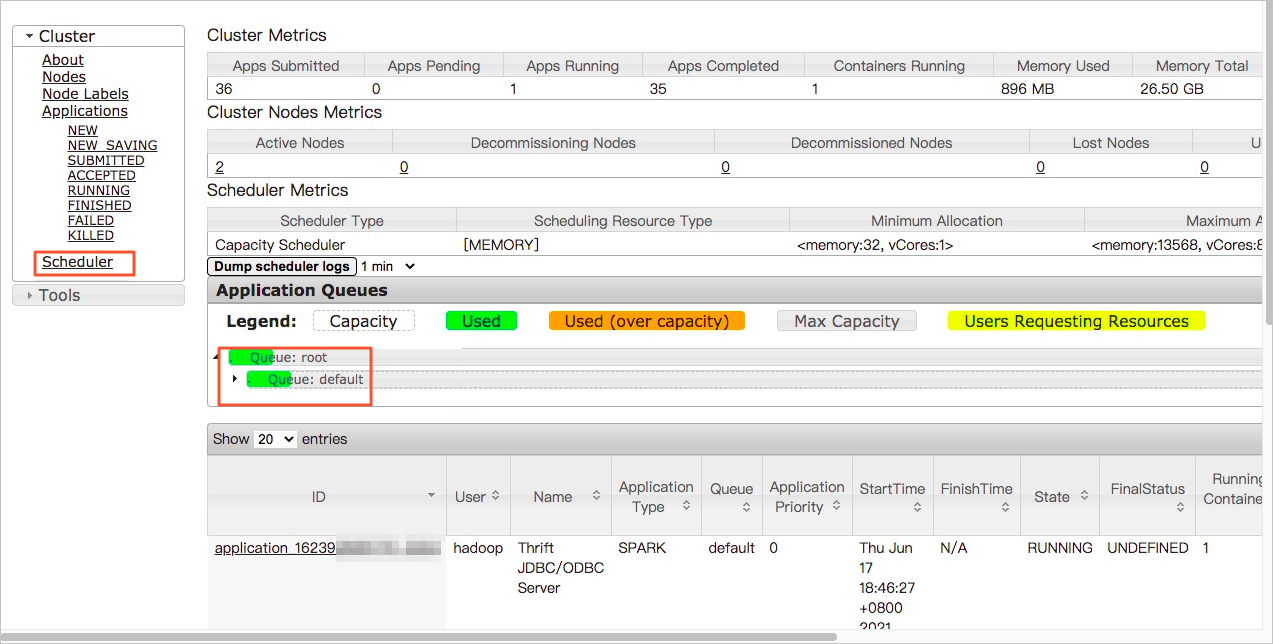
- Go to the Access Links and Ports tab of the EMR console and click the link in the Access URL column that corresponds to YARN UI.
- Click the ID of an application. You can view the size of the data that is read in each map task on the Map tasks page. The size of the data that is read is two bytes, as shown in the following figure. If the size of data in files that are read in most map tasks is small, merge the small files.
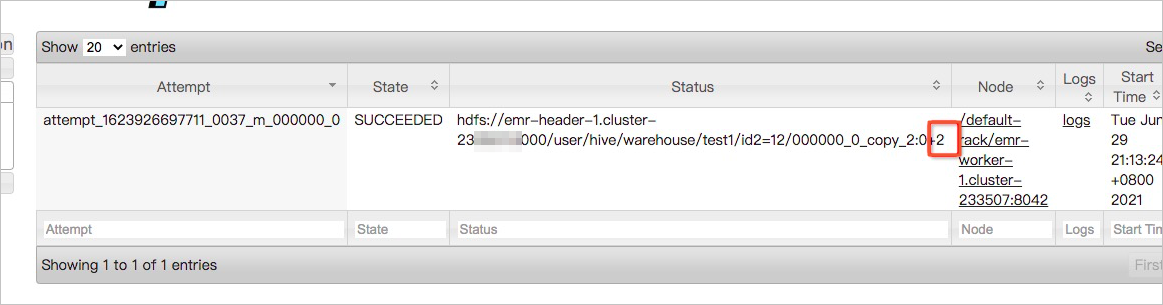
You can also view more information in the log of each map task.
What do I do if reduce tasks consume a large amount of time?
Perform the following steps to identify the issue:
- Go to the Access Links and Ports tab of the EMR console and click the link in the Access URL column that corresponds to YARN UI.
- Click the ID of an application.
- On the Reduce tasks page, sort reduce tasks by completion time in descending order and then find the top reduce tasks that consume the longest time in execution.

