This topic provides answers to frequently asked questions about Spark.
Spark Core
Spark SQL
PySpark
Spark Streaming
spark-submit
How do I view information about a historical Spark job?
To view information about a historical Spark job, perform the following operations: Log on to the E-MapReduce (EMR) console and go to the Access Links and Ports tab of the desired cluster. On the Access Links and Ports tab, find the Spark service and click the URL for Spark. For information about how to access the web UI of Spark, see Access the web UIs of open source components in the EMR the console.
Can I submit Spark jobs in standalone mode?
No, you cannot submit Spark jobs in standalone mode. EMR allows you to submit Spark jobs in Spark on YARN mode or Spark on Kubernetes mode. You cannot submit Spark jobs in standalone mode or Mesos mode.
How do I reduce the number of logs generated by Spark 2 CLI tools?
By default, if you select Spark 2 for an EMR DataLake cluster, logs at the INFO level are generated when you use command-line interface (CLI) tools such as spark-sql and spark-shell. If you want to reduce the number of logs that are generated by the Spark CLI tools, perform the following operations to change the level of log4j logs:
Create a log4j.properties configuration file on the node on which you want to run the CLI tools, such as a master node. You can also run the following command to copy the configuration file from the default configurations:
cp /etc/emr/spark-conf/log4j.properties /new/path/to/log4j.propertiesChange the log level of the new configuration file.
log4j.rootCategory=WARN, consoleIn the spark-defaults.conf configuration file of Spark, change -Dlog4j.configuration=file:/etc/emr/spark-conf/log4j.properties in the value of the spark.driver.extraJavaOptions configuration item to -Dlog4j.configuration=file:/new/path/to/log4j.properties.
ImportantThe path in the value of the configuration item requires the file: prefix.
How do I use the small file merging feature of Spark 3?
To enable Spark to merge small files, set the spark.sql.adaptive.merge.output.small.files.enabled parameter to true. Spark compresses merged files. By default, a merged file can be a maximum of 256 MB in size. If the default size is too small, set the spark.sql.adaptive.advisoryOutputFileSizeInBytes parameter to a larger value.
How do I handle data skew in Spark SQL?
For Spark 2, you can use one of the following methods to handle data skew:
Filter out irrelevant data, such as null data, when you read data from a table.
Broadcast the small table.
select /*+ BROADCAST (table1) */ * from table1 join table2 on table1.id = table2.idSeparate skewed data based on a specific skewed key.
select * from table1_1 join table2 on table1_1.id = table2.id union all select /*+ BROADCAST (table1_2) */ * from table1_2 join table2 on table1_2.id = table2.idScatter the skewed data based on a known skewed key.
select id, value, concat(id, (rand() * 10000) % 3) as new_id from A select id, value, concat(id, suffix) as new_id from ( select id, value, suffix from B Lateral View explode(array(0, 1, 2)) tmp as suffix)Scatter the skewed data without a known skewed key.
select t1.id, t1.id_rand, t2.name from ( select id , case when id = null then concat('SkewData_', cast(rand() as string)) else id end as id_rand from test1 where statis_date='20221130 ') t1 left join test2 t2 on t1.id_rand = t2.id
For Spark 3, you can perform the following operations to handle data skew: Log on to the EMR console and go to the Configure tab of the Spark service page. On this tab, set the spark.sql.adaptive.enabled and spark.sql.adaptive.skewJoin.enabled parameters to true.
How do I use Python 3 in PySpark jobs?
In this example, Spark 2.X and a DataLake cluster of EMR V5.7.0 are used to describe how to use Python 3 in PySpark jobs.
You can use one of the following methods to change the version of Python:
Temporarily change the version of Python
Log on to the cluster in SSH mode. For more information, see Log on to a cluster.
Run the following command to change the version of Python:
export PYSPARK_PYTHON=/usr/bin/python3Run the following command to view the version of Python:
pysparkIf the output contains the following information, the Python version is changed to Python 3:
Using Python version 3.6.8
Permanently change the version of Python
Log on to the cluster in SSH mode. For more information, see Log on to a cluster.
Modify the configuration file.
Run the following command to open the profile file:
vi /etc/profilePress the I key to enter the edit mode.
Add the following information to the end of the profile file to change the Python version:
export PYSPARK_PYTHON=/usr/bin/python3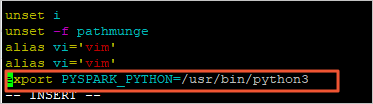
Press the Esc key to exit the edit mode. Then, enter
:wqto save and close the file.
Run the following command to rerun the modified configuration file and apply the configurations:
source /etc/profileRun the following command to view the version of Python:
pysparkIf the output contains the following information, the Python version is changed to Python 3:
Using Python version 3.6.8
Why does a Spark Streaming job unexpectedly stop running?
Check whether the Spark version is earlier than 1.6. If the Spark version is earlier than 1.6, update the Spark version.
Spark whose versions are earlier than 1.6 has a memory leak bug. This bug can cause the container to unexpectedly stop running.
Check whether your code is optimized for memory usage.
Why does a Spark Streaming job remain in the Running state in the EMR console after the job is stopped?
EMR has known issues related to the monitoring of the status of a Spark Streaming job that is submitted in yarn-client mode. Check whether the job is submitted in yarn-client mode. If the job is submitted in yarn-client mode, change the mode to yarn-cluster.
What do I do if the error message java.lang.ClassNotFoundException is displayed when I run spark-submit to submit jobs in YARN-cluster mode in an EMR cluster with Kerberos authentication enabled?
The following figure shows the error message.
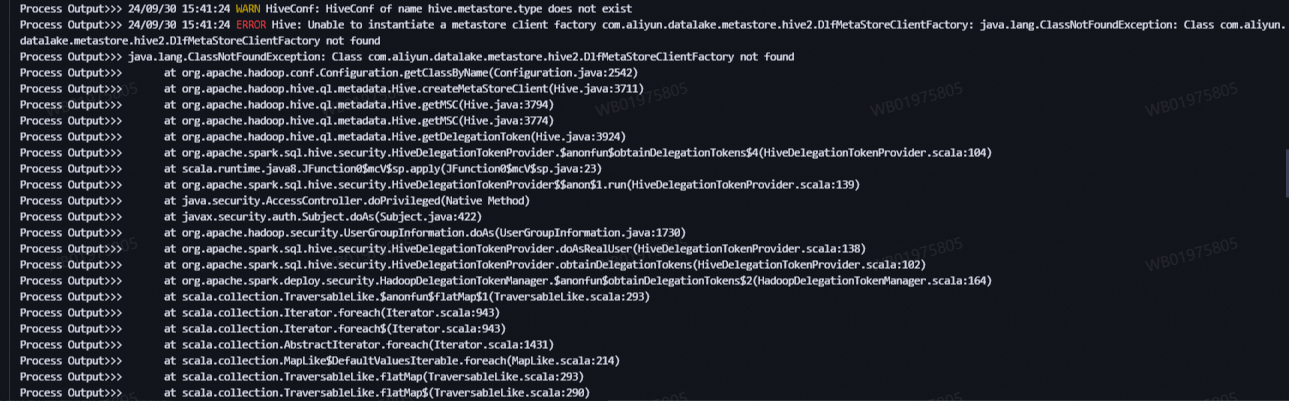
Cause: When you run spark-submit to submit jobs in YARN-cluster mode in an EMR cluster with Kerberos authentication enabled, the class path of the Spark driver is not automatically extended to include the JAR files in a specific directory. As a result, an error occurs when you run a Spark job.
Solution: Add the --jars parameter. This way, the JAR packages in the /opt/apps/METASTORE/metastore-current/hive2 directory are also added to the spark-submit command in addition to the JAR package of Spark.
In YARN-cluster mode, the dependencies configured for the --jars parameter must be separated with commas (,).
For example, if the JAR package of Spark is /opt/apps/SPARK3/spark3-current/examples/jars/spark-examples_2.12-3.5.3-emr.jar, execute the following code to submit jobs:
spark-submit --deploy-mode cluster --class org.apache.spark.examples.SparkPi --master yarn \
--jars $(ls /opt/apps/METASTORE/metastore-current/hive2/*.jar | tr '\n' ',') \
/opt/apps/SPARK3/spark3-current/examples/jars/spark-examples_2.12-3.5.3-emr.jar