This topic describes how to use the demo of a Kafka client to consume tracked data. The change tracking feature of the new version allows you to consume tracked data by using a Kafka client of V0.11 to V2.7.
Usage notes
If you enable auto commit when you use the change tracking feature, some data may be committed before it is consumed. This results in data loss. We recommend that you manually commit data.
NoteIf data fails to be committed, you can restart the client to continue consuming data from the last recorded consumption checkpoint. However, duplicate data may be generated during this period. You must manually filter out the duplicate data.
Data is serialized and stored in the Avro format. For more information, see Record.avsc.
WarningIf you are not using the Kafka client that is described in this topic, you must parse the tracked data based on the Avro schema.
The search unit is second when Data Transmission Service (DTS) calls the
offsetForTimesoperation. The search unit is millisecond when a native Kafka client calls this operation.Transient connections may occur between a Kafka client and the change tracking server due to several reasons, such as disaster recovery. If you are not using the Kafka client that is described in this topic, your Kafka client must have network reconnection capabilities.
Run the Kafka client
Download the Kafka client demo. For more information about how to use the demo, see Readme.
Click the
 icon and select Download ZIP to download the package.
icon and select Download ZIP to download the package. If you use a Kafka client of version 2.0, you must change the version number in the subscribe_example-master/javaimpl/pom.xml file to 2.0.0.
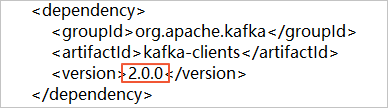
Table 1. The following table describes the steps to run the Kafka client.
Step | File or directory |
1. Use the native Kafka consumer to obtain incremental data from the change tracking instance. | subscribe_example-master/javaimpl/src/main/java/recordgenerator/ |
2. Deserialize the image of the incremental data, and obtain the pre-image (The value of each field before a data entry is updated), the post-image (The value of each field after a data entry is updated), and other attributes. Warning
| subscribe_example-master/javaimpl/src/main/java/boot/RecordPrinter.java |
3. Convert the dataTypeNumber values in the deserialized data into the data types of the corresponding database. Note For more information, see the following sections of this topic: | subscribe_example-master/javaimpl/src/main/java/recordprocessor/mysql/ |
Procedure
The following steps show how to run the Kafka client to consume tracked data. In this example, IntelliJ IDEA Community Edition 2018.1.4 for Windows is used.
Create a change tracking task. For more information, see Track data changes from an ApsaraDB RDS for MySQL instance, Track data changes from a PolarDB for MySQL cluster, or Track data changes from a self-managed Oracle database.
Create one or more consumer groups. For more information, see Create consumer groups.
Download the Kafka client demo and decompress the package.
NoteClick the
icon and select Download ZIP to download the package. Open IntelliJ IDEA. In the window that appears, click Open.

In the dialog box that appears, go to the directory in which the downloaded demo resides. Find the pom.xml file.
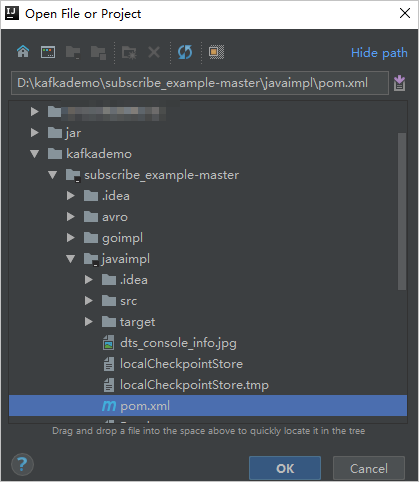
In the dialog box that appears, select Open as Project.
In the Project tool window of IntelliJ IDEA, click folders to find the demo file of the Kafka client, and double-click the file. The file name is NotifyDemoDB.java.
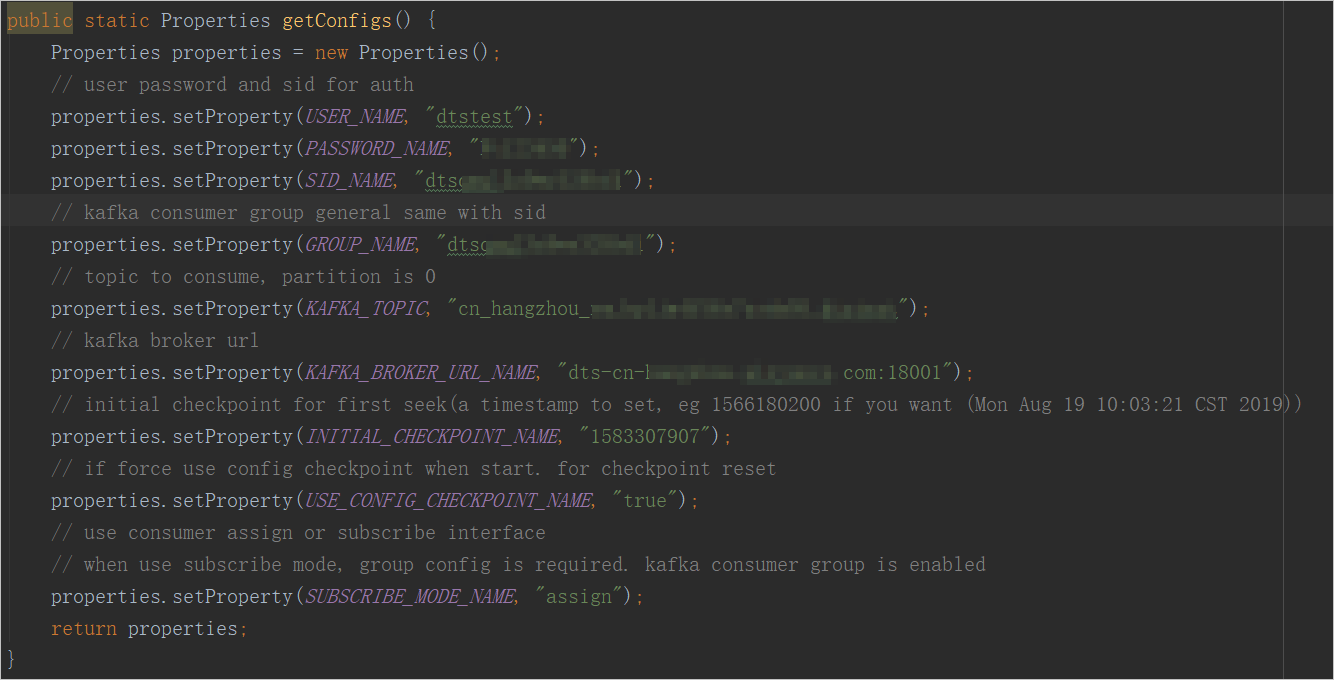
Configure the parameters in the NotifyDemoDB.java file.
Parameter
Description
Method to obtain the parameter value
USER_NAME
The account of the consumer group.
WarningIf you are not using the Kafka client that is described in this topic, you must specify the account in the following format:
<Username>-<Consumer group ID>. Example:dtstest-dtsae******bpv. Otherwise, the connection fails.In the DTS console, find the change tracking instance that you want to manage and click the instance ID. In the left-side navigation pane, click Consume Data. On the page that appears, you can obtain the consumer group ID and the corresponding username.
NoteThe password of the consumer group account is automatically specified when you create the consumer group.

PASSWORD_NAME
The password of the account.
SID_NAME
The ID of the consumer group.
GROUP_NAME
The name of the consumer group. Set this parameter to the consumer group ID.
KAFKA_TOPIC
The topic of the change tracking instance.
In the DTS console, find the change tracking instance that you want to manage and click the instance ID. On the Task Management page, you can obtain the topic and network information.
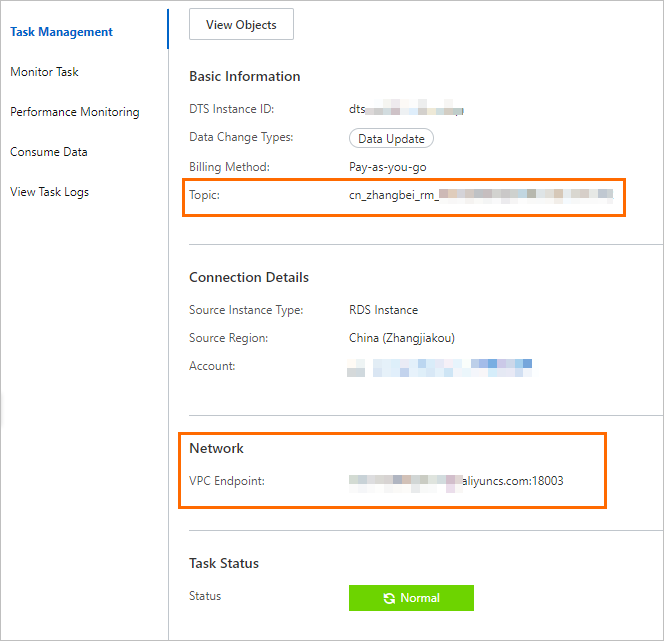
KAFKA_BROKER_URL_NAME
The endpoint of the change tracking instance.
NoteIf you track data changes over internal networks, the network latency is minimal. This is applicable if the Elastic Compute Service (ECS) instance on which you deploy the Kafka client resides on the classic network or in the same virtual private cloud (VPC) as the change tracking instance.
INITIAL_CHECKPOINT_NAME
The consumption checkpoint of consumed data. The value is a UNIX timestamp. Example: 1592269238.
NoteYou must save the consumption checkpoint for the following reasons:
If the consumption process is interrupted, you can specify the consumption checkpoint on the Kafka client to resume data consumption. This prevents data loss.
When you start the Kafka client, you can specify the consumption checkpoint to consume data on demand.
If the SUBSCRIBE_MODE_NAME parameter is set to subscribe, the INITIAL_CHECKPOINT_NAME parameter that you specified takes effect only when you start the Kafka client for the first time.
The consumption checkpoint of consumed data must be within the data range of the change tracking instance, as shown in the following figure. The consumption checkpoint must be converted into a UNIX timestamp.
 Note
NoteYou can use a search engine to obtain a UNIX timestamp converter.
USE_CONFIG_CHECKPOINT_NAME
Specifies whether to force the client to consume data from the specified consumption checkpoint. Default value: true. You can set this parameter to true to prevent the data that is received but not processed from being lost.
N/A
SUBSCRIBE_MODE_NAME
Specifies whether to run two or more Kafka clients for a consumer group. If you want to use this feature, set this parameter to subscribe for these Kafka clients.
The default value is assign, which indicates that the feature is not used. We recommend that you deploy only one Kafka client for a consumer group.
N/A
In the top menu bar of IntelliJ IDEA, choose to run the client.
NoteIf you run IntelliJ IDEA for the first time, a specific time period is required to load and install relevant dependencies.
Results on the Kafka client
The following figure shows that the Kafka client can track data changes from the source database.

You can delete the double forward slashes (//) from the //log.info(ret); string in line 25 of the NotifyDemoDB.java file. Then, run the client again to view the data change information.
FAQ
Q: Why do I need to record the consumption checkpoint of the Kafka client?
A: The consumption checkpoint recorded by DTS is the point in time when DTS receives a commit operation from the Kafka client. The recorded consumption checkpoint may be different from the actual consumption time. If a business application or the Kafka client is unexpectedly interrupted, you can specify an accurate consumption checkpoint to continue data consumption. This prevents data loss or duplicate data consumption.
Mappings between MySQL data types and dataTypeNumber values
For more information, see SQL Type field.
Mappings between Oracle data types and dataTypeNumber values
Oracle data type | Value of dataTypeNumber |
VARCHAR2 and NVARCHAR2 | 1 |
NUMBER and FLOAT | 2 |
LONG | 8 |
DATE | 12 |
RAW | 23 |
LONG_RAW | 24 |
UNDEFINED | 29 |
XMLTYPE | 58 |
ROWID | 69 |
CHAR and NCHAR | 96 |
BINARY_FLOAT | 100 |
BINARY_DOUBLE | 101 |
CLOB and NCLOB | 112 |
BLOB | 113 |
BFILE | 114 |
TIMESTAMP | 180 |
TIMESTAMP_WITH_TIME_ZONE | 181 |
INTERVAL_YEAR_TO_MONTH | 182 |
INTERVAL_DAY_TO_SECOND | 183 |
UROWID | 208 |
TIMESTAMP_WITH_LOCAL_TIME_ZONE | 231 |
Mappings between PostgreSQL data types and dataTypeNumber values
PostgreSQL data type | Value of dataTypeNumber |
INT2 and SMALLINT | 21 |
INT4, INTEGER, and SERIAL | 23 |
INT8 and BIGINT | 20 |
CHARACTER | 18 |
CHARACTER VARYING | 1043 |
REAL | 700 |
DOUBLE PRECISION | 701 |
NUMERIC | 1700 |
MONEY | 790 |
DATE | 1082 |
TIME and TIME WITHOUT TIME ZONE | 1083 |
TIME WITH TIME ZONE | 1266 |
TIMESTAMP and TIMESTAMP WITHOUT TIME ZONE | 1114 |
TIMESTAMP WITH TIME ZONE | 1184 |
BYTEA | 17 |
TEXT | 25 |
JSON | 114 |
JSONB | 3082 |
XML | 142 |
UUID | 2950 |
POINT | 600 |
LSEG | 601 |
PATH | 602 |
BOX | 603 |
POLYGON | 604 |
LINE | 628 |
CIDR | 650 |
CIRCLE | 718 |
MACADDR | 829 |
INET | 869 |
INTERVAL | 1186 |
TXID_SNAPSHOT | 2970 |
PG_LSN | 3220 |
TSVECTOR | 3614 |
TSQUERY | 3615 |