This topic describes YARN schedulers.
Overview
ResourceManager is the core component of Hadoop YARN. You can use the ResourceManager component to manage and schedule cluster resources. Schedulers are the core of the ResourceManager component. You can use schedulers to manage cluster resources and allocate resources to applications. Schedulers optimize the resource layout of clusters to maximize the use of cluster resources and to prevent issues such as hotspot issues from affecting applications. Schedulers also coordinate diverse applications that run on a cluster and resolve resource competition issues based on policies such as multi-tenant fairness and application priority. Schedulers can meet the requirements of specific applications in terms of node dependency and placement policies.
YARN schedulers are pluggable plug-ins. YARN provides the following types of schedulers: First-In-First-Out (FIFO) Scheduler, Fair Scheduler and Capacity Scheduler.
FIFO Scheduler is the simplest scheduler. It does not allow applications to be submitted to multiple tenants for scheduling. This indicates that all applications are submitted to the default queue for scheduling without cluster resource allocation. In this case, applications are scheduled based on the FIFO policy without other control and scheduling configurations. FIFO Scheduler is suitable only for simple scenarios and is rarely used in production environments.
Fair Scheduler is the default scheduler that is used by Cloudera Distributed Hadoop (CDH). After CDH is merged with Hortonworks Data Platform (HDP), Cloudera Data Platform (CDP) comes into being and uses Capacity Scheduler instead of Fair Scheduler. If you use Apache Hadoop, Capacity Scheduler is also recommended. Fair Scheduler provides the multi-tenant management and resource scheduling capabilities. The capabilities include multi-level queue management, quota management, access control list (ACL)-based control, resource sharing, fair scheduling among tenants, application scheduling within tenants, resource reservation and preemption, and asynchronous scheduling. However, the development of Fair Scheduler is not as up-to-date as the development of Capacity Scheduler in Apache Hadoop. Fair Scheduler does not consider the resource layout of clusters and does not support scheduling features such as node labels, node attributes, and placement constraints.
Capacity Scheduler is the default scheduler that is used by Apache Hadoop, HDP, and CDP. Capacity Scheduler provides complete multi-tenant management and resource scheduling capabilities, which include all capabilities of Fair Scheduler. Capacity Scheduler can optimize the resource layout of clusters based on global scheduling, reduce the risk of hotspot issues, and maximize the use of cluster resources. Capacity Scheduler also supports scheduling features such as node labels, node attributes, and placement constraints.
We recommend that you use Capacity Scheduler for E-MapReduce (EMR) YARN. The following sections describe Capacity Scheduler in detail. For more information about other schedulers, see the documentation provided by Apache Hadoop YARN.
Architecture and core process
MainScheduler of Capacity Scheduler can be triggered by using one of the following methods:
Node heartbeat-driven: When a capacity scheduler receives the heartbeat of a node, MainScheduler is triggered to select an application that can be scheduled for the node. This type of scheduling is local scheduling of nodes. MainScheduler is subject to heartbeat intervals and is similar to random scheduling. As a result, a large number of nodes may not be hit because of insufficient resources and unmet scheduling requirements. This causes low scheduling efficiency. This method is suitable for clusters that do not have high requirements on scheduling performance and scheduling features.
Asynchronous scheduling: MainScheduler is triggered by an asynchronous thread or multiple parallel threads. A random node is selected from the node list for scheduling. This improves the scheduling performance. This method is suitable for clusters that have high requirements on scheduling performance but low requirements on scheduling features.
Global scheduling: MainScheduler is triggered by a global thread. This type of scheduling is global scheduling of applications. Applications are selected for scheduling based on factors such as multi-tenant fairness and application priority. Then, nodes are selected for scheduling based on factors such as the resource size, scheduling requirements, and resource distribution of the applications. This way, optimal scheduling decisions can be made. This method is suitable for clusters that have high requirements on scheduling performance and scheduling features.
The following figure shows the architecture of global scheduling based on YARN 3.2 or later.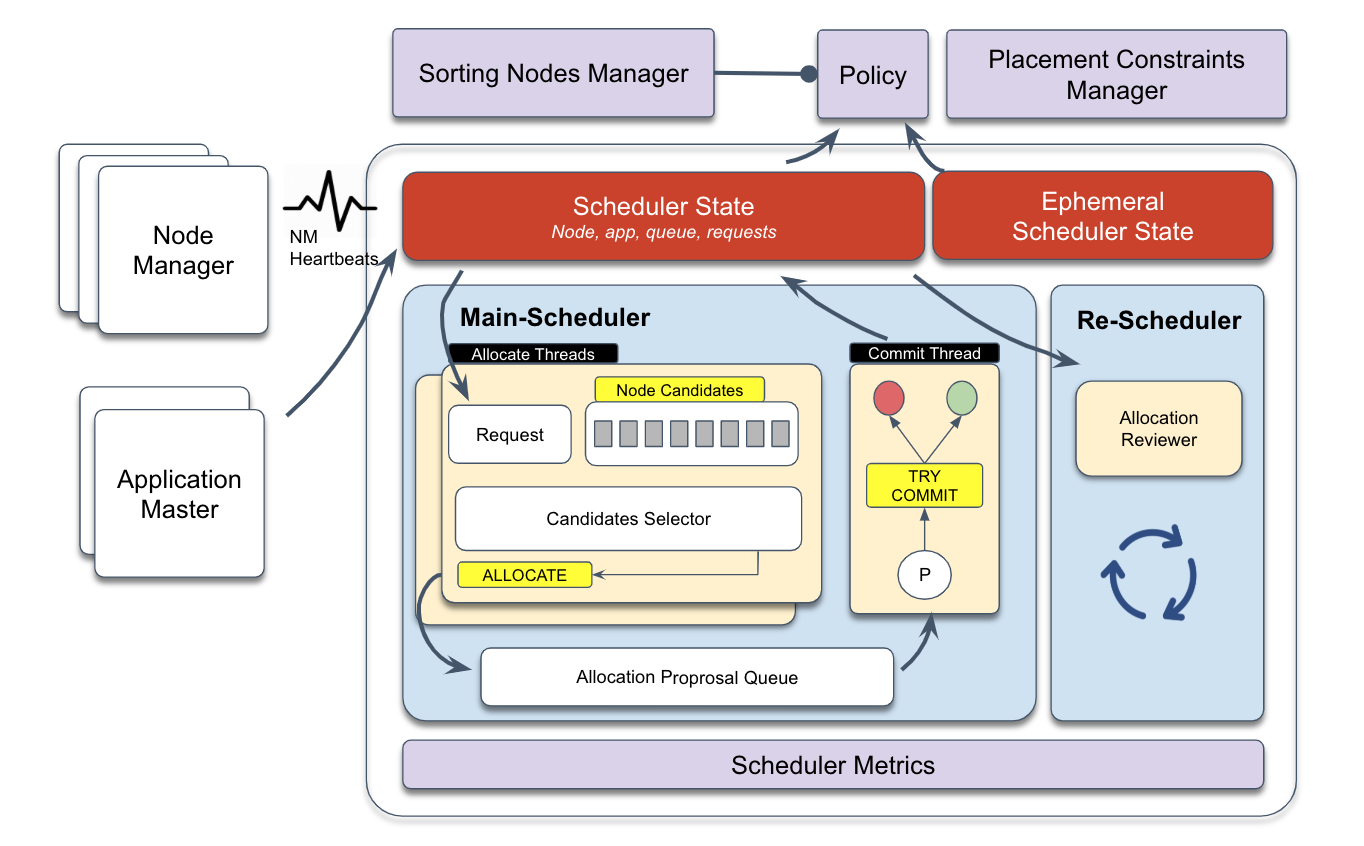
MainScheduler is an asynchronous multithreading processing framework based on resource requests. MainScheduler contains allocation and submission threads. One or more allocation threads are used to locate the resource request that has the highest priority, select appropriate candidate nodes based on the resource size and placement constraints, generate allocation proposals, and arrange the allocation proposals in the intermediate queue. A submission thread is used to consume the allocation proposals, recheck various placement constraints, and then submit or reject the allocation proposals. The submission thread can also be used to update the status of a capacity scheduler.
ReScheduler is a dynamic resource monitoring framework that periodically runs. ReScheduler contains multiple resource monitoring policies, such as policies that are related to inter-queue preemption, intra-queue preemption, and reserved resource preemption.
Node Sorting Manager and Placement Constraint Manager are global scheduling plug-ins of MainScheduler. The plug-ins are used for load balancing and management of complex placement constraints.
The following figure shows the global scheduling process of Capacity Scheduler.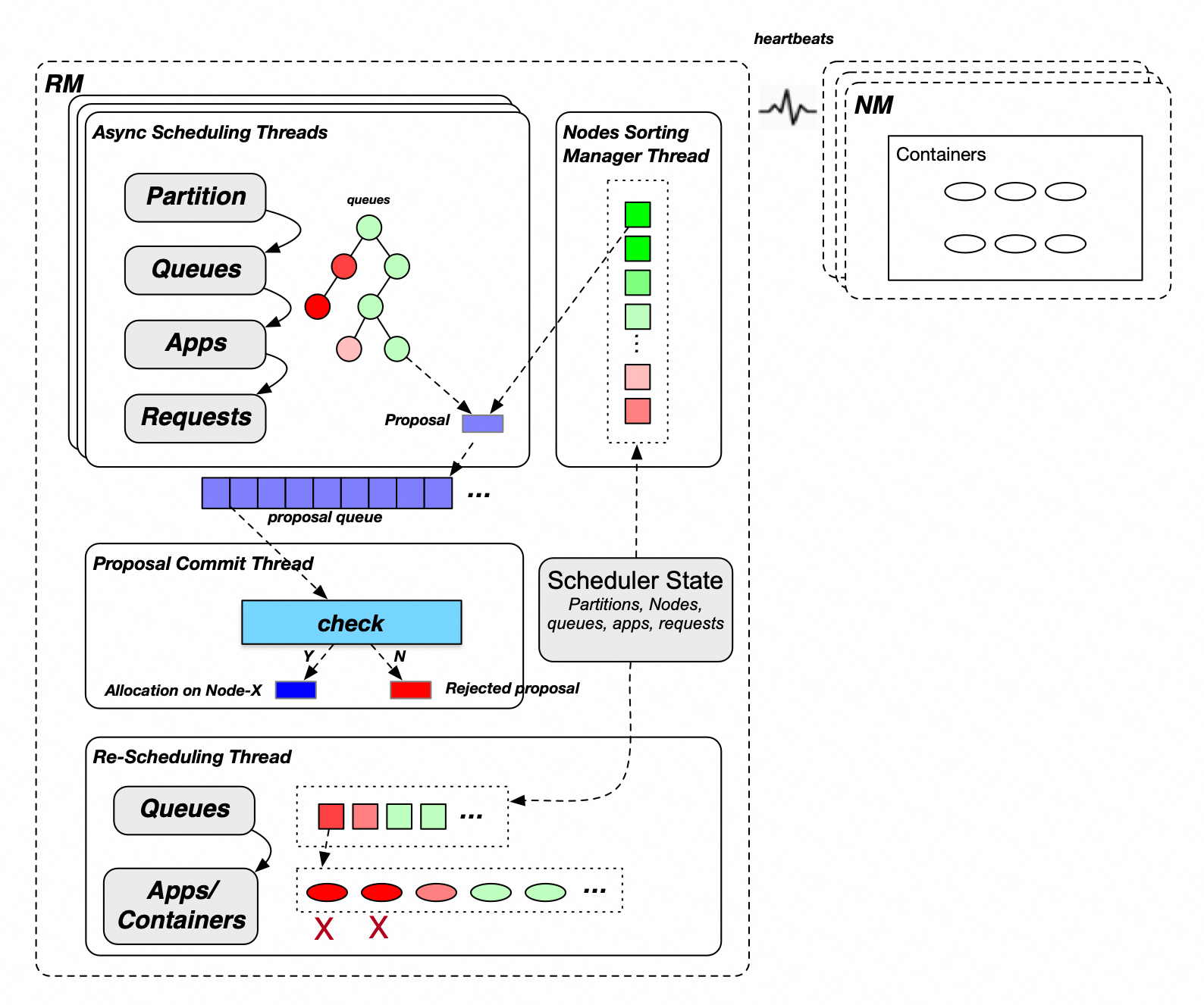
Container allocation process of MainScheduler:
Select partitions (node labels). A cluster may have one or more partitions. MainScheduler allocates containers to partitions in turn.
Select leaf queues. MainScheduler traverses queues from the root queue. Child queues at the same level are traversed in ascending order of the percentage of guaranteed resources that are allocated to queues until the leaf queues are found. In the preceding figure, a red queue indicates that the resource usage is high, and a green queue indicates that the resource usage is low. Resources are preferentially allocated to green queues.
Select applications. MainScheduler selects applications within a queue based on the fair or FIFO policy. If the fair policy is used, applications are selected in the ascending order of the amount of memory resources that are allocated to the applications. If the FIFO policy is used, applications are selected in the descending order of priority and ascending order of application IDs.
Select requests. MainScheduler selects requests based on the priority.
Select sorted candidate nodes. MainScheduler searches for the candidate nodes that meet specific resource requirements from all sorted nodes based on the request placement constraints.
Traverse the candidate nodes and allocate a container to each candidate node. During the allocation process, MainScheduler checks the allocated, used, or unconfirmed resources of a queue or a node. After the check passes, an allocation proposal is generated and put into the proposal queue.
Container submission process of MainScheduler: A submission thread checks the allocation proposal in the proposal queue. In this case, the submission thread checks whether the requirements on applications, nodes, and placement constraints are met. If requirements are not met, the allocation proposal is discarded. If the requirements are met, the allocated container takes effect, and the resources of applications or nodes are updated.
Resource preemption process of ReScheduler: If the total amount of available resources of a cluster is less than a specific resource threshold and the resources that are allocated to specific applications are insufficient, ReScheduler may trigger resource preemption by using different methods.
Inter-queue preemption: YARN allows unused guaranteed resources of a queue to be shared by other queues. When an application in the queue whose guaranteed resources are not sufficient requires more resources, but the cluster has no idle resources, inter-queue preemption is triggered. The resources within the queue capacity are guaranteed resources, and the resources that exceed the queue capacity but are less than the maximum queue capacity are shared resources.
Intra-queue preemption: ReScheduler monitors and adjusts the resources of applications based on the FIFO or fair policy of queues. When applications that have a high priority require resources but the resources that are allocated to the queue are exhausted, intra-queue preemption is triggered.
Reserved resource preemption: When a task meets specific conditions, the task and the resources that are reserved for the task are released. For example, if resources are not allocated to a task within the timeout period, the task and resources that are reserved for the task are released.
Features
Capacity Scheduler provides the following features:
Multi-level queue management: Capacity Scheduler allows you to manage multiple levels of queues in multiple tenants. The resource quota of a parent queue limits the resource usage of all its child queues, and the resource quota of a single child queue cannot exceed the resource quota of the parent queue. This ensures controllable multi-tenant management and meets the requirements of various complex application scenarios.
Resource quota: Capacity Scheduler allows you to configure the resources that are guaranteed for a queue and the maximum amount of resources that can be used by a queue. You can also configure the maximum number of applications that can run on a queue, the maximum number of resources that ApplicationMaster can use, and the ratio of resources that a user uses to the configured resources. This way, you can control queues from multiple dimensions, such as applications, task types, and users.
Elastic resource sharing: The amount of elastic resources in a queue can be calculated by using the following formula: Maximum queue capacity - Queue capacity. When a cluster and the parent queue have idle resources, child queues can use the unused guaranteed resources of other queues. This ensures schedule-based reuse of resources in different queues and improves the resource utilization of the cluster.
ACL-based control: Capacity Scheduler allows you to manage permissions on queues. You can specify multiple users to submit and manage tasks, or specify the same user to manage multiple queues.
Inter-tenant queue scheduling: Queues at the same level are scheduled in the ascending order of the percentage of guaranteed resources of queues. This ensures that queues that require fewer guaranteed resources are scheduled first. If you configure the priorities of queues, queues at the same level are divided into two groups: queues whose used resources are less than or equal to the guaranteed resources and queues whose used resources are greater than the guaranteed resources. Resources are first allocated to the queues whose used resources are less than or equal to the guaranteed resources. Then, all queues in the two groups are sorted in the descending order of priority and in the ascending order of the percentage of guaranteed resources.
Intra-tenant application scheduling: Applications in a tenant are scheduled based on the FIFO or fair policy. If applications are scheduled based on the FIFO policy, all applications in a tenant are scheduled in the descending order of priority and the ascending order of submission time. If applications are scheduled based on the fair policy, all applications in a tenant are scheduled in the ascending order of the percentage of resources that are used by the applications and the ascending order of submission time.
Preemption: The resources of clusters are constantly changing. To meet the requirements of elastic resource sharing, fair intra-tenant queue scheduling, and inter-tenant application scheduling, the preemption process is used to balance the resource usage of queues and applications.
Configurations and usage notes
Global configurations
Configuration file | configuration item | Recommended value | Description |
yarn-site.xml | yarn.resourcemanager.scheduler.class | Left empty | The scheduler class. Default value: org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler. The default value indicates CapacityScheduler. |
capacity-scheduler.xml | yarn.scheduler.capacity.maximum-applications | Left empty | The maximum number of concurrent applications that can run on a cluster. Default value: 10000. |
yarn.scheduler.capacity.global-queue-max-application | Left empty | The maximum number of concurrent applications that can run on a queue. If you do not configure this parameter, the applications that can concurrently run on a cluster are allocated to queues in proportion. The maximum number of concurrent applications that can run on each queue is calculated by using the following formula: Queue capacity/Cluster resource × ${yarn.scheduler.capacity.maximum-applications}. If multiple queues that have special requirements exist, configure this parameter based on your business requirements. For example, if you want to run a large number of applications on a queue whose capacity is low, you can change the value of this parameter based on your business requirements. | |
yarn.scheduler.capacity.maximum-am-resource-percent | 0.25 | The percentage of the maximum amount of resources that can be used by Application Master (AM) of all applications in the queue. The maximum amount of resources cannot exceed the amount of resources that are calculated by using the following formula: Value of this parameter × Maximum queue capacity. Default value: 0.1. If a queue has a large number of small applications, the proportion of AM containers is high, and the number of applications that can run on the queue is limited. You can increase the value of this parameter based on your business requirements. | |
yarn.scheduler.capacity.resource-calculator | org.apache.hadoop.yarn.util.resource.DominantResourceCalculator | The calculator that is used to compute the compute resources that are required by queues, nodes, and applications. If you set this parameter to the default value org.apache.hadoop.yarn.util.resource.DefaultResourceCalculator, only memory resources that are required by queues, nodes, and applications are computed. You can also set this parameter to org.apache.hadoop.yarn.util.resource.DominantResourceCalculator. This indicates that all types of configured resources, such as memory, CPU, and other resources, are computed. The resources that are used the most are considered as the primary resources. Note The modification to this configuration item takes effect after you restart ResourceManager or perform a switchover between the primary node and the secondary node if HA is enabled. The refresh operation cannot make the modification to the configuration item take effect. | |
yarn.scheduler.capacity.node-locality-delay | -1 | The number of times that a node is delayed for scheduling. The default value is 40. This parameter is used in scenarios in which Hadoop scheduling heavily relies on local storage. This indicates that tasks are allocated to nodes on which the data required by computing resides. With the development of networks and storage, disks and networks are no longer the main bottlenecks. Therefore, you do not need to consider localization issues. We recommend that you set this parameter to -1 to improve the scheduling performance. |
Node configurations
Node heartbeat modes
Configuration file | configuration item | Recommended value | Description |
capacity-scheduler.xml | yarn.scheduler.capacity.per-node-heartbeat.multiple-assignments-enabled | false | Specifies whether to allocate multiple containers in a heartbeat at a time. The default value is true. If you set this parameter to true, the load balancing of clusters is affected, and hotspot issues may occur. We recommend that you do not set this parameter to true. |
yarn.scheduler.capacity.per-node-heartbeat.maximum-container-assignments | Left empty | The maximum number of containers that can be assigned in a heartbeat. Default value: 100. This parameter takes effect only if you set the yarn.scheduler.capacity.per-node-heartbeat.multiple-assignments-enabled parameter to true. | |
yarn.scheduler.capacity.per-node-heartbeat.maximum-offswitch-assignments | Left empty | The maximum number of off-switch containers that can be assigned in a heartbeat. This parameter takes effect only if you set the yarn.scheduler.capacity.per-node-heartbeat.multiple-assignments-enabled parameter to true. |
Asynchronous scheduling
Configuration file | configuration item | Recommended value | Description |
capacity-scheduler.xml | yarn.scheduler.capacity.schedule-asynchronously.enable | true | Specifies whether to enable asynchronous scheduling. The default value is false. We recommend that you set this parameter to true to improve the scheduling performance. |
yarn.scheduler.capacity.schedule-asynchronously.maximum-threads | 1 or left empty | The maximum number of threads that can be allocated for asynchronous scheduling. The default value is 1. Multiple threads may generate a large number of duplicate proposals. In most cases, the scheduling performance is high when a single thread is allocated. We recommend that you do not configure this parameter. | |
yarn.scheduler.capacity.schedule-asynchronously.maximum-pending-backlogs | Left empty | The maximum number of allocation proposals to be submitted in a queue for asynchronous scheduling. The default value is 100. If the cluster size is large, you can increase the value of this parameter based on your business requirements. |
Global scheduling
All configuration items related to asynchronous scheduling are required for global scheduling and are not provided in the following table.
Configuration file | Configuration item | Recommended value | Description |
capacity-scheduler.xml | yarn.scheduler.capacity.multi-node-placement-enabled | true | Specifies whether to enable global scheduling. The default value is false. You can enable global scheduling for clusters that have high requirements on scheduling performance and scheduling features. |
yarn.scheduler.capacity.multi-node-sorting.policy | default | The name of the default global scheduling policy. | |
yarn.scheduler.capacity.multi-node-sorting.policy.names | default | The names of the global scheduling policies. Separate multiple names with commas (,). | |
yarn.scheduler.capacity.multi-node-sorting.policy.default.class | org.apache.hadoop.yarn.server.resourcemanager.scheduler.placement.ResourceUsageMultiNodeLookupPolicy | The unique implementation class of the default global scheduling policy that is used to sort nodes in the ascending order of the absolute values of the resources allocated to the nodes. | |
yarn.scheduler.capacity.multi-node-sorting.policy.default.sorting-interval.ms |
| The interval at which the cache is refreshed based on the default global scheduling policy. You can determine whether to enable node caching based on the cluster size:
Default value: 1000. The value of this configuration item must be greater than or equal to 0. The value 0 indicates that synchronous sorting is implemented. For large-scale clusters, synchronous sorting has a great impact on performance.) |
Node partition configurations
For more information, see Node labels.
Basic queue configurations
Basic queue configurations include the configurations of the following items: hierarchical relationships of queues, capacity of queues, and the maximum capacity of queues. If a YARN cluster is shared by multiple departments and teams of an enterprise, you can organize YARN queues based on a specific organization mode and expected percentage of resources. The parent queue root has four child queues, as shown in the following figure: dev, test, support, and default. The percentages of guaranteed resources for the queues are 50%, 30%, 10%, and 10%, and the percentages of the maximum amount of resources for the queues are 100%, 50%, 30%, and 100%. The dev queue has two child queues: training and services. The percentages of guaranteed resources for the child queues are 40% and 60%, and the percentages of the maximum amount of resources for the child queues are both 100%.

The following table describes the basic configurations of queues.
Configuration file | Configuration item | Sample value | Description |
capacity-scheduler.xml | yarn.scheduler.capacity.root.queues | dev,test,support,default | The child queues of the root queue. Separate multiple queues with commas (,). |
yarn.scheduler.capacity.root.dev.capacity | 50 | The percentage of guaranteed resources for the dev queue to the cluster resources. | |
yarn.scheduler.capacity.root.dev.maximum-capacity | 100 | The percentage of the maximum amount of resources for the dev queue to the cluster resources. | |
yarn.scheduler.capacity.root.dev.queues | training,services | The child queues of the dev queue. | |
yarn.scheduler.capacity.root.dev.training.capacity | 40 | The percentage of guaranteed resources for the training queue to the guaranteed resources for the dev queue. | |
yarn.scheduler.capacity.root.dev.training.maximum-capacity | 100 | The percentage of the maximum amount of resources for the training queue to the maximum amount of resources for the dev queue. | |
yarn.scheduler.capacity.root.dev.services.capacity | 60 | The percentage of guaranteed resources for the services queue to the guaranteed resources for the dev queue. | |
yarn.scheduler.capacity.root.dev.services.maximum-capacity | 100 | The percentage of the maximum amount of resources for the services queue to the maximum amount of resources for the dev queue. | |
yarn.scheduler.capacity.root.test.capacity | 30 | The percentage of guaranteed resources for the test queue to the cluster resources. | |
yarn.scheduler.capacity.root.test.maximum-capacity | 50 | The percentage of the maximum amount of resources for the test queue to the cluster resources. | |
yarn.scheduler.capacity.root.support.capacity | 10 | The percentage of guaranteed resources for the support queue to the cluster resources. | |
yarn.scheduler.capacity.root.support.maximum-capacity | 30 | The percentage of the maximum amount of resources for the support queue to the cluster resources. | |
yarn.scheduler.capacity.root.default.capacity | 10 | The percentage of guaranteed resources for the default queue to the cluster resources. | |
yarn.scheduler.capacity.root.default.maximum-capacity | 100 | The percentage of the maximum amount of resources for the default queue to the cluster resources. |
The list on the YARN Scheduler page displays the hierarchy of queues, the percentage of guaranteed resources, and the percentage of the maximum amount of resources for the queues. In the following figure, the solid gray box represents the percentage of the maximum amount of resources of each queue, and the dashed box represents the percentage of guaranteed resources of each queue to the cluster resources. You can expand a queue to view the details of the queue, such as the queue status, resource information, application information, and other configurations, as shown in the following figure.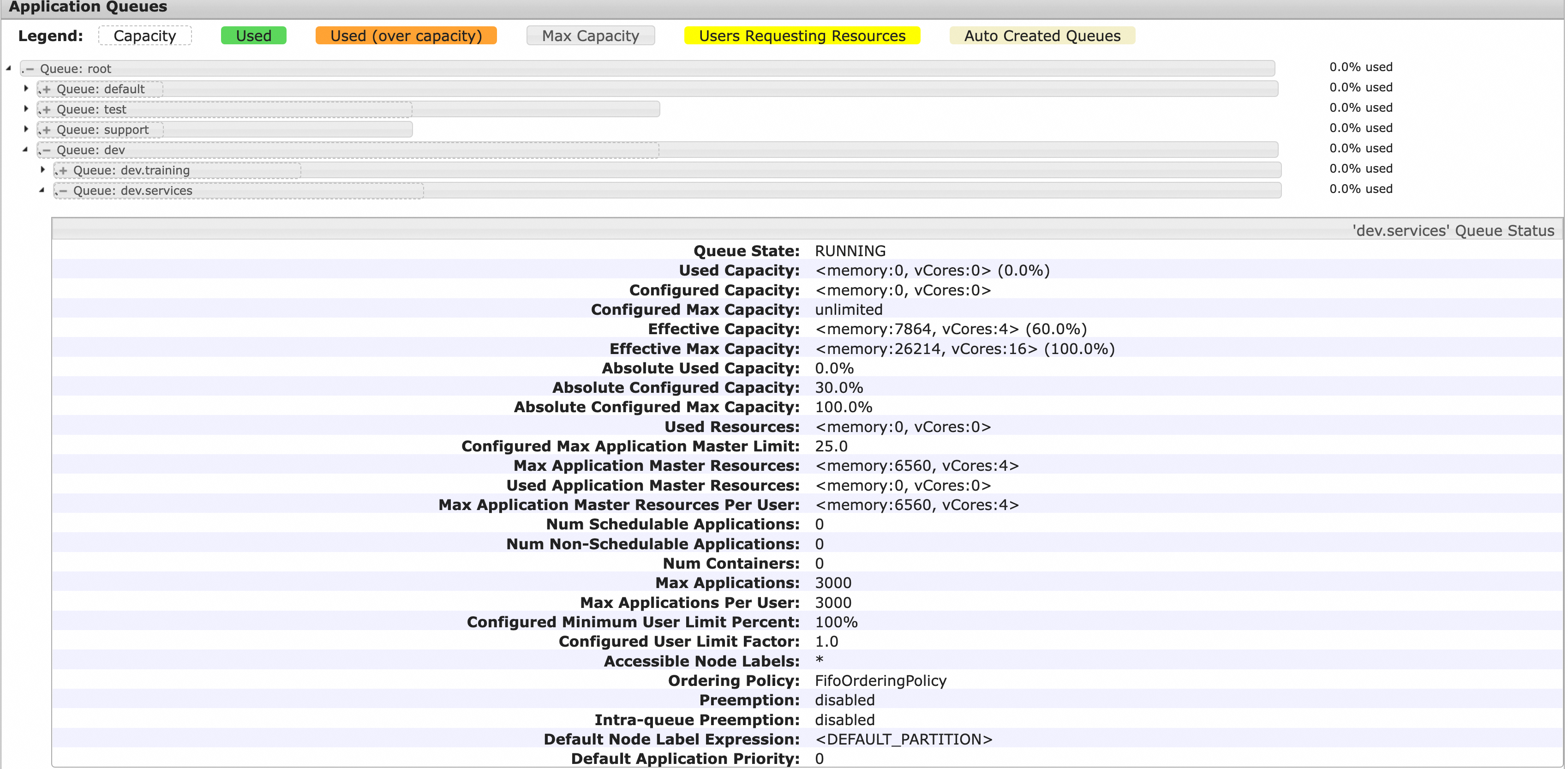
Advanced queue configurations
Configuration file | Configuration item | Recommended value | Description |
capacity-scheduler.xml | yarn.scheduler.capacity.<queue_path>.ordering-policy | fair | Specifies the policy that is used to schedule applications in a queue. Applications in a queue are scheduled based on the FIFO or fair policy. If applications are scheduled based on the FIFO policy, all applications in a queue are scheduled in the descending order of priority and the ascending order of submission time. If applications are scheduled based on the fair policy, all applications in a queue are scheduled in the ascending order of the percentage of resources that are used by the applications and the ascending order of submission time. The default value is fifo. In most cases, we recommend that you set this parameter to fair. |
yarn.scheduler.capacity.<queue-path>.ordering-policy.fair.enable-size-based-weight | Left empty | Specifies whether to enable the weight-based fair scheduling policy. You can determine whether to enable the fair scheduling policy based on the resources that are allocated to applications. The default value is false. The value false indicates that applications are scheduled in the ascending order of the amount of used resources of the applications. The value true indicates that applications are scheduled in the ascending order of the resources that are calculated by using the following formula: Used resources/Required resources. This helps prevent large applications from lacking resources during resource competition. | |
