This topic describes how to use BigDL Privacy Preserving Machine Learning (BigDL PPML) to run a distributed, end-to-end secure Apache Spark big data analytics application on Intel® TDX enabled g8i instances.
Background information
As enterprises migrate their data and computing resources to the cloud, protecting data privacy and confidentiality becomes a critical challenge for big data analytics and AI applications.
BigDL PPML can be used to run standard big data and AI applications (such as Apache Spark, Apache Flink, Tensorflow, and PyTorch) on Alibaba Cloud TDX instances while protecting data that is in transit and in use and assuring application integrity. For more information, see BigDL-PPML.
Intel® Trusted Domain Extensions (Intel® TDX) provides hardware-assisted security to protect data. It is independent of firmware and the security status of hosts and can build a confidential computing environment on physical machines.
Alibaba Cloud g8i instances are Intel® TDX enabled instances (hereinafter referred to as TDX instances) that provide TDX confidential computing capabilities and create a safer, trusted, confidential environment with hardware-enforced protection. TDX instances mitigate risks that are associated with malware attacks and achieve high levels of data privacy and application integrity.
BigDL PPML is a solution that is developed based on Intel® TDX to secure data analysis and AI applications.
Architecture
By using BigDL PPML, you can run existing distributed big data analytics and AI applications, such as Apache Spark, Apache Flink, Tensorflow, and PyTorch, in a confidential environment with no code changes. Big data analytics and AI applications run on Kubernetes clusters that are based on TDX instances, where compute and memory are protected by Intel® TDX. BigDL PPML enables the following end-to-end security mechanisms for distributed applications at the underlying layer:
A security mechanism that provides and attests a trusted cluster environment in a Kubernetes cluster that is based on TDX instances.
Key management service (KMS): manages keys and uses the keys to encrypt and decrypt distributed data.
Secure, distributed computing and communication.
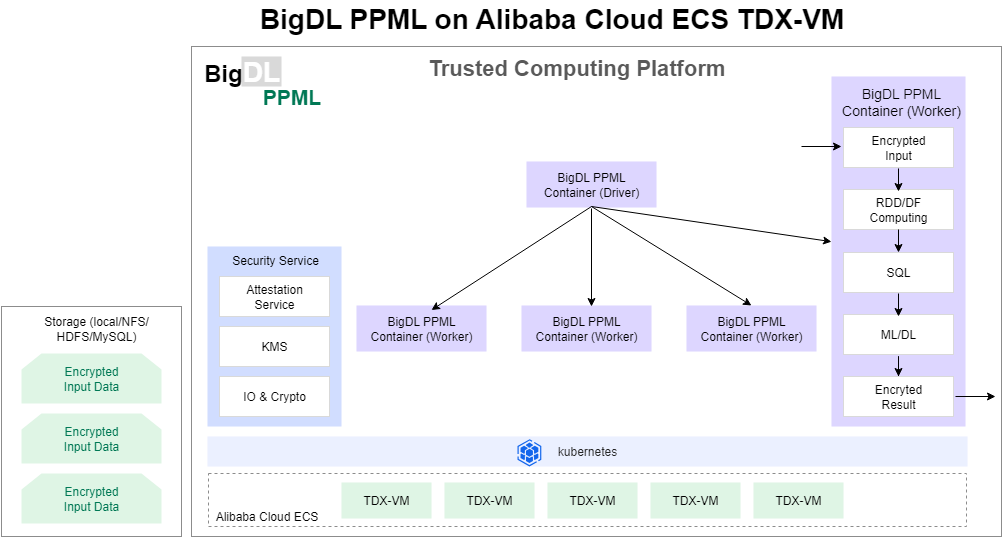
BigDL PPML secures the end-to-end big data and AI pipeline in a Kubernetes cluster that is deployed based on Intel® TDX enabled instances, as shown in the preceding figure. All data is encrypted and stored in data lakes and data warehouses.
BigDL PPML workers load encrypted input data, obtain data keys by performing remote attestations or by using KMS, and use the keys to decrypt input data on TDX instances.
