This topic describes how to use the extract, transform, and load (ETL) feature to analyze real-time orders.
Scenarios
The ETL feature allows you to extract, transform, and load streaming data and efficiently integrate large amounts of real-time data to meet the requirements for real-time data processing. The ETL feature supports drag-and-drop operations and low-code development to facilitate various business scenarios such as business decision making, real-time reporting, and real-time data computing. During the digital transformation of enterprises, the ETL feature can be used in the following real-time data processing scenarios:
Centralized management of multi-region or heterogeneous data in real time: The ETL feature allows you to store heterogeneous data or data from multiple regions to the same database in real time. This facilitates centralized and efficient management and decision-making.
Real-time reporting: The ETL feature allows you to build a real-time reporting system. The reporting system improves the reporting efficiency during the digital transformation and is suitable for various real-time analysis scenarios.
Real-time computing: The ETL feature allows you to cleanse the streaming data generated on the business side in real time to extract feature values and tags. Typical real-time computing scenarios include online business computing models such as profiling, risk control, and recommendations and dashboards that are used to display real-time data.
Overview
In this example, the ETL feature is used to merge real-time transaction data and business data, and ship the data that meets specified filter conditions to a data warehouse in real time. The transaction data includes the order number, customer ID, product or commodity code, transaction amount, and transaction time. The business data includes the product code, product unit price, and product name. For example, you can specify filter conditions to query the real-time transaction information about orders whose price value exceed 3,000. Then, you can analyze the transaction data from multiple dimensions such as the product and customer dimensions. In addition, you can use tools to create a visualized dashboard and gain insights into dynamic data based on your business requirements.
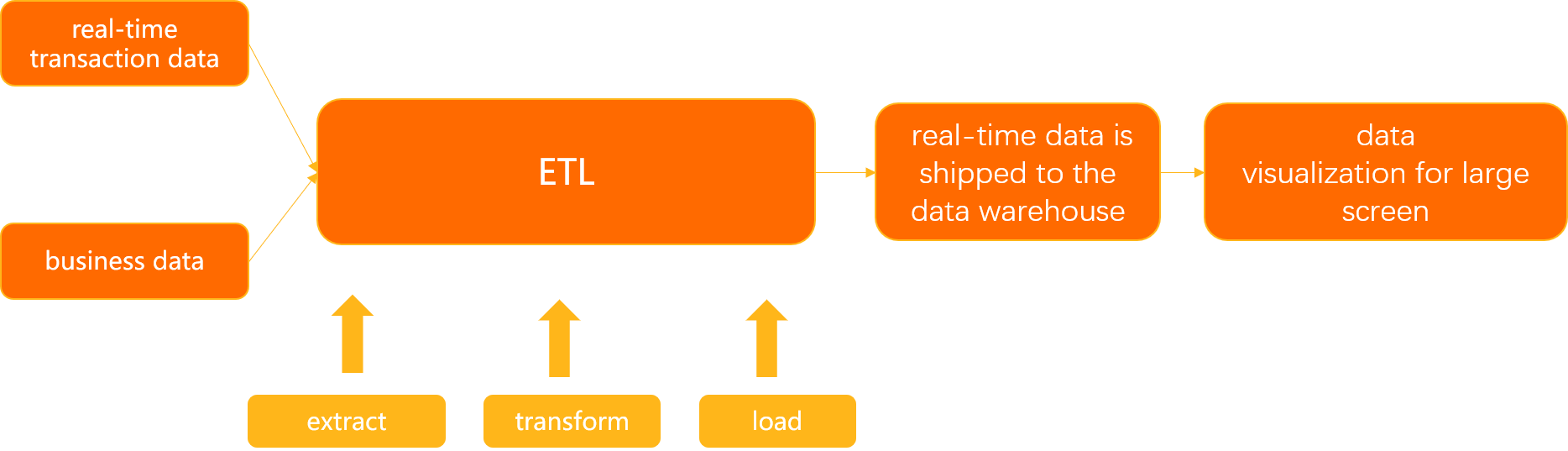
Procedure
To ensure the successful configuration and execution of an ETL task, we recommend that you read the Prerequisites and Precautions sections of the "Configure an ETL task in DAG mode" topic before you configure the ETL task.

