Elastic GPU Service provides extensive service coverage, superior computing power and network performance, and flexible purchase methods. DeepGPU is a free toolkit provided by Alibaba Cloud to enhance GPU computing capabilities of Elastic GPU Service. This topic describes the benefits of Elastic GPU Service and DeepGPU.
Elastic GPU Service
Extensive service coverage
Elastic GPU Service supports large-scale deployment in 17 regions around the world. Elastic GPU Service also provides flexible delivery methods such as auto provisioning and auto scaling to meet your sudden business demands.
Superior computing power
Elastic GPU Service provides GPUs that have superior computing power. When you use Elastic GPU Service together with a high-performance CPU platform, a GPU-accelerated instance can provide mixed-precision computing performance of up to 1,000 trillion floating point operations per second (TFLOPS).
Excellent network performance
GPU-accelerated instances use virtual private clouds (VPCs) that support up to 4.5 million packets per second (Mpps) and 32 Gbit/s of internal bandwidth. You can use GPU-accelerated instances together with Super Computing Cluster (SCC) to provide a Remote Direct Memory Access (RDMA) network that has up to 50 Gbit/s of bandwidth between nodes. This meets the low-latency and high-bandwidth requirements when data is transmitted between nodes.
Flexible purchase methods
Elastic GPU Service supports various billing methods, such as the subscription and pay-as-you-go billing methods, preemptible instances, reserved instances, and storage capacity units (SCUs). To prevent inefficient use of resources, you can select a billing method based on your business requirements.
DeepGPU
DeepGPU includes the following components: Deepytorch, AIACC-ACSpeed (ACSpeed), AIACC-AGSpeed (AGSpeed), FastGPU, and cGPU. The following section describes the core benefits of the components.
Deepytorch
Deepytorch is an AI accelerator developed by Alibaba Cloud to accelerate training and inference in generative AI and Large Language Model (LLM) scenarios. Deepytorch provides high performance and usability for training and inference tasks. The AI accelerator includes the Deepytorch Training and Deepytorch Inference software packages.
Significant performance improvement
Deepytorch Training integrates distributed communication and computational graph compilation to significantly improve the end-to-end training performance. This accelerates model training iterations and reduces costs.
Deepytorch Inference accelerates compilation to reduce the latency of model inference tasks and improve the timeliness and response speed of models. This helps significantly improve model inference performance.
Ease of use
Deepytorch Training is fully compatible with open source ecosystems, mainstream PyTorch versions, and mainstream distributed training frameworks. For example, Deepytorch is compatible with DeepSpeed, PyTorch Fully Sharded Data Parallel (FSDP), and Megatron-LM.
Deepytorch Inference eliminates the need to specify the precision and input size and supports instant compilation to reduce manual operations on code. This improves usability and reduces code complexity and maintenance costs.
DeepNCCL
DeepNCCL is an AI communication acceleration library developed for Alibaba Cloud heterogeneous products of the SHENLONG architecture to support multi-GPU communication. You can use DeepNCCL for AI distributed training tasks and multi-GPU inference tasks to accelerate communication.
Optimized communication efficiency
DeepNCCL can optimize communication on a single machine and across machines and delivers more than 20% higher performance than the cloud-native NCCL.
Imperceptible acceleration
DeepNCCL supports multi-GPU communication and can be used to accelerate distributed training tasks and multi-GPU inference tasks without business interruptions.
DeepGPU-LLM
DeepGPU-LLM is an LLM inference engine developed by Alibaba Cloud based on Elastic GPU Service to provide high-performance inference capabilities in processing LLM tasks.
High performance and low latency
DeepGPU-LLM supports tensor parallelism and communication optimization across GPUs to improve the efficiency and speed of multi-GPU parallel computing.
Support for mainstream models
DeepGPU-LLM supports mainstream models, such as Tongyi Qianwen, Llama, ChatGLM, and Baichuan, to meet model inference requirements in different scenarios.
FastGPU
FastGPU is a fast cluster deployment tool that allows you to build AI computing tasks without the need to deploy computing, storage, or network resources at the IaaS layer. You need to only configure simple settings to deploy clusters, which helps you save time and reduce costs.
High efficiency
You can quickly deploy clusters. You do not need to separately deploy resources such as computing, storage, and network resources at the IaaS layer. The time required to deploy a cluster is reduced to 5 minutes.
You can manage tasks and resources in a convenient and efficient manner by using interfaces and command lines.
Cost-effectiveness
You can purchase a GPU-accelerated instance after the dataset completes the preparations and triggers a training or inference task. After the training or inference task ends, the GPU-accelerated instance is automatically released. FastGPU can synchronize the resource lifecycle with tasks to reduce costs.
You can create preemptible instances.
Ease of use
All resources are deployed at the IaaS layer. The resources are accessible and can be debugged.
FastGPU meets visualization and log management requirements and ensures that tasks are traceable.
cGPU
cGPU allows you to flexibly allocate resources and isolate your business data. You can use cGPU to reduce costs and improve security.
