JindoTable provides a native engine that can be used to accelerate the queries of files. This feature accelerates the speed of Spark, Hive, or Presto to query ORC or Parquet files. It is disabled by default.
Prerequisites
An E-MapReduce (EMR) cluster of V3.35.0 or later V3.X.X, or V4.9.0 or later V4.X.X is created. ORC or Parquet files are stored in JindoFS or Object Storage Service (OSS). For more information about how to create an EMR cluster, see Create a cluster.
Background information
The following table lists the supported Spark, Hive, and Presto engines and the file formats supported by each engine.
Engine | ORC | Parquet |
Spark2 | Supported | Supported |
Presto | Supported | Unsupported |
Hive2 | Unsupported | Supported |
Limits
Data of the binary type is not supported.
Partitioned tables whose values of partition key columns are stored in files are not supported.
You are not allowed to use spark.read.schema (userDefinedSchema) to define a schema because the schema may be inconsistent with the existing file schema.
Data of the date type must be in the YYYY-MM-DD format and range from 1400-01-01 to 9999-12-31.
Queries of columns that are case-sensitive in the same table cannot be accelerated. For example, queries of the ID and id columns of the same table cannot be accelerated.
Improve performance of Spark to read data
Enable query acceleration for ORC or Parquet files in JindoTable.
NoteQuery acceleration consumes off-heap memory. We recommend that you add
--conf spark.executor.memoryOverhead=4gto a Spark task to apply for additional resources for query acceleration.You can use the native engine when Spark reads data from ORC or Parquet files.
Configure global parameters.
For more information, see Configure the global parameters of Spark.
Configure job-level parameters.
You can add Spark startup parameters when you run Spark Shell or Spark SQL jobs.
spark.sql.extensions==io.delta.sql.DeltaSparkSessionExtension,com.aliyun.emr.sql.JindoTableExtensionFor more information about the configurations of jobs, see Configure a Spark Shell job or Configure a Spark SQL job.
Check whether query acceleration is enabled.
Access the web UI of Spark History Server.
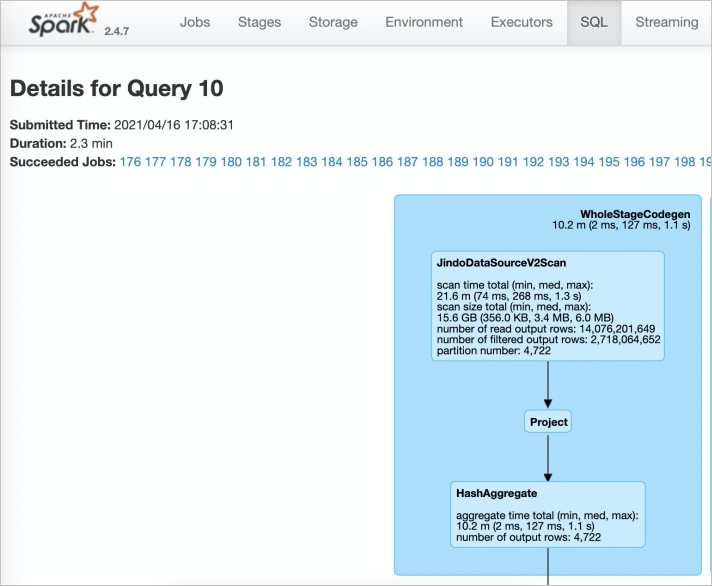
On the SQL tab of Spark, view the execution task.
If JindoDataSourceV2Scan appears, query acceleration is enabled. Otherwise, check the configurations in Step 1.
Improve performance of Presto to read data
Presto has built-in catalog: hive-acc. You can use catalog: hive-acc to enable query acceleration.
Example:
presto --server https://emr-header-1.cluster-xxx:7778/ --catalog hive-acc --schema defaultemr-header-1.cluster-xxx indicates the hostname of the emr-header-1 node.
Complex data types, such as MAP, STRUCT, and ARRAY, are not supported when you use this feature in Presto.
Improve performance of Hive to read data
If you want to schedule jobs in a more stable environment, we recommend that you disable this feature in Hive.
EMR Hive V2.3.7 (EMR V3.35.0) has integrated a plug-in provided by JindoTable. The plug-in accelerates queries of Parquet files. You can set hive.jindotable.native.enabled in your Hive job to enable query acceleration. Alternatively, you can add the hive.jindotable.native.enabled custom parameter and set it to true on the hive-site.xml tab of the Hive configuration page to enable query acceleration, and restart Hive. The latter is suitable to Hive on MapReduce and Hive on Tez.
Example:
set hive.jindotable.native.enabled=true;Complex data types, such as MAP, STRUCT, and ARRAY, are not supported when you use this feature in Hive.
Configure the global parameter of Spark
Go to the Spark service page.
Log on to the Alibaba Cloud EMR console.
In the top navigation bar, select the region where your cluster resides and select a resource group based on your business requirements.
Click the Cluster Management tab.
On the Cluster Management page, find your cluster and click Details in the Actions column.
In the left-side navigation pane, choose .
On the Spark service page, click the Configure tab.
Find the spark.sql.extensions parameter and change its value to io.delta.sql.DeltaSparkSessionExtension,com.aliyun.emr.sql.JindoTableExtension.
Save the configurations.
Click Save in the upper-right corner of the Service Configuration section.
In the Confirm Changes dialog box, specify Description and click OK.
Restart ThriftServer.
Choose in the upper-right corner.
In the Cluster Activities dialog box, specify Description and click OK.
In the Confirm message, click OK.