This topic describes how to perform O&M operations when the disk space of a Kafka cluster is full. In this topic, E-MapReduce (EMR) Kafka 2.4.1 is used.
Business scenario
Kafka stores log data on a disk. If the disk space is full, the Kafka log directory on the disk becomes offline. In this case, the partition replicas on the disk cannot be read or written. This reduces the availability and fault tolerance of partitions. The load of other brokers is increased because the leader partition replica is migrated to other brokers. Therefore, you must resolve the issue at the earliest opportunity when the disk space is full.
Overview
This topic describes the O&M policies that can be used when the disk space of a Kafka cluster is full from the following two perspectives: monitoring and recovering full disks.
Monitor a full disk
Kafka service: You can configure alert rules for the OfflineLogDirectoryCount metric of EMR Kafka clusters in the CloudMonitor console to detect offline log directories in real time.
Recover a full disk
If the Kafka log directory on a disk becomes offline, you must first check whether the disk space is full.
- Resize a disk: resizes a disk to increase the disk space. This policy is applicable to scenarios where disks are attached to a broker. For more information, see the Resize a disk section of this topic.
- Migrate partitions within a broker: migrates partitions from a full disk of a broker to other disks of this broker. This policy is applicable to scenarios where the disk usage is imbalanced on a broker. For more information, see the Migrate partitions within a broker section of this topic.
- Clear logs: clears log data that is written to a disk whose space is full. This policy is applicable to scenarios where outdated log data can be deleted. For more information, see the Clear logs section of this topic.
Resize a disk
Description
If the space of a disk is full on a broker, increase the disk space to meet relevant requirements by using this policy. The advantages of this policy are simple operations, low risks, and the ability to quickly resolve the issue of insufficient disk space.
Scenario
This policy is applicable to scenarios where disks are attached to a broker.
Procedure
In the EMR console, resize a disk for a broker. For more information, see Expand a disk.
Migrate partitions within a broker
Description
If the space of a disk is full on a broker, the Kafka log directory on the disk becomes offline. As a result, you cannot use the kafka-reassign-partitions.sh tool to migrate partitions. In this case, you can perform operations on the Elastic Compute Service (ECS) instance where the broker is deployed to move the partition replica data to other disks of the broker and modify the metadata in the corresponding Kafka data directory. This helps resolve the issue of insufficient disk space.
Scenario
This policy is applicable to scenarios where the disk usage is imbalanced on a broker due to the existence of a full disk and disks with relatively low usage.
Usage notes
- This policy allows you to migrate partitions between disks only within a broker.
- Partition migration may cause the I/O hotspotting issue on disks. This may affect the performance of clusters. You need to evaluate the impacts of the size and duration of each migration on your business.
- This policy contains non-standard operations. We recommend that you test the policy on the corresponding Kafka cluster version before you perform operations on a production cluster.
Procedure
If the space of a disk is full, the Kafka log directory on the disk is offline. In this case, you cannot use the kafka-reassign-partitions.sh tool to migrate partitions. This section describes how to perform non-standard operations to migrate partitions by directly moving files and modifying Kafka-related metadata.
- Create a test topic.
- Log on to the master node of the Kafka cluster in SSH mode. For more information, see Log on to a cluster.
- Run the following command to create a test topic named test-topic. Partition replicas are distributed on Broker 0 and Broker 1.
kafka-topics.sh --bootstrap-server core-1-1:9092 --topic test-topic --replica-assignment 0:1 --createRun the following command to query the details of the topic:kafka-topics.sh --bootstrap-server core-1-1:9092 --topic test-topic --describeThe following output is returned. In this case, Broker 0 is in the in-sync replicas (ISR) list.Topic: test-topic PartitionCount: 1 ReplicationFactor: 2 Configs: Topic: test-topic Partition: 0 Leader: 0 Replicas: 0,1 Isr: 0,1
- Run the following command to simulate data writing:
kafka-producer-perf-test.sh --topic test-topic --record-size 1000 --num-records 600000000 --print-metrics --throughput 10240 --producer-props linger.ms=0 bootstrap.servers=core-1-1:9092 - Modify the permissions on the log directory of partitions on Broker 0.