- Click the name of a top reduce task.
- In the left-side navigation pane of the task details page, click Counters.
 View the values of the Reduce input records and Reduce shuffle bytes metrics in the current reduce task. If the values of the two metrics are greater than the values of the two metrics in other tasks, a data skew occurs.
View the values of the Reduce input records and Reduce shuffle bytes metrics in the current reduce task. If the values of the two metrics are greater than the values of the two metrics in other tasks, a data skew occurs.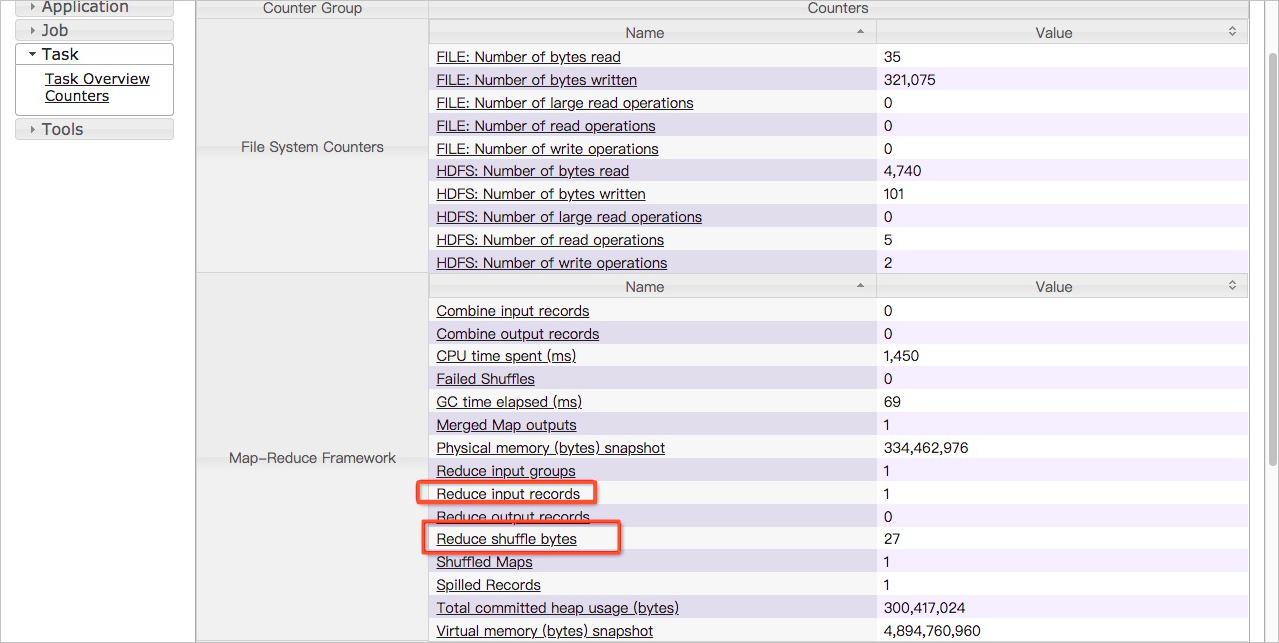
How do I estimate the maximum number of Hive jobs that can be concurrently run?
The maximum number of Hive jobs that can be concurrently run depends on the memory size of HiveServer2 and the number of master nodes. You can use the following formula to estimate the maximum concurrency:
max_num = master_num × max(5, hive_server2_heapsize/512)Parameters in the formula:
- master_num: the number of master nodes in the cluster.
- hive_server2_heapsize: the memory size of HiveServer2, which is specified in the hive-env.sh configuration file. The default size is 512 MB.
Example: If a cluster has three master nodes and the memory size of HiveServer2 is 4 GB, the maximum concurrency is 24. In this case, up to 24 Hive jobs can be concurrently run.
Why does an external table created in Hive contain no data?
- Problem description: After an external table is created, the table is queried but no data is returned. Sample statement that is used to create an external table:
CREATE EXTERNAL TABLE storage_log(content STRING) PARTITIONED BY (ds STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE LOCATION 'oss://log-12453****/your-logs/airtake/pro/storage';Command that is used to query data:select * from storage_log; - Cause: Hive does not automatically associate a Partitions directory.
- Solution:
- Manually specify a Partitions directory:
alter table storage_log add partition(ds=123); - Query data.
select * from storage_log;The following data is returned:OK abcd 123 efgh 123
- Manually specify a Partitions directory: