Apache Airflow is a powerful workflow automation and scheduling tool that allows developers to orchestrate, schedule, and monitor the running of data pipelines. EMR Serverless Spark provides a serverless computing environment for processing large-scale data processing jobs. This topic describes how to use Apache Airflow to enable automatic job submission to EMR Serverless Spark. This approach helps you automate job scheduling and execution to manage data processing jobs more efficiently.
Background
Apache Livy interacts with Spark by calling RESTful APIs. This significantly simplifies the complexity of communication between Spark and the application server. For information about the Livy API, see REST API.
Apache Airflow enables you to use Livy Operator or EmrServerlessSparkStartJobRunOperator to submit jobs to EMR Serverless Spark as needed. You can select a method based on your requirements.
Method | Scenarios |
If you want to use the open-source Operator of Apache Airflow to submit jobs to Serverless Spark, you can select this method. | |
Method 2: Use EmrServerlessSparkStartJobRunOperator to submit a job | EmrServerlessSparkStartJobRunOperator is a dedicated component provided by EMR Serverless Spark for Apache Airflow to submit jobs to EMR Serverless Spark. EmrServerlessSparkStartJobRunOperator is deeply integrated into the Directed Acyclic Graph (DAG) mechanism of Apache Airflow and helps easily orchestrate and schedule jobs. If you use a new project or process data completely based on EMR Serverless Spark, we recommend this method to improve performance and reduce operational complexity. |
Prerequisites
Airflow is installed and started. For more information, see Installation of Airflow.
A workspace is created. For more information, see Create a workspace.
Usage notes
You cannot call the EmrServerlessSparkStartJobRunOperator operation to query job logs. If you want to view job logs, you must go to the EMR Serverless Spark page and find the job run whose logs you want to view by job run ID. Then, you can check and analyze the job logs on the Logs Exploration tab of the job details page or on the Spark Jobs page in the Spark UI.
Method 1: Use Livy Operator to submit a job
Step 1: Create a Livy gateway and a token
Create and start a Livy gateway.
Go to the Gateways page.
Log on to the EMR console.
In the left-side navigation pane, choose .
On the Spark page, click the name of the target workspace.
On the EMR Serverless Spark page, click in the left-side navigation pane.
Click the Livy Gateway tab.
On the Livy Gateway page, click Create Livy Gateway.
On the Create Gateway page, enter a Name (for example, Livy-gateway) and click Create.
You can configure other parameters as needed. For more information, see Manage gateways.
On the Livy Gateway page, find the created gateway and click Start in the Actions column.
Create a token.
On the Gateway page, find the Livy-gateway and click Tokens in the Actions column.
Click Create Token.
In the Create Token dialog box, enter a Name (for example, Livy-token) and click OK.
Copy the token.
ImportantAfter the token is created, you must immediately copy the token. You can no longer view the token after you leave the page. If the token expires or is lost, reset the token or create a new token.
Step 2: Configure Apache Airflow
Run the following command to install Apache Livy in Apache Airflow:
pip install apache-airflow-providers-apache-livyAdd a connection.
Use the UI
Find the default connection named livy_default in Apache Airflow and modify the connection. Alternatively, you can manually add a connection on the web UI of Apache Airflow. For more information, see Creating a Connection with the UI.
This includes the following information:
Host: Enter the Endpoint of the gateway.
Schema: Enter https.
Extra: Enter a JSON string.
x-acs-spark-livy-tokenindicates the token that you copied in the previous step.{ "x-acs-spark-livy-token": "6ac**********kfu" }
Use the CLI
Use the Airflow command-line interface (CLI) to run a command to add a connection. For more information, see Creating a Connection.
airflow connections add 'livy_default' \ --conn-json '{ "conn_type": "livy", "host": "pre-emr-spark-livy-gateway-cn-hangzhou.data.aliyun.com/api/v1/workspace/w-xxxxxxx/livycompute/lc-xxxxxxx", # The endpoint of the gateway. "schema": "https", "extra": { "x-acs-spark-livy-token": "6ac**********kfu" # The token that you copied in the previous step. } }'
Step 3: Configure a DAG and submit a job
Apache Airflow lets you use Directed Acyclic Graphs (DAGs) to declare the mode for running jobs. The following sample code shows how to use the LivyOperator of Apache Airflow to run a Spark job.
Run the Python script file obtained from Object Storage Service (OSS).
from datetime import timedelta, datetime
from airflow import DAG
from airflow.providers.apache.livy.operators.livy import LivyOperator
default_args = {
'owner': 'aliyun',
'depends_on_past': False,
'email_on_failure': False,
'email_on_retry': False,
'retries': 1,
'retry_delay': timedelta(minutes=5),
}
# Initiate DAG
livy_operator_sparkpi_dag = DAG(
dag_id="livy_operator_sparkpi_dag", # The unique ID of the DAG.
default_args=default_args,
schedule_interval=None,
start_date=datetime(2024, 5, 20),
tags=['example', 'spark', 'livy'],
catchup=False
)
# define livy task with LivyOperator
# Replace the value of file as needed.
livy_sparkpi_submit_task = LivyOperator(
file="oss://<YourBucket>/jars/spark-examples_2.12-3.3.1.jar",
class_name="org.apache.spark.examples.SparkPi",
args=['1000'],
driver_memory="1g",
driver_cores=1,
executor_memory="1g",
executor_cores=2,
num_executors=1,
name="LivyOperator SparkPi",
task_id="livy_sparkpi_submit_task",
dag=livy_operator_sparkpi_dag,
)
livy_sparkpi_submit_task
The following table describes the parameters:
Parameter | Description |
| The unique ID of the DAG. You can use the IDs to distinguish different DAGs. |
| The scheduling interval at which the DAG is scheduled. |
| The date on which the DAG starts to be scheduled. |
| The tags added to the DAG. This helps you categorize and search for DAGs. |
| Specifies whether to run the historical jobs that are not run. If this parameter is set to |
| The file path that corresponds to the Spark job. In this example, this parameter is set to the path of the JAR package that is uploaded to OSS. You can configure this parameter as needed. For information about how to upload a file to OSS, see Simple upload. |
| The main class name in the JAR package. |
| The command-line arguments of the Spark job. |
| The memory size and number of cores for the driver. |
| The memory size and number of cores for each executor. |
| The number of executors. |
| The name of the Spark job. |
| The unique identifier of the Airflow task. |
| Associates the task with the DAG. |
Method 2: Use EmrServerlessSparkStartJobRunOperator to submit a job
Step 1: Configure Apache Airflow
Install the airflow-alibaba-provider plug-in on each node of Airflow.
The airflow-alibaba-provider plug-in is provided by EMR Serverless Spark. It contains the EmrServerlessSparkStartJobRunOperator component, which is used to submit jobs to EMR Serverless Spark.
pip install airflow_alibaba_provider-0.0.3-py3-none-any.whlAdd a connection.
Use the CLI
Use the Airflow CLI to run commands to establish a connection. For more information, see Creating a Connection.
airflow connections add 'emr-serverless-spark-id' \ --conn-json '{ "conn_type": "emr_serverless_spark", "extra": { "auth_type": "AK", # The AccessKey pair is used for authentication. "access_key_id": "<yourAccesskeyId>", # The AccessKey ID of your Alibaba Cloud account. "access_key_secret": "<yourAccesskeyKey>", # The AccessKey secret of your Alibaba Cloud account. "region": "<yourRegion>" } }'Use the UI
You can manually create a connection on the Airflow web UI. For more information, see Creating a Connection with the UI.
On the Add Connection page, configure the parameters.