Step | Description |
Store the real-time transaction data and business data in source tables and create a destination table based on your business requirements. Note In this example, the tables that store the real-time transaction data and business data and the destination table are stored in an ApsaraDB RDS for MySQL instance. | |
Configure the table that stores the real-time transaction data as a stream table and the table that stores the business data as a dimension table. | |
Join the dimension table and stream table into a wide table. | |
Specify filter conditions to query data in the wide table. For example, you can query the orders whose price value exceeds 3,000. | |
Load the processed data to the destination table in real time. | |
Precheck and start the ETL task. |
Preparations
Before you configure an ETL task, you must store the real-time transaction data in a stream table and the business data in a dimension table in the source ApsaraDB RDS for MySQL instance.
You must also create a destination table in the destination ApsaraDB RDS for MySQL instance based on your business requirements.
You can execute the following statements to create a real-time transaction data table, a business data table, and a destination table.
Real-time transaction data table
create table test_orders(
order_id bigint not null COMMENT 'Order ID',
user_id bigint not null comment 'User ID',
product_id bigint not null comment 'Product ID',
total_price decimal(15,2) not null COMMENT 'Total Price',
order_date TIMESTAMP not null COMMENT 'Order Date',
PRIMARY KEY (order_id))Business data table
CREATE table product (
product_id bigint not null comment 'Product ID',
product_name varchar(20) comment 'Product Name',
product_price decimal(15,2) not null comment 'Unit Price')Destination table
create table test_orders(
order_id bigint not null COMMENT 'Order ID',
user_id bigint not null comment 'User ID',
product_id bigint not null comment 'Product ID',
total_price decimal(15,2) not null COMMENT 'Total Price',
order_date TIMESTAMP not null
COMMENT 'Order Date',
product_id_2 bigint not null comment 'Product ID',
product_name varchar(20) comment 'Product Name',
product_price decimal(15,2) not null comment 'Unit Price',
PRIMARY KEY (order_id))Step 1: Configure the source database
Go to the Streaming ETL page.
Log on to the DTS console.
In the left-side navigation pane, click ETL.
In the upper-left corner of the Streaming ETL page, click
 . In the Create Data Flow dialog box, specify an ETL task name in the Data Flow Name field and set the Development Method parameter to DAG.
. In the Create Data Flow dialog box, specify an ETL task name in the Data Flow Name field and set the Development Method parameter to DAG. Click OK.
Configure the stream table and dimension table.
Configure the stream table.
On the left side of the canvas, drag an Input/Dimension Table MySQL node to the blank area of the canvas.
Click Input/Dimension Table MySQL-1 on the canvas.
On the Node Settings tab, configure the parameters.
Parameter
Description
Data Source Name
Data Transmission Service (DTS) automatically generates a data source name. We recommend that you specify a descriptive name for easy identification. You do not need to use a unique name.
Region
Select the region in which the source database resides.
NoteYou can create an ETL task in one of the following regions: China (Hangzhou), China (Shanghai), China (Qingdao), China (Beijing), China (Zhangjiakou), China (Shenzhen), China (Guangzhou), and China (Hong Kong).
Instances
Select the source database instance. You can also click Create Instance to create a source database instance. For more information, see Databases supported by DMS.
Node Type
Select the type of the source table. In this example, Stream Table is selected.
Stream Table: a table that is updated in real time and can be associated with a dimension table for data association queries.
Dimension Table: a table that is not updated in real time and is generally used to assemble real-time data into a wide table for data analysis.
Convert Format
ETL converts a stream into a dynamic table and performs continuous queries on the dynamic table to generate a new dynamic table. In this process, the dynamic table is continuously modified by performing the INSERT, UPDATE, and DELETE operations. When the dynamic table is finally written to the destination database, the new dynamic table is converted back into a stream. When the new dynamic table is converted into a stream, you must specify the Convert Format parameter to encode the modifications to the dynamic table.
Upsert Stream: The data in a dynamic table can be modified by performing the INSERT, UPDATE, and DELETE operations. When the dynamic table is converted into a stream, the INSERT and UPDATE operations are encoded as upsert messages and the DELETE operations are encoded as delete messages.