- Run the following command to switch to the emr-user account on the master node:
su emr-user - Run the following command to log on to the core node that you want to manage in password-free mode:
ssh core-1-1 - Run the following sudo command to obtain the root permissions:
sudo su - root - Run the following command to find the disk on which the test-topic-0 partition resides:
sudo find / -name test-topic-0If the following output is returned, the partition is in the /mnt/disk4/kafka/log directory./mnt/disk4/kafka/log/test-topic-0 - Run the following command to set the permissions on the log directory of partitions on Broker 0 to 000:
sudo chmod 000 /mnt/disk4/kafka/log - Run the following command to query the status of test-topic:
kafka-topics.sh --bootstrap-server core-1-1:9092 --topic test-topic --describeThe following output is returned. Broker 0 is no longer in the ISR list.Topic: test-topic PartitionCount: 1 ReplicationFactor: 2 Configs: Topic: test-topic Partition: 0 Leader: 1 Replicas: 0,1 Isr: 1
- Run the following command to switch to the emr-user account on the master node:
- Stop Broker 0.
Stop the Kafka service on Broker 0 in the EMR console.
- Run the following command to move the partitions of test-topic on Broker 0 to another disk on Broker 0:
mv /mnt/disk4/kafka/log/test-topic-0 /mnt/disk1/kafka/log/ - Modify files.
Based on the metadata files in the /mnt/disk4/kafka/log source directory and the /mnt/disk1/kafka/log destination directory, the files to be modified include replication-offset-checkpoint and recovery-point-offset-checkpoint.
- Modify the replication-offset-checkpoint file: Move test-topic-related entries from the replication-offset-checkpoint file in the source log directory to the replication-offset-checkpoint file in the destination log directory, and modify the number of entries in the file.
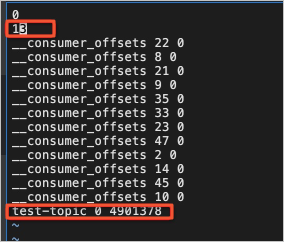
- Modify the recovery-point-offset-checkpoint file: Move test-topic-related entries from the recovery-point-offset-checkpoint file in the source log directory to the recovery-point-offset-checkpoint file in the destination log directory, and modify the number of entries in the file.
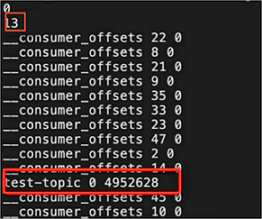
- Modify the replication-offset-checkpoint file: Move test-topic-related entries from the replication-offset-checkpoint file in the source log directory to the replication-offset-checkpoint file in the destination log directory, and modify the number of entries in the file.
- Run the following command to modify the permissions on the log directory of partitions on Broker 0:
sudo chmod 755 /mnt/disk4/kafka/log - Start Broker 0.
Start the Kafka service on Broker 0 in the EMR console.
- Run the following command to check whether the status of the cluster is normal:
kafka-topics.sh --bootstrap-server core-1-1:9092 --topic test-topic --describe
Clear logs
Description
If the space of a disk is full on a broker, delete business log data in chronological order from the earliest data to the latest data until sufficient disk space is released. The data in the internal topics of a Kafka cluster cannot be deleted.
Scenario
This policy is applicable to scenarios where outdated business log data can be deleted from a full disk.
If the retention period of the data is not changed, the disk may become fully occupied soon. Therefore, this policy is generally applicable to scenarios where data surges due to special circumstances.
Usage notes
You cannot delete data from the topics whose names start with underscores (_).
Procedure
- Log on to the machine on which a disk is fully occupied.
- Find the full disk and delete unnecessary business log data. Take note of the following items:
- Do not delete the data directories of the Kafka cluster. This prevents unnecessary data loss.
- Find the topics that occupy a large space or that you no longer need. Select some partitions of the topics to delete data from the earliest stored log data. Delete historical log segments and the index and timeindex files of the segments from some partitions of the topics. Do not delete data from internal topics, such as __consumer_offsets and _schema.
- Restart the broker on which the full disk resides to make the log directory online.