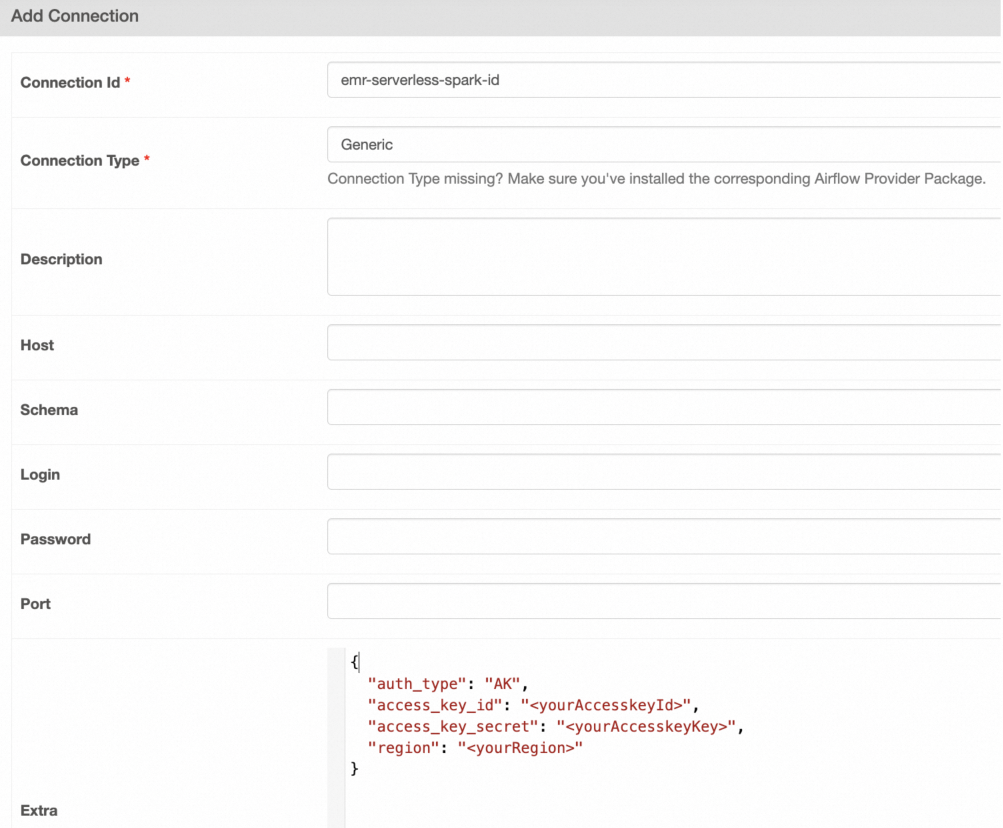
The following table describes the parameters:
Parameter
Description
Connection Id
The connection ID. In this example, enter emr-serverless-spark-id.
Connection Type
The connection type. In this example, select Generic. If Generic is not available, you can also select Email.
Extra
The additional configuration. In this example, enter the following content:
{ "auth_type": "AK", # The AccessKey pair is used for authentication. "access_key_id": "<yourAccesskeyId>", # The AccessKey ID of your Alibaba Cloud account. "access_key_secret": "<yourAccesskeyKey>", # The AccessKey secret of your Alibaba Cloud account. "region": "<yourRegion>" }
Step 2: Configure DAGs
Apache Airflow lets you use Directed Acyclic Graphs (DAGs) to declare the mode for running jobs. The following sample code provides an example on how to use EmrServerlessSparkStartJobRunOperator to run different types of Spark jobs in Apache Airflow.
Submit a JAR package
Use an Airflow task to submit a precompiled Spark JAR job to EMR Serverless Spark.
from __future__ import annotations
from datetime import datetime
from airflow.models.dag import DAG
from airflow_alibaba_provider.alibaba.cloud.operators.emr import EmrServerlessSparkStartJobRunOperator
# Ignore missing args provided by default_args
# mypy: disable-error-code="call-arg"
DAG_ID = "emr_spark_jar"
with DAG(
dag_id=DAG_ID,
start_date=datetime(2024, 5, 1),
default_args={},
max_active_runs=1,
catchup=False,
) as dag:
emr_spark_jar = EmrServerlessSparkStartJobRunOperator(
task_id="emr_spark_jar",
emr_serverless_spark_conn_id="emr-serverless-spark-id",
region="cn-hangzhou",
polling_interval=5,
workspace_id="w-7e2f1750c6b3****",
resource_queue_id="root_queue",
code_type="JAR",
name="airflow-emr-spark-jar",
entry_point="oss://<YourBucket>/spark-resource/examples/jars/spark-examples_2.12-3.3.1.jar",
entry_point_args=["1"],
spark_submit_parameters="--class org.apache.spark.examples.SparkPi --conf spark.executor.cores=4 --conf spark.executor.memory=20g --conf spark.driver.cores=4 --conf spark.driver.memory=8g --conf spark.executor.instances=1",
is_prod=True,
engine_release_version=None
)
emr_spark_jar
Submit an SQL file
Run SQL commands in Airflow DAGs.
