When you use an E-MapReduce (EMR) cluster built on instance families with local disks, such as instance families with local SSDs (i series) and big data instance families (d series), you may receive a notification that a local disk is damaged. This topic describes how to replace a damaged local disk in the cluster.
Precautions
To resolve this issue, remove the abnormal node and add a new one. This method prevents long-term impacts on your business operations.
Data on the original disk is lost after the disk is replaced. Ensure that your data has a sufficient number of replicas and is backed up before you proceed.
The disk replacement process includes stopping services, unmounting the disk, mounting a new disk, and restarting services. The replacement is usually completed within five business days. Before you perform the steps in this topic, evaluate whether the service's disk usage and the cluster's load can support your business operations while the services are stopped.
Procedure
Log on to the ECS console to view event details. The details include the instance ID, status, damaged disk ID, event progress, and related operations.
Step 1: Get information about the damaged disk
Log on to the node that contains the damaged disk using Secure Shell (SSH). For more information, see Log on to a cluster.
Run the following command to view the block device information.
lsblkThe response is similar to the following.
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT vdd 254:48 0 5.4T 0 disk /mnt/disk3 vdb 254:16 0 5.4T 0 disk /mnt/disk1 vde 254:64 0 5.4T 0 disk /mnt/disk4 vdc 254:32 0 5.4T 0 disk /mnt/disk2 vda 254:0 0 120G 0 disk └─vda1 254:1 0 120G 0 part /Run the following command to view the disk information.
sudo fdisk -lThe returned message is similar to the following.
Disk /dev/vdd: 5905.6 GB, 5905580032000 bytes, 11534336000 sectors Units = sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 4096 bytes I/O size (minimum/optimal): 4096 bytes / 4096 bytesFrom the output of the previous two steps, record the device name
$device_nameand the mount target$mount_path.For example, if the device in the disk damage event is vdd, the device name is /dev/vdd and the mount target is /mnt/disk3.
Step 2: Isolate the damaged local disk
Stop the applications that read data from or write data to the damaged disk.
In the EMR console, click the cluster that contains the damaged disk. On the Cluster Services tab, find the EMR services that read from or write to the damaged disk. These services typically include storage services such as HDFS, HBase, and Kudu. In the area where the endpoint is deployed for the target service, choose
 > Stop to stop the service.
> Stop to stop the service.Run the following commands to stop the related management processes.
sudo crontab -l | grep -v "exporter_check.sh" | sudo crontab - sudo service taihao_exporter stop sudo service ilogtaild stop sudo service ilogtaildclt stopNote: After you stop these management processes, the metric collection and log monitoring features for the node are affected. These features automatically recover after the disk is replaced and the processes are restarted.
You can also run the
sudo fuser -mv $device_namecommand on the node to view the full list of processes that are using the disk, and then stop the services in the list from the EMR console.Run the following command to set application-layer read and write fencing for the local disk.
sudo chmod 000 $mount_pathRun the following command to unmount the local disk.
sudo umount $device_name;sudo chmod 000 $mount_pathImportantIf you do not unmount the disk, its device name may change after the disk is repaired and the fencing is removed. This may cause applications to read from or write to the wrong disk.
Update the fstab file.
Back up the existing /etc/fstab file.
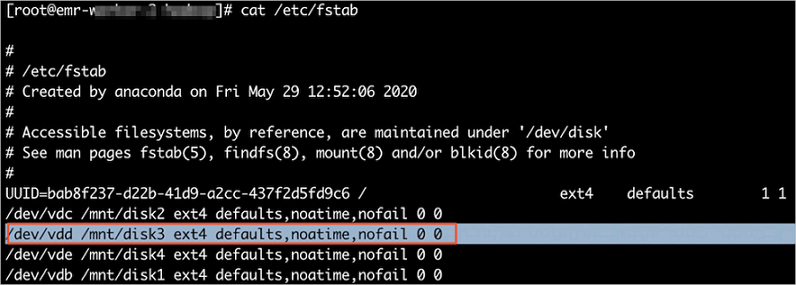
Delete the record for the disk from the /etc/fstab file.
For example, if the damaged disk in this topic is dev/vdd, delete the record for that disk.
You can start a stopped application.
On the Cluster Services tab of the cluster that contains the damaged disk, find the EMR services that you stopped in Step 2. Then, for each service, in the area where the endpoint is deployed, choose
> Start.
Step 3: Replace the disk
Repair the disk in the ECS console. For more information, see Isolate or repair local disks.
Step 4: Mount the disk
After the disk is repaired, mount it to use it as a new disk.
Run the following command to normalize the device name.
device_name=`echo "$device_name" | sed 's/x//1'`This command normalizes device names. For example, a device name such as /dev/xvdk is changed to /dev/vdk.
Run the following command to create a mount directory.
mkdir -p "$mount_path"Run the following command to mount the disk.
mount $device_name $mount_path;sudo chmod 755 $mount_pathIf the disk fails to mount, perform the following steps:
Run the following command to format the disk.
fdisk $device_name << EOF n p 1 wq EOFRun the following command to mount the disk again.
mount $device_name $mount_path;sudo chmod 755 $mount_path
Run the following command to modify the fstab file.
echo "$device_name $mount_path $fstype defaults,noatime,nofail 0 0" >> /etc/fstabNoteRun the
which mkfs.ext4command to check whether ext4 exists. If it exists, set$fstypeto ext4. Otherwise, set$fstypeto ext3.Create a script file and select the script code based on the cluster type.
DataLake, DataFlow, OLAP, DataServing, and Custom clusters
Data lake (Hadoop) clusters
Run the following commands to run the script file, create the service folders, and then delete the script.
$file_pathis the path to the script file.chmod +x $file_path sudo $file_path -p $mount_path rm $file_pathUse the new disk.
In the EMR console, restart the services that run on the node.
Run the following commands to start the management processes.
sudo service taihao_exporter start sudo service ilogtaild start sudo service ilogtaildclt start (sudo crontab -l; echo "*/5 * * * * bash /usr/local/taihao_exporter/exporter_check.sh") | sudo crontab -Verify that the disk is working correctly.