NoteA dynamic table that is converted into an upsert stream requires a unique key. The key may be composite.
Append-Only Stream: The data in a dynamic table can be modified only by performing the INSERT operation. When the dynamic table is converted into a stream, only the inserted data is sent.
Select Databases and Tables
Select the databases and tables that you want to transform.
After the node is configured, you are redirected to the Output Fields tab. On this tab, select the databases and tables in the Column Name column based on your business requirements.
Click the Time Attribute tab and configure the parameters.
Parameter
Description
Event Time Watermark
Select a time field in the stream table. In most cases, a time field is defined in a stream table to represent the time when data is generated. The time field is usually an informative timestamp such as ordertime.
Latency of Event Time Watermark
Enter the maximum data latency that you can accept.
A latency may exist between the time when the data is generated and the time when the data is processed in ETL. ETL cannot indefinitely wait to process the delayed data. You can use this parameter to specify the maximum latency for ETL to process out-of-order data. For example, if the data generated at 10:00 is received, but the data generated at 9:59 is not received, ETL only waits until "10:00 + latency". If the data generated at 9:59 is not received before this point in time, the data is discarded.
Processing Time
The server time when the data is processed in ETL. Enter a column name. ETL saves the server time when the data is processed in this column. The processing time is used for operator operations. For example, the processing time is used to associate the latest version of a standard table when you perform temporal join operations.
NoteIf the
 icon is not displayed on the right side of the stream table, the stream table is configured.
icon is not displayed on the right side of the stream table, the stream table is configured. Configure the dimension table.
On the left side of the canvas, drag an Input/Dimension Table MySQL node to the blank area of the canvas.
Click Input/Dimension Table MySQL-2 on the canvas.
On the Node Settings tab, configure the parameters.
Parameter
Description
Data Source Name
DTS automatically generates a data source name. We recommend that you specify a descriptive name for easy identification. You do not need to use a unique name.
Region
Select the region in which the source database resides.
Instances
Select the source database instance. You can also click Create Instance to create a source database instance. For more information, see Databases supported by DMS.
Node Type
In this example, Dimension Table is selected.
Select Databases and Tables
Select the databases and tables that you want to transform.
After the node is configured, you are redirected to the Output Fields tab. On this tab, select the databases and tables in the Column Name column based on your business requirements.
NoteIf the
icon is not displayed on the right side of the stream table, the stream table is configured.
Step 2: Configure the Table Join component
In the Transform section on the left side of the page, select JOIN and drag it to the canvas on the right side of the page.
Move the pointer over the stream table node, click the hollow circle on the right side of the node, and then drag a connection line to the Table Join-1 component. Then, move the pointer over the dimension table node, click the hollow circle on the right side of the node, and then drag a connection line to the Table Join-1 component.
Click Table Join-1 on the canvas to configure the Table Join-1 component.
On the Node Settings tab, configure the parameters.
Section
Parameter
Description
Conversion Name
Enter Transformation Name
DTS automatically generates a name for the Table Join-1 component. We recommend that you specify a descriptive name for easy identification. You do not need to use a unique name.
JOIN Settings
Left Table in JOIN Clause
Select the left table in the JOIN clause. The table is used as the primary table. In this example, the stream table is selected.
Temporal Join Time Attribute (Regular joins apply if not selected)
Select the time attribute of the stream table associated with the temporal table when a temporal join operation is performed. If you do not specify this parameter, a regular join operation is performed. In this example, Based on Processing Time is selected.
NoteA temporal table is a dynamic table, which is a table-based parameterized view. Temporal tables record data change history based on time. Temporal tables include versioned tables and standard tables. Versioned tables can display historical versions of data. Standard tables display only the latest version of data.
To perform a temporal join operation, the time attributes must be defined for all stream tables, and the right table must have a primary key. If the right table is a dimension table, the primary key of the table must be contained in the specified JOIN Condition parameter.
Based on Event Time Watermark: uses the time when the data of the stream table is generated to associate the version of the versioned table.
Based on Processing Time: uses the processing time of the stream table to associate the latest version of the standard table.
Select JOIN Operation
Select a join operation. In this example, Inner Join is selected.