from __future__ import annotations
from datetime import datetime
from airflow.models.dag import DAG
from airflow_alibaba_provider.alibaba.cloud.operators.emr import EmrServerlessSparkStartJobRunOperator
# Ignore missing args provided by default_args
# mypy: disable-error-code="call-arg"
ENV_ID = os.environ.get("SYSTEM_TESTS_ENV_ID")
DAG_ID = "emr_spark_sql"
with DAG(
dag_id=DAG_ID,
start_date=datetime(2024, 5, 1),
default_args={},
max_active_runs=1,
catchup=False,
) as dag:
emr_spark_sql = EmrServerlessSparkStartJobRunOperator(
task_id="emr_spark_sql",
emr_serverless_spark_conn_id="emr-serverless-spark-id",
region="cn-hangzhou",
polling_interval=5,
workspace_id="w-7e2f1750c6b3****",
resource_queue_id="root_queue",
code_type="SQL",
name="airflow-emr-spark-sql",
entry_point=None,
entry_point_args=["-e","show tables;show tables;"],
spark_submit_parameters="--class org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver --conf spark.executor.cores=4 --conf spark.executor.memory=20g --conf spark.driver.cores=4 --conf spark.driver.memory=8g --conf spark.executor.instances=1",
is_prod=True,
engine_release_version=None,
)
emr_spark_sql
Submit an SQL file from OSS
Run the SQL script file obtained from OSS.
from __future__ import annotations
from datetime import datetime
from airflow.models.dag import DAG
from airflow_alibaba_provider.alibaba.cloud.operators.emr import EmrServerlessSparkStartJobRunOperator
# Ignore missing args provided by default_args
# mypy: disable-error-code="call-arg"
DAG_ID = "emr_spark_sql_2"
with DAG(
dag_id=DAG_ID,
start_date=datetime(2024, 5, 1),
default_args={},
max_active_runs=1,
catchup=False,
) as dag:
emr_spark_sql_2 = EmrServerlessSparkStartJobRunOperator(
task_id="emr_spark_sql_2",
emr_serverless_spark_conn_id="emr-serverless-spark-id",
region="cn-hangzhou",
polling_interval=5,
workspace_id="w-ae42e9c92927****",
resource_queue_id="root_queue",
code_type="SQL",
name="airflow-emr-spark-sql-2",
entry_point="",
entry_point_args=["-f", "oss://<YourBucket>/spark-resource/examples/sql/show_db.sql"],
spark_submit_parameters="--class org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver --conf spark.executor.cores=4 --conf spark.executor.memory=20g --conf spark.driver.cores=4 --conf spark.driver.memory=8g --conf spark.executor.instances=1",
is_prod=True,
engine_release_version=None
)
emr_spark_sql_2
Submit a Python script from OSS
Run the Python script file obtained from OSS.
from __future__ import annotations
from datetime import datetime
from airflow.models.dag import DAG
from airflow_alibaba_provider.alibaba.cloud.operators.emr import EmrServerlessSparkStartJobRunOperator
# Ignore missing args provided by default_args
# mypy: disable-error-code="call-arg"
DAG_ID = "emr_spark_python"
with DAG(
dag_id=DAG_ID,
start_date=datetime(2024, 5, 1),
default_args={},
max_active_runs=1,
catchup=False,
) as dag:
emr_spark_python = EmrServerlessSparkStartJobRunOperator(
task_id="emr_spark_python",
emr_serverless_spark_conn_id="emr-serverless-spark-id",
region="cn-hangzhou",
polling_interval=5,
workspace_id="w-ae42e9c92927****",
resource_queue_id="root_queue",
code_type="PYTHON",
name="airflow-emr-spark-python",
entry_point="oss://<YourBucket>/spark-resource/examples/src/main/python/pi.py",
entry_point_args=["1"],
spark_submit_parameters="--conf spark.executor.cores=4 --conf spark.executor.memory=20g --conf spark.driver.cores=4 --conf spark.driver.memory=8g --conf spark.executor.instances=1",
is_prod=True,
engine_release_version=None
)
emr_spark_python
The following table describes the parameters:
Parameter | Type | Description |
|
| The unique identifier of the Airflow task. |
|
| The ID of the connection between Airflow and EMR Serverless Spark. |
|
| The region in which the EMR Spark job is created. |
|
| The interval at which Airflow queries the state of the job. Unit: seconds. |
|
| The unique identifier of the workspace to which the EMR Spark job belongs. |
|
| The ID of the resource queue used by the EMR Spark job. |
|
| The job type. SQL, Python, and JAR jobs are supported. The meaning of the entry_point parameter varies based on the job type. |
|
| The name of the EMR Spark job. |
|
| The location of the file that is used to start the job. JAR, SQL, and Python files are supported. The meaning of this parameter varies based on |
|
| The parameters that are passed to the Spark application. |
|
| The additional parameters used for the |
|
| The environment in which the job runs. If this parameter is set to True, the job runs in the production environment. In this case, the |
|
| The version of the EMR Spark engine. Default value: esr-2.1-native, which indicates an engine that runs Spark 3.3.1 and Scala 2.12 in the native runtime. |