Cost-effectiveness
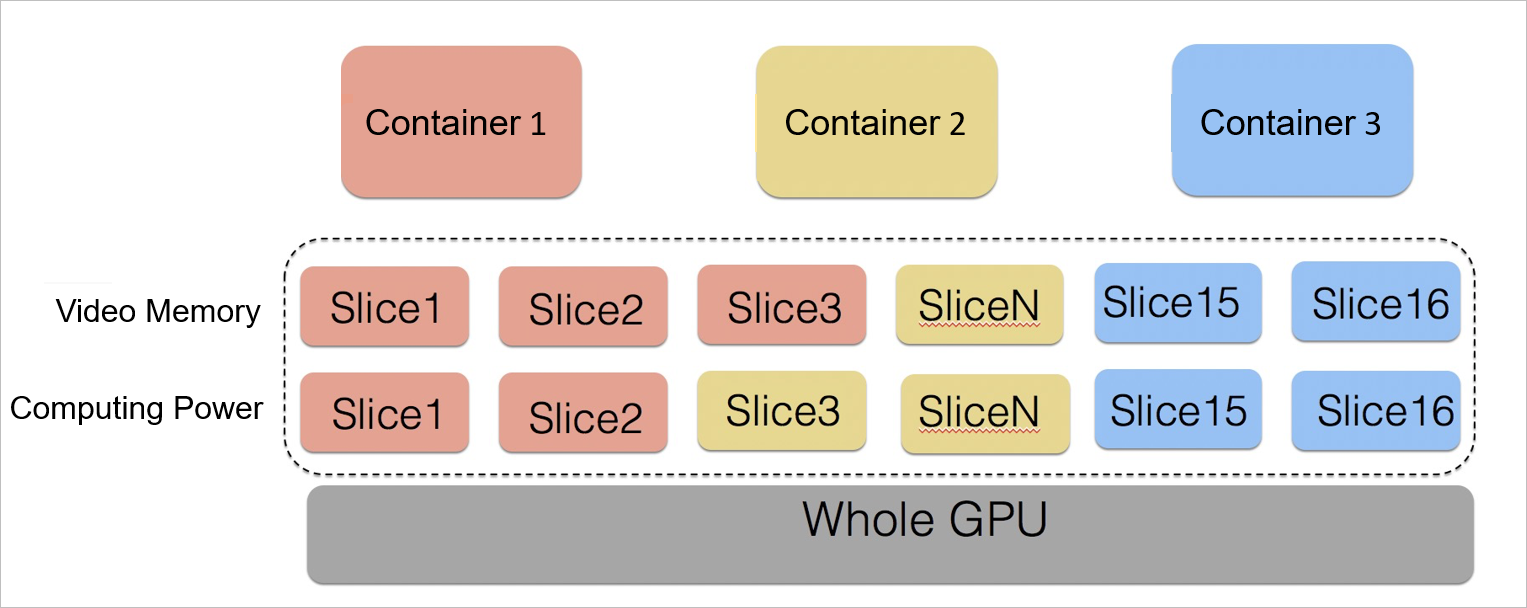
With the continuous development of GPUs and the progress of the semiconductor manufacturing industry, a single GPU provides higher computing power but has a higher price. In most business scenarios, an AI application does not require an entire GPU. cGPU allows multiple containers to share one GPU. This isolates business data for security, improves GPU utilization, and reduces costs.
Flexible resource allocation
cGPU allows you to flexibly allocate physical GPU resources based on a specific ratio.
You can flexibly allocate resources by GPU memory or computing power.
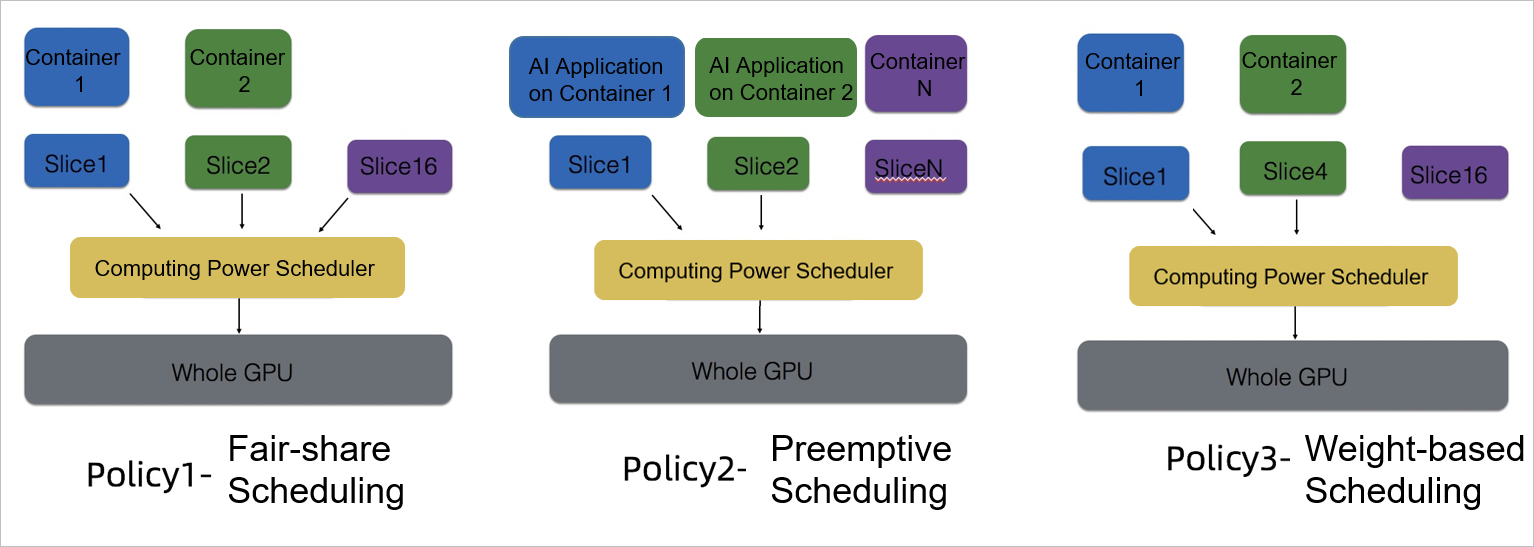
cGPU also allows you to flexibly configure policies to allocate computing power. You can switch between the following three scheduling policies in real time to meet the requirements of AI workloads during peak and off-peak hours.