yarn.scheduler.capacity.<queue_path>.state | Left empty | The status of the queue. The default value is RUNNING. In most cases, you do not need to configure this parameter. You can set the parameter to STOPPED only when you need to delete the queue. After you change the queue status to STOPPED and all applications in the queue are complete, the queue is deleted. | |
yarn.scheduler.capacity.<queue_path>.maximum-am-resource-percent | Left empty | The percentage of the maximum amount of resources that can be used by Application Master of all applications in the queue. The maximum amount of resources cannot exceed the amount of resources that are calculated by using the following formula: Value of this parameter × Maximum queue capacity. The default value is the same as the default value of the yarn.scheduler.capacity.maximum-am-resource-percent parameter. | |
yarn.scheduler.capacity.<queue_path>.user-limit-factor | Left empty | The upper limit factor for a single user. The maximum amount of resources that a user can use is calculated by using the following formula: min (Maximum queue resources, Guaranteed queue resources × Value of userLimitFactor). Default value: 1.0. | |
yarn.scheduler.capacity.<queue_path>.minimum-user-limit-percent | Left empty | The minimum percentage of the resources that a single user can use to the guaranteed queue resources. The minimum amount of resources that a user can use is calculated by using the following formula: max (Guaranteed queue resources/Number of users, Guaranteed queue resources × Minimum value of userLimitFactor/100). Default value: 100. | |
yarn.scheduler.capacity.<queue_path>.maximum-applications | Left empty | The maximum number of applications that can run on a queue. If you do not configure this parameter, the value calculated by using the following formula is used: Percentage of guaranteed resources of a queue × Value of the yarn.scheduler.capacity.maximum-applications parameter. | |
yarn.scheduler.capacity.<queue_path>.acl_submit_applications | Left empty | The application submission ACL. If you do not configure this parameter for a queue, the queue inherits the configurations of its parent queue. By default, the root queue allows all users to submit applications to a queue. | |
yarn.scheduler.capacity.<queue_path>.acl_administer_queue | Left empty | The queue management ACL. If you do not configure this parameter for a queue, the queue inherits the configurations of its parent queue. By default, the root queue allows all users to manage queues. |
ACL configurations of queues
The following table describes the ACL configurations of queues. In most cases, you can disable ACL. You can enable ACL based on your business requirements.
Configuration file | Configuration item | Recommended value | Description |
yarn-site.xml | yarn.acl.enabled | Left empty | Specifies whether to enable ACL. Default value: false. |
capacity-scheduler.xml | yarn.scheduler.capacity.<queue_path>.acl_submit_applications | Left empty | The application submission ACL. If you do not configure this parameter for a queue, the queue inherits the configurations of its parent queue. By default, the root queue allows all users to submit applications to a queue. |
yarn.scheduler.capacity.<queue_path>.acl_administer_queue | Left empty | The queue management ACL. If you do not configure this parameter for a queue, the queue inherits the configurations of its parent queue. By default, the root queue allows all users to manage queues. |
The ACL configurations of the parent queue take effect on all child queues. For example, the default queue of root allows only Hadoop users to submit jobs. However, other users can also submit applications to the default queue of root because the root queue allows all users to submit and manage queues. To use the ACL feature of child queues, you must configure the yarn.scheduler.capacity.root.acl_submit_applications=<space> and yarn.scheduler.capacity.root.acl_administer_queue=<space> parameters.
To grant a user group or user the ACL permissions to submit and transfer applications, you must configure the yarn.scheduler.capacity.<queue_path>.acl_submit_applications and yarn.scheduler.capacity.<queue_path>.acl_administer_queue parameters.
Preemption configurations
Preemption is used to ensure the fairness of queue scheduling among multiple tenants and the priority of applications. For clusters that have high scheduling requirements, you can enable preemption. YARN V2.8.0 or later supports the preemption feature. The following table describes the related configurations.