Inner Join: obtains the intersection of two tables.
Left Join: obtains all data in the left table and the intersection of the two tables in the right table.
Right Join: obtains the intersection of the two tables in the left table and all data in the right table.
JOIN Condition
+ Add Condition
Click + Add Condition and select join conditions.
NoteThe fields on the left side of the equal sign (=) belong to the left table. The fields on the right side of the equal sign (=) belong to the right table.
After you configure the JOIN Condition parameter, click the Output Fields tab. On this tab, select the fields in the Column Name column based on your business requirements.
If the icon is not displayed on the right side of the Table Join-1 component, the join component is configured.
Step 3: Configure the Table Record Filter component
In the Transform section on the left side of the page, select Table Record Filter and drag it to the canvas on the right side of the page.
Move the pointer over the Table Join-1 component, click the hollow circle on the right side of the component, and then drag a connection line to the Table Record Filter-1 component.
Click Table Record Filter -1 on the canvas to configure the Table Record Filter -1 component.
On the Node Settings tab, enter the name of the Table Record Filter-1 component in the Conversion Name field.
NoteDTS automatically generates a name for the Table Record Filter-1 component. We recommend that you specify a descriptive name for easy identification. You do not need to use a unique name.
In the WHERE Condition field, specify a WHERE condition by using one of the following methods:
Enter the WHERE condition. For example, enter total_price>3000.00 to query the data whose value of the total_price parameter is greater than 3000.00 in the joined table.
Click an option in the Input Fields or Operator section to specify the WHERE condition.
If the icon is not displayed on the right side of the Table Join-1 component, the join component is configured.
Step 4: Configure the destination database
In the Output section on the left side of the page, select MySQL and drag it to the canvas on the right side of the page.
Move the pointer over the Table Record Filter-1 component, click the hollow circle on the right side of the component, and then drag a connection line to the Output MySQL-1 component.
Click Output MySQL-1 on the canvas to configure the Output MySQL-1 component.
On the Node Settings tab, configure the parameters.
Parameter
Description
Data Source Name
DTS automatically generates a data source name. We recommend that you specify a descriptive name for easy identification. You do not need to use a unique name.
Region
Select the region in which the destination database resides.
NoteYou can create an ETL task in one of the following regions: China (Hangzhou), China (Shanghai), China (Qingdao), China (Beijing), China (Zhangjiakou), China (Shenzhen), China (Guangzhou), and China (Hong Kong).
Instances
Select the destination database instance. You can also click Create Instance to create a destination database instance. For more information, see Databases supported by DMS.
Table Mapping
Select the table to be stored in the destination database.
In the Select Destination Table section, click the destination table.
Select the tables in the Column Name column based on your business requirements.
If the icon is not displayed on the right side of the Output MySQL-1 component, the destination database is configured.
Step 5: Precheck and start the task
After you complete the preceding configurations, click Generate Flink SQL Validation. ETL generates and validates Flink SQL statements.
After the Flink SQL validation is complete, click View ETL Validation Details. In the dialog box that appears, view the Flink SQL validation results and the SQL statements. Confirm the results and click Close.
NoteIf the validation fails, you can troubleshoot the failure based on the causes displayed in the results.
Click Next: Save Task Settings and Precheck. DTS can start the ETL task only after the task passes the precheck. If the task fails to pass the precheck, click View Details next to each failed item. Troubleshoot the issues based on the error message and run a precheck again.
After the precheck is passed, click Next: Purchase Instance in the lower part of the page.
On the Purchase Instance page, configure the Instance Class and Compute Units (CUs) parameters. Then, read and select Data Transmission Service (Pay-as-you-go) Service Terms and Service Terms for Public Preview.
NoteDuring public preview, each user can create two ETL instances free of charge.
Click Buy and Start to start the ETL task.
Task results
In this example, after the ETL task is started on August 1, the updated data in the real-time transaction table test_orders that meets the filter condition is synchronized to the destination table test_orders_new. The filter condition is that the value of the total_price parameter is greater than 3000.00, which indicates that the total transaction volume of an order is greater than 3000.00.
Figure 1. Real-time transaction data table: test_orders
Figure 2. Destination table: test_orders_new