BigDL PPML workers use big data and AI computing frameworks to preprocess data in a distributed manner, train models, and perform inference by using models.
BigDL PPML workers encrypt and write final results, output data, or models to distributed storage.
Data that is transmitted between nodes is encrypted in transit based on security protocols, such as Advanced Encryption Standard (AES) and Transport Layer Security, to ensure the end-to-end security and privacy of data.
Procedure
This section describes how to run a distributed, end-to-end secure, big data analytics application on TDX instances. In this example, an Apache Spark big data analytics application and a Simple Query example are used. For information about how to use big data and AI applications, see BigDL PPML Tutorials & Examples.
Step 1: Deploy a Kubernetes cluster and runtime environment
In this topic, a Kubernetes cluster that consists of a master node and two worker nodes is used. The number of nodes in the cluster must be the same as that of TDX instances that you purchase. You can create a Kubernetes cluster that consists of a specific number of nodes based on your business requirements.
Create Intel® TDX enabled g8i instances.
For more information, see Create an instance on the Custom Launch tab. Take note of the following parameters:
Instance Type: Select an instance type that supports Simple Query examples. An instance type must have at least 32 vCPUs and 64 GiB of memory to support Simple Query examples. In this topic, the ecs.g8i.8xlarge instance type is used.
Image: Select Alibaba Cloud Linux 3.2104 LTS 64-bit.
Public IP Address: Select Assign Public IPv4 Address.
Quantity: Enter 3.
Connect to an instance.
For more information, see Methods for connecting to an ECS instance.
Deploy a Kubernetes cluster and configure security settings.
Deploy a Kubernetes cluster on the g8i instances.
For more information, see Creating a cluster with kubeadm.
Run the following commands to configure security settings (role-based access control settings) on the master node of the Kubernetes cluster:
kubectl create serviceaccount spark kubectl create clusterrolebinding spark-role --clusterrole=edit --serviceaccount=default:spark --namespace=default
Create a PersistentVolume.
Run the following command as the root user to create the pv-volume.yaml file:
vim pv-volume.yamlPress the
Ikey to enter the Insert mode.Add the following content to pv-volume.yaml:
apiVersion: v1 kind: PersistentVolume metadata: name: task-pv-volume labels: type: local spec: storageClassName: manual capacity: storage: 10Gi accessModes: - ReadWriteOnce hostPath: path: "/mnt/data"Press the
Esckey and enter:wqto save the changes and exit the Insert mode.Run the following commands to create a PersistentVolume and view the PersistentVolume:
kubectl apply -f pv-volume.yaml kubectl get pv task-pv-volume
Create a PersistentVolumeClaim.
Run the following command as the root user to create the pv-claim.yaml file:
vim pv-claim.yamlPress the
Ikey to enter the Insert mode.Add the following content to pv-claim.yaml:
apiVersion: v1 kind: PersistentVolumeClaim metadata: name: task-pv-claim spec: storageClassName: manual accessModes: - ReadWriteOnce resources: requests: storage: 3GiPress the
Esckey and enter:wqto save the changes and exit the Insert mode.Run the following commands to create a PersistentVolumeClaim and view the PersistentVolumeClaim:
kubectl apply -f pv-claim.yaml kubectl get pvc task-pv-claim
Step 2: Encrypt training data
Run the following command on each node of the Kubernetes cluster to obtain the BigDL PPML image.
The image is used to run standard Apache Spark applications and provides data encryption and decryption features.
docker pull intelanalytics/bigdl-ppml-trusted-bigdata-gramine-reference-16g:2.3.0-SNAPSHOTGenerate the training dataset file people.csv.
Run the following command on the master node of the Kubernetes cluster to download the training script generate_people_csv.py:
wget https://github.com/intel-analytics/BigDL/raw/main/ppml/scripts/generate_people_csv.pyRun the following command to generate the training dataset file people.csv:
python generate_people_csv.py </save/path/of/people.csv> <num_lines>NoteSet </save/path/of/people.csv> to the path in which you want to generate the people.csv file. In this example, the /home/user path is used.