Configuration file | Configuration item | Recommended value | Description |
yarn-site.xml | yarn.resourcemanager.scheduler.monitor.enable | true | Specifies whether to enable preemption. |
capacity-scheduler.xml | yarn.resourcemanager.monitor.capacity.preemption.intra-queue-preemption.enabled | true | Specifies whether to enable intra-queue resource preemption. By default, inter-queue resource preemption is enabled and cannot be disabled. |
yarn.resourcemanager.monitor.capacity.preemption.intra-queue-preemption.preemption-order-policy | priority_first | The policy based on which the intra-queue resource preemption is performed. Default value: userlimit_first. | |
yarn.scheduler.capacity.<queue-path>.disable_preemption | true | Specifies whether to allow the queue to be preempted. By default, if you do not configure this parameter, the configuration of the parent queue is used. For example, if you set this parameter to true for the root queue, all child queues cannot be preempted. If you do not configure this parameter for the root queue, the default value is false. This indicates that the queue can be preempted. | |
yarn.scheduler.capacity.<queue-path>.intra-queue-preemption.disable_preemption | true | Specifies whether to disable intra-queue preemption. By default, if you do not configure this parameter, the configuration of the parent queue is used. For example, if you set this parameter to true for the root queue, intra-queue preemption is disabled for all child queues. |
Configurations of capacity-scheduler.xml by using the RESTful API
In previous versions of YARN, you can manage the capacity-scheduler.xml file only by calling the RefreshQueues operation. Each time the RefreshQueues operation is called, full configurations of the capacity-scheduler.xml file are updated, but the updated configuration items cannot be obtained. In YARN V3.2.0 and later, you can call RESTful APIs to perform incremental data update and view all configurations that have taken effect in the capacity-scheduler.xml file. This significantly improves the management efficiency of queues.
To enable Capacity Scheduler, configure the configuration items that are described in the following table.
Configuration file | Configuration item | Recommended value | Description |
yarn-site.xml | yarn.scheduler.configuration.store.class | fs | The type of storage. |
yarn.scheduler.configuration.max.version | 100 | The maximum number of configuration files that can be stored in the file system. Excess configuration files are automatically deleted when the number of configuration files exceeds the value of this parameter. | |
yarn.scheduler.configuration.fs.path | /yarn/<Cluster name>/scheduler/conf | The path in which the capacity-scheduler.xml file is stored. If the path does not exist, the system creates a path. If no prefix is specified, the relative path of the default file system is used as the storage path. Important Replace <Cluster name> with a specific cluster name. Multiple clusters for which the YARN service is deployed can use the same distributed storage. |
Methods for viewing the capacity-scheduler.xml file:
RESTful API: Access a URL in the following format: http://<rm-address>/ws/v1/cluster/scheduler-conf.
HDFS: Access the configuration path ${yarn.scheduler.configuration.fs.path}/capacity-scheduler.xml.<timestamp> to view configurations of the capacity-scheduler.xml file. <timestamp> indicates the time at which the capacity-scheduler.xml file is generated. The capacity-scheduler.xml file that has the largest timestamp value is the latest configuration file.
Example on how to update configuration items:
You can change the value of the yarn.scheduler.capacity.maximum-am-resource-percent parameter to 0.2 and delete the yarn.scheduler.capacity.xxx parameter. To delete a parameter, you need to only remove the value field of the parameter.
curl -X PUT -H "Content-type: application/json" 'http://<rm-address>/ws/v1/cluster/scheduler-conf' -d ' { "global-updates": [ { "entry": [{ "key":"yarn.scheduler.capacity.maximum-am-resource-percent", "value":"0.2" },{ "key":"yarn.scheduler.capacity.xxx" }] } ] }'
Resource limits on a single task or container
The resource limits for a single task or container are determined by the configuration items that are described in the following table.
Configuration file | Configuration item | Description | Default Value/Rule |
yarn-site.xml | yarn.scheduler.maximum-allocation-mb | The maximum memory resources that can be scheduled at the cluster level. Unit: MiB. | The available memory resources of the core or task node group whose memory size is the largest. The memory size of a node group is specified when the cluster is created. The value is the same as that of the yarn.nodemanager.resource.memory-mb parameter of the node group whose memory size is the largest. |
yarn.scheduler.maximum-allocation-vcores | The maximum CPU resources that can be scheduled at the cluster level. Unit: VCore. | The default value is 32. | |
capacity-scheduler.xml | yarn.scheduler.capacity.<queue-path>.maximum-allocation-mb | The maximum memory resources that can be scheduled for the specified queue. Unit: MiB. | By default, this parameter is left empty. If you configure this parameter, the system overrides the cluster-level settings. This parameter takes effect only for a specified queue. |
yarn.scheduler.capacity.<queue-path>.maximum-allocation-vcores | The maximum CPU resources that can be scheduled for the specified queue. Unit: VCore. | By default, this parameter is left empty. If you configure this parameter, the system overrides the cluster-level settings. This parameter takes effect only for a specified queue. |
If the requested resources exceed the maximum available resources for a single task or container, the following error is recorded in application logs: InvalidResourceRequestException: Invalid resource request….