The classification and grading feature provided by Data Management (DMS) can detect sensitive data of databases, automatically tag fields that meet the condition of an identification rule with the corresponding data category, and display the sensitive fields in the identification results. This feature also protects the fields with a high sensitivity level. This topic describes the principle of the classification and grading feature of DMS.
How it works
The classification and grading feature of DMS is implemented by the underlying identification model-based scanning and the upper-layer classification and grading-based scanning. When this feature is used, DMS first uses identification models to scan the fields and data of tables. Then, DMS scans the fields of tables by using the classification and grading rules. The identification model-based scanning can identify the data category, such as name or time. The classification and grading-based scanning works based on the identification results of an identification model. You can use the classification and grading templates that are associated with instances to classify and grade fields. During this process, the security levels and data masking algorithms are automatically set for the fields.
The identification model-based scanning and the classification and grading-based scanning are independent of each other.
Identification model-based scanning
The identification model-based scanning supports the following two identification methods:
Data content identification (regular expression match)
In this identification method, the identification model classifies fields based on the field content. For example, if an identification model is named ID Card and a field meets the conditions of the ID card algorithm, the field is tagged by this identification model with a data category of ID card.
During the data content identification, DMS randomly samples some data from a field for identification to ensure the identification efficiency. If the amount of data that meets the requirements of the identification model in the sampled data is greater than the specified threshold, DMS determines that the data category of this field is ID card.
Metadata identification
In this identification method, the identification model classifies fields based on the field name. For example, a built-in ID Card identification model of DMS identifies a field named id_card in a table, the field is tagged with a data category of ID card.
Identification results
Each field may correspond to multiple identification results. For example, a field that contains a mobile number can be identified by a Mobile Number identification model and a custom identification model whose identification rule is 11 digits. DMS saves up to three identification results for a field.
DMS provides a variety of built-in identification models. You can also create custom identification models. Custom identification models support only data content identification.
You can enable or disable an identification model. By default, after you create an identification model, the model is enabled. Only the identification models that are enabled can be used by DMS for identification.
Classification and grading-based scanning
In classification and grading-based scanning, DMS matches the fields to be scanned with classification rules one by one. If a field meets the conditions of a classification rule, the field is tagged with the corresponding data category.
Principle
DMS filters all the enabled classification rules in a classification and grading template, and then uses each classification rule for identification in the following three steps:
Determine whether a classification rule contains the identification models corresponding to a field based on the scan results of identification models.
For example, if the identification models corresponding to a field are identification model A and identification model B, and the identification models specified for a classification rule are identification model B and identification model C, DMS identifies the intersection of the identification models, which is identification model B. In this case, DMS also determines that this classification rule contains the identification model of the field, and continues to use the next classification rule for identification. If a classification rule contains no identification models of the field, the identification fails and DMS continues to use the next classification rule for identification.
Determine the identification scope based on the metadata of the field, including the database name, table name, field name, and field description.
In this step, DMS determines whether the data of the field is within the identification scope that is specified for the classification rule. If the data of the field is within the identification scope specified for the classification rule, the corresponding data category is stored in the classification results of the field and DMS continues to use the next classification rule for identification.
Tag the field with a data category.
After all classification rules are used for identification, if the field meets the conditions of only one classification rule, the field is tagged with the corresponding data category. If the field meets the conditions of multiple classification rules, DMS sorts the classification rules based on their security levels in ascending order and then tags the field with the data category corresponding to the classification rule whose security level is the highest.
The following figure shows how the classification and grading feature scans a single field.

Parameters related to identification rules
Before you perform a classification and grading-based scanning, you can create custom identification rules for a classification and grading template. The following section describes the parameters that you can configure when you create an identification rule.
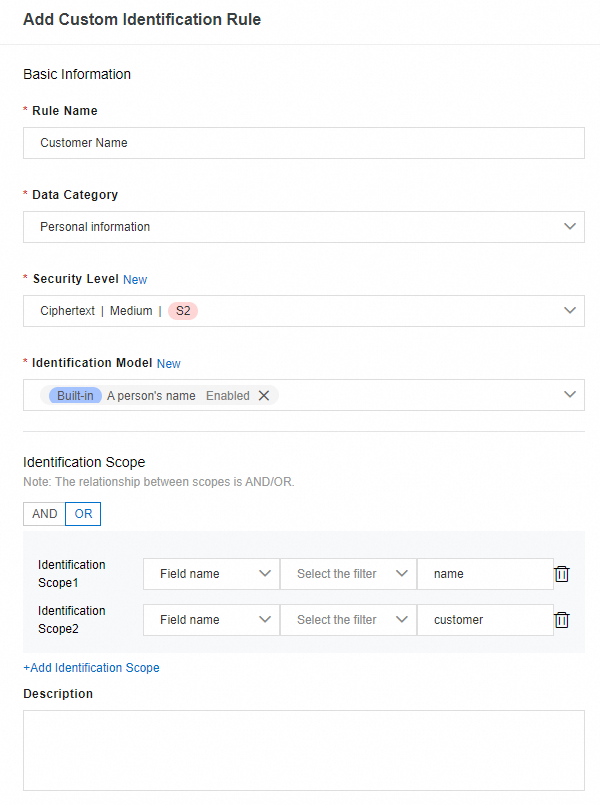
Security Level: the security levels of the fields. You can set this parameter based on your business requirements. A higher security level indicates that the field is more sensitive and important. For more information, see Field security level.
Identification Model: the underlying identification models that you want to use for this identification rule. You can select multiple identification models. The logical relationship among the selected models is OR. For example, if a field hits one of the selected identification models, the field is detected by this identification rule.
Identification Scope: You can set this parameter to filter metadata. Valid values are AND and OR. If you select AND, the fields whose metadata meets the conditions of all the specified scopes are detected. If you select OR, the fields whose metadata meets the condition of one of the specified scopes are detected.