Set <num_lines> to the number of lines in people.csv. In this example, the number of lines is 500.
Run the following command to move people.csv to a specific directory:
sudo scp /home/user/people.csv /mnt/data/simplekms/ImportantReplace
/home/userwith an actual directory.In this example, the
/mnt/data/simplekms/directory is used. The/mnt/data/simplekms/directory stores encrypted and decrypted data and is not separately elaborated in the subsequent sections of this topic.
Run the following commands on the master node of the Kubernetes cluster to run the bigdl-ppml-client container.
The container is used to encrypt and decrypt training data.
NoteReplace
/home/user/kuberconfig:/root/.kube/configbased on the user that runs the bigdl-ppml-client container.If the root user runs the container, replace /home/user/kuberconfig:/root/.kube/config with
/root/kuberconfig:/root/.kube/config.If a common user such as the test user runs the container, replace /home/user/kuberconfig:/root/.kube/config with
/home/test/kuberconfig:/root/.kube/config.
export K8S_MASTER=k8s://$(kubectl cluster-info | grep 'https.*6443' -o -m 1) echo The k8s master is $K8S_MASTER . export SPARK_IMAGE=intelanalytics/bigdl-ppml-trusted-bigdata-gramine-reference-16g:2.3.0-SNAPSHOT sudo docker run -itd --net=host \ -v /etc/kubernetes:/etc/kubernetes \ -v /home/user/kuberconfig:/root/.kube/config \ -v /mnt/data:/mnt/data \ -e RUNTIME_SPARK_MASTER=$K8S_MASTER \ -e RUNTIME_K8S_SPARK_IMAGE=$SPARK_IMAGE \ -e RUNTIME_PERSISTENT_VOLUME_CLAIM=task-pv-claim \ --name bigdl-ppml-client \ $SPARK_IMAGE bash docker exec -it bigdl-ppml-client bashEncrypt people.csv on the master node of the Kubernetes cluster.
Run the following commands to generate a primary key (primarykey) based on the application ID (APPID) and an API key (APIKEY).
You can use simple KMS to generate an application ID and an API key that are 1 to 12 characters in length. In this example, the value of APPID is 98463816****, and the value of APIKEY is 15780936****. --primaryKeyPath specifies the directory in which you want to store the primary key.
java -cp '/ppml/spark-3.1.3/conf/:/ppml/spark-3.1.3/jars/*:/ppml/bigdl-2.3.0-SNAPSHOT/jars/*' \ com.intel.analytics.bigdl.ppml.examples.GeneratePrimaryKey \ --primaryKeyPath /mnt/data/simplekms/primaryKey \ --kmsType SimpleKeyManagementService \ --simpleAPPID 98463816**** \ --simpleAPIKEY 15780936****Create the encryption script encrypt.py.
Run the following command to switch to the
/mnt/data/simplekmsdirectory:cd /mnt/data/simplekmsRun the following command to create and open the encrypt.py file:
sudo vim encrypt.pyPress the
Ikey to enter the Insert mode.Add the following content to the encrypt.py file:
# encrypt.py from bigdl.ppml.ppml_context import * args = {"kms_type": "SimpleKeyManagementService", "app_id": "98463816****", "api_key": "15780936****", "primary_key_material": "/mnt/data/simplekms/primaryKey" } sc = PPMLContext("PPMLTest", args) csv_plain_path = "/mnt/data/simplekms/people.csv" csv_plain_df = sc.read(CryptoMode.PLAIN_TEXT) \ .option("header", "true") \ .csv(csv_plain_path) csv_plain_df.show() output_path = "/mnt/data/simplekms/encrypted-input" sc.write(csv_plain_df, CryptoMode.AES_CBC_PKCS5PADDING) \ .mode('overwrite') \ .option("header", True) \ .csv(output_path)Press the
Esckey and enter:wqto save the changes and exit the Insert mode.
Run the following command in the bigdl-ppml-client container to encrypt people.csv by using APPID, APIKEY, and primarykey.
The encrypted data is stored in the
/mnt/data/simplekms/encrypted-outputdirectory.java \ -cp '/ppml/spark-3.1.3/conf/:/ppml/spark-3.1.3/jars/*:/ppml/bigdl-2.3.0-SNAPSHOT/jars/*' \ -Xmx1g org.apache.spark.deploy.SparkSubmit \ --master 'local[4]' \ --conf spark.network.timeout=10000000 \ --conf spark.executor.heartbeatInterval=10000000 \ --conf spark.python.use.daemon=false \ --conf spark.python.worker.reuse=false \ --py-files /ppml/bigdl-2.3.0-SNAPSHOT/python/bigdl-ppml-spark_3.1.3-2.3.0-SNAPSHOT-python-api.zip,/ppml/bigdl-2.3.0-SNAPSHOT/python/bigdl-spark_3.1.3-2.3.0-SNAPSHOT-python-api.zip,/ppml/bigdl-2.3.0-SNAPSHOT/python/bigdl-dllib-spark_3.1.3-2.3.0-SNAPSHOT-python-api.zip \ /mnt/data/simplekms/encrypt.py
Run the following commands on each worker node of the Kubernetes cluster to copy
/mnt/data/simplekmsfrom the master node to each worker node.cd /mnt/data sudo scp -r user@192.168.XXX.XXX:/mnt/data/simplekms .NoteReplace user with the actual username of the master node and 192.168.XXX.XXX with the actual IP address of the master node.
Step 3: Run a BigDL PPML based big data analytics example
In the bigdl-ppml-client container, submit an Apache Spark job to the Kubernetes cluster to run a Simple Query example.
NoteIn spark.driver.host=192.168.XXX.XXX, replace 192.168.XXX.XXX with the actual IP address of the master node.
${SPARK_HOME}/bin/spark-submit \ --master $RUNTIME_SPARK_MASTER \ --deploy-mode client \ --name spark-simplequery-tdx \ --conf spark.driver.memory=4g \ --conf spark.executor.cores=4 \ --conf spark.executor.memory=4g \ --conf spark.executor.instances=2 \ --conf spark.driver.host=192.168.XXX.XXX \ --conf spark.kubernetes.authenticate.driver.serviceAccountName=spark \ --conf spark.cores.max=8 \ --conf spark.kubernetes.container.image=$RUNTIME_K8S_SPARK_IMAGE \ --class com.intel.analytics.bigdl.ppml.examples.SimpleQuerySparkExample \ --conf spark.network.timeout=10000000 \ --conf spark.executor.heartbeatInterval=10000000 \ --conf spark.kubernetes.executor.deleteOnTermination=false \ --conf spark.driver.extraClassPath=local://${BIGDL_HOME}/jars/* \ --conf spark.executor.extraClassPath=local://${BIGDL_HOME}/jars/* \ --conf spark.kubernetes.file.upload.path=/mnt/data \ --conf spark.kubernetes.driver.volumes.persistentVolumeClaim.${RUNTIME_PERSISTENT_VOLUME_CLAIM}.options.claimName=${RUNTIME_PERSISTENT_VOLUME_CLAIM} \ --conf spark.kubernetes.driver.volumes.persistentVolumeClaim.${RUNTIME_PERSISTENT_VOLUME_CLAIM}.mount.path=/mnt/data \ --conf spark.kubernetes.executor.volumes.persistentVolumeClaim.${RUNTIME_PERSISTENT_VOLUME_CLAIM}.options.claimName=${RUNTIME_PERSISTENT_VOLUME_CLAIM} \ --conf spark.kubernetes.executor.volumes.persistentVolumeClaim.${RUNTIME_PERSISTENT_VOLUME_CLAIM}.mount.path=/mnt/data \ --jars local:///ppml/bigdl-2.3.0-SNAPSHOT/jars/bigdl-ppml-spark_3.1.3-2.3.0-SNAPSHOT.jar \ local:///ppml/bigdl-2.3.0-SNAPSHOT/jars/bigdl-ppml-spark_3.1.3-2.3.0-SNAPSHOT.jar \ --inputPartitionNum 8 \ --outputPartitionNum 8 \ --inputEncryptModeValue AES/CBC/PKCS5Padding \ --outputEncryptModeValue AES/CBC/PKCS5Padding \ --inputPath /mnt/data/simplekms/encrypted-input \ --outputPath /mnt/data/simplekms/encrypted-output \ --primaryKeyPath /mnt/data/simplekms/primaryKey \ --kmsType SimpleKeyManagementService \ --simpleAPPID 98463816**** \ --simpleAPIKEY 15780936****View the status of the Apache Spark job on the master node.
Run the following command to view the names and status of drivers and executors:
kubectl get podWhen the Apache Spark job is completed, the value of STATUS changes from
RunningtoCompleted.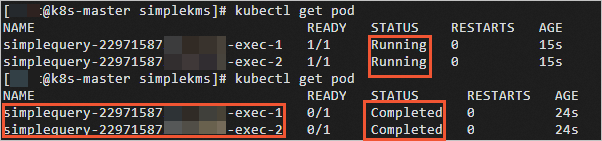
Run the following command to view the logs of the pod:
kubectl logs simplequery-xxx-exec-1NoteReplace simplequery-xxx-exec-1 with the corresponding value of Name that you obtained in the preceding step.
When the Apache Spark job is completed,
Finishedis displayed in the logs of the pod.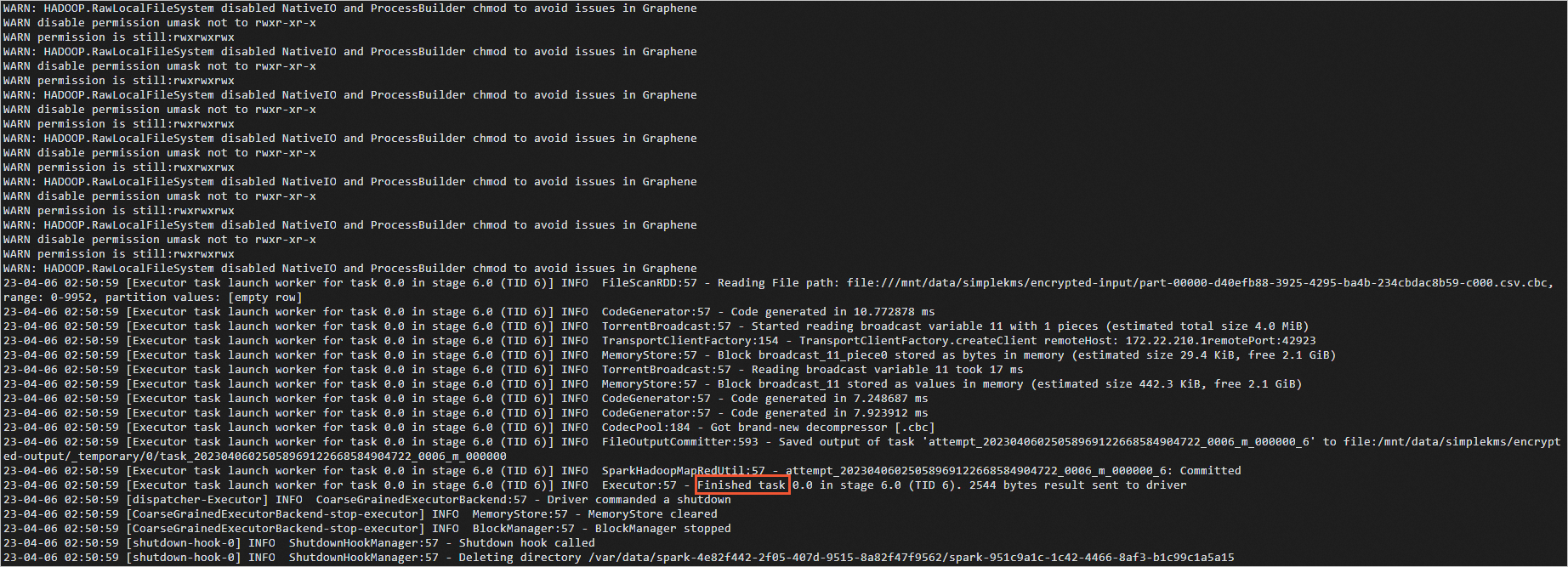
Step 4: Decrypt the results
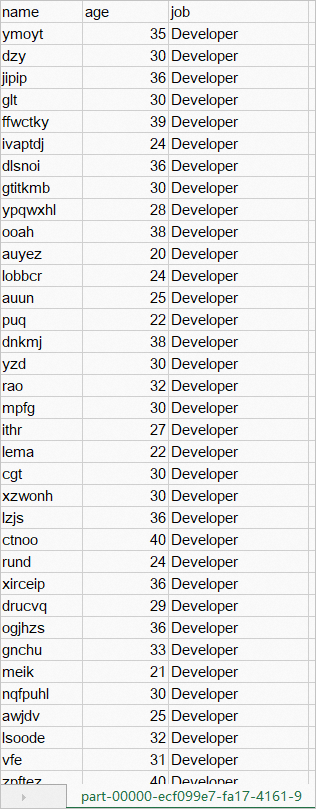
Upload the
.metaandpart-XXXX.csv.cbcfiles that are stored in the encrypted-output directory of each worker node to the encrypted-output directory of the master node.After the files are uploaded, the encrypted-output directory of the master node contains data, as shown in the following figure.

In the
/mnt/data/simplekmsdirectory of the master node, create the decrypt.py file.Run the following command to switch to the
/mnt/data/simplekmsdirectory:cd /mnt/data/simplekmsRun the following command to create and open the decrypt.py file:
sudo vim decrypt.pyPress the
Ikey to enter the Insert mode.Add the following content to the decrypt.py file:
from bigdl.ppml.ppml_context import * args = {"kms_type": "SimpleKeyManagementService", "app_id": "98463816****", "api_key": "15780936****", "primary_key_material": "/mnt/data/simplekms/primaryKey" } sc = PPMLContext("PPMLTest", args) encrypted_csv_path = "/mnt/data/simplekms/encrypted-output" csv_plain_df = sc.read(CryptoMode.AES_CBC_PKCS5PADDING) \ .option("header", "true") \ .csv(encrypted_csv_path) csv_plain_df.show() output_path = "/mnt/data/simplekms/decrypted-output" sc.write(csv_plain_df, CryptoMode.PLAIN_TEXT) \ .mode('overwrite') \ .option("header", True)\ .csv(output_path)Press the
Esckey and enter:wqto save the changes and exit the Insert mode.
Run the following commands on the master node of the Kubernetes cluster to decrypt the data that is stored in the
encrypted_csv_pathdirectory.APPID, APIKEY, and primarykey are used to decrypt data. The decrypted data file
part-XXXX.csvis stored in the/mnt/data/simplekms/decrypted-outputdirectory.java \ -cp '/ppml/spark-3.1.3/conf/:/ppml/spark-3.1.3/jars/*:/ppml/bigdl-2.3.0-SNAPSHOT/jars/*' \ -Xmx1g org.apache.spark.deploy.SparkSubmit \ --master 'local[4]' \ --conf spark.network.timeout=10000000 \ --conf spark.executor.heartbeatInterval=10000000 \ --conf spark.python.use.daemon=false \ --conf spark.python.worker.reuse=false \ --py-files /ppml/bigdl-2.3.0-SNAPSHOT/python/bigdl-ppml-spark_3.1.3-2.3.0-SNAPSHOT-python-api.zip,/ppml/bigdl-2.3.0-SNAPSHOT/python/bigdl-spark_3.1.3-2.3.0-SNAPSHOT-python-api.zip,/ppml/bigdl-2.3.0-SNAPSHOT/python/bigdl-dllib-spark_3.1.3-2.3.0-SNAPSHOT-python-api.zip \ /mnt/data/simplekms/decrypt.pyThe decrypted data is displayed in Windows, as shown